- 获取pdf:密码7281
文章目录
- 一:数据集介绍
- 二:GAN简介
- (1)简介
- (2)损失函数
- 三:代码编写
- (1)参数及数据预处理
- (2)生成器与判别器模型
- (3)优化器和损失函数
- (4)训练
- 三:效果查看
- (1)tensorboard
- (2)生成图片效果
一:数据集介绍
MNIST数据集:MNIST是个手写数字图片集,每张图片都做了归一化处理,大小是28x28,并且是灰度图像,所以每张图像格式为1x28x28
- 数据集下载地址
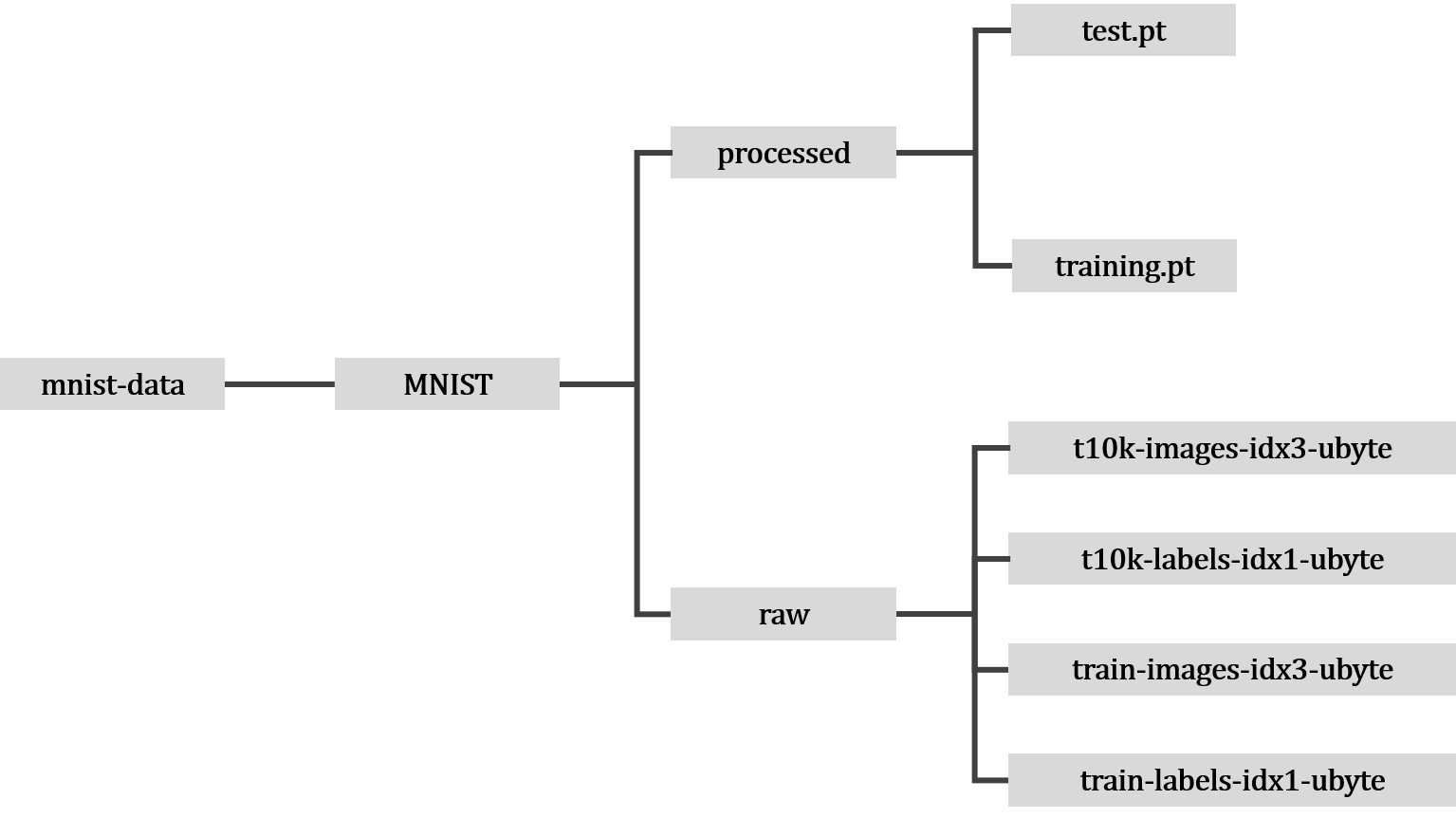
包括如下四个文件

含义如下
| 类别 | 文件名 | 描述 |
|---|---|---|
| 训练集图片 | train-images-idx3-ubyte.gz(9.9M) | 包含60000个样本 |
| 训练集标签 | train-labels-idx1-ubyte.gz(29KB) | 包含60000个标签 |
| 测试集图片 | t10k-images-idx3-ubyte.gz(1.6M) | 包含10000个样本 |
| 测试集标签 | t10k-labels-idx1-ubyte.gz(5KB) | 包含10000个样本 |
当然torchvision.datasets中也内置了这个数据集,可以通过如下代码从网络上下载
train_data = dataset.MNIST(root='./mnist/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = dataset.MNIST(root='./mnist/',
train=False,
transform=transforms.ToTensor(),
download=False)
root:表示数据集待存放的目录train:如果为true将会使用训练集的数据集(training.pt),如果为false将会使用测试集数据集(test.pt)download:如果为true将会从网络上下载并放入root中,如果数据集已下载则不会再次下载transform:接受PIL图片并返回转换后的图片,常用的就是转换为tensor(这里便会调用torchvision.transform)
数据集加载成功后,文件布局如下
二:GAN简介
(1)简介
GAN(Generative Adversial Nets,生成式对抗网络):这是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型有两个模型:生成模型(Generative Model)和辨别模型(Discriminative Model)的互相博弈学习产生相当好的输出。实际使用时一般会选择DNN作为G和D
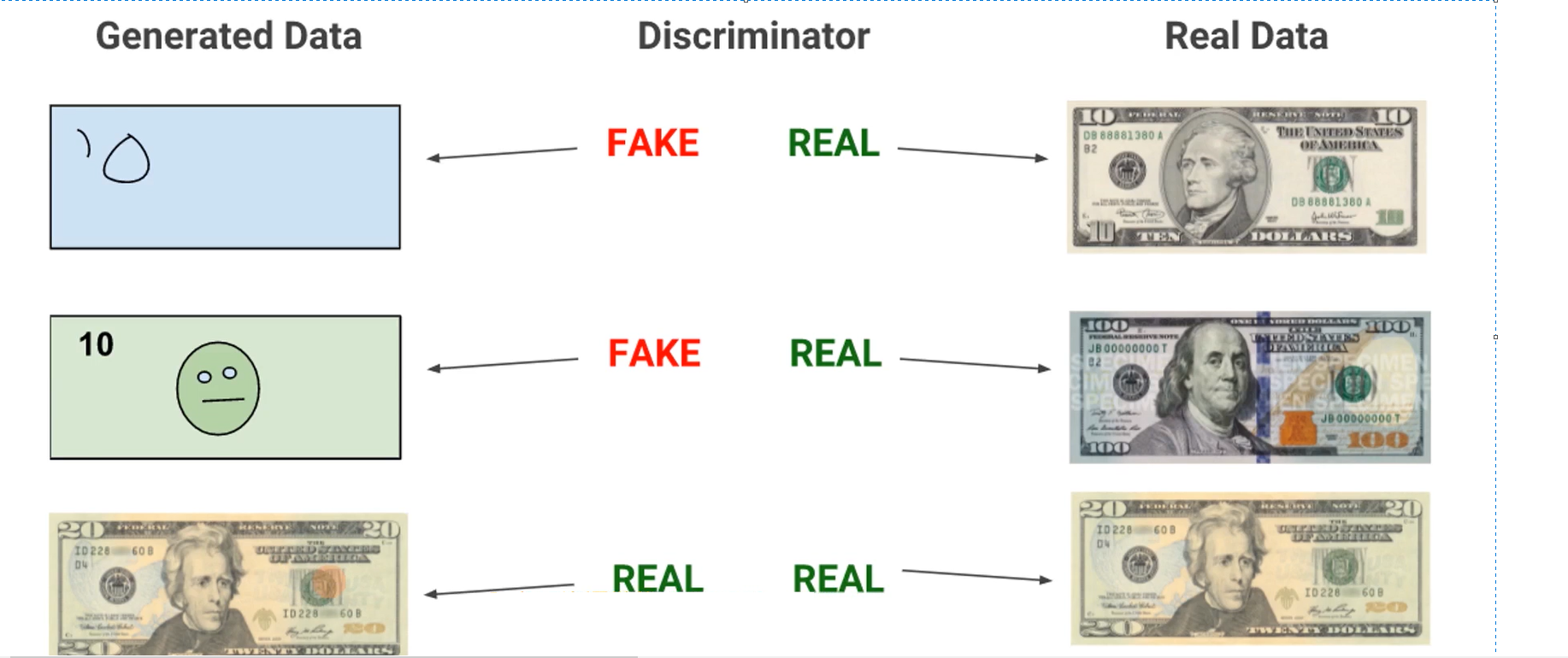
如下图,以论文中所述的制作假钞的例子为例进行说明
- 生成模型G的目的是尽量能够生成足以以假乱真的假钞去欺骗判别模型D,让它以为这是真钞
- 判别模型D的目的是尽量能够鉴别出生成模型G生成的假钞是假的
(2)损失函数
GAN损失函数如下

其中参数含义如下
- x x x:真实的数据样本
- z z z:噪声,从随机分布采集的样本
- G G G:生成模型
- D D D:判别模型
- G ( z ) G(z) G(z):输入噪声生成一条样本
- D ( x ) D(x) D(x):判别真实样本是否来自真实数据(如果是则为1,如果不是则为0)
- D ( G ( z ) ) D(G(z)) D(G(z)):判别生成样本是否来自真实数据(如果是则为1,如果不是则为0)
该损失函数整体分为两个部分
第一部分:给定 G G G找到使 V V V最大化的 D D D,因为使 V V V最大化的 D D D会使判别器效果最好
- 对于①:判别器的输入为真实数据 x x x, E x ∼ p d a t a [ l o g D ( x ) ] E_{x}\sim p_{data}[logD(x)] Ex∼pdata[logD(x)]值越大表示判别器认为输入 x x x为真实数据的概率越大,也即表示判别器的能力越强,所以这一项输出越大对判别器越有利
- 对于②:判别器的输入伪造数据 G ( z ) G(z) G(z),此时 D ( G ( z ) ) D(G(z)) D(G(z))越小那么就表示判别器将此伪造数据鉴别为真实数据的概率也越小,也即表示判别器的能力越强。注意此时第二项是 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))的期望 E x ∼ p d a t a [ l o g ( 1 − D ( G ( z ) ) ) ] E_{x}\sim p_{data}[log(1-D(G(z)))] Ex∼pdata[log(1−D(G(z)))]。所以当判别器能力越强时, D ( G ( z ) ) D(G(z)) D(G(z))越小同时 E x ∼ p d a t a [ l o g ( 1 − D ( G ( z ) ) ) ] E_{x}\sim p_{data}[log(1-D(G(z)))] Ex∼pdata[log(1−D(G(z)))]也就越大
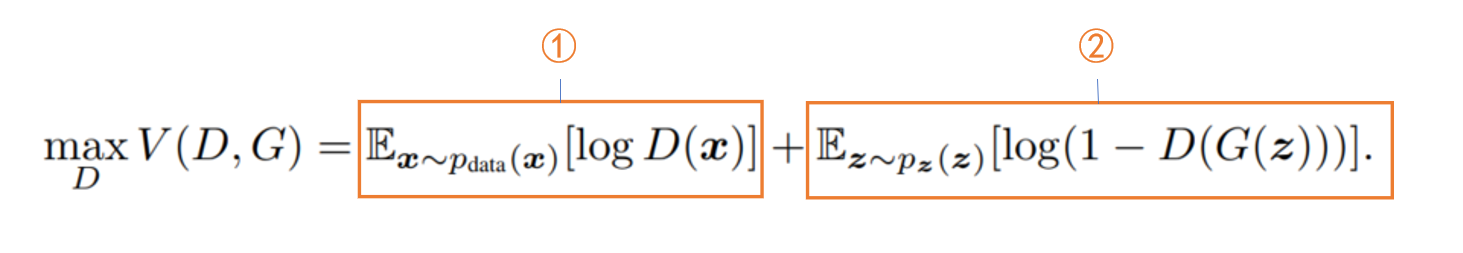
第二部分:给定 D D D找到使 V V V最小化的 G G G,因为使 V V V最小化的 G G G会使生成器效果最好
- 对于①:由于固定了 D D D,而这一部分只和 D D D有关,因此这一部分是常量,所以可以舍去
- 对于②:判别器的输入伪造数据 G ( z ) G(z) G(z),与上面不同的是,我们期望生成器的效果要好,尽可能骗过辨别器,所以 D ( G ( z ) ) D(G(z)) D(G(z))要尽可能大( D ( G ( z ) ) D(G(z)) D(G(z))越大表示辨别器鉴定此数据为真实数据的概率越大), E x ∼ p d a t a [ l o g ( 1 − D ( G ( z ) ) ) ] E_{x}\sim p_{data}[log(1-D(G(z)))] Ex∼pdata[log(1−D(G(z)))]也就越小
三:代码编写
(1)参数及数据预处理
# 设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
print("GPU上运行")
else:
print("CPU上运行")
# 图片格式
img_size = [1, 28, 28]
# batchsize
batchsize = 64
# latent_dim
latent_dim = 100
# 数据集及变化
data_transforms = transforms.Compose(
[
transforms.Resize(28),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
]
)
dataset = torchvision.datasets.MNIST(root='~/autodl-tmp/dataset', train=True, download=False, transform=data_transforms)
(2)生成器与判别器模型
# 生成器模型
"""
根据输入生成图像
"""
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, np.prod(img_size, dtype=np.int32)),
nn.Tanh()
)
def forward(self, x):
# [batchsize, latent_dim]
output = self.model(x)
image = output.reshape(x.shape[0], *img_size)
return image
# 判别器模型
"""
判别图像真假
"""
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear( np.prod(img_size, dtype=np.int32), 512),
nn.ReLU(inplace=True),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 1),
nn.ReLU(inplace=True),
nn.Sigmoid(),
)
def forward(self, x):
# [batch_size, 1, 28, 28]
x = x.reshape(x.shape[0], -1)
output = self.model(x)
return output
(3)优化器和损失函数
# 优化器和损失函数
generator = Generator()
generator = generator.to(device)
discriminator = Discriminator()
discriminator = discriminator.to(device)
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0001)
loss_func = nn.BCELoss()
(4)训练
def train():
step = 0
dataloader = DataLoader(dataset=dataset, batch_size=batchsize, shuffle=True, drop_last=True, num_workers=8)
for epoch in range(1, 100):
print("-----------当前epoch:{}-----------".format(epoch))
for i, batch in enumerate(dataloader):
print("-----------当前batch:{}/{}-----------".format(i, (len(dataloader))))
# 拿到真实图片
X, _ = batch
X = X.to(device)
# 采用标准正态分布得到的batchsize × latent_dim的向量
z = torch.randn(batchsize, latent_dim)
z = z.to(device)
# 送入生成器生成假图片
pred_X = generator(z)
g_optimizer.zero_grad()
"""
生成器损失:
让生成的图像与通过辨别器与torch.ones(batchsize, 1)越接近越好
"""
g_loss = loss_func(discriminator(pred_X), torch.ones(batchsize, 1).to(device))
g_loss.backward()
g_optimizer.step()
d_optimizer.zero_grad()
"""
辨别器损失:
一方面让真实图片通过辨别器与torch.ones(batchsize, 1)越接近越好
另一方面让生成图片通过辨别器与torch.zeros(batchsize, 0)越接近越好
"""
d_loss = 0.5 * (loss_func(discriminator(X), torch.ones(batchsize, 1).to(device)) + loss_func(discriminator(pred_X.detach()), torch.zeros(batchsize, 1).to(device)))
d_loss.backward()
d_optimizer.step()
print("生成器损失{}".format(g_loss), "辨别器损失{}".format(d_loss))
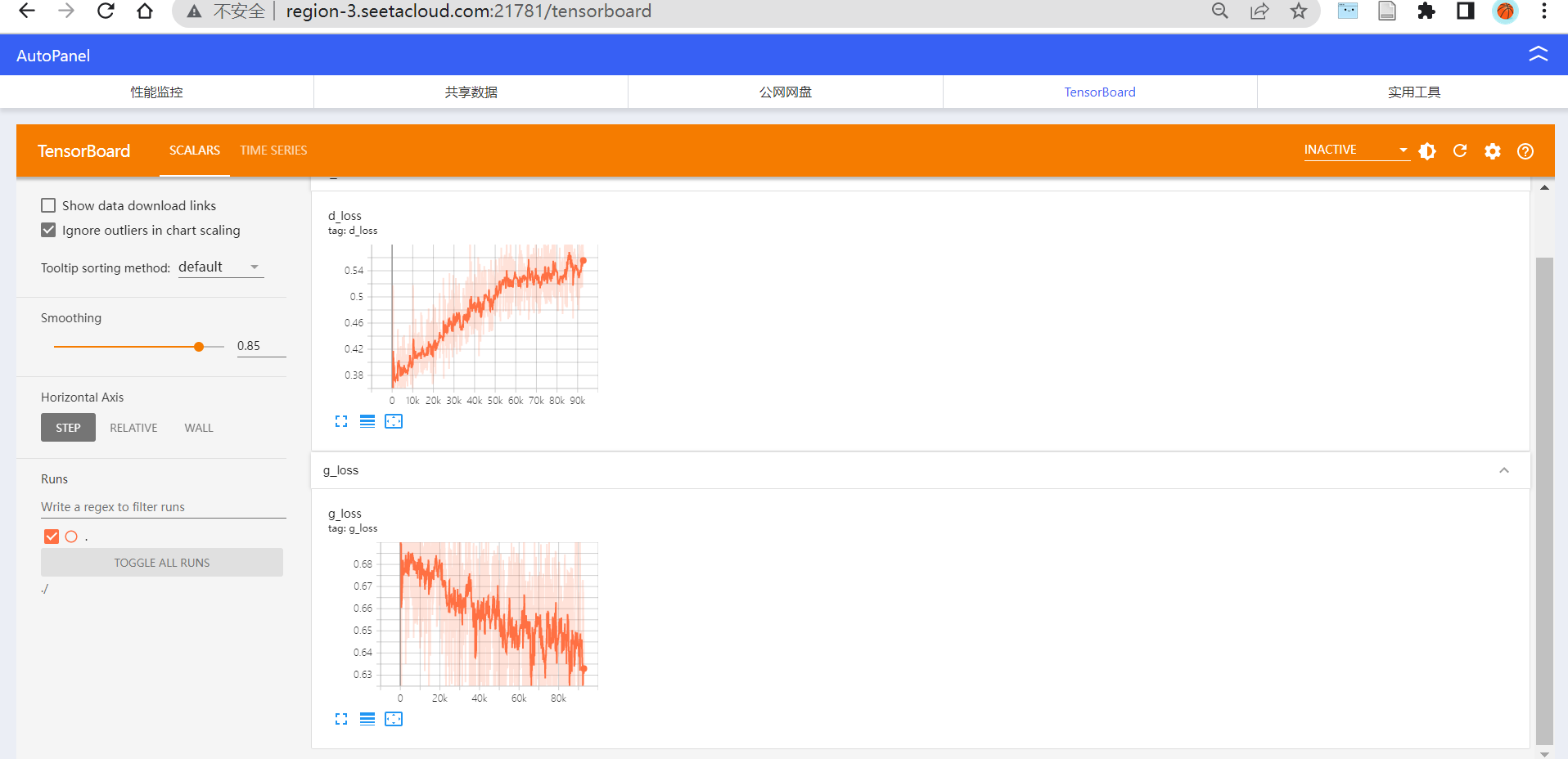
logger.add_scalar('g_loss', g_loss, step)
logger.add_scalar('d_loss', d_loss, step)
step = step+1
if step % 1000 == 0:
save_image(pred_X.data[:25], "./image_save/image_{}.png".format(step), nrow=5)
三:效果查看
(1)tensorboard
(2)生成图片效果
每1000个step保存一次照片,最后生成了92张图片,每张图片由每个batch的前25张图片构成
1000-step

5000-step

10000-step

20000-step

30000-step

50000-step

70000-step

80000-step

90000-step

920000-step(final)









![[Android开发基础4] 意图与意图过滤器](https://img-blog.csdnimg.cn/38bd5d4445c043c4bc2b486d2ca4c82d.png)