就像人和人交流时先会喊对方的名字一样,关键词就好比智能设备的"名字",而关键词检测模块则相当于交互流程的触发开关。
本文介绍魔搭社区中远场语音增强与唤醒一体化的语音唤醒模型的构成、体验方式,以及如何基于开发者自有数据进行模型的定制。
▏远场唤醒模型它能做什么?
关键词检测(keyword spotting, KWS)即我们通常所说的语音唤醒,指的是一系列从实时音频流中检测出若干预定义关键词的技术。随着远讲免提语音交互(distant-talking hands free speech interaction)技术的发展,关键词检测及其配套技术也变得越来越重要。
为了应对远讲免提语音交互过程中所出现的设备回声、人声干扰、环境噪声、房间混响等诸多不利声学因素的影响,关键词检测通常需要配合语音增强来使用。
我们基于盲源分离(blind source separation, BSS)统一框架的语音增强算法,将去混响、回声消除以及声源的分离问题都统一到了盲源分离的理论框架中,从而实现了目标函数和优化方法的统一,达到联合优化的目的[1]。
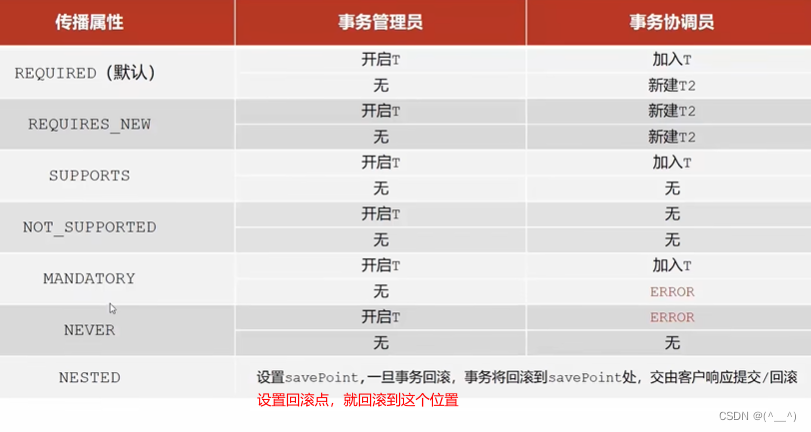
远场语音增强和关键词检测的系统框架图如图1所示,其中x为麦克风信号,r为参考信号,y为增强后的音频,n'为送往云端用于后续交互流程的通道序号。在有的应用中,还存在从关键词检测到语音增强算法的反馈机制,例如图1中的p为关键词存在概率,该信息可以更好的指导语音增强算法进行降噪处理。
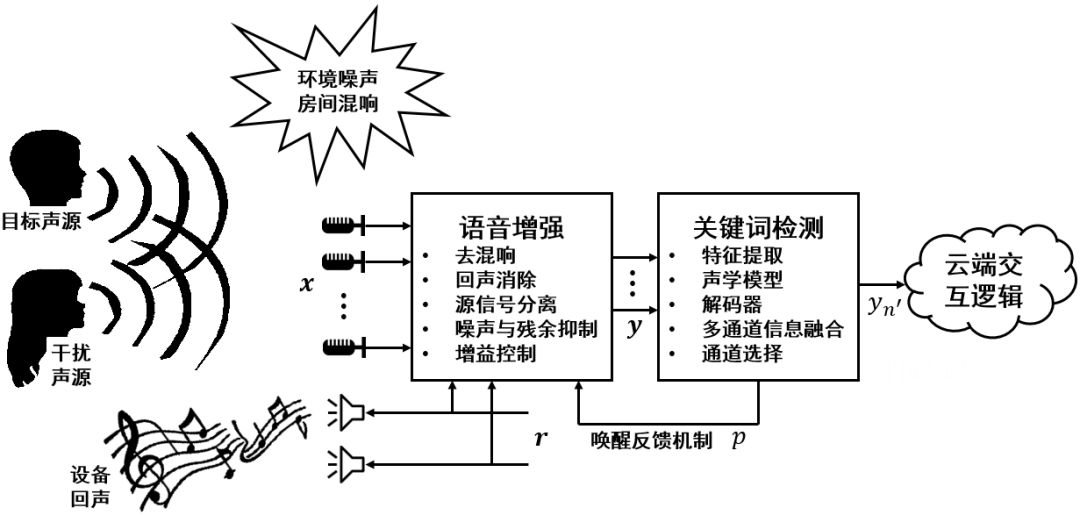
图1 系统框架图
从图1中的系统框架也可以看出,由于语音增强算法通常会输出多通道的增强后的信号,所以,针对远场应用的关键词检测算法需要具备处理多通道信息的能力。同时,由于目前主流的云端语音识别应用只支持单通道的音频,所以关键词检测算法还需要具备选出用于云端交互的最佳通道的能力,即选出包含关键词语音质量最好的通道。另外,为了提升关键词模型的性能,在模型训练过程中还需要做到语音信号处理与关键词检测的匹配训练。
声学模型是关键词检测系统中最重要的部分。本开源项目中使用基于FSMN(feedforward sequential memory network)的网络结构,如图2所示。模型的输入为多通道特征,而输出为各个建模单元的观测概率。图中的建模单元ABCD分别代表四个汉字,而Filler则代表非关键词音频。整个模型由若干层FSMN单元叠加而成,在其中的某个(本项目中为最后一个)FSMN单元之后的max pooling操作用于将多通道信息进行融合,同时根据最大值的选择结果来确定最佳通道序号[2]。
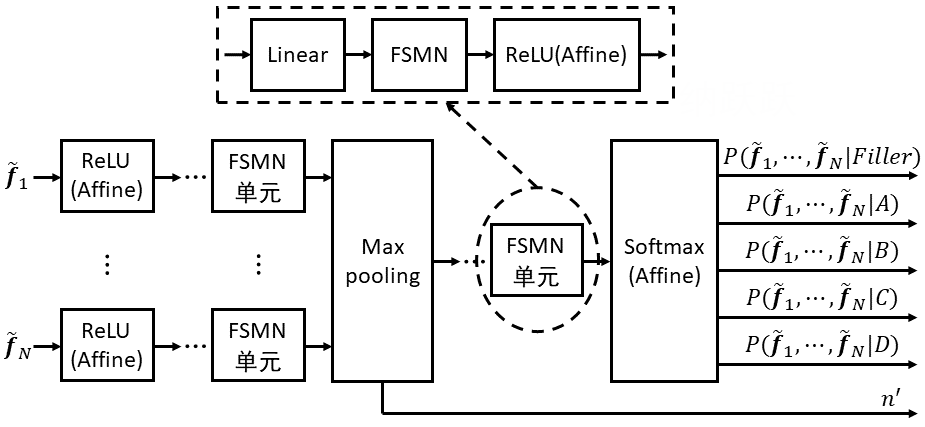
图2 多通道关键词检测模型网络结构示意图。
▏如何快速体验远场唤醒模型效果?
在线体验
在ModelScope官网的模型页面上可直接在线体验模型效果。体验界面在页面右侧,可以在“测试内容”栏内看到我们预先准备的一段唤醒音频,点击播放按钮可以试听,音频中音乐声较大,唤醒词“你好米雅”声音较小,前三次大约在第5秒、第8秒、第11秒左右,需要仔细分辨才能听得出。可以直接点击“执行测试”按钮,在下方“测试结果”中查看模型唤醒结果。
测试音频:
从强音乐背景噪音中获取唤醒词 音频
您也可以点击“录音”按钮,利用浏览器录制一段音频来测试。由于浏览器本身的限制,无法录制麦克风阵列和参考信号,所以唤醒效果会受较大影响仅做演示。
如果想测试真实设备录制的多通道音频,请参考下一节“在Notebook中使用”。
在ModelScope网站上轻松找到唤醒模型和在线体验的过程:
视频
在Notebook中使用
对于有开发需求的使用者,特别推荐您使用Notebook进行离线处理,具体使用方式请参考视频演示。
视频
登录ModelScope账号,点击模型页面右上角的“在Notebook中打开”按钮出现对话框。首次使用会提示您关联阿里云账号,按提示操作即可。
如果您有多个音频文件要处理,可以循环调用kws对象:
from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Taskskws = pipeline(Tasks.keyword_spotting,model='damo/speech_dfsmn_kws_char_farfield_16k_nihaomiya')your_wav_list = ['/data/file1.wav', '/data/file2.wav']for wav_file in your_wav_list:result = kws(wav_file)print(result)
▏如何更换唤醒词训练自有的唤醒模型?
进行模型训练
我们封装了ModelScope的模型训练能力,再增加数据处理,效果评测,流程控制等辅助功能,连同一些相关工具打包成唤醒模型训练套件,已经在Github上开源,欢迎有兴趣的开发者试用:
https://github.com/alibaba-damo-academy/kws-training-suite
为了达到更好的唤醒效果,训练套件默认会做两轮训练和评测。第一轮训出的模型根据评测结果选出最优的模型作为基础,第二轮再继续finetune。大致流程如下图所示,更多详细信息请参考训练套件说明文档。
数据准备
训练需要的数据大致分如下几类,格式除特殊说明外要求为采样率16000Hz的单声道PCM编码.wav文件。
-
带标注的唤醒词音频
-
负样本音频
-
噪声音频(单通道/多通道)
针对其中负样本音频和单通道噪声音频,训练套件内提供了自动下载开源数据的功能,用户只要准备带标注的唤醒词音频就可以启动训练啦。
唤醒词音频文件,通常是众包采集的背景安静,发音清晰的唤醒词语音。
数据量至少需要 100 人 * 100 句 = 10000条数据,每一条单独保存一个文件。数据量越多越好,总数据量相同的情况下,人数越多越好。数据打标可以通过人工,也可以利用训练套件中提供的force align工具,详见说明。
搭建环境
硬件配置:
-
64 CPU 48G内存 ——此为推荐值,配置越高训练越快
-
1 GPU(Tesla P4或以上) 8G显存
-
400G存储空间
以上配置支持60个线程并发,整个训练流程约耗时4天。
软件要求:
推荐使用ModelScope提供的docker镜像,上面已经预装好了模型训练所需的Python环境和ModelScope框架。
# CPU版本:registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-py37-torch1.11.0-tf1.15.5-1.1.0# GPU版本:registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py37-torch1.11.0-tf1.15.5-1.1.0
进入docker环境后只需再安装几个测试时要用到的库,环境就准备好了。
apt-get updateapt-get install unzipapt-get install openjdk-11-jdk
配置和运行
训练配置项和说明参见源码中的HOW_TO_CONFIG.md
配置完成后可进入kws-training-scripts目录,运行以下命令:
# 通过设置环境变量指定希望使用的GPU的id序号,从 0 开始export CUDA_VISIBLE_DEVICES=gpu_id# config.yml 为训练配置文件# --remote_dataset 指定需要下载第三方开源数据集# /data/open_dataset 是用户指定的数据集存放目录,需要至少300G磁盘空间# 程序支持断点续传和智能判断,之前已经下载过的话不会重复下载python pipeline.py config.yml --remote_dataset /data/open_dataset
运行步骤和产物
-
检查数据,生成最终训练配置
-
训练阶段,实时读取原始数据,生成训练数据,训练模型,每轮生成的模型checkpoint保存成.pth文件,放在$work_dir/first,默认训练500轮
-
训练完毕后,从所有模型checkpoint中挑选loss最小的一批(约20%),转换为推理格式.txt文件,保存在$work_dir/first_txt
-
每个模型都用测试集测试各场景唤醒率和误唤醒率,汇总结果存放在$work_dir/first_roc,详细结果存放在$work_dir/first_roc_eval
-
综合唤醒率和误唤醒率结果对模型进行排序后存放在$work_dir/first_roc_sort
-
给出排序第一名的模型:第一轮和第二轮产物相同,第一轮存放路径前缀为first,第二轮为second
测试您的模型
首先复制一份唤醒工具配置文件。
# 以下命令仍然都在唤醒套件目录下运行# 复制唤醒工具配置cp /your/test_dir/tmp.conf .
手工修改配置文件中的唤醒模型路径,指向上面生成的模型参数文件(.txt),例如:
# 唤醒模型路径。kws_model_base = /your/test_dir/second_txt/top_01_checkpoint_0399_loss_train_0.1136_loss_val_0.1098.txt
运行唤醒工具,参数分别为配置文件,测试音频,处理后的输出音频。
输出的字段含义为:
-
detected x 中x表示唤醒id
-
kw表示唤醒词
-
spot, bestend, duration都是唤醒时间信息
-
confidence是置信度
-
bestch是通道选择信息
./bin/SoundConnect ./tmp.conf test.wav ./output.wav# 以下为输出[detected 0], kw: 0_xiao_ai_tong_xue, spot: 13.219999, bestend: 13.219999, duration: [12.139999-12.940000], confidence: 0.926316, bestch: 0[detected 1], kw: 0_xiao_ai_tong_xue, spot: 31.699999, bestend: 31.699999, duration: [30.660000-31.420000], confidence: 0.914814, bestch: 0[detected 2], kw: 0_xiao_ai_tong_xue, spot: 40.899998, bestend: 40.899998, duration: [39.899998-40.619999], confidence: 0.853534, bestch: 0
▏远场语音唤醒的典型应用场景与案例
语音唤醒模型训练完成以后,还需要经过推理加速和系统集成等工程化工作才能在真实的产品中使用起来。
有别于AI数据中心等大规模、高算力场景,远场唤醒和声学前端所处的 Tiny 方向则聚焦于低功耗、高性价比等特性,需要充分利用软硬一体的加速技术。以语音唤醒为例,采用蒸馏和裁剪等模型训练压缩、基于 TVM 的神经网络编译图优化、RISC-V 指令集以及语音领域相关的工程实践。在2022年AI基准测试 MLPerf™ Tiny Benchmark 的嵌入式语音唤醒场景中,我们提交的方案较好地平衡了推理任务中的准确率与延时,保证准确率90.7%最高的情况下耗时最短,具体细节可参考技术文章。软硬一体联合优化技术,让回声消除、盲源分离、语音降噪和语音唤醒等高复杂度端侧语音AI前沿算法,在资源极致严苛的嵌入式芯片上得以实现,算法内存开销低至1M字节,运行功耗低于100mW,从而可以为客户整机降低一半以上的模组成本,并依然保持高性能的算法体验。
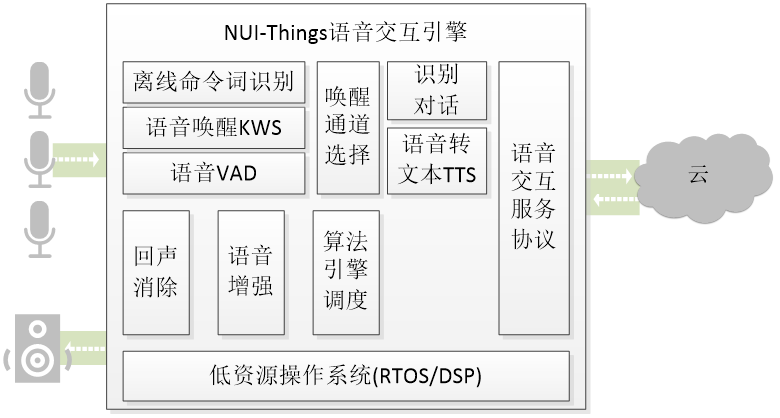
为了帮助客户快速的将语音唤醒模型部署到实际硬件产品中,我们提供完整的软件部署方案-NUI Things智能语音交互引擎,该引擎具备丰富的工程实践,已落地音箱、故事机、电动两轮车/四轮车、行车记录仪、扫地机等多型智能化设备。引擎既包括语音增强和唤醒等端侧算法、算法加速和上云服务等通用功能,也具有语音交互逻辑调度、平台定制化优化等特有功能,同时具备低资源、支持异构系统等特点。通过一键引入的功能,客户定制的唤醒模型可以便捷的导入到引擎中,降低繁杂的工程部署工作,同时获得高性能、高稳定性的完整端侧语音AI产品化能力,让开发、迭代到应用的路径变得更加高效。