#Linux查看性能相关命令
##CPU性能
###/cat/proc/cpuinfo
这个文件能够获取到物理cpu的数量,每个物理cpu的核心数,是否开启超线程等信息
物理cpu: 表示主板上实际存在的cpu数量
cpu核数: 单个cpu上可以处理数据的芯片组数量,如双核,四核等
逻辑cpu数量:
一般来说,
逻辑CPU = 物理CPU数 × 核心数 # 不支持超线程技术
逻辑CPU = 物理CPU数量 × 每个CPU核心数量 * 2 # 表示服务器的CPU支持超线程技术(简单来说就是可以让处理器中的1个核心成为操作系统中的2个核心。这样,操作系统可用的执行资源翻了一番,大大提高了系统的整体性能)
示例输出:
processor : 0 系统中逻辑处理核心的数量,
vendor_id : GenuineIntel cpu制造商
cpu family : 6 cpu产品系统代号
model : 79 cpu属于其系列中的那一代
model name : Intel(R) Xeon(R) CPU E5-26xx v4 cpu的名称及其编号
stepping : 1 CPU属于生产更新版本
microcode : 0x1
cpu MHz : 2394.454 实际CPU频率
cache size : 4096 KB cpu二级缓存的大小
physical id : 0 单个物理cpu标号
siblings : 2 单个物理cpu的逻辑cpu数量
core id : 0 当前所在cpu中的物理内核id
cpu cores : 2 逻辑核所在的cpu的物理内核数.
apicid : 0 用于区分不同逻辑核心的编号,系统中每个逻辑核编号必须不同,编号且不一定是连续的.
initial apicid : 0
fpu : yes 是否有浮点单元
fpu_exception : yes 支持支持浮点计算异常
cpuid level : 13 在执行cpuid指令之前,eax寄存器中的值会根据不同的值返回不同的内容
wp : yes 当前cpu是否支持内核态用户空间的写保护
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx lm constant_tsc rep_good nopl cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch pti bmi1 avx2 bmi2 rdseed adx xsaveopt
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds
bogomips : 4788.90 粗略测量的cpu速度每秒
clflush size : 64 每个flush缓存的大小单元
cache_alignment : 64 缓存地址对齐单元
address sizes : 40 bits physical, 48 bits virtual 可访问地址空间的数量
power management: 支持电源管理
常用的信息:
查看cpu个数:
cat /proc/cpuinfo | grep ‘physical id’ | ‘sort’| uniq |wc -l
查看每个物理cpu的核数:
cat /proc/cpuinfo | grep ‘cpu cores’ | sort |uniq | awk -F ‘:’ ‘{print $NF}’
查看逻辑cpu数
cat /proc/cpuinfo| grep ‘processor’|wc -l
###lscpu命令
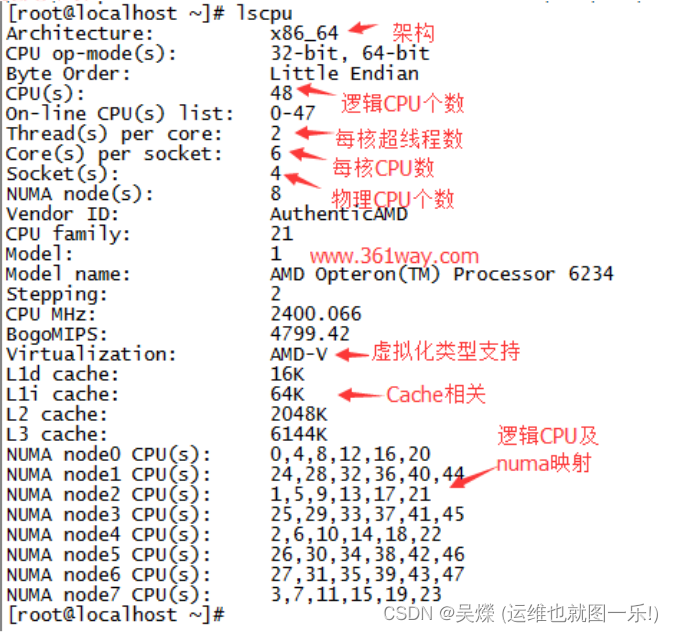
lscpu命令从sysfs和/proc/cpuinfo收集cpu体系结构,
语法:
lscpu [-a|-b|-c] [-x] [-s directory] [-e [=list]|-p [=list]]
lscpu -h|V
-a, –all: 包含上线和下线的cpu的数量,此选项只能与选项e或-p一起指定
-b, –online: 只显示出上线的cpu数量,此选项只 能与选项e或者-p一起指定
-c, –offline: 只显示出离线的cpu数量,此选项只能与选项e或者-p一起指定
-e, –extended [=list]: 以人性化的格式显示cpu信息,如果list参数省略,输出所有可用数据的列,在指定了list参数时,选项的字符串、等号(=)和列表必须不包含任何空格或其他空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’
-h, –help:帮助
-p, –parse [=list]: 优化命令输出,便于分析.如果省略list,则命令的输出与早期版本的lscpu兼容,兼容格式以两个逗号用于分隔cpu缓存列,如果没有发现cpu缓存,则省略缓存列,如果使用list参数,则缓存列以冒号(:)分隔。在指定了list参数时,选项的字符串、等号(=)和列表必须不包含空格或者其它空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’
-s, –sysroot directory: 为一个Linux实例收集CPU数据,而不是发出lscpu命令的实例。指定的目录是要检查Linux实例的系统根
-x, –hex:使用十六进制来表示cpu集合,默认情况是打印列表格式的集合(例如:0,1)
###mpstat
mpstat (multiprocessor state) 可以查看所有cpu的平均负载,也可以查看指定cpu的负载。所以mpstat其实就是主要查看CPU负载的一个工具。是一款常用的多核CPU性能分析工具,用来实时查询每个CPU的性能指标,以及所有CPU的平均指标。
yum install -y sysstat #安装mpstat命令软件

命令回显:
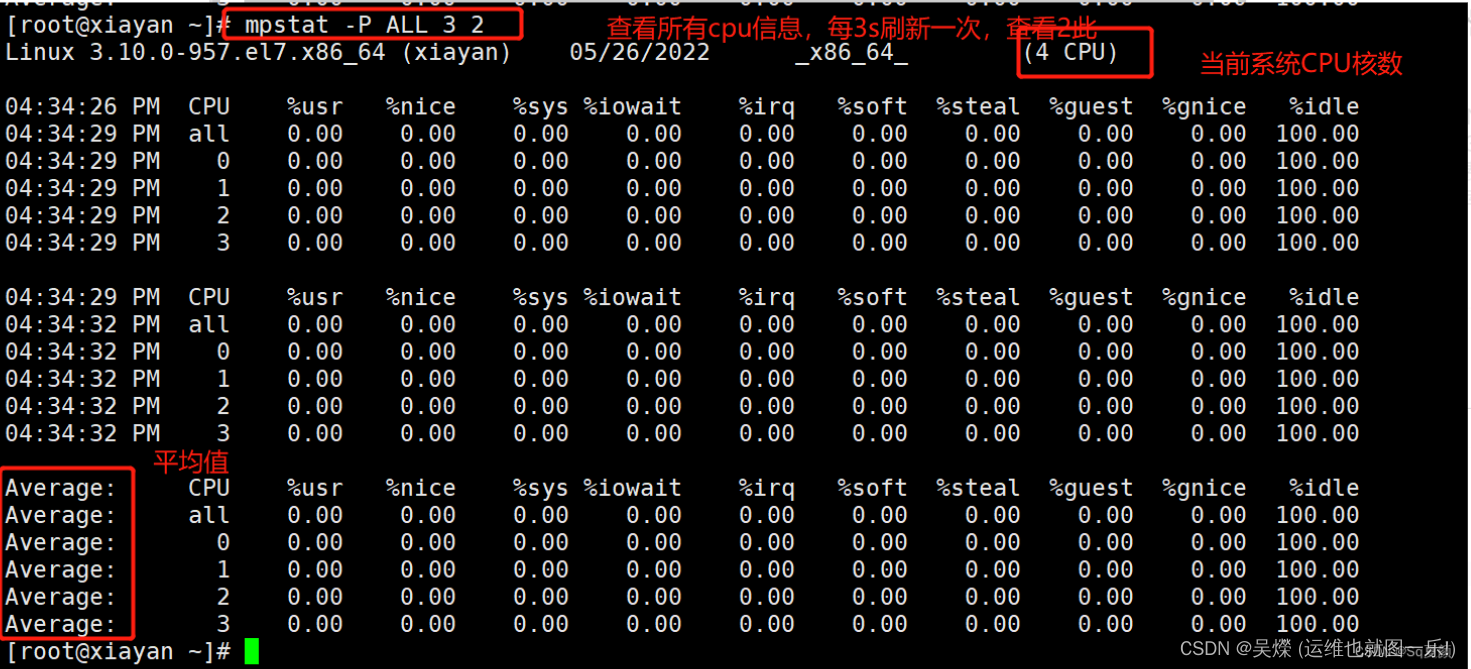
显示参数详解:
###vmstat

其中针对cpu状态的监控指标有以下几个参数:
r: 在运行队列中等待的进程数
b: 在等待io的进程数
cs: 每秒的上下文切换的次数
us: 用户进程使用的cpu时间(%)
sy: 系统进程使用的cpu时间(%)
id: cpu空闲时间
wa: 等待io所消耗的cpu时间
st: 从虚拟设备中获得的时间
命令参数:
用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a显示活跃和非活跃内存
-f显示从系统启动至今的fork数量
-m 显示slabinfo
-n只在开始时显示一次各字段名称
-s 显示内存相关统计信息及多种活动系统活动数量
delay: 刷新时间间隔,如果不指定,只显示一条结果
count :刷新次数,如果不指定刷新次数,但制定了刷新时间间隔,这时就会一直刷新
-d: 显示磁盘相关统计信息
-p: 显示制定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
###top命令
在top命令按P键则是按照cpu的消耗率进行排序:

这里可以很清楚的看到当前占用cpu最高的是哪个进程,且用户是谁,pid是多少.
命令顶部的信息:
第一行:
1,当前系统运行的时间
2,当前接入的终端用户数
3 load average:1分钟,5分钟,15分钟对应的平均负载.
第二行:
tasks: 当前有多少进程
total: 正在运行的进程
sleeping: 正在休眠的进程
stopped: 正在停止的进程
zombie: 僵尸进程数
第三行:
us: 当前用户使用率,
sy: 当前系统使用率
ni: 切换优先级占用率
id:空闲率
wa: io等待率
hi:硬终端占用百分比
si: 软中断占用
st: 从虚拟设备中获得的时间
top的其他交互命令:
c: 显示完整的命令
d: 更改刷新频率
f: 增加或减少要显示的列(选中的会变成大写并加*号)
F: 选择排序的列
h: 显示帮助画面
H: 显示线程
i: 忽略闲置和僵死进程
k: 通过给予一个PID和一个signal来终止一个进程。(默认signal为15。在安全模式中此命令被屏蔽)
l: 显示平均负载以及启动时间(即显示影藏第一行)
m: 显示内存信息
M: 根据内存资源使用大小进行排序
N: 按PID由高到低排列
o: 改变列显示的顺序
O: 选择排序的列,与F完全相同
P: 根据CPU资源使用大小进行排序
q: 退出top命令
r: 修改进程的nice值(优先级)。优先级默认为10,正值使优先级降低,反之则提高的优先级
s: 设置刷新频率(默认单位为秒,如有小数则换算成ms)。默认值是5s,输入0值则系统将不断刷新
S: 累计模式(把已完成或退出的子进程占用的CPU时间累计到父进程的MITE+ )
T: 根据进程使用CPU的累积时间排序
t: 显示进程和CPU状态信息(即显示影藏CPU行)
u: 指定用户进程
W: 将当前设置写入~/.toprc文件,下次启动自动调用toprc文件的设置
<: 向前翻页
>: 向后翻页
?: 显示帮助画面
1(数字1): 显示每个CPU的详细情况
###iostat命令查看cpu
###sar命令
需要安装yum install sysstat

还支持很多参数,进行系统性能的查看:

###mpstat 命令

##内存性能
###查看系统内存的指标cat/proc/meminfo
可以查看到当前系统内存各种大小设置
###free 命令
-h以人类很好可读的方式显示

常用参数:

total:表示 总计物理内存的大小。
used:表示 已使用多少。
free:表示 可用内存多少。
Shared:表示多个进程共享的内存总额。
Buffers/cached:表示 磁盘缓存的大小。
###vmstat命令中的关于内存部分:

swpd: 正在使用的虚拟内存的大小,单位k
free: 空闲的内存大小
buff: 已使用的buff大小,对块设备的读写进行缓冲
cache: 已用cache大小,文件系统的cache
si: 每秒从交换区写入内存的大小,
so: 每秒从内存写到交换分区的大小
##网络性能
##ip和ifconfig
1.3.1 网络接口的状态标志。ifconfig 显示【RUNNING】,IP 输出【LOWER_UP】,表示物理网络是连通。如果看不到它们的状态,可能网线被拔掉了。
1.3.2 MTU的大小,MTU默认大小是1500,可能需要根据网络架构的不同调整MTU大小
1.3.3 网络接口的配置信息需要确保正确,IP地址、子网掩码及MAC地址。
1.3.4 网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题 ,RX表示网络收包,,TX表示网络发报
1.3.5 errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
1.3.6 dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
1.3.7 overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
1.3.8 carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
1.3.9 collisions 表示碰撞数据包数。
##netstat命令

需要注意的两个参数接收队列(Recv-Q)和发送队列(Send-Q),他们通常为0,当他们不是0时,说明网络中包有堆积,
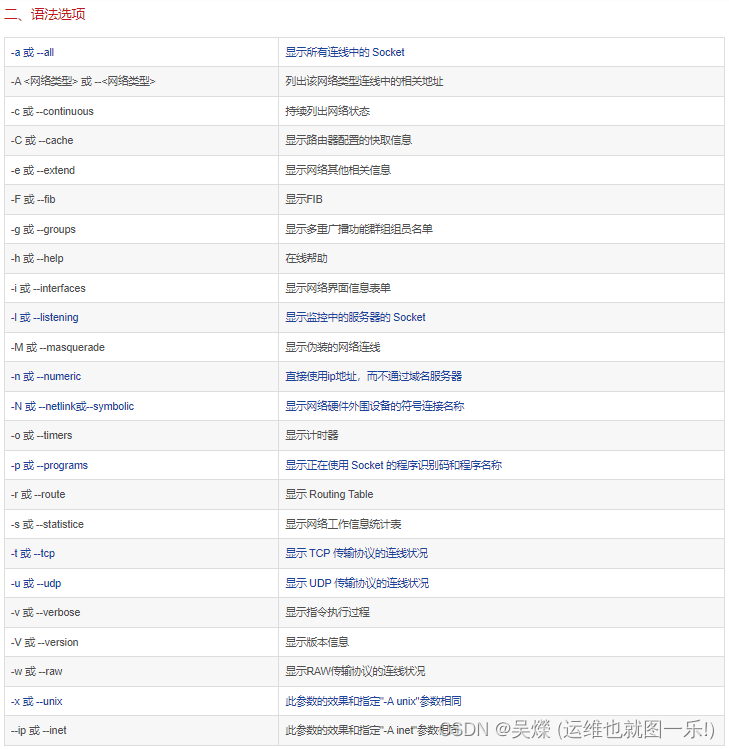
##ss命令:
它可以显示和netstat类似的内容。ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。
当服务器的socket连接数量变得非常大时,无论是使用netstat命令还是直接cat /proc/net/tcp,执行速度都会很慢。
ss快的秘诀在于,它利用到了TCP协议栈中tcp_diag。tcp_diag是一个用于分析统计的模块,可以获得Linux 内核中第一手的信息,这就确保了ss的快捷高效。
参数:
1 . 常用ss命令
ss -l 显示本地打开的所有端口
ss -pl 显示每个进程具体打开的socket
ss -t -a 显示所有tcp socket
ss -u -a 显示所有的UDP Socekt
ss -o state established ‘( dport = :smtp or sport = :smtp )’ 显示所有已建立的SMTP连接
ss -o state established ‘( dport = :http or sport = :http )’ 显示所有已建立的HTTP连接
ss -x src /tmp/.X11-unix/* 找出所有连接X服务器的进程
ss -s 列出当前socket详细信息
##磁盘性能
###sar -d 查看磁盘

tps: 每秒从物理磁盘的io上的次数,
rd_sec/s: 每秒读扇区的次数
wr_sec/s:每秒写扇区的次数
avgrq-sz:平均每次设备 I/O 操作的数据大小(扇区)
avgqu-sz:磁盘请求队列的平均长度
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒
svctm: 系统处理每次请求的平均时间,包括在请求队列中消耗的时间,
%util: io请求占cpu的百分比,比率越大,说明越饱和.
###iostat命令
相关参数:
参数 详解
-c 只显示cpu相关统计信息(默认是同时显示cpu和磁盘信息)
-d 只显示磁盘统计信息(默认是同时显示cpu和磁盘信息)
-h 使用NFS的输出报告更加友好可读。
-j { ID | LABEL | PATH | UUID | … } 磁盘列表的Device列要用什么维度来描述磁盘
-k 默认情况下,iostat的输出是以block作为计量单位,加上这个参数可以以kb作为计量单位显示。(该参数仅在linux内核版本2.4以后数据才是准确的)
-m 默认情况下,iostat的输出是以block作为计量单位,加上这个参数可以以mb作为计量单位显示。(该参数仅在linux内核版本2.4以后数据才是准确的)
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS相关统计数据(network fileSystem)。(该参数只在linux内核版本2.6.17之后有用)
-p [ { device [,…] | ALL } ] 显示磁盘分区的相关统计信息(默认粒度只到磁盘,没有显示具体的逻辑分区)
-t 显示终端和CPU的信息,每次输出报告时显示系统时间。
-V 显示当前iostat的版本信息
-x 显示更详细的磁盘报告信息,默认只显示六列,加上该参数后会显示更详细的信息。(该参数需要在内核版本2.4之后才能使用)
-y 跳过不显示第一次报告的数据,因为iostat使用的是采样统计,所以iostat的第一次输出的数据是自系统启动以来累计的数据
-z 只显示在采样周期内有活动的磁盘
加上-x 参数会有更加详细的输出

Device:磁盘名称,可以通过-p参数改成ID、PATH、UUID的形式
tps:取样周期内,磁盘的读写次数。但是由于有时操作系统会合并多个IO请求成一个,因此这个参数并不是十分准确。
Blk_read/s:取样周期内,每秒读取的block数量(通过参数-k -m可以将单位改成kb、mb)
Blk_wrtn/s:取样周期内,每秒写入的block数量(通过参数-k -m可以将单位改成kb、mb)
Blk_read:取样周期内,读取的总block数量(通过参数-k -m可以将单位改成kb、mb)
Blk_wrtn:取样周期内,写入的总block数量(通过参数-k -m可以将单位改成kb、mb)
##df 命令
用来查看当前系统中磁盘分区以及占用情况.
##vmstat命令
其中的id段: bi 表示块设备每秒接受的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认是1024字节.
bo: 块设备每秒发送块数量,
例如我们读取文件,bo就要大于0,bi和bo一般都要接近0,不然就是io过于频繁,需要调整.
###iotop命令
iostat命令主要完成系统级别的io监控,而iotop命令主要是对进程级别的io监控.
iotop参数:
-h: 帮助
-o: only只显示正在产生io的进程或者线程,
-b: 非交互模式,一用来记录日志,
-n 设置检测的次数,默认为无限,
-d 设置每次检测的间隔,
-p pid指定监测的进程
-u 指定监测某个用户的io
-P 仅显示进程,默认iotop显示所有线程
-a 显示累计的io,而不是带宽,
-k 使用kb单位,
-t 加上时间戳
-q, --quiet 禁止头几行,非交互模式。有三种指定方式。
-q 只在第一次监测时显示列名
-qq 永远不显示列名。
-qqq 永远不显示I/O汇总。
iotop记录到文本:
iotop -botq --iter=3 > /opt/iotop
–iter 等于-n,表示检测迭代的次数
一般使用 iotop --only 就可以清楚看到哪个进程在使用io.
##系统负载
##uptime 命令

第一项是当前时间,up表示系统正在运行,然后是系统启动总时间.
最后是系统负载load的信息: 1分钟,5分钟,15分钟的一个平均负载
负载的数据都是从/proc/loadavg文件中,获取出来的,
负载load接近0,表示系统处于空闲状态,
如果1分钟的load高于5分钟或者15分钟说明 load在上升,反之下降,
如果load高于cpu核心数,那么系统就可能会遇到性能问题.
##w命令
第一行的显示内容与uptime相同信息,
user:表示当前登录用户
tty: 表示当前登录后系统分配的终端号 ,pts表示伪终端
from: 远程登录主机
login: 何时登录进入的
idea: 用户空闲时间,一旦用户执行了任何操作,该计时器便会重置.
JCPU: 和该终端连接的所有进程占用时间,包括当前正在运行的后台作业时间,
PCPU: 当前进程占用时间
WHAT: 表示当前正在运行进程的命令行
##top命令,
最顶段的第一行也可以查看到当前的负载
##进程占用
##使用ps命令
ps -aux 命令可以看到当前进程的cpu使用率
\
###iotop 命令:
iotop -p pid 就可以实现对该进程使用的io情况,记性打印,
###通过 cat /proc/pid/status
这个文件可以看到这个进程当前的信息.
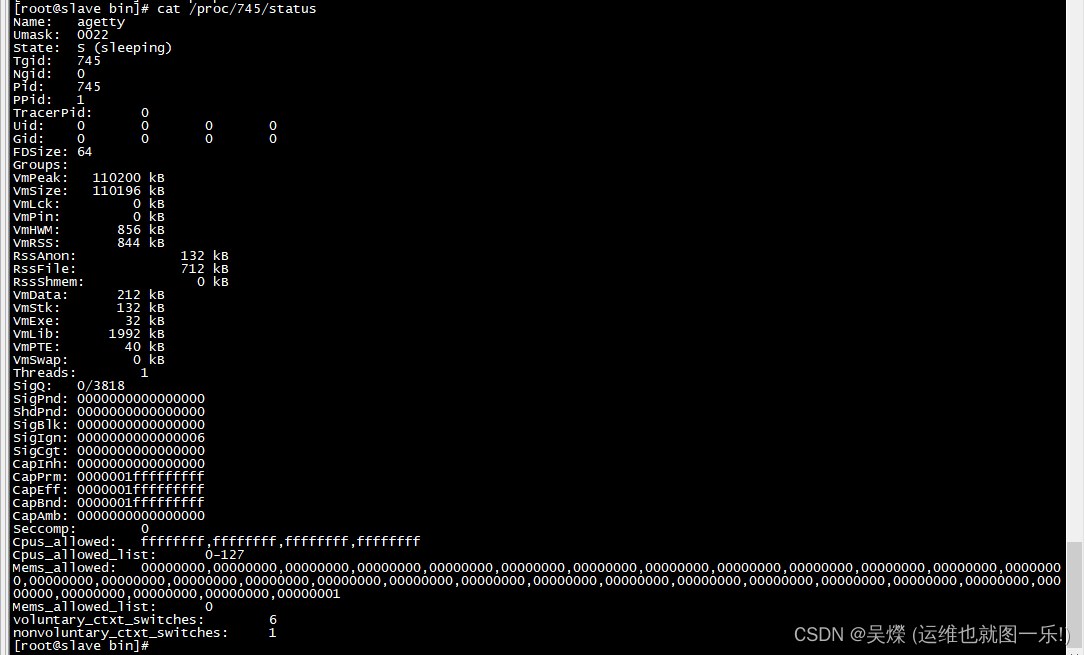
VmPeak代表当前进程运行过程中占用内存的峰值.
VmSize代表进程现在正在占用的内存
VmLck代表进程已经锁住的物理内存的大小.锁住的物理内存不能交换到硬盘.
VmHWM是程序得到分配到物理内存的峰值.
VmRSS是程序现在使用的物理内存.
VmData:表示进程数据段的大小.
VmStk:表示进程堆栈段的大小.
VmExe:表示进程代码的大小.
VmLib:表示进程所使用LIB库的大小.
VmPTE:占用的页表的大小.
VmSwap:进程占用Swap的大小.
Threads:表示当前进程组的线程数量.
SigPnd:屏蔽位,存储了该线程的待处理信号,等同于线程的PENDING信号.
ShnPnd:屏蔽位,存储了该线程组的待处理信号.等同于进程组的PENDING信号.
SigBlk:存放被阻塞的信号,等同于BLOCKED信号.
SigIgn:存放被忽略的信号,等同于IGNORED信号.
SigCgt:存放捕获的信号,等同于CAUGHT信号.
CapEff:当一个进程要进行某个特权操作时,操作系统会检查cap_effective的对应位是否有效,而不再是检查进程的有效UID是否为0.
CapPrm:表示进程能够使用的能力,在cap_permitted中可以包含cap_effective中没有的能力,这些能力是被进程自己临时放弃的,也可以说cap_effective是cap_permitted的一个子集.
CapInh:表示能够被当前进程执行的程序继承的能力.
CapBnd:是系统的边界能力,我们无法改变它.
Cpus_allowed:3指出该进程可以使用CPU的亲和性掩码,因为我们指定为两块CPU,所以这里就是3,如果该进程指定为4个CPU(如果有话),这里就是F(1111).
Cpus_allowed_list:0-1指出该进程可以使用CPU的列表,这里是0-1.
voluntary_ctxt_switches表示进程主动切换的次数.
nonvoluntary_ctxt_switches表示进程被动切换的次数.
###pidstat工具
yum install -y pidstat
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
常用的参数:
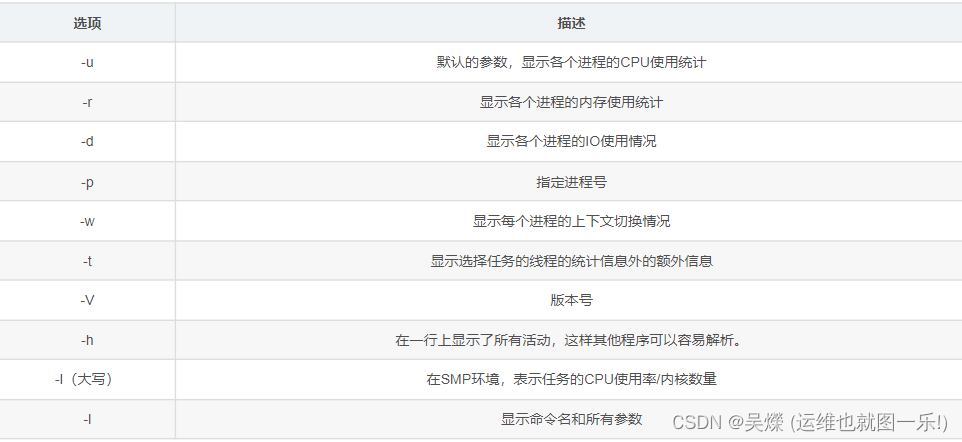
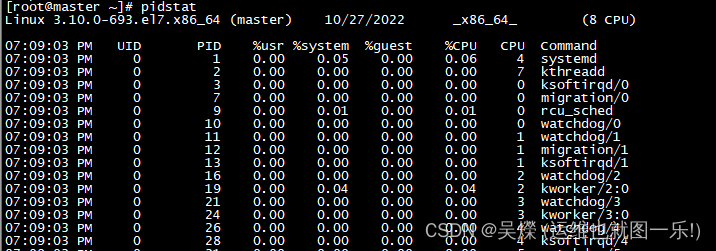
命令使用:
##性能工具
###dstat命令
用来集合全能一个信息系统的工具,需要使用yum 安装: yun -y install dstat
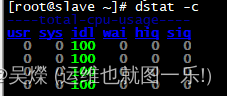
通过帮助,可以看到,之处查询的指标有很多.
支持磁盘,cpu,负载,内存,io性能,网络,swap等等.
###htop工具
类似于top命令的图形化监控工具.
##常见系统性能的处理方式
IO/CPU/men连锁反应
1.free急剧下降
2.buff和cache被回收下降,但也无济于事
3.依旧需要使用大量swap交换分区swpd
4.等待进程数,b增多
5.读写IO,bi bo增多
6.si so大于0开始从硬盘中读取
7.cpu等待时间用于 IO等待,wa增加
内存不足
1.开始使用swpd,swpd不为0
2.si so大于0开始从硬盘中读取
io瓶颈
1.读写IO,bi bo增多超过2000
2.cpu等待时间用于 IO等待,wa增加 超过20
3.sy 系统调用时间长,IO操作频繁会导致增加 >30%
4.wa io等待时间长
iowait% <20% 良好
iowait% <35% 一般
iowait% >50%
5.进一步使用iostat观察
CPU瓶颈:load,vmstat中r列
1.反应为CPU队列长度
2.一段时间内,CPU正在处理和等待CPU处理的进程数之和,直接反应了CPU的使用和申请情况。
3.理想的load average:核数CPU数0.7
CPU个数:grep ‘physical id’ /proc/cpuinfo | sort -u
核数:grep ‘core id’ /proc/cpuinfo | sort -u | wc -l
4.超过这个值就说明已经是CPU瓶颈了
CPU瓶颈
1.us 用户CPU时间高超过90%
涉及到web服务器,cs 每秒上下文切换次数
例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
1.cs可以对apache和nginx线程和进程数限制起到一定的参考作用
2.我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了
较好的趋势:主要是 swap使用少,swpd数值低。si so分页读取写入数值趋近于零