前言
本文基于 ElasticJob-Lite 3.x 版本展开分析。
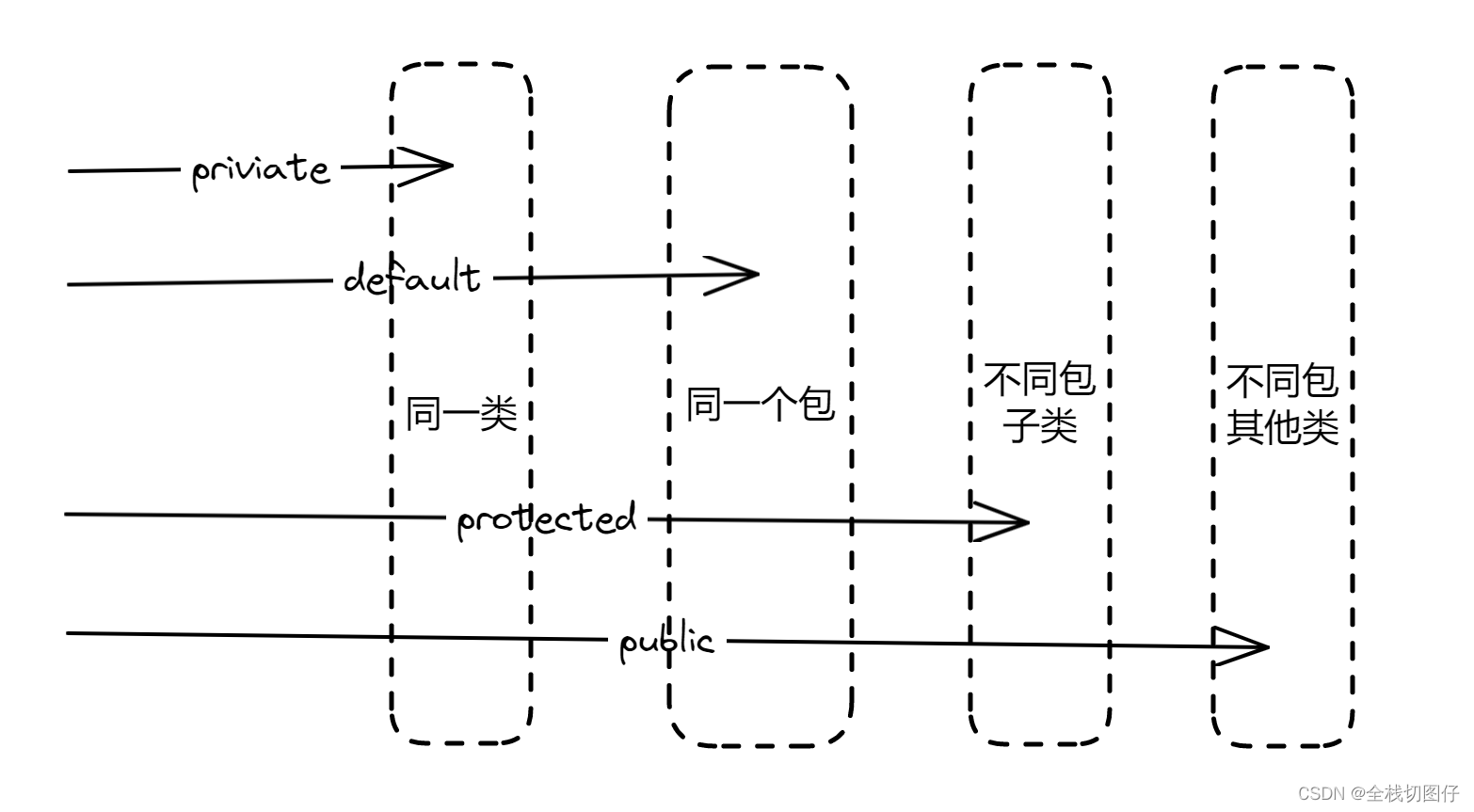
如果 Quartz 集群中有多个服务端节点,任务决定在哪个服务端节点上执行的呢?
Quartz 采用随机负载,通过 DB 抢占下一个即将触发的 Trigger 绑定的任务的执行权限。
在 Quartz 的基础上,需要一个新的分布式任务调度框架。它可以帮助我们做到如下:
- 通过选举一个 Leader 节点来协调多个服务端节点,可以指定任务在哪个服务端节点上执行。
- 如果任务数量过多,需要分片,多个节点执行分片任务。
- 支持动态调度以及拥有可视化界面。
介绍
ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。它通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署。
ElasticJob-Lite 定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务。
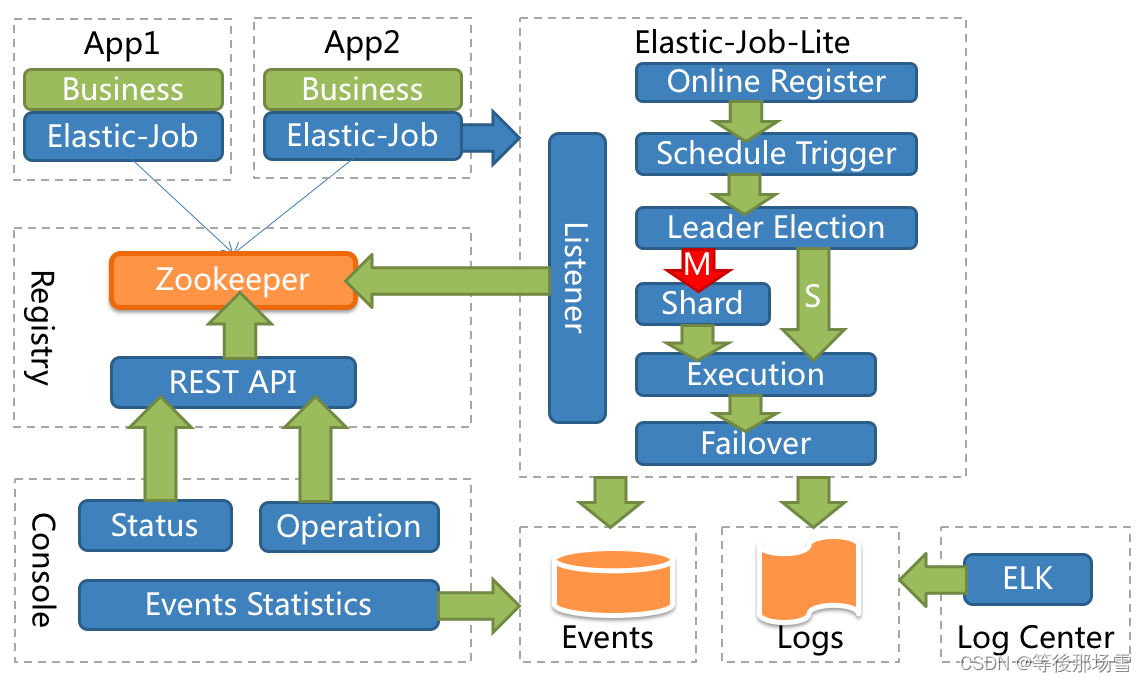
核心概念与功能
调度模型
ElasticJob 的调度模型分为支持线程级别调度的进程内调度 ElasticJob-Lite 和进程级别调度的 ElasticJob-Cloud。
进程内调度
ElasticJob-Lite 是面向进程内的线程级别调度框架。通过它,作业能够透明化的与业务应用系统相结合。它能够方便的与 Spring、Dubbo 等 Java 框架配合使用,在作业中可以自由使用 Spring 注入的 Bean,如数据库连接池、Dubbo 远程服务等,更加方便的贴合业务开发。
进程调度
ElasticJob-Cloud 拥有进程内调度和进程级别调度两种方式。 由于 ElasticJob-Cloud 能够对作业服务器的资源进行控制,因此其作业类型可划分为常驻任务和瞬时任务。 常驻任务类似于 ElasticJob-Lite,是进程内调度;瞬时任务则完全不同,它充分的利用了资源分配的削峰填谷能力,是进程级的调度,每次任务会启动全新的进程处理。
弹性调度
弹性调度是 ElasticJob 最重要的功能,也是这款产品名称的由来。它是一款能够让任务通过分片进行水平拓展的任务处理系统。
分片
ElasticJob 中任务分片项的概念,使得任务可以在分布式的环境下运行,每台任务服务器只运行分配给该服务器的分片。 随着服务器的增加或宕机,ElasticJob 会近乎实时的感知服务器数量的变更,从而重新为分布式的任务服务器分配更加合理的任务分片项,使得任务可以随着资源的增加而提升效率。
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
分片项
分片项为数字,始于 0 而终于分片总数减 1。
分片参数
个性化参数可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
例如:按照地区水平拆分数据库,数据库 A 是北京的数据;数据库 B 是上海的数据;数据库 C 是广州的数据。 如果仅按照分片项配置,开发者需要了解 0 表示北京;1 表示上海;2 表示广州。 合理使用个性化参数可以让代码更可读,如果配置为 0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
举例说明,如果作业分为 4 片,用两台服务器执行,则每个服务器分到 2 片,分别负责作业的 50% 的负载,如下图所示。
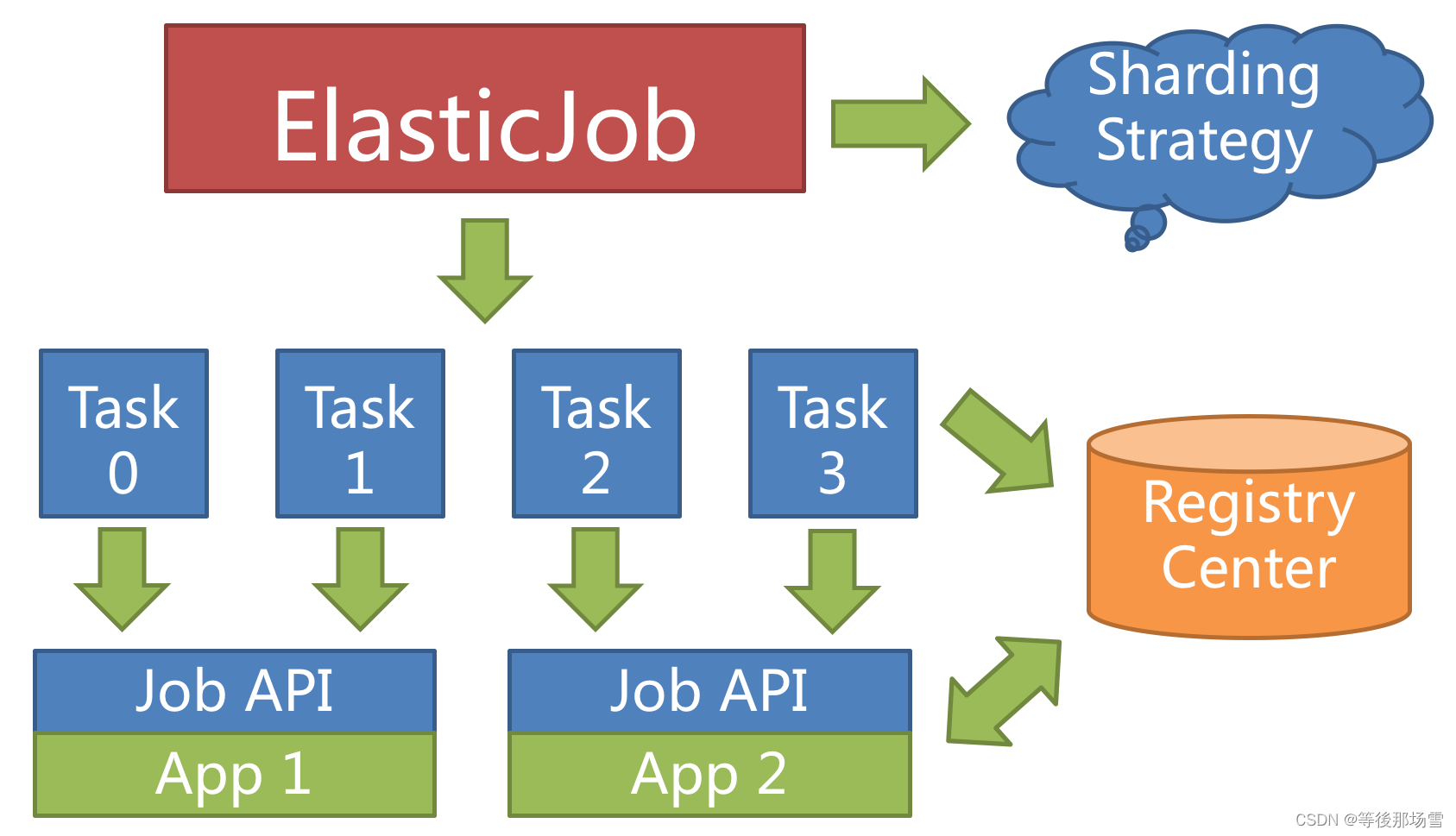
资源最大限度利用
当新增加作业服务器时,ElasticJob 会通过注册中心的临时节点的变化感知到新服务器的存在,并在下次任务调度的时候重新分片,新的服务器会承载一部分作业分片。
将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如:3 台服务器,分成 10 片,则分片项分配结果为服务器 A = 0,1,2,9;服务器 B = 3,4,5;服务器 C = 6,7,8。 如果服务器 C 崩溃,则分片项分配结果为服务器 A = 0,1,2,3,4; 服务器 B = 5,6,7,8,9。 在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
高可用
当作业服务器在运行中宕机时,注册中心同样会通过临时节点感知,并将在下次运行时将分片转移至仍存活的服务器,以达到作业高可用的效果。 本次由于服务器宕机而未执行完的作业,则可以通过失效转移的方式继续执行
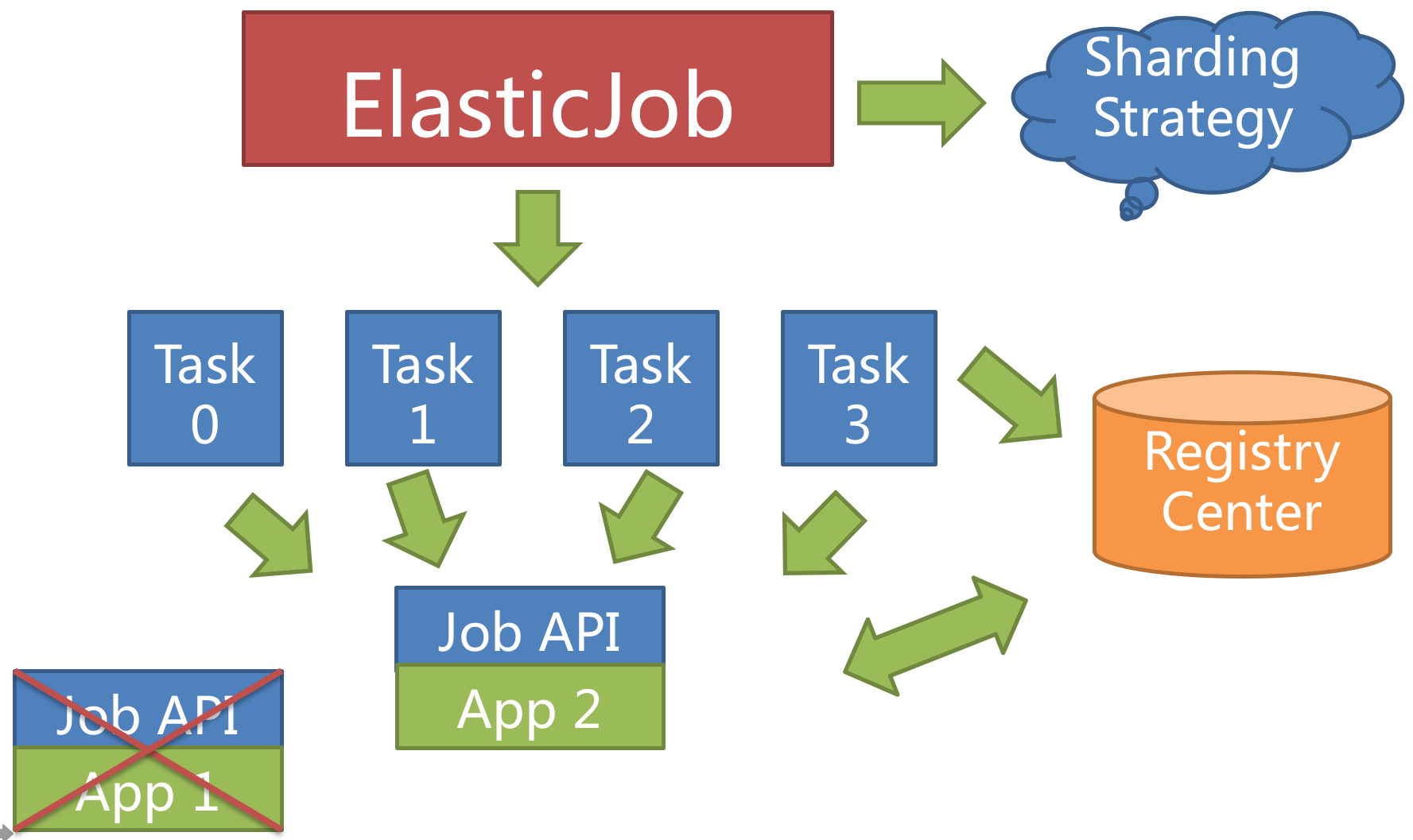
实现原理
ElasticJob-Lite 无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。 注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
弹性分布式实现
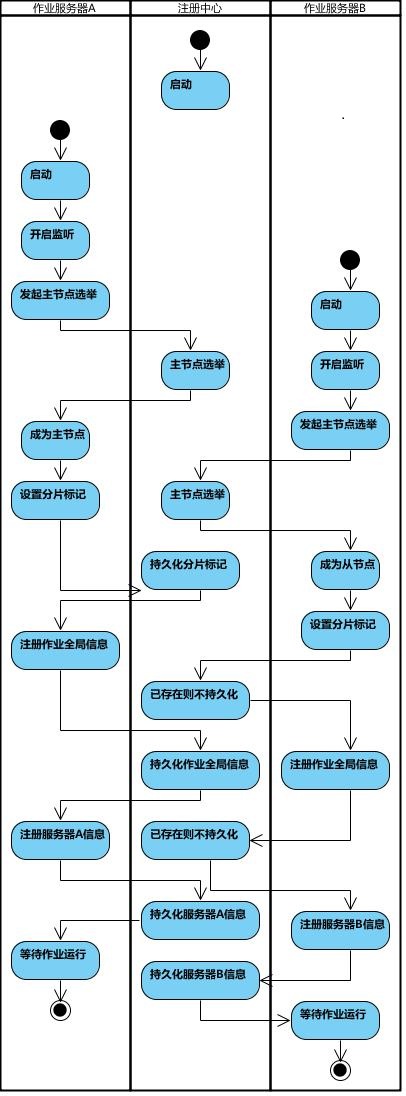
- 第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
- 某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
- 主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
- 定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
- 通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
- 每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
- 实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
注册中心数据结构
注册中心在定义的命名空间下,创建作业名称节点,用于区分不同作业,所以作业一旦创建则不能修改作业名称,如果修改名称将视为新的作业。 作业名称节点下又包含5个数据子节点,分别是 config, instances, sharding, servers 和 leader。
config 节点
作业配置信息,以 YAML 格式存储。
instances 节点
作业运行实例主键由作业运行服务器的 IP 地址和 PID 构成。 作业运行实例主键均为临时节点,当作业实例上线时注册,下线时自动清理。注册中心监控这些节点的变化来协调分布式作业的分片以及高可用。 可在作业运行实例节点写入 TRIGGER 表示该实例立即执行一次。
sharding 节点
作业分片信息,子节点是分片项序号,从零开始,至分片总数减一。 分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。 节点详细信息说明:
| 子节点名 | 临时节点 | 描述 |
|---|---|---|
| instance | 否 | 执行该分片项的作业运行实例主键 |
| running | 是 | 分片项正在运行的状态 仅配置 monitorExecution 时有效 |
| failover | 是 | 如果该分片项被失效转移分配给其他作业服务器,则此节点值记录执行此分片的作业服务器 IP |
| misfire | 否 | 是否开启错过任务重新执行 |
| disabled | 否 | 是否禁用此分片项 |
servers 节点
作业服务器信息,子节点是作业服务器的 IP 地址。 可在 IP 地址节点写入 DISABLED 表示该服务器禁用。 在新的云原生架构下,servers 节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。 为了更加纯粹的实现作业核心,servers 功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。
leader 节点
作业服务器主节点信息,分为 election,sharding 和 failover 三个子节点。 分别用于主节点选举,分片和失效转移处理。
leader节点是内部使用的节点。
| 子节点名 | 临时节点 | 描述 |
|---|---|---|
| election\instance | 是 | 主节点服务器IP地址 一旦该节点被删除将会触发重新选举 重新选举的过程中一切主节点相关的操作都将阻塞 |
| election\latch | 否 | 主节点选举的分布式锁 为 curator 的分布式锁使用 |
| sharding\necessary | 否 | 是否需要重新分片的标记 如果分片总数变化,或作业服务器节点上下线或启用/禁用,以及主节点选举,会触发设置重分片标记 作业在下次执行时使用主节点重新分片,且中间不会被打断 作业执行时不会触发分片 |
| sharding\processing | 是 | 主节点在分片时持有的节点 如果有此节点,所有的作业执行都将阻塞,直至分片结束 主节点分片结束或主节点崩溃会删除此临时节点 |
| failover\items\分片项 | 否 | 一旦有作业崩溃,则会向此节点记录 当有空闲作业服务器时,会从此节点抓取需失效转移的作业项 |
| failover\items\latch | 否 | 分配失效转移分片项时占用的分布式锁 为 curator 的分布式锁使用 |
流程图
作业启动
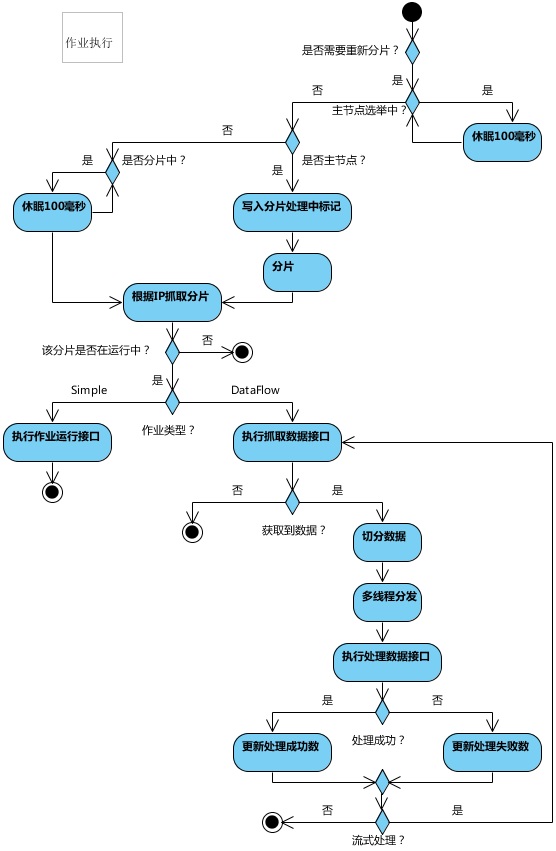
作业执行
失效转移
概念
失效转移是当前执行作业的临时补偿执行机制,在下次作业运行时,会通过重分片对当前作业分配进行调整。
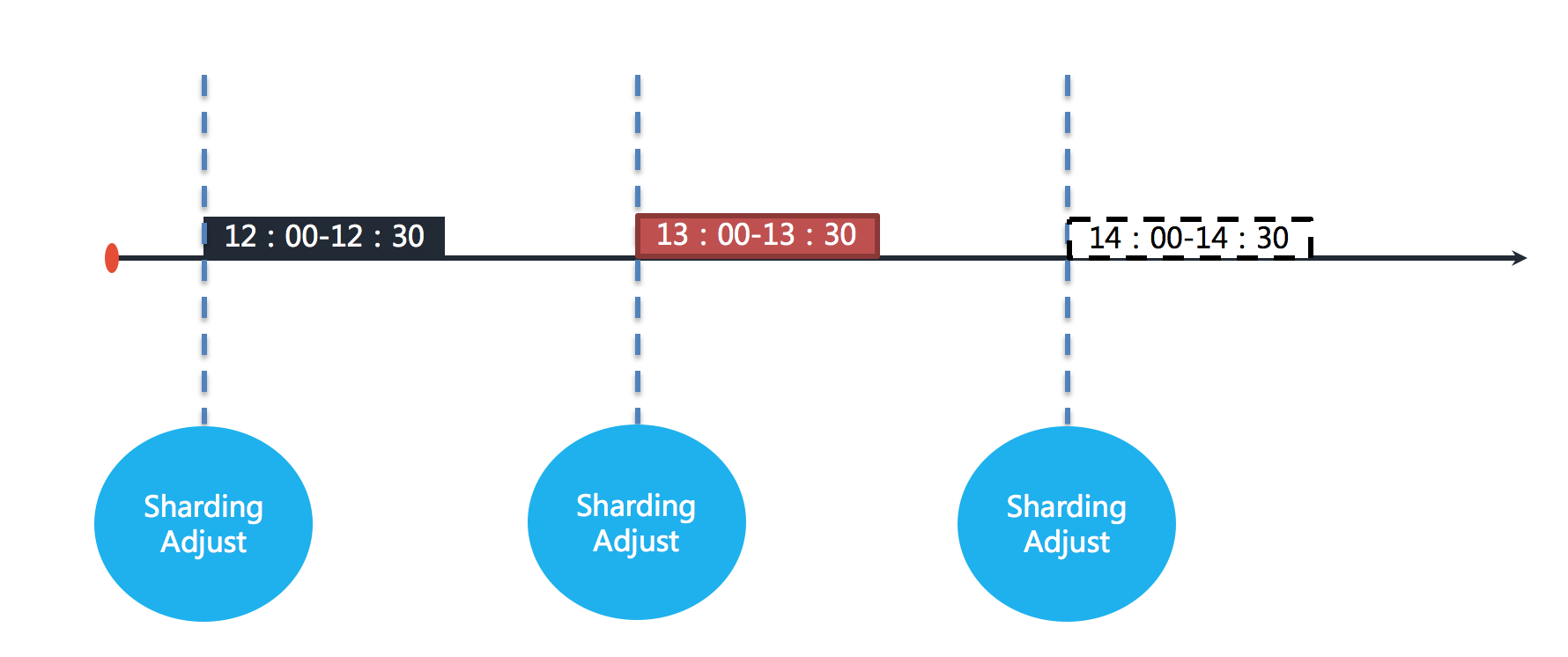
举例说明,若作业以每小时为间隔执行,每次执行耗时 30 分钟。图中表示作业分别于 12:00,13:00 和 14:00 执行。图中显示的当前时间点为 13:00 的作业执行中。
如果作业的其中一个分片服务器在 13:10 的时候宕机,那么剩余的 20 分钟应该处理的业务未得到执行,并且需要在 14:00 时才能再次开始执行下一次作业。 也就是说,在不开启失效转移的情况下,位于该分片的作业有 50 分钟空档期。在开启失效转移功能之后,ElasticJob 的其他服务器能够在感知到宕机的作业服务器之后,补偿执行该分片作业。在资源充足的情况下,作业仍然能够在 13:30 完成执行。
执行机制
当作业执行的节点宕机时,会触发失效转移流程。ElasticJob 根据触发时的分布式作业执行的不同情况来决定失效转移的执行时机。
1、通知执行。当其它服务器感知到有失效转移的作业需要处理时,且该作业服务器已经完成了本地作业,则会实时的拉取待失效转移的分片项,并开始补偿执行。也称为实时执行。
2、问询执行。作业服务器在本地任务执行结束后,会向注册中心询问待执行的失效转移分片项,如果有,则开始补偿执行。也称为异步执行。
适用场景
开启失效转移功能,ElasticJob 会监控作业每一个分片的执行状态,并将其写入到注册中心,供其它节点感知。
在一次运行耗时较长且间隔较长的作业场景,失效转移是提升作业运行实时性的有效手段;对于间隔较短的作业,会产生大量与注册中心的网络通信,对集群的性能产生影响。而且间隔较短的作业并未见得关注单次作业的实时性,可以通过下次作业执行的重分片使所有的分片正确执行,因此不建议短间隔作业开启失效转移。
另外需要注意的是,作业本身的幂等性,是保证失效转移正确性的前提。
错过任务重执行
错误任务重执行功能可以使逾期未执行的作业在上次作业执行完成之后立即执行。ElasticJob 不允许作业在同一时间内叠加执行。
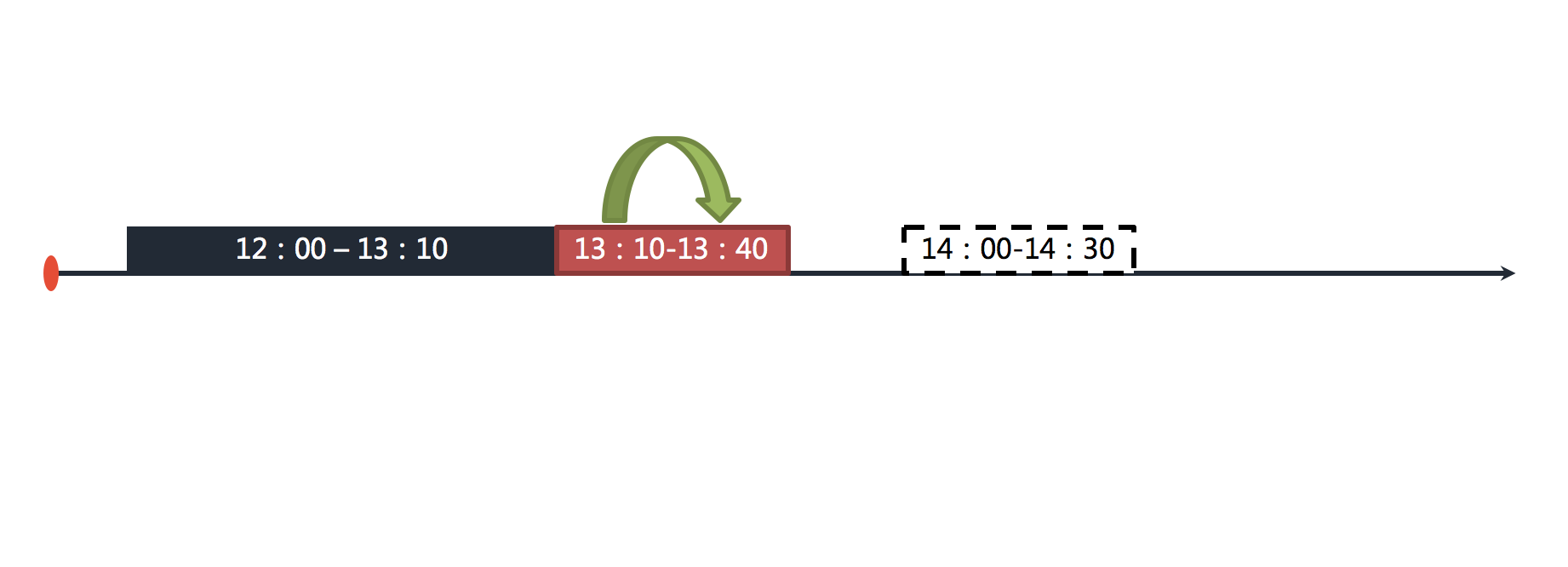
举例说明,若作业以每小时为间隔执行,每次执行耗时 30 分钟。如果 12:00 开始执行的作业在 13:10 才执行完毕,那么本该由 13:00 触发的作业则错过了触发时间,需要等待至 14:00 的下次作业触发。在开启错过任务重执行功能之后,ElasticJob 将会在上次作业执行完毕后,立刻触发执行错过的作业。如下图所示。
适用场景
在一次运行耗时较长且间隔较长的作业场景,错过任务重执行是提升作业运行实时性的有效手段; 对于未见得关注单次作业的实时性的短间隔的作业来说,开启错过任务重执行并无必要。
作业 API
作业
ElasticJob 的作业分为:基于 class 和基于 type 两种类型。
基于 class 的作业需要开发者自行通过实现接口的方式织入业务逻辑。此外方法参数 shardingContext 包含作业配置、分片和运行时信息。可以通过 getShardingTotalCount()、getShardingItem() 等方法分别获取分片总数、运行在本作业服务器的分片序列号等。 ElasticJob 目前提供了 Simple、Dataflow 两种基于 class 的作业类型。
基于 type 的作业无需编码,只需要提供相应配置即可。ElasticJob 目前提供了 Script、HTTP 两种基于 type 的作业类型。
此外,用于可以通过实现 SPI 接口自行拓展作业类型。
简单作业
意为简单实现,未经任何封装的类型。需要实现 SimpleJob 接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与 Quartz 原生接口相似,但是提供了弹性扩缩容和分片等功能。
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
switch (shardingContext.getShardingItem()) {
case 0: {
// process task
break;
}
case 1: {
// process task
break;
}
case 2: {
// process task
break;
}
default: {
break;
}
}
}
}
数据流作业
用于处理数据流,需要实现 DataflowJob 接口。该接口提供了两个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
public class MyDataflowJob implements DataflowJob<String> {
@Override
public List<String> fetchData(ShardingContext shardingContext) {
List<String> result = new ArrayList<>();
switch (shardingContext.getShardingItem()) {
case 0: {
// get data from database by sharding item 0
break;
}
case 1: {
// get data from database by sharding item 1
break;
}
case 2: {
// get data from database by sharding item 2
break;
}
default: {
break;
}
}
return result;
}
@Override
public void processData(ShardingContext shardingContext, List<String> list) {
// process data
}
}
可以通过属性配置 streaming.process 开启或者关闭流式处理。如果开启流式处理,则作业只有在 fetchData 方法的返回值为 null 或者集合容量为空时,才停止抓取,否则作业将一直运行下去;如果关闭流式处理,则每次作业执行过程中仅执行一次 fetchData 和 processData 方法,随即完成本次作业。
如果采用流式作业处理方式,建议 processData 在处理数据后更新其状态,避免 fetchData 再次抓取到,从而使得作业永不停止。
脚本作业
支持 shell、python、perl 等所有类型的脚本。可以通过配置属性 script.command.line 配置待执行脚本,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架自动追加最后一个参数为作业运行时信息。
例如如下脚本:
#!/bin/bash
echo sharding execution context is $*
作业运行时将输出:
sharding execution context is {"jobName":"scriptElasticDemoJob","shardingTotalCount":10,"jobParameter":"","shardingItem":0,"shardingParameter":"A"}
HTTP作业
可以通过配置属性 http.url、http.method、http.data 等配置待请求的 http 信息。分片信息以 Header 形式传递,key 为 shardingContext,值为 json 格式。
public class HttpJobMain {
public static void main(String[] args) {
new ScheduleJobBootstrap(regCenter, "HTTP", JobConfiguration.newBuilder("javaHttpJob", 1)).setProperty(HttpJobProperties.URI_KEY, "http://xxx.com/execute")
.setProperty(HttpJobProperties.METHOD_KEY, "POST")
.setProperty(HttpJobProperties.DATA_KEY, "source=ejob")
.cron("0/5 * * * * ?").shardingItemParameters("0=Beijing").build()).schedule();
}
}
@Controller
@Slf4j
public class HttpJobController {
@PostMapping("execute")
public void execute(String source, @RequestHeader String shardingContext) {
log.info("execute from source : {}, shardingContext : {}", source, shardingContext);
}
}
作业运行时将输出:
execute from source : ejob, shardingContext : {"jobName":"scriptElasticDemoJob","shardingTotalCount":3,"jobParameter":"","shardingItem":0,"shardingParameter":"Beijing"}
Spring Boot 环境中,需要将对应的作业注册为 Spring 容器中的 bean。比如标注 @Component 注解。
Bean 默认是单例的,如果该作业实现会在同一个进程内被创建出多个 JobBootstrap 的实例, 可以考虑设置 Scope 为 prototype。
作业配置
JobConfiguration.newBuilder("mySimpleJob", 3)
.cron("0/5 * * * * ?")
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou").build();
注意:一次性调度的作业配置不需要加 cron 表达式。
Spring Boot 环境中,在 application.yml 配置文件中进行配置。
elasticjob:
reg-center:
server-lists: 10.211.55.6:2181
namespace: elasticjob-lite-springboot
jobs:
mySimpleJob:
elasticJobClass: com.mzs.elasticjob.demo.job.MySimpleJob
cron: 0/5 * * * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
作业启动
ElasticJob-Lite 调度器分为定时调度和一次性调度两种类型。每种调度器启动时都需要注册中心配置、作业对象(作业类型)以及作业配置三个参数。
定时调度
public class JobDemo {
public static void main(String[] args) {
jobDemo1();
}
/**
* 定时调度
*/
private static void jobDemo1() {
// 调度基于 class 类型的作业
new ScheduleJobBootstrap(createRegistryCenter(), new MySimpleJob(), createJobConfiguration()).schedule();
// 调度基于 type 类型的作业
new ScheduleJobBootstrap(createRegistryCenter(), "MY_TYPE", createJobConfiguration()).schedule();
}
private static JobConfiguration createJobConfiguration() {
return JobConfiguration.newBuilder("mySimpleJob", 3)
.cron("0/5 * * * * ?").shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou").build();
}
private static CoordinatorRegistryCenter createRegistryCenter() {
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("10.211.55.6:2181,10.211.55.7:2181,10.211.55.8:2181", "elasticjob-demo"));
registryCenter.init();
return registryCenter;
}
}
定时调度作业在 Spring Boot 应用程序启动完成后自动启动,无需其它额外操作。
一次性调度
public class JobDemo {
public static void main(String[] args) {
jobDemo2();
}
/**
* 一次性调度
*/
private static void jobDemo2() {
// 调度基于 class 类型的作业
OneOffJobBootstrap oneOffJobBootstrap = new OneOffJobBootstrap(createRegistryCenter(), new MySimpleJob(), createJobConfigurationForOneOffJob());
oneOffJobBootstrap.execute();
}
private static JobConfiguration createJobConfigurationForOneOffJob() {
return JobConfiguration.newBuilder("mySimpleJob", 3)
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou").build();
}
private static CoordinatorRegistryCenter createRegistryCenter() {
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("10.211.55.6:2181,10.211.55.7:2181,10.211.55.8:2181", "elasticjob-demo"));
registryCenter.init();
return registryCenter;
}
}
一次性调度在 Spring Boot 的 application.yml 文件中配置 jobBootstrapBeanName 属性。然后注入 OneOffJobBootstrap,在合适的地方调用它的 execute 方法。
@Resource(name = "someJobBootstrapBeanName")
private OneOffJobBootstrap oneOffJobBootstrap;
// @Autowired
// @Qualifier(name = "someJobBootstrapBeanName")
// private OneOffJobBootstrap oneOffJobBootstrap;
oneOffJobBootstrap.execute();
配置作业导出端口
使用 ElasticJob-Lite 过程中可能会遇到一些分布式问题,导致作业运行不稳定。
由于无法在生产环境调试,通过 dump 命令可以把作业内部相关信息导出,方便开发者调试分析;导出命令的使用请参见 运维指南。
以下示例用于展示如何通过 SnapshotService 开启用于导出命令的监听端口:
new SnapshotService(createRegistryCenter(), 9888).listen();
在 Spring Boot 环境中,配置如下:
elasticjob:
reg-center:
server-lists: 10.211.55.6:2181
namespace: elasticjob-lite-springboot
dump:
enabled: true
port: 9888
配置错误处理策略
使用 ElasticJob-Lite 过程中当作业发生异常后,可采用以下错误处理策略。
| 错误处理策略名称 | 说明 | 是否内置 | 是否默认 | 是否需要额外配置 |
|---|---|---|---|---|
| 记录日志策略 | 记录作业异常日志,但不中断作业执行 | 是 | 是 | |
| 抛出异常策略 | 抛出系统异常并中断作业执行 | 是 | ||
| 忽略异常策略 | 忽略系统异常且不中断作业执行 | 是 | ||
| 邮件通知策略 | 发送邮件消息通知,但不中断作业执行 | 是 | ||
| 企业微信通知策略 | 发送企业微信消息通知,但不中断作业执行 | 是 | ||
| 钉钉通知策略 | 发送钉钉消息通知,但不中断作业执行 | 是 |
在实际开发中,配置错误处理策略需要在作业配置的 jobErrorHandlerType 方法指定参数,以上六种错误处理策略分别对应:LOG、THROW、IGNORE、EMAIL、WECHAT、DINGTALK。
JobConfiguration.newBuilder("mySimpleJob", 3)
.cron("0/5 * * * * ?")
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou")
.jobErrorHandlerType("LOG")
.build();
对于邮件通知策略、企业微信通知策略、钉钉通知策略额外需要引入相关依赖以及设置相关配置,详见:错误处理策略。
在 Spring Boot 环境中,需要在 application.yml 配置文件中指定 jobErrorHandlerType 属性,支持 LOG、THROW、IGNORE、EMAIL、WECHAT、DINGTALK。
elasticjob:
reg-center:
server-lists: 10.211.55.6:2181
namespace: elasticjob-lite-springboot
jobs:
mySimpleJob:
elasticJobClass: com.mzs.elasticjob.demo.job.MySimpleJob
cron: 0/5 * * * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
jobErrorHandlerType: LOG
作业监听器
ElasticJob-Lite 提供了作业监听器,用于在任务执行前和任务执行后的执行监听的方法。
常规监听器
监听每个节点的任务执行。适用于任务实现简单,并且不需要考虑全局分布式任务是否完成的场景。比如:作业处理作业服务器的文件,处理完成后删除文件,每个节点都参与执行任务。
public class MyElasticJobListener implements ElasticJobListener {
/**
* 在任务开始执行时调用该方法
*/
@Override
public void beforeJobExecuted(ShardingContexts shardingContexts) {
}
/**
* 在任务开始执行时调用该方法
*/
@Override
public void afterJobExecuted(ShardingContexts shardingContexts) {
}
@Override
public String getType() {
return "simpleJobListener";
}
}
JobConfiguration.newBuilder("mySimpleJob", 3)
.cron("0/5 * * * * ?")
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou")
.jobListenerType("simpleJobListener")
.build();
在作业配置中通过 jobListenerType 方法添加对应的作业监听器的类型。
分布式监听器
监听集群中最后一个开始/结束执行任务的节点的任务执行。需要同步分布式环境下的作业的状态同步,提供了超时设置来避免作业状态不同步导致死锁。比如:作业处理数据库数据,处理完成后只需要一个节点完成数据清理任务即可。
public class MyDistributedOnceJobListener extends AbstractDistributeOnceElasticJobListener {
private static final long START_TIMEOUT_MILLS = 3000;
private static final long COMPLETE_TIMEOUT_MILLS = 3000;
public MyDistributedOnceJobListener() {
super(START_TIMEOUT_MILLS, COMPLETE_TIMEOUT_MILLS);
}
/**
* 在任务开始执行时调用该方法
*/
@Override
public void doBeforeJobExecutedAtLastStarted(ShardingContexts shardingContexts) {
}
/**
* 在任务结束执行时调用该方法
*/
@Override
public void doAfterJobExecutedAtLastCompleted(ShardingContexts shardingContexts) {
}
@Override
public String getType() {
return "distributeOnceJobListener";
}
}
JobConfiguration.newBuilder("mySimpleJob", 3)
.cron("0/5 * * * * ?")
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou")
.jobListenerType("distributeOnceJobListener")
.build();
在作业配置中通过 jobListenerType 方法添加对应的作业监听器的类型。
Spring Boot 环境中, 将 JobListener 实现添加至 resources/META-INF/services/org.apache.shardingsphere.elasticjob.infra.listener.ElasticJobListener。
com.mzs.elasticjob.demo.listener.MyElasticJobListener
在配置文件中指定如下:
elasticjob:
reg-center:
server-lists: 10.211.55.6:2181
namespace: elasticjob-lite-springboot
jobs:
mySimpleJob:
elasticJobClass: com.mzs.elasticjob.demo.job.MySimpleJob
cron: 0/5 * * * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
jobListenerTypes: simpleJobListener
事件追踪
ElasticJob 提供了事件追踪的功能,可以通过事件订阅的方式处理调度过程的重要事件,用于查询、统计和监控。
目前提供了基于关系型数据库的事件订阅方式记录事件,开发者也可以通过 SPI 自行拓展。
// 初始化数据源
DataSource dataSource = ...;
// 定义日志数据库事件溯源配置
TracingConfiguration tracingConfig = new TracingConfiguration("RDB", dataSource);
JobConfiguration jobConfig = JobConfiguration.newBuilder("mySimpleJob", 3)
.cron("0/5 * * * * ?")
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou")
.build();
jobConfig.getExtraConfigurations().add(tracingConfig);
需要定义 TracingConfiguration,然后将其添加到作业配置中的 extraConfigurations 集合中。
在 Spring Boot 环境中,需要导入如下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
然后配置如下:
spring:
datasource:
url: jdbc:mysql://10.211.55.6:3306/elastic_job_log
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
elasticjob:
tracing:
type: RDB
最后Elastic Job 会自动创建 JOB_EXECUTION_LOG 和 JOB_STATUS_TRACE_LOG 两张表以及若干索引。
JOB_EXECUTION_LOG 字段含义
| 字段名称 | 字段类型 | 是否必填 | 描述 |
|---|---|---|---|
| id | VARCHAR(40) | 是 | 主键 |
| job_name | VARCHAR(100) | 是 | 作业名称 |
| task_id | VARCHAR(1000) | 是 | 任务名称,每次作业运行生成新任务 |
| hostname | VARCHAR(255) | 是 | 主机名称 |
| ip | VARCHAR(50) | 是 | 主机IP |
| sharding_item | INT | 是 | 分片项 |
| execution_source | VARCHAR(20) | 是 | 作业执行来源。可选值为NORMAL_TRIGGER, MISFIRE, FAILOVER |
| failure_cause | VARCHAR(2000) | 否 | 执行失败原因 |
| is_success | BIT | 是 | 是否执行成功 |
| start_time | TIMESTAMP | 是 | 作业开始执行时间 |
| complete_time | TIMESTAMP | 否 | 作业结束执行时间 |
JOB_EXECUTION_LOG 记录每次作业的执行历史。 分为两个步骤:
- 作业开始执行时向数据库插入数据,除 failure_cause 和 complete_time 外的其他字段均不为空。
- 作业完成执行时向数据库更新数据,更新 is_success, complete_time 和 failure_cause(如果作业执行失败)。
JOB_STATUS_TRACE_LOG 字段含义
| 字段名称 | 字段类型 | 是否必填 | 描述 |
|---|---|---|---|
| id | VARCHAR(40) | 是 | 主键 |
| job_name | VARCHAR(100) | 是 | 作业名称 |
| original_task_id | VARCHAR(1000) | 是 | 原任务名称 |
| task_id | VARCHAR(1000) | 是 | 任务名称 |
| slave_id | VARCHAR(1000) | 是 | 执行作业服务器的名称,Lite版本为服务器的IP地址,Cloud版本为Mesos执行机主键 |
| source | VARCHAR(50) | 是 | 任务执行源,可选值为CLOUD_SCHEDULER, CLOUD_EXECUTOR, LITE_EXECUTOR |
| execution_type | VARCHAR(20) | 是 | 任务执行类型,可选值为NORMAL_TRIGGER, MISFIRE, FAILOVER |
| sharding_item | VARCHAR(255) | 是 | 分片项集合,多个分片项以逗号分隔 |
| state | VARCHAR(20) | 是 | 任务执行状态,可选值为TASK_STAGING, TASK_RUNNING, TASK_FINISHED, TASK_KILLED, TASK_LOST, TASK_FAILED, TASK_ERROR |
| message | VARCHAR(2000) | 是 | 相关信息 |
| creation_time | TIMESTAMP | 是 | 记录创建时间 |
JOB_STATUS_TRACE_LOG 记录作业状态变更痕迹表。 可通过每次作业运行的 task_id 查询作业状态变化的生命周期和运行轨迹。
分片策略
平均分片策略
类型:AVG_ALLOCATION
根据分片项平均分片。
如果作业服务器数量与分片总数无法整除,多余的分片将会顺序的分配至每一个作业服务器。
举例说明:
- 如果 3 台作业服务器且分片总数为9,则分片结果为:1=[0,1,2], 2=[3,4,5], 3=[6,7,8];
- 如果 3 台作业服务器且分片总数为8,则分片结果为:1=[0,1,6], 2=[2,3,7], 3=[4,5];
- 如果 3 台作业服务器且分片总数为10,则分片结果为:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]。
奇偶分片策略
类型:ODEVITY
根据作业名称哈希值的奇偶数决定按照作业服务器 IP 升序或是降序的方式分片。
如果作业名称哈希值是偶数,则按照 IP 地址进行升序分片; 如果作业名称哈希值是奇数,则按照 IP 地址进行降序分片。 可用于让服务器负载在多个作业共同运行时分配的更加均匀。
举例说明:
- 如果 3 台作业服务器,分片总数为2且作业名称的哈希值为偶数,则分片结果为:1 = [0], 2 = [1], 3 = [];
- 如果 3 台作业服务器,分片总数为2且作业名称的哈希值为奇数,则分片结果为:3 = [0], 2 = [1], 1 = []。
轮询分片策略
类型:ROUND_ROBIN
根据作业名称轮询分片。
线程池策略
CPU 资源策略
类型:CPU
根据 CPU 核数 * 2 创建作业处理线程池。
单线程策略
类型:SINGLE_THREAD
使用单线程处理作业。
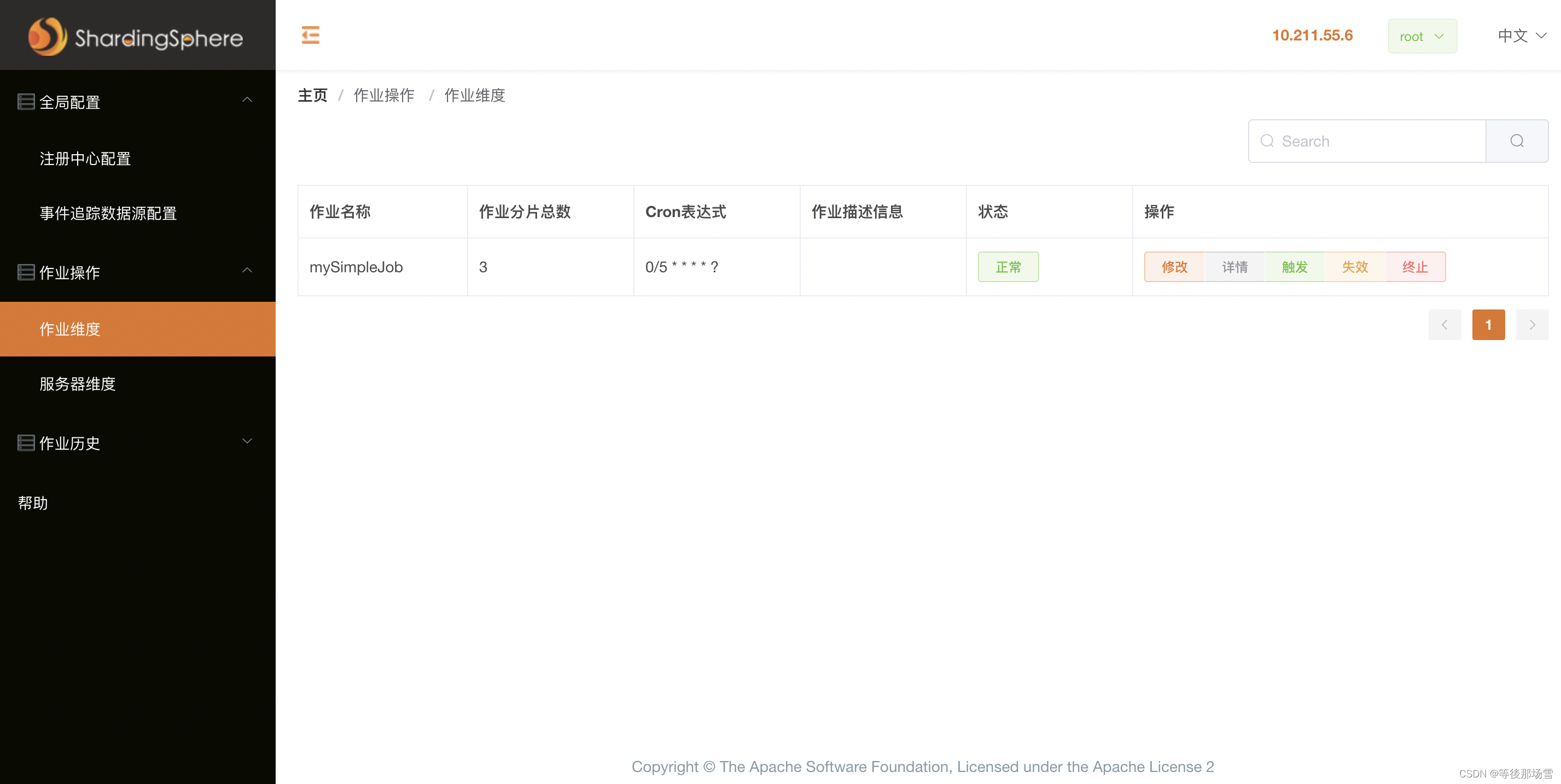
UI工具
使用 ElasticJob UI,界面如下: