文章目录
- 1.索引的使用语法
- 2.索引的基本使用
- 2.1.准备一张数据表
- 2.2.按照如下需求为表中的字段创建索引
- 2.3.查看创建的索引
- 2.4.删除索引
- 3.验证使用索引前后的执行效率
1.索引的使用语法
1)创建索引
创建索引时,如果不指定索引的类型,默认就是常规索引,如果同时在一个索引中指定了多个字段,那么这个索引就是多字段的联合索引。
CREATE [UNIQUE | FULLTEXT] INDEX {index_name} ON {table_name} (字段1,字段2)
2)查看索引
SHOW INDEX FROM 表名
3)删除索引
DROP INDEX index_name ON 表名
2.索引的基本使用
2.1.准备一张数据表
准备一张员工信息表,用于索引的使用。
1)创建表
CREATE TABLE tb_user (
id INT PRIMARY KEY auto_increment COMMENT '主键',
xm VARCHAR ( 50 ) NOT NULL COMMENT '姓名',
lxfs VARCHAR ( 11 ) NOT NULL COMMENT '联系方式',
yx VARCHAR ( 100 ) COMMENT '邮箱',
zy VARCHAR ( 11 ) COMMENT '专业',
nl TINYINT UNSIGNED COMMENT '年龄',
xb CHAR ( 1 ) COMMENT '性别:1表示男 2表示女',
zt CHAR ( 1 ) COMMENT '状态:1表示在职 2表示离职',
rzsj date COMMENT '入职时间'
) COMMENT '人员信息表';
2)准备数据
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '余伟', '13401004368', 'yuwei@jiangxl.com.cn', '软件工程', 37, '1', '1', '2009-02-02' );
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '江睿基', '13900090963', 'jiangruiji@jiangxl.com.cn', '网络工程', 31, '1', '1', '2017-01-01' );
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '张希', '15101030779', 'zhangxi@jiangxl.com.cn', '网络工程', 28, '1', '1', '2020-12-05' );
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '张子云', '18301006454', 'zhangziyun@jiangxl.com.cn', '软件工程', 35, '1', '1', '2017-10-12' );
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '陈国明', '15201254765', 'chenguoming@jiangxl.com.cn', '软件工程', 27, '1', '1', '2016-09-15' );
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '王蕊蕊', '18800005497', 'wangruirui@jiangxl.com.cn', '软件工程', 31, '2', '1', '2018-10-23' );
INSERT INTO tb_user ( xm, lxfs, yx, zy, nl, xb, zt, rzsj ) VALUES ( '牛泽阳', '18701176856', 'niuzeyang@jiangxl.com.cn', '软件工程', 20, '1', '1', '2018-10-31' );
3)数据准备就绪

2.2.按照如下需求为表中的字段创建索引
创建索引的规则:表中频繁查询的字段要设置索引,提高查询的效率。
1)为xm字段创建一个常规索引,查姓名的频率也比较高。
create后面不能任何参数默认创建的就是常规索引。
create index idx_user_xm on tb_user (xm);
2)为lxfs字段创建一个唯一索引,不允许有重复值。
唯一索引要在create后面加上unique参数。
create unique index idx_user_lxfs on tb_user (lxfs);
3)为zy、nl、zt等字段创建联合索引。
联合索引就是在常规索引的基础上,一个索引中同时增加了多个字段。
create index idx_user_zy_nl_zt on tb_user (zy,nl,zt);
在联合索引中,同时增加多个字段时,字段顺序是有讲究的。
如下图所示,这是查询表中的索引信息,可以看到有一列是seq_in_index,这一列表示索引字段的顺序,可以看到其他索引的这个字段都是1,表示这些索引只有一个字段,而在idx_user_zy_nl_zt这个索引有三条记录,且seq_in_index一列的值分被是1、2、3,这也就说明了当索引指定了多个字段时,就有相应的顺序。

4)为yx字段创建常规索引,提高查询效率。
create index idx_user_yx on tb_user (yx);
2.3.查看创建的索引
show index from tb_user;
+---------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| tb_user | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | | YES | NULL |
| tb_user | 0 | idx_user_lxfs | 1 | lxfs | A | 7 | NULL | NULL | | BTREE | | | YES | NULL |
| tb_user | 1 | idx_user_xm | 1 | xm | A | 7 | NULL | NULL | | BTREE | | | YES | NULL |
| tb_user | 1 | idx_user_zy_nl_zt | 1 | zy | A | 2 | NULL | NULL | YES | BTREE | | | YES | NULL |
| tb_user | 1 | idx_user_zy_nl_zt | 2 | nl | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL |
| tb_user | 1 | idx_user_zy_nl_zt | 3 | zt | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL |
| tb_user | 1 | idx_user_yx | 1 | yx | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL |
+---------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
7 rows in set (0.01 sec)

Table一列表示索引属于哪张表。
Key_name是索引的名称,如果一个索引指定了多个字段,则会显示多行数据,如idx_user_zy_nl_zt这个索引。
seq_in_index是索引字段的顺序,如果一个索引中只有一个字段,那么只会显示1,如果有多个字段,则会有显示顺序。
Column_name是索引的字段。
Index_type是索引的数据结构,InnoDB引擎默认都是B+Tree数据结构。
2.4.删除索引
drop index idx_user_yx on tb_user;
3.验证使用索引前后的执行效率
dabiao这张表中name字段是没有添加索引的,下面以name字段为查询条件,来验证没有添加索引前的执行效率。
select * from dabiao where name = '江睿基';
查询耗时大概是2.442秒。
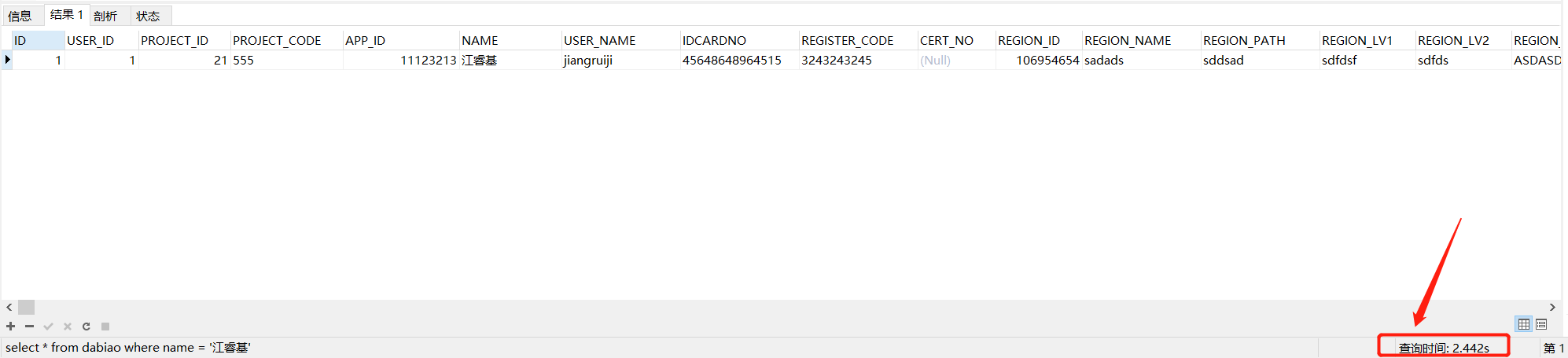
下面为name字段添加索引,然后再来验证添加索引后,查询的效率如何。
create index idx_dabiao_name on dabiao (name);
再次执行相同的SQL观察执行的效率。
mysql> select * from dabiao where name = '江睿基'\G;
······
1 row in set (0.01 sec)
效率有了非常明显的提升,执行总耗时为0.01。