本文是一个关于Python numpy的基础学习教程,其中,Python版本为Python 3.x
什么是Numpy
Numpy = Numerical + Python,它是Python中科学计算的核心库,可以高效的处理多维数组的计算。并且,因为它的许多底层函数是用C语言编写的,所以运算速度敲快。
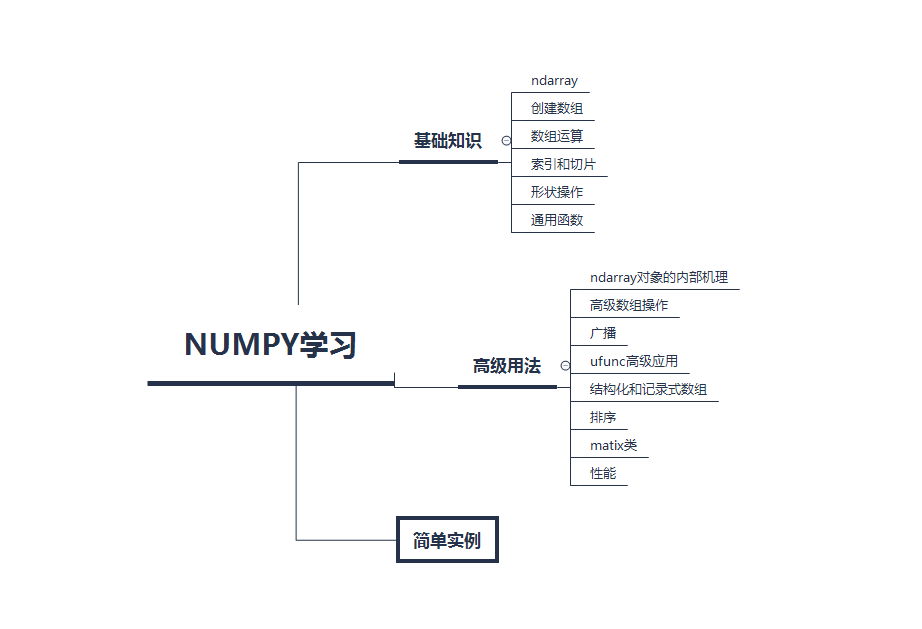
基础知识
ndarray
NumPy的主要对象是同类型的多维数组ndarray。它是一个通用的同构数据多维容器,所有的元素必须是相同类型的,并通过正整数元组索引。利用该对象可以对整块数据执行一些数学运算,语法和标量元素之间的运算一样。在NumPy中,维度称为轴,轴的数目为rank。
介绍一下ndarray常用的属性:
- ndarray.shape:表示各个维度中数组的大小,是一个整数的元组
- ndarray.dtype:描述数组中元素类型的对象
- ndarray.ndim:数组中轴的个数
- ndarray.size:数组元素的总数
- ndarray.itemsize:数组中每个元素的字节大小
创建数组
创建数组通常有5种方式:
1. 由Python结构(list, tuple等)转换
创建数组最简单的办法就是使用array对象,它可以接受任何序列型的对象,然后产生一个新的含有传入数据的numpy数组(ndarray)。
举个最简单的例子:
import numpy as np
a = np.array([1, 2, 3])
print(a)
print(a.dtype)
print(a.shape)
2. 使用Numpy原生数组创建(arange, ones,zeros等)
如:
b = np.zeros(10)
c = np.ones((1, 2))
3. 从磁盘读取数组
使用np.load方法读取数据。
4. 使用字符串或缓冲区从原始字节创建数组
5. 使用特殊库函数(random等)
索引和切片
基础操作
一维数组中的索引表面看起来和Python list的功能差不多。
对于切片而言,当你将一个标量值赋值给一个切片时,该值会自动传播到整个选区,跟Python list最重要的区别在于:Numpy中数组的切片作用的是原始数据的视图,也就是数据没有被复制,所有的修改都会直接作用到源数据。这是因为,Numpy设计之初就是为了处理大数据,将数据复制来复制去自然会产生很多性能问题。如果你想要得到一份数据副本,就需要显式的使用.copy()方法。
举个例子:
arr = np.arange(10)
print(arr)
print(arr[0])
print(arr[1:6])
arr_slice = arr[1:6]
arr_slice[1:3] = 5
print(arr_slice)
print(arr)
arr_copy = arr[1:6].copy()
arr_copy[1:3] = 6
print(arr_copy)
print(arr)
对于多维数组,各索引位置上的元素不再是标量,而是数组,可以传入一个以逗号隔开的索引列表来访问单个元素。其它操作和一维数组相同。
举个例子:
arr_2d = np.array([[1, 2, 3], [2, 3, 4], [3, 4, 5]])
print(arr_2d[0])
print(arr_2d[0, 1])
arr_2d_slice = arr_2d[1]
print(arr_2d_slice)
arr_2d_slice[0] = 1
print(arr_2d_slice)
print(arr_2d)
切片索引
ndarray的切片语法和Python list类似,对于高维对象,花样比较多,可以在一个或者多个轴进行切片,也可以跟整数索引混合使用(降低维度)。
举个例子:
arr_test = np.array([[1, 2, 3], [2, 3, 4], [3, 4, 5]])
print(arr_test[:2])
print(arr_test[:2, 1:])
print(arr_test[1, :1])
arr_slice_test = arr_test[:2, 1:]
arr_slice_test[0] = 0
print( arr_slice_test)
print(arr_test)
布尔型索引
通过布尔型索引,可以方便我们根据指定条件快速的检索数组中的元素。如果进行变量或者标定量的大数据处理,这种筛选功能的使用肯定会给程序的设计带来极大的便捷。
举个简单例子:
In [1]: import numpy as np
In [2]: x = np.array([[0, 1], [2, 3], [3, 4]])
In [3]: x
Out[3]:
array([[0, 1],
[2, 3],
[3, 4]])
In [4]: x > 2
Out[4]:
array([[False, False],
[False, True],
[ True, True]])
In [5]: x[ x > 2] = 0
In [6]: x
Out[6]:
array([[0, 1],
[2, 0],
[0, 0]])
并且,可以结合使用ndarray的统计方法来对布尔型数组中的True值进行计数,常见有三种方法:
- sum():对True值进行计数
- any():测试数组中是否存在一个或者多个True
- all():检查数组中的所有值是否都是True
花式索引
花式索引(Fancy indexing)是一个Numpy的术语,指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
举个例子:
In [1]: import numpy as np
In [2]: array = np.empty((4, 3))
In [3]: for i in range(4):
...: array[i] = i
...:
In [4]: array
Out[4]:
array([[0., 0., 0.],
[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.]])
In [5]: array[[1, 3]]
Out[5]:
array([[1., 1., 1.],
[3., 3., 3.]])
In [6]: array[[-1, -3]]
Out[6]:
array([[3., 3., 3.],
[1., 1., 1.]])
In [7]: array[np.ix_([3, 0],[2, 1])]
Out[7]:
array([[3., 3.],
[0., 0.]])
形状操作
形状转换
介绍几个常见的修改数组形状的方法:
-
reshape():不改变原始数据的情况下修改数组
-
flat():一个数组元素的迭代器,可以处理数组元素中的每个数据
-
flatten():返回一份数组拷贝,对拷贝所做的处理不会影响原始数组,格式为.flatten(order=''),其中order='C'表示按行展开,'F'表示按列,'A'表示原顺序,'K'表示元素在内存中的出现顺序。
-
ravel():展平的数组元素,顺序通常是"C风格",返回的是数组视图,修改会影响原始数组。
该函数接收两个参数:
举个例子:
arr = np.arange(12)
print(arr)
arr1 = arr.reshape(3, 4)
for item in arr1:
print(item)
for item in arr1.flat:
print(item)
print(arr1.flatten())
print(arr1.flatten(order="K"))
arr.flatten()[10] = 0
print(arr)
print(arr.ravel())
arr.ravel()[10] = 0
print(arr)
转置与轴对换
介绍常见的几种方法:
- ndarray.T:转置
- transpose: 对换数组的维数
- rollaxis: 向后滚动指定的轴
- swapaxes:用于交换数组的两个轴
转置是数据重塑的一种特殊形式,返回了源数据的视图。简单的转置可以使用.T,也可以使用transpose方法和swapaxes。
举个例子:
arr = np.arange(12).reshape((2, 2, 3))
print(arr)
print(arr.T)
print(arr.transpose((1, 0, 2)))
print(arr.swapaxes(1, 2))
通用函数:快速的元素级数组函数
通用函数(ufunc)是一种对ndarray中的数据执行元素级运算的函数,可将其分为一元和二元进行说明。
一元func
一元func可看做是简单的元素级变体,比如sqrt和cos,举个例子:
arr = np.arange(10)
print(np.sqrt(arr))
print(np.square(arr))
二元func
接受2个数组,然后返回一个结果数组,比如add和mod,举个例子:
arr1 = np.arange(10)
arr2 = np.arange(10)
print(np.add(arr1, arr2))
更多函数去官方文档查阅,哈哈,这里就不赘述了。
数组运算
基础运算
在Numpy中,可以利用ndarray对整块数据执行一些数学运算,语法和普通的标量元素之间的运算一样。其中,数组与标量的运算会将标量作用于各个数组元素。
举个例子:
i = np.array([[1, 2], [3, 4]])
j = np.array([[5, 6], [7, 8]])
print(i + j)
print(i - j)
print(i - 1)
print(i * j)
print( i / j)
以上,乘法并不同于矩阵乘法,若需进行矩阵相乘,可使用:
i = np.array([[1, 2], [3, 4]])
j = np.array([[5, 6], [7, 8]])
print(j.dot(i))
除此之外,Numpy还提供了以下常用统计方法:
- min():数组最小值
- max():数组最大值
- sum():数组元素相加
- cumsum():计算轴向元素累加和,返回由中间结果组成的数组
- cumprod():所有元素的累计积
数组表达式
编写数组表达式处理多个数组数据也是很便捷高效的,举个例子:假设我们想要在一组值(网格型)上计算函数sqrt(x^2 + y^2),使用np.mashgrid函数接受两个一维数组,产生两个二维矩阵:
In [1]: import numpy as np
In [2]: points = np.arange(-5, 5, 0.01)
In [3]: x, y = np.meshgrid(points, points)
In [4]: x
Out[4]:
array([[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
...,
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99]])
In [5]: z = np.sqrt(x ** 2 + y ** 2)
In [6]: z
Out[6]:
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]])
条件筛选
介绍几个常见的筛选方法:
- where:返回输入数组中满足给定条件的元素的索引
- .argmax() 和 numpy.argmin()函数分别沿给定轴返回最大和最小元素的索引
- nonzero() 函数返回输入数组中非零元素的索引。
实例
接下来,使用Numpy来模拟随机漫步操作下数组运算。
首先,实现一个很简单的1000步的随机漫步,从0开始,随机生成1和-1,判断随机漫步过程中第一次到达某个值(暂定为8)的时间(步数),实现:
import numpy as np
nsteps = 1000
draws = np.random.randint(0, 2, size=nsteps)
steps = np.where(draws > 0, 1, -1)
# 各步的累计和
walk = steps.cumsum()
# 第一次到达8的时间
walk_8 = (np.abs(walk) >= 8).argmax()
print(walk_8)