摘要
生成式零样本目的是训练一个模型,监督学习下,输出类别不可知条件下,该模型对数据样本进行分类。为了解决这个任务,生成式零样本利用可见的语义信息和不可见类别在不可见和可见类别间构建桥梁,结论,许多的零样本模型都被确切的陈述,在这篇论文的概览中,我们提出一个关于零样本的全面性观点。首先,我们提出生成式零样本的概述,包括挑战和问题。其次,我们介绍了生成式零样本方法,并讨论了每一种类别的代表性方法,另外,我们讨论了在基准数据集上,生成式零样本方法的应用,联同讨论了研究不足和未来展望。
关键词:生成式零样本学习、深度学习、语义空间、生成式对抗网络、VAE。
介绍
随着近年来,随着图像处理和计算机视觉的快速发展。深度学习模型非常受欢迎,由于它们有能力提供端到端的解决方案从特征提取到分类。虽然这些成功了,传统深度学习模型要求为每个类别训练大规模的标签数据,连同大规模的样本。在这方面,收集大规模的有标签的样本是一个挑战性问题。作为一个案例,ImageNet是一个大规模的数据集,包含14百万张图片,21814类别,许多的类别包含仅有少量的图片。另外,标准的深度学习模型能够识别样本属于哪一个类别,这些类别在整个训练阶段是可见的,但是,其并不能够去处理不可见的类别。然而,在许多真实世界应用的场景中,并不是对所有类别都有足够多数量的标签样本。一方面**,标注大量细粒度的样本是费力的,其要求一个领域的专家知识**。
另一方面,许多类别缺乏足够的标签样本。比如:endangered bird。不断完善的,比如:COvID-19。或者在训练阶段未涵盖,但是出现在测试阶段。
多种学习技术已经开发出来,零样本和少样本学习技术能够使用一些少量的学习样本来学习类别。这些技术从其他类别数据样本中获取知识,和训练处理少量样本类别的分类模型。开集识别学习OSR技术能够识别测试样本是否属于不可见类别。它们无能力去预测一个精确的类别。Out-of-distribution技术试图去识别测试样本, 测试样本是不同于训练样本的,然而,以上提及的技术都不能分类不见类样本,相反,人类能够识别大约30000万张类别,我们并不需要提前学习所有类别。一个案例,一个儿童能够容易的识别zera,如果其在之前已经看过马, 那么其将会有zebra的知识,看起来像黑色和白色条纹的horse。零样本技术对类似的挑战是一个很好的解决方案。
零样本技术目的是在语义信息的帮助下训练一个模型能够分类不可间类别实体(目标域)从可见类别(source main)哪里获得知识。语义信息在高维向量中嵌入了可见类别和不可见类别的名称。语义信息的获得方式有手动定义属性向量,自动提取词向量、上下文嵌入、或者其他的组合方法。换句话说,零样本学习使用语义信息来构建可见类别和不可见类别的桥梁。这种学习范式能够与人类相比较,在识别新物体的时候,通过其描述和以前习得的观念来测度其可能性。
在传统的零样本技术中,测试集仅包含不可见类别是不现实的,其并不能反应真实世界的应用场景。实际上,与不可见类别相比,可见类别的样本数据是更普遍的。同时识别两类的样本数据是重要的,而不是仅识别不可见类别的样本数据。
这种方法称为生成式零样本方法,确实,生成式零样本方法是零样本方法的实用版本。生成式零样本方法的主要动机是模仿人类识别能力,其能够识别来自可见类别和不可见类别的样本,

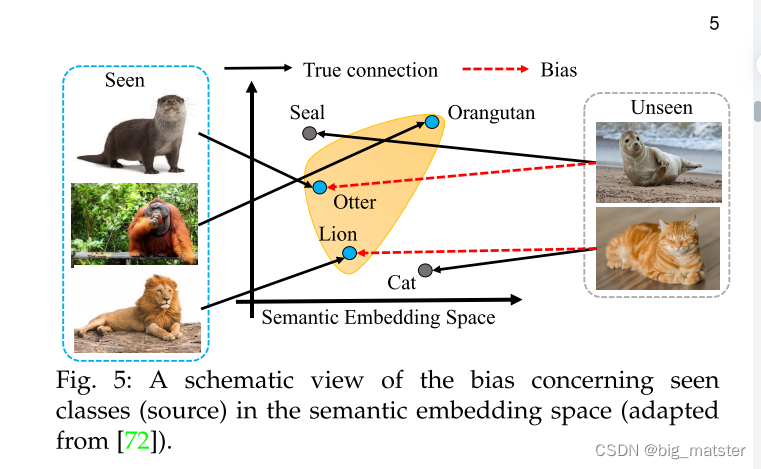
上图代表一个广义零样本和零样本类别的示意图。
Socher在2013年,首次提出了广义零样本的概念。离群点检测方法被整合进模型去决定被测试样本是否属于可见类别。如果其来自可见类别,标准的分类其能够被使用,否则,通过计算不可见类别的可能性可以为图像分配一个类别。
在同一年,Frome et al 试图去学习标签间语义关系,通过利用文本数据和将图片数据集映射进语义嵌入空间。
Norouzi et al :使用一个类标签嵌入向量凸组合将图片映射进语义嵌入空间。试图去识别可见类别和不可见类别的样本。
然而直到2016年,广义零样本并没有得到重视,
Chao et al:富有经验性的显示在生成式零样本技术,零样本技术的效果并不是很好,这是因为零样本技术容易在可见类别上过拟合。比如,将不可见类别的测试样本作为可见类别的一个类。后来,
Xian et al和Liu et al. 在图像和web-scale video data上有类似的发现。同时,这主要由于已经存在的技术大部分都是针对可见类别的,几乎所有测试样本都属于不可见类别。可以被分为可见类别的一类。
为了解决这个问题。
Chao et al。提出了一种有效的精准技术,称为calilbrated stacking。
为了评估两股力量,识别样本中的可见类别和不可见类别。因此,广义零样本的技术根本性的越来越多。
Contributions
广义零样本技术已经受到许多研究者的关注,虽然零样本技术的概览在一些文献中能够被找到,我们的论文和以往零样本调查的文献在于以下方面:
- 聚焦于零样本学习,仅有少量的广义零样本方法被复查,
- 在不同案例中进行调查了多种零样本技术和广义零样本技术的影响,
- Several SOTA ZSL and GZSL methods已经被选择和使用不同的数据集进行评估。
然而,这些工作更聚焦于实证研究,而不是零样本和广义零样本的综述性文章。研究聚焦于零样本技术,少部分的讨论广义零样本方法。 - Rezaei and Shahidi使用新冠肺炎诊断数据集研究了零样本方法的重要性,与上面综述性文章不同的是,在这篇文章中,我们更加关注广义零样本,而不是零样本技术。然而,几乎没有一个对广义零样本进行深入调查和分析的。为了弥补这方面的不足。我们目的是在这篇文章中,我们提出了一个广义零样本的全面性概览,包括:问题描述、挑战性问题、层次分类和应用。
我们浏览出版文章、会议论文、文章篇章和高质量的预印本。这些资料与广义零样本相关。从2016年到2021年都相当流行。然而,我们可能回缺失一些近年来的研究,这是不可避免的,这篇文章的主要贡献包括如下: - 广义零样本方法的全面性概览,据我们所知,第一篇论文中,试图提供一个深入分析的广义零样本的方法。
- 广义零样本方法的层次类别,连通与其对应的具有代表性的model与真实场景的应用。
- 阐明研究空白和未来研究展望。
Organization
这篇文章包含六个部分,
- 给出一个广义零样本技术的概览:问题描述、语义信息、嵌入空间、挑战性问题。
- 归纳推导和语义推导的广义零样本方法,这是广义零样本方法提供的一个层次分类。
每个类别都被进一步分为几种成分。 - 聚焦于直推式广义零样本方法,
- 将广义零样本技术应用到多个领域:计算机视觉和自然语言处理。
- 研究不足和未来展望,连通结束语。
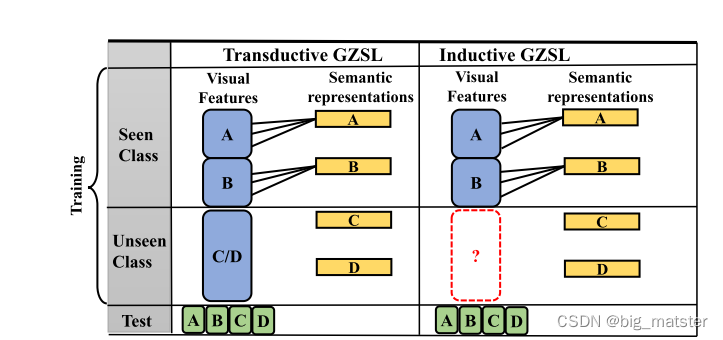
上图是直推式和归纳式示意图。在归纳式中,仅有视觉特征和可见类别的(A和B)的语义表示,然而,直导式系列中,可见类信息有权访问不可见类别的无标签视觉样本。
广义零样本学习的概览
问题描述
{ S = ( x i s , a i s , y i s ) i = 1 N s ∣ x i s ∈ X s . a i s ∈ A s . y i s ∈ Y s S = (x^s_i,a^s_i,y^s_i)^{N_s}_{i = 1} | x^s_i \in X^s.a^s_i \in A^s.y^s_i \in Y^s S=(xis,ais,yis)i=1Ns∣xis∈Xs.ais∈As.yis∈Ys}
{
U
=
(
X
j
u
,
a
j
u
,
y
j
u
)
j
=
1
N
s
∣
x
j
s
∈
X
s
,
a
j
s
∈
A
s
,
y
j
s
∈
Y
s
U = {(X^u_j,a^u_j,y^u_j)^{N_s}_{j = 1} | x^s_j \in X^s,a^s_j \in A^s,y^s_j \in Y^s}
U=(Xju,aju,yju)j=1Ns∣xjs∈Xs,ajs∈As,yjs∈Ys}
U
U
U和
S
S
S代表可见集和不可见集。
-
分别地, x i s . x j u ∈ R D x^s_i.x^u_j \in R^D xis.xju∈RD 表明这个特征空间 X X X中的D维图像,特征空间 X X X能够使用预训练深度学习模型得到,比如:ResNet、VGG-19、GoogLeNet。
-
a i s , a j u ∈ R K a^s_i,a^u_j \in R^K ais,aju∈RK 表明K维,语义表示(属性或词向量)在语义空间中。
-
A ; Y s = y 1 s , ⋯ , y C s s A; Y^s = {y^s_1,\cdots,y^s_{C_s}} A;Ys=y1s,⋯,yCss
-
{ Y u = y 1 u , ⋯ , y C u u Y^u = y^u_1,\cdots,y^u_{C_u} Yu=y1u,⋯,yCuu}
表明了可见类别和不可见类别在标签空间中的标签集 y y y。 -
C s C_s Cs和 C u C_u Cu是可见类别和不可见类别的数量。
-
y = Y s ∪ Y u y = Y^s \cup Y^u y=Ys∪Yu :为可见类别和不可见类别的联合集。
-
Y s ∩ Y u Y^s \cap Y^u Ys∩Yu = ∅ \emptyset ∅
-
在广义零样本,实体学习到的模型
F G Z S L : X → y F_{GZSL}: X \rightarrow y FGZSL:X→y
为分类 N t N_t Nt测试样本,
D t , s = ( x m . y m ) m = 1 N t D_{t,s} = (x_m.y_m)^{N_t}_{m = 1} Dt,s=(xm.ym)m=1Nt
其中 x m ∈ R D , a n d y m ∈ y x_m \in R^D,and y_m \in y xm∈RD,andym∈y
在广义零样本训练阶段,能够被分为两方面:
inductive learning 和transductive learning。
- Inductive learning: 仅利用一个视觉特征和可见类别的语义信息去构建模型。
- Transductive setting: 另外,可见类别的信息、语义表示和不可见类别的无标签视觉特征,可以利用这些进行学习。
- 上图说明了transductive GZSL和Inductive GZSL的主要区别:
上述可见,可见类别的优势可以被上述两种模式使用,不可见类别的优势仅仅取决于一种模式。
如下所示,In inductive learning setting。
不存在不可见类别的先验知识,
然而在 In transductive learning模式下,模型使用不可见类别的无标签训练样本,不可见类别的优势显现出来,
虽然,在transductive learning 下,几个框架被开发出来啦,这些学习范式是不切实际的。
一方面,其违背了不可见类别的假定和降低了挑战性。另一方面,假定无标签数据对所有不可见类别适用是不切实际的。
另外,一些研究者在transductive learning下,适用所有的不可见类别图片样本(训练阶段),其他人将样本切分成两个相等部分,一个为训练,另一个为推断。
近年来,几个研究者们也认为大部分基于生成式方法(Section3.2)并不是纯粹的inductive learning。因为不可见类别的语义信息被使用去生成不可见类别的视觉特征。它们将基于生成式方法归类为语义transdcutive learning。
另外,inductive generative-based methods ,该方法在测试之前不需要嵌入不可见类别的语义信息。
绩效指标
为了评估广义零样本方法的效果,在文献中,已经使用了几个指标。可见类别准确率
A
c
c
s
Acc_s
Accs,
不可见类别的准确率
A
c
c
u
Acc_u
Accu是两个共同绩效指标。
Chao et.al引入了可见和不可见准确率曲线区域
A
U
S
U
C
AUSUC
AUSUC去衡量the trade-off recognizing between seen and unseen classes for calibration-based techniques。
这个曲线主要能够通过 varying
γ
\gamma
γ的等式1中得到。
higher
A
U
S
U
C
AUSUC
AUSUC目的是实现广义零样本分类任务的均衡性能。
- HM是另一种评价指标,其有能力测量基于广义零样本方法的t
h
e
i
n
h
e
r
e
n
t
b
i
a
s
n
e
s
s
he inherent biasness
heinherentbiasness
公式1为:
H = 2 ∗ A c c s ∗ A c c u A c c s + A c c u H =2* \frac{Acc_s*Acc_u}{Acc_s + Acc_u} H=2∗Accs+AccuAccs∗Accu
语义信息
语义信息是广义零样本的关键,因为这是不可见类别中的无标签训练样本。使用语义信息构建不可见类别和可见类别的桥梁。语义信息使得广义零样本识别具有可操作性。
语义信息必须包含所有不可见类别的识别属性,去保证为每一个不可见类别提供足够的语义信息,其应该与特征空间中的样本相关的,为了确保语义信息的实用性。
- 语义信息的ideas来自于人类识别能力,人类能够在语义信息的帮助下识别不可见类别样本。
- 语义信息构建一个包括可见类别和不可见类别的空间,这能够被零样本学习和广义零样本学习所使用,广义零样本最广泛的使用语义信息方法有手动定义属性、词向量和其混合方法。
手动定义属性
这些属性描述一个类别的高层次特征,比如,形状(circle)、颜色(blue)、这些属性使得广义零样本模型有能力在真实空间中进行分类,这些属性是精确的,但是要求人工标注,这并不适合与大规模问题,
- Wu et al提出全局语义一致性网络* (GSC-Net)为可见类别和不可见类别构建语义属性。
- Lou et al开发了一个特定数据的特征提取器,根据这个属性标签树。
Word vectors
可以从大规模语料库中自动提取向量(Wikipedia),去代表相似度和词语之间的差异性和描述每个对象的属性。词向量要求很少的人工,因此,它们适合大规模的数据集,然而,它们包含了噪音,这降低了模型的性能。一个例子:
- Wang et al : 应用Node2Vec去生成概念化的词向量,这个研究试图从噪音语义描述中提取语义表示。
- Akata et al : 提出从多个文本源头来提取语义表示。
嵌入空间
许多广义零样本方法学习一个嵌入\映射函数,去将可见类别的低层次特征整合为对应的语义向量。这个函数能够被优化,或者通过ridge regression loss。或者ranking loss 求两个空间的兼容性得分。因此,使用这个学习函数去识别新类别,通过度量嵌入空间中原型表示和数据样本预测性表示的相似性水平。由于属性向量的每个维度表示一个类的描述,预计类别的相似性描述包含相似性属性向量在语义空间中。然而,在视觉空间中,相似性属性的类别可能有大的变化,因此,发现一个像样的嵌入空间是一个挑战性任务,引起视觉语义歧义问题。
一方面,嵌入空间能够被分进
E
u
c
l
i
d
e
a
n
Euclidean
Euclidean和
n
o
n
−
E
u
c
l
i
d
e
a
n
s
p
a
c
e
non-Euclidean space
non−Euclideanspace,然而,这些欧氏空间是简单的,其受制于信息丢失。
非欧氏空间,普遍基于图神经网络的,流形学习、或聚类。经常使用数据样本之间保留的几何关系,另一方面,嵌入空能够被分类进:语义嵌入、视觉嵌入、潜在空间嵌入。以下来进行讨论每个类别。
Semantic Embedding
语义表示使用不同的约束或损失函数学习从视觉空间到语义空间的映射,并且在语义空间中进行分类。目的是将归属于所有类别的语义嵌入映射到一些真实标签嵌入中。一旦得到这个最佳投影函数,可以执行最近邻搜索识别给出的测试图像。
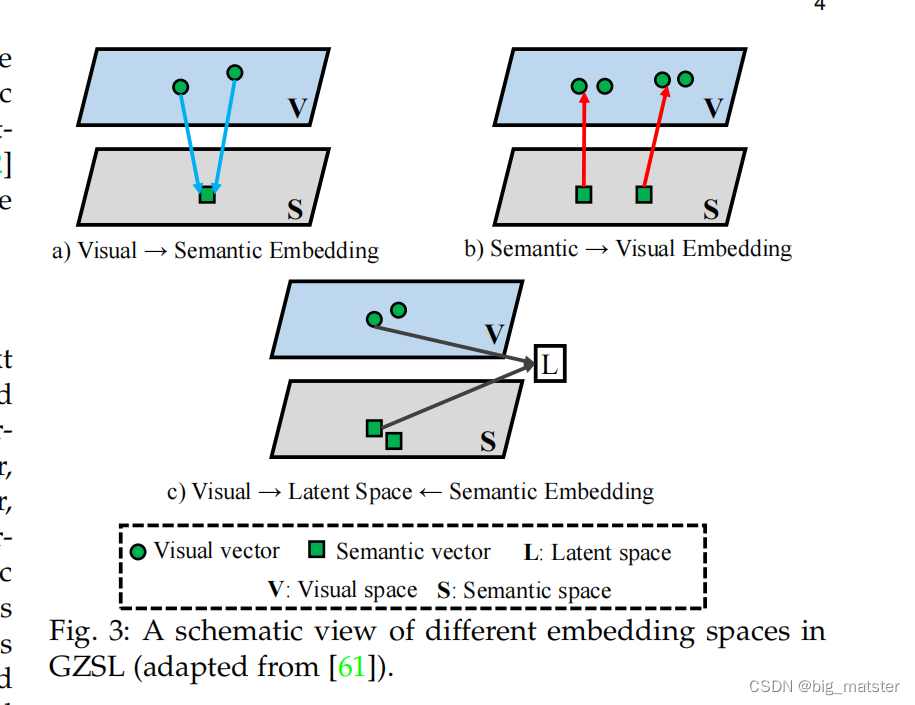
Visual Embedding(视觉嵌入)
视觉嵌入学习一个反向投影函数,将语义嵌入映射到视觉空间。并且在视觉空间上进行分类。目标是使语义表示与视觉特征相对应。在获得最佳投影函数之后,使用最近邻搜索来识别测试图像。
Latent Embedding
语义嵌入和视觉嵌入都是学习一个嵌入函数从一种模式空间中到另一个模式空间中。然而,具有挑战性的问题是如何学习一个关联两个空间的可利用的映射函数。由于不同模式的显著不同的性质。在这一方面,潜在空间嵌入将视觉空间和语义表示空间合并成一个普通空间,
L
:
a
l
a
t
e
n
t
e
m
b
e
d
d
i
n
g
L :a latent embedding
L:alatentembedding
利用两种模式的共同语义属性,目的是将每个类别的视觉和语义特征投影到潜在空间。理想的latent space应该能够满足两个条件:1、类内紧凑性:2、类间独立。
Zhang et.al提出:映射的目的是为何解决零样本模型的维度灾难,这将在2.5章中进行讨论。
Challlenge issues
在广义零样本中,一些挑战性问题已经被解决啦,高维空间中的聚集效应是早期的零样本和广义零样本的一个挑战性问题。学习嵌入空间和利用最近邻算法去进行识别。高维空间中的一种聚集效应是一个维度灾难的一种体现,这影响着最近邻算法。一个样本与数据集中的其他样本最为相似。
Dinu et,al:a large number of different map vectors are surrounded by many common items, in which the presence of such items causes problem in high-dimensional spaces.
(高维空间中的一种聚集效应的问题成因)
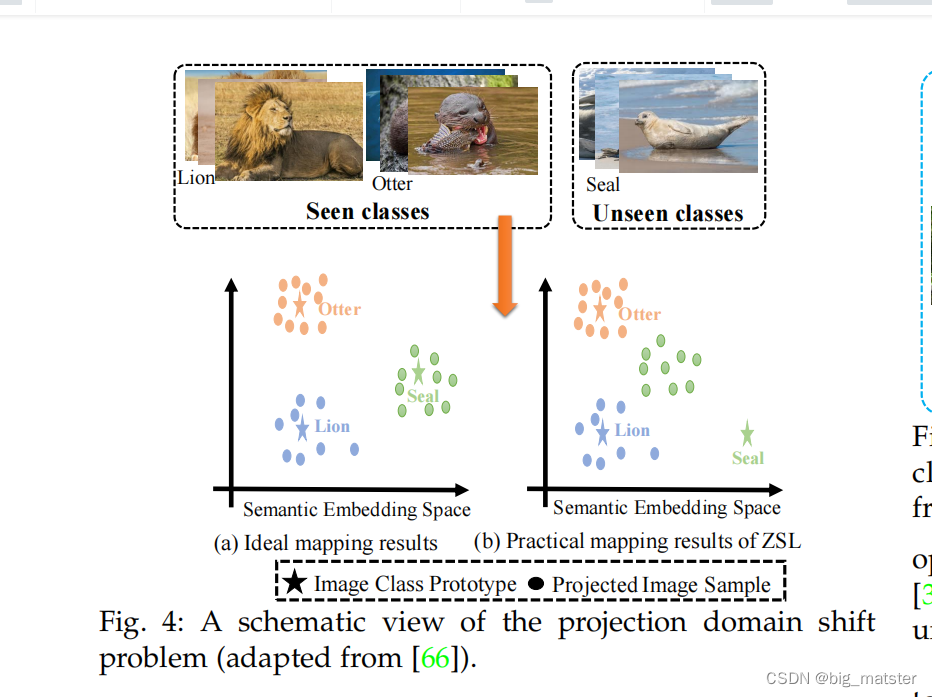
零样本模型和广义零样本模型的另一个挑战是:映射域迁移问题。
零样本和广义零样本模型首先会利用可见类别的数据样本,去学习一个视觉空间和语义空间的映射函数。利用学习到的映射函数将不可见类别的图像从视觉空间投影到语义空间。
一方面,视觉和语义空间是两个不同的实体,另一方面,可见类别和不可见类别的数据样本是相互独立的,是不相关的,并且它们的分布也是不同的。resulting in a large domain gap.
因此,使用可间类别数据样本学习一个嵌入空间,没有适应的不可见类别将会引起
t
h
e
p
r
o
j
e
c
t
i
o
n
d
o
m
a
i
n
s
h
i
f
t
p
r
o
b
l
e
m
the projection domain shift problem
theprojectiondomainshiftproblem.
问题在广义;零样本中更具有挑战性。整个预测期间,由于可见类别的存在。要求广义零样本方法去识别可见类别和不可见类别
d
u
r
i
n
g
i
n
f
e
r
e
n
c
e
during inference
duringinference.(在推论过程中)
其往往倾向于可见类,(这将在下一段作为广义零样本任务的第三个问题)
整个学习期间,由于可见类别视觉特征的可利用性。因此,学习一个精准的映射函数是至关重要的避免误差和确保零样本学习结果的有效性。
The projection domain shift problem differs from the vanilla domain shift problem.
与the vanilla domain shift problem不同的是,两个域共享相同类别,仅在训练阶段和测试阶段输入和输出的联合分布是不同的,(joint distribution)
the projection domain shift can be directly observed in terms of the projection
shift, rather than the feature distribution shift
另外,可见类类别完全不同于不可见类别的,两者甚至完全不相关的。
图4显示一个理想状态下的映射函数,能够使得可见类别和不可见类别的的the projected visual samples。环绕其潜在空间中的语义特征。
实际上,广义零样本任务上,训练和测试样本是不相交的。从可见类别中学习一个无偏的映射函数,其能够将不可见类别的视觉特征投射到语义特征。
这些问题时更普遍的,基于inductive-based methods。
因为其在整个训练阶段无法访问不可见类别数据。为了克服这些问题,基于归纳式方法从可见类合并额外约束和信息。(
i
n
d
u
c
t
i
v
e
−
b
a
s
e
d
m
e
t
h
o
d
s
i
n
c
o
r
p
o
r
a
t
e
a
d
d
i
t
i
o
n
a
l
c
o
n
s
t
r
a
i
n
t
s
o
r
i
n
f
o
r
m
a
t
i
o
n
f
r
o
m
t
h
e
s
e
e
n
c
l
a
s
s
e
s
inductive-based methods incorporate additional constraints or information from the seen classes
inductive−basedmethodsincorporateadditionalconstraintsorinformationfromtheseenclasses)
此外:several transdactive-based methods已经被开发出来为了避免这个
t
h
e
p
r
o
j
e
c
t
i
o
n
d
o
m
a
i
n
s
h
i
f
t
p
r
o
b
l
e
m
the projection domain shift problem
theprojectiondomainshiftproblem。这些方法能够从不可见类别中使用流行信息。
检测值的目的是识别测试样本是否属于可见类别和不可见类别。这些策略是限制可能类的集合通过训练样本属于类的信息。
- Socher,et.al:考虑到不可见类别能够被投影到OOD,关于the seens ones。
然而,不可见类别的数据样本能够被视为所有可见类分布的异常值, - Bhat-taxharjee: 开发了一个自编码框架去识别这个the set of possible classes.
为了实现这些,额外的信息,这个正确类别的信息能够被引入这个解码器,重构输入样本。
因此,广义零样本的方法使用可见类别的数据样本去学习一个模型在可见和不可见类别进行分类。其往往对可见类别是无关的,导致将不可见类别误分类为可见类别中,如上图所示:
大部分的零样本方法都能够有效的解决这个问题,为了减弱这些问题,一些策略已经被提出来啦:calibrated stacking、novelty detec-
tor 。calibrated stacking方法平衡了识别可见类和不可见类的冲突,使用以下公式:
y ^ = a r g m a x c ∈ y f c ( x ) − γ ∏ [ c ∈ Y s ] \hat{y} = argmax_{c \in y}f_c(x) - \gamma\prod[c \in Y^s] y^=argmaxc∈yfc(x)−γ∏[c∈Ys]

Later, entropy-based [76], probabilistic-based [75], [87], distance-based [88], cluster-based [89] and parametric novelty detection [51] approaches have been developed to detect OOD, i.e., the unseen classes. Felix et al. [90] learned a discriminative model using the latent space to identify whether a test sample belongs to a seen or unseen class. Geng et al. [91] decomposed GZSL into open set recognition
(OSR) [9] and ZSL tasks.
广义零样本方法的概览
广义零样本的主要思想是通过使用语义表示将可见类别知识迁移到不可见类别来在可见类别和不可见类别实体进行分类。为了实现这些,两个关键性的问题必须被解决:
-
如何将可见类别的知识迁移到不可见类别中。
-
如何学习一个模型去识别图像从可见类别和无标签数据的不可见类别。在这方面,许许多多的方法已经被提出来,这能够被广泛的进行分类。
-
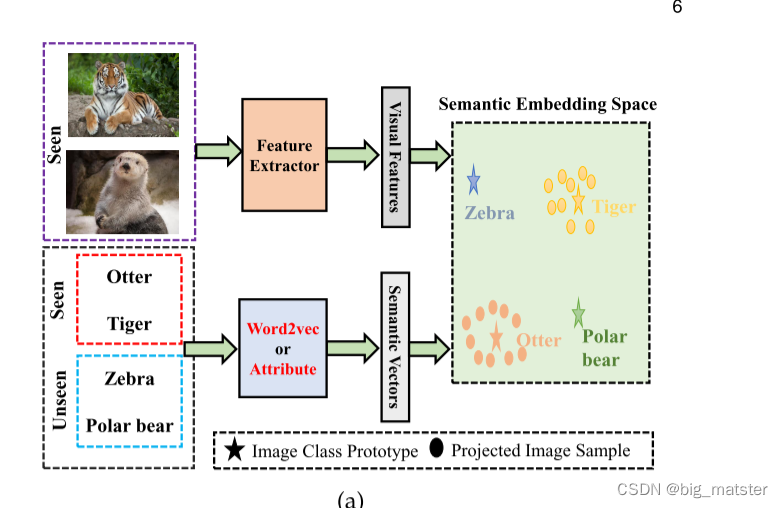
Embedding-based methods:
学习一个嵌入空间将可见类别的低层次的视觉特征嵌入到语义向量中。可以使用学习到的映射函数去识别新类别,通过测度嵌入空间数据样本的预测表示和原型的相似度。
-
Generative-based methods
基于可见类别样本和两个类别的语义表示,学习一个model为不可见类别去生成一个图像或视觉特征,通过生成不可见类别的样本,将广义零样本问题转换为传统的监督学习问题。
基于单同一的过程,可以训练模型对包含可见类别和不可见类别的测试样本进行分类。并解决误差问题。虽然,这些方法在视觉空间上能够识别,并且它们也能够归类为视觉嵌入模型,我们将其归属于基于嵌入的方法(the embedding based methods)
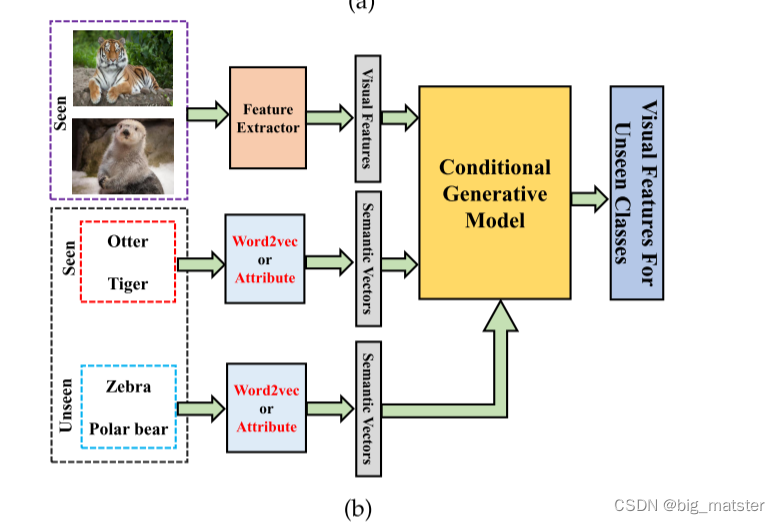
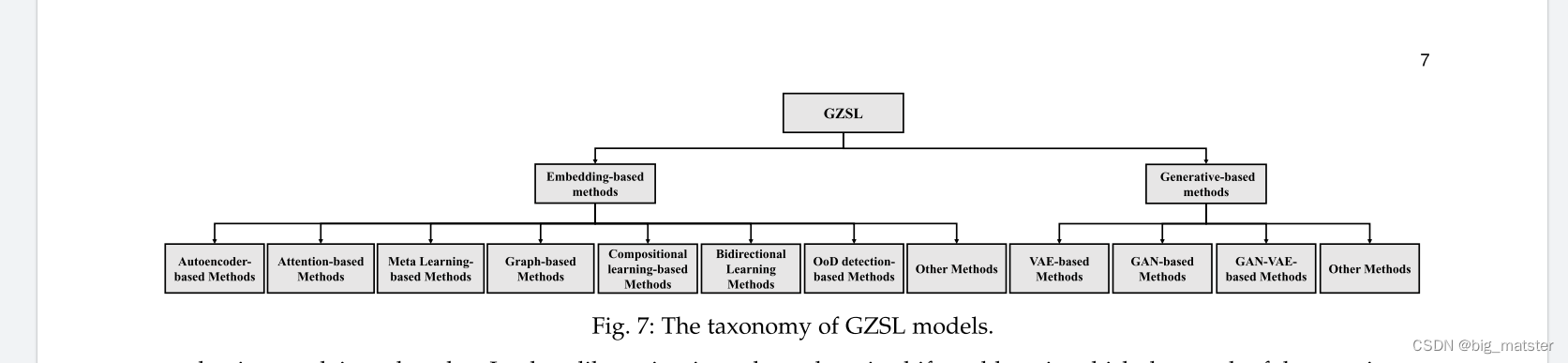
图7中展示,两种方法的分层类别,连通它们的sub-categories。
如下所示:
基于嵌入的方法
近年来,多种多样的基于嵌入的方法已经被用于去设计一个框架去处理广义零样本问题,这些方法可以被分为:graph-based、attention-based、
autoencoder-based、meta learning、compositional learning、和bidirectional learning methods、如下图7所示:
在以下章节,我们浏览每个类别,和在表4中提供这些类别的概要。
Out-of-distribution detection-based methods
异常点检测目的是识别异常的数据样本和与其他样本区别很大的样本。一些研究应用异常点检测方法去处理广义零样本任务.
- 可以运用离群点检测技术将不可见类别和可见类别分开。
- 领域专家分类:可见类别使用标准分类器、不可见类别使用零样本分类方法,其共同分类可见类别和不可见类别的数据样本。
- Lee et al: 开发了一个基于语言信息上的分层分类方法。(a novelty detector based on a hierarchical taxonomy), 这些方法在知样本上构建了超近义词关系的分类系统。希望以某种方式的不可见类别实体可以被分类进与可见类别最相关的一个。
- Atzmon and Chechik: 设想出一种基于概率的门控机制,将一个拉普拉斯先验引入到门控机制去区分可见类别和不可见类别。然而,训练这个门控是一个挑战性问题,因为,整个训练阶段,不可见类别的视觉特征是不被使用的,为了解决这些问题:**boundary-based OOD classifier、
- semantic encoding classifier、domain detector based on entropy gate**.
另外,这些研究也将OOD技术整合进生成式方法去处理广义零样本任务。
基于图学习的方法
Graph-based Methods
图对于建模一组对象是非常有用的,其有一系列节点和与其相关的边所组成的数据结构。图学习利用机器学习技术去提取相关特征,将图的性质映射为在嵌入空间中具有相同维度的特征向量,
机器学习技术将基于图形的属性转换成一系列特征向量( 并不是将提取信息投影到低维空间中)
一般地,
- 基于图学习方法中每个类别被表示为一个节点。
- 每个节点由其他节点通过边连接。构成它们之间的关系。
潜在的空间中要素的几何结构被保存在图形中,与其他技术相比,形成一个更丰富信息的紧凑表示。
虽然如此,使用结构化信息和不可见类别视觉例子学习一个分类器是一个挑战性问题。并且基于图信息的使用增加了模型的复杂度。
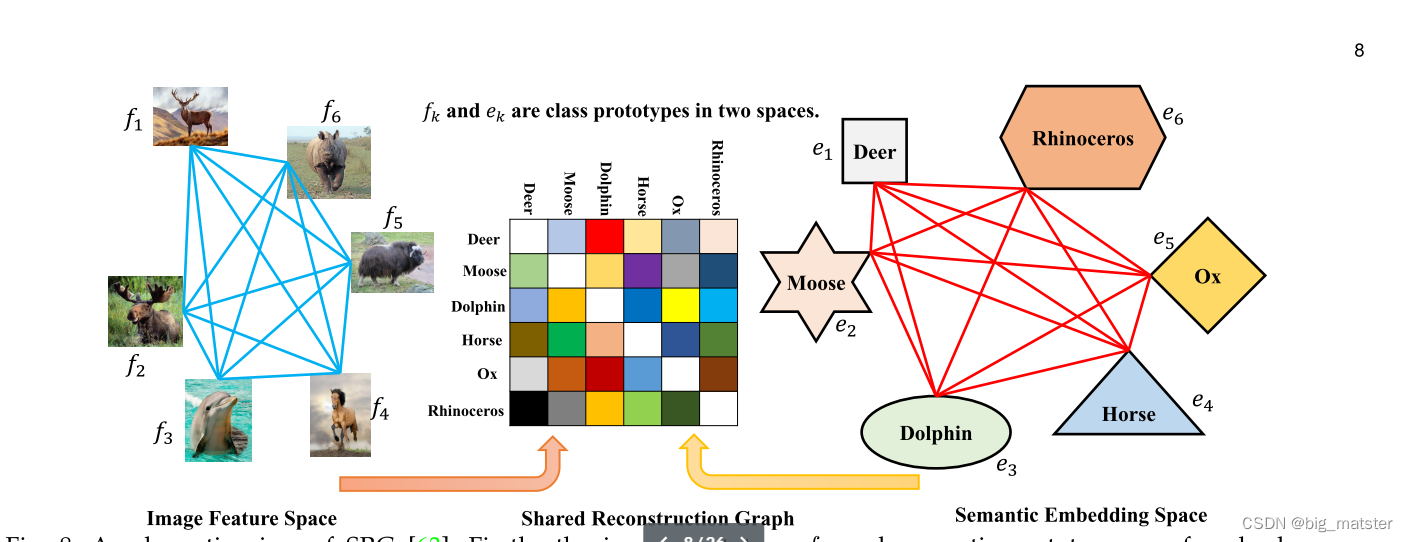
近年来,近年来,图学习技术已经展示了广义零样本学习的有效范式。比如:SRG使用每一类的聚中心去表示图像特征空间中的类原型,基于以下公式重构每一个语义原型:
c k = ∑ i = 1 k a k i b k i = A b k c_k = \sum^k_{i = 1}a^i_kb^i_k = Ab_k ck=i=1∑kakibki=Abk
s . t b k k = 0 s.t b^k_k = 0 s.tbkk=0
b k ∈ R K × 1 b_k \in R^{K \times1} bk∈RK×1,包括这个重构系数,
和 K = 1 , ⋯ , C s + C u K = 1,\cdots,C_s + C_u K=1,⋯,Cs+Cu
在学习不同类别的 图像关系后,学习两个空间的共享重构系数去合成不可见类别的图像原型。
SRG包含系数约束(a sparsity constraint)
有能力使模型将类别分为不同子空间的许多类簇。
整个建模过程中,正则化项选择较少的和相关的类别。重构系数是共享的,为了将知识从语义原型迁移到图像原型。另外,使用不可见语义嵌入方法去缓解the projection domain shift problem。
可见图像原型图被用来缓解the space shift problem。
广义零样本,比如基于图形的非对称的零样本方法,
AGZSL [99], i.e., asymmetric graph-based ZSL, combines the class-level semantic manifold with the instance-level visual manifold by constructing an asymmetric graph. In
addition, a constraint is made to project the visual and attribute features orthogonally when they belong to different classes.
一些研究利用图卷积神经网络(GCN)去迁移不同类别间的知识。使用GCN去生成图形语义空间中的超类别,使用相似性距离去最小化可见类别视觉特征和语义表示的距离,使用a triplet margin loss function去优化去解决维度灾难问题。 - DAGDA使用diffusion-based GCN为每个类别生成anchors。
- Specifically, a semantic relation regularization is derived to refine the distribution in the anchor space
为了缓和维度灾难问题,使用两个自编码器保持潜在空间的原始信息,
- Xie et al: 设计一个注意力技术,发现图像中最重要的regions,将这些regions作为一个节点去表示一张图。
基于元学习方式
元学习被认为学会学习,是一系列学习范式的集合,从其他学习算法中学习。
其目的是从一系列辅助任务中提取迁移知识,
为了设计一个模型去解决过拟合问题。元学习方法的基本原则是为特定数据集去识别最优学习算法,元学习提高了学习算法的性能,根据实验结果去改善一些方面,通过最优化实验数量。
一些研究利用元学习策略去解决广义零样本问题,基于广义零样本的元学习将训练集非常两个集合,support and query,这与可见类别和不可见类别是等价的,随机选择类别训练不同的任务,这种机制帮助元学习方法去迁移知识从可见类别到不可见类别,因此,避免了the bias problem。
-
Sung et al: 使用元学习网络去训练一个辅助化参数,目的是参数化广义零样本的前馈网络,特别地,设计一个a relation module去计算相似性矩阵,在协作模块输出和数据样本的特征向量之间,因此,使用学习参数去识别,
-
-
元学习方法包含任务模块去提供初始化程序和a correction module去更新初始化预测。设计多种多样的任务模块去学习训练样本的不同集合,
设计多种任务的模块学习训练样本不同subsets,
然后,从任务模块的预测,在整个训练模块中被更新,基于广义零样本生成式元学习的案例也可以被使用。
Attention-based Methods
与学习一个在基于视觉特征和语义向量嵌入空间其他方法不同的是,基于注意力的方法聚焦于学习图像的关键性区域,换句话说,注意力机制将权重添加进深度学习模型中作为训练参数去加强输入的最重要部分。比如:sentences和images。普遍地,基于注意力的方法对识别细粒度类是有效的,因为这些类别仅在一些区域中包含判别信息,遵循注意力机制方法的基本原则,图像被分成许多区域,使用注意力技术来识别最重要的区域,注意力机制的主要优势是其有能力去识别与输入执行任务有关的重要信息,学习改善结果,另一方面,基于注意力机制生成越来越多的计算精度,影响注意力机制的实时实现。
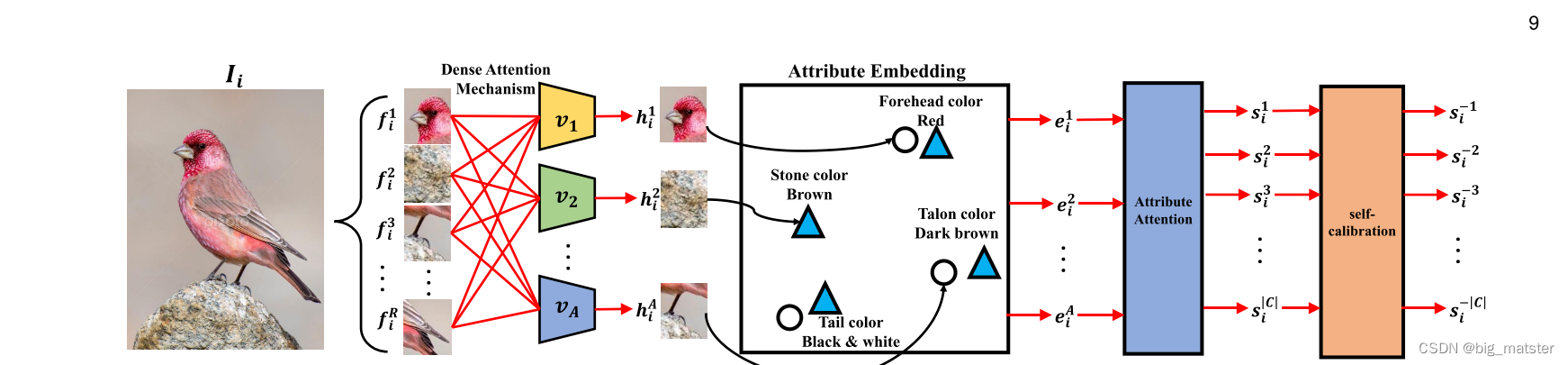
- The dense attention zero-shot learning:通过聚焦更相关的属性区域提炼每一个属性来获取视觉特征。设计一个属性嵌入技术(an attribute embedding techtique )去调整每一个获得的属性特征使其与语义向量属性相同维度。
*解决多标签广义零样本问题的相似性方法时(multi-label GZSL)问题的措施为: - The attention region embedding network(AREN): 使用一个带注意力的二阶嵌入机制,去自动化发现判别性区域并捕捉t二阶分序差异。
关键词: an attention compressed second-order embedding mechanism
the discriminative regions
the second-ordered appearance differences.
使用语义表示将视觉特征生成特征图:
an attention map。
使用自注意力机制来测量每个维度的the focus ratio vector 去计算这个嵌入空间。 - Zhu et al :使用多头注意力将视觉特征映射为一系列有限的特征向量。
the visual features、a finite set of features vectors。
将建模的特征向量作为C-dimensional Gaussian mixture model with the isotropic components.
使用低维度的嵌入机制允许模型去聚焦图像中更重要的区域,联同删除更多不相关的特征。、
因此,降低这个the semantic-visual gap.
另外,广义零样本提出这个a visual oracle去提供缺失类和现存类的信息。 - 由人类注行为引发灵感设计出来的The gaze estimation module(GEM):更加关注判别式属性物体的部分,目的时改善判别式属性的局部性。
使用局部属性将局部特征投影到语义空间,其利用一个全局池化方案作为一个聚集机制,进一步降低误差。(不可见类别获得的模式与那些可见类别获得的模式是相似的),能够提升局部性,
相反,the semantic-guided multi-attention(SGMA)局部特征共同学习全局和局部特征来提供丰富的视觉信息。 - Liu et al: 使用一个图注意力网络(graph attetnion network)去产生每个类别的优化属性向量,
- Ji et al: 提出了一个语义注意网络(a semantic attention network去选择每个训练类别视觉样本的数量,去确保在每次训练迭代时,每个类别贡献相等,(each class contributes equally)
- 另外,提出的模型搜索语义表示从其他类别中分离某一类别,另一方面,Paz et.al设计visually relevant language 去提取噪音文本的相关性句子。
Compositional learning-based model
CL目的是学习一个模型去识别出已知物体中不可见成分的贡献,fish and cat primitive states。
cute and old。
近年来,CL的概念已经被应用到零样本学习中,被称为组合零样本学习。(Compositional ZSL)
- kao et,al: 引入一个框架去识别零样本学习行为,(zeor-hot human actions)
- 使用GCN,build an external knowledge graph based on the extracted subject, verb and object (SVO) triplets [129] from knowledge bases,
为了去记录一系列人类对象交互性,图中的每个节点因为一个(a noun)或(a verb)将词嵌入作为其特征。 - Each action node, which is represented by
a SVO-triplet, propagates information along the graph to
learn its representations
最后,视觉特征和学习图能够共同绘制潜在空间为零样本识别和人类行为。
The task-driven modular network(TMN)使用一个模块化结构将概念迁移到CNNs的高层次语义空间中,extracts features that are related
to all members of the input triplet to determine the joint-compatibility among visual features and object attributes - Sylvain et,al:富有经验的强调了聚焦于局部图像区域的重要性,还有结合局部知识去识别不可见类别,这些工作已经被其后续研究所支持。
Bidirectional learning Methods(双向学习)
这个类别利用双向投影去充分利用数据样本的信息和学习更加一般化的投影,为了区分可见类别和不可见类别。视觉和语义空间共同投进共享子空间。每个空间都被重构通过一个双向投影学习。
- The dual-triple network(DTNet)网络使用tow triplet模块去重新构建区分性的矩阵空间,
一些研究者考虑到类被间的属性关系通过学习一个属性空间到视觉空间的映射,然而,另一些研究者考虑到视觉特征,(visual features)
Guo et al:通过引入一个损失函数来考虑,a dual-view ranking。共同最小化这个这个图像视图标签和label-view image rankings。
这个模型去训练一个更好地图像标签匹配模型,特别低,在任何训练样本任何其他标签之前的排名正确的标签。
the label-view image 的目的是考虑到图像的其他类的时候将各自的图像考虑到正确类别。
另外,一种密集的自适应边距(a density adaptive margin设置一个基于数据样本的边距。这是因为在不同特征空间中,有多种多样密集图像,并且不同的图像有不同的相似度得分(Similarity scores).
这个模型提出包含两个部分: - 使用回归学习一个嵌入空间(visual-label activating).
- semantic-label activatiing:学习一个语义空间到标签空间的投影函数,
另外,在语义和标签之间的双向限制性约束,去缓解the projection shift problem - Zhang et.al:
解决了一个类别级水平的过拟合问题,
It is related to parameter fitting during training
without prior knowledge about the unseen classes
为了解决这些问题,TVN(a triple verification network)解决广义零样本的a vertification task。
这些验证性程序的目的是预测被给的一些样本是否属于tha same class 或其他类别。
TVN模型架构将可见类别投影到正交空间,为了得到一个更好的绩效和更加较快的收敛速度,
继而,提出一个DR方法,在视觉特征和语义表示之间做回归,(与不可见类别相容的语义表示)
Autoencoder-based Methods
Autoencoders (AEs) NNS: 表征学习
结合the similarity level。cosine distance、
-
Latent space encoding(LSE)
-
Product quantization ZSL(PQZSL):
an orthogonal common space、a center loss function。 -
two variational auto-encoder (VAE) models: the cross-modal latent features。
-
Cross alignment and distribution alignment strategies are devised to match
the features from different spaces.
other methods
除了上面提到的方法以外,一些研究也使用多种多样的策略去处理广义零样本问题,
一些研究设计的方法考虑到了,the inter-class and intra-class 关系,在不同了类别间。
-
Das and Lee:using the least square loss method 、Rational matrices
-
the inter-class pairwise relations between two spaces.
-
a point-to-point correspondence between the semantic representations and test samples is found
-
TCN:The transferable construction network:考虑了两部分的信息:fusion and constructive learning。
-
the joint optimization of center loss and softmax loss functions are adopted to learn more discriminative visual features for different classes while minimizing the intra-class variations. Besides that, the performance of GZSL can be improved by rectifying the model output.
The studies in [145], [146] devise a dictionary-based
framework for GZSL. The model proposed in [145] jointly
aligns the visual-semantic structure to constructs a class
structure between the visual and semantic spaces by ob-
taining the class prototypes in both spaces. The aim is to
explore some bases in each space to represent each class. A
domain adaptation is proposed to learn the prototypes from
both seen and unseen classes in the visual space, in order
to alleviate the problem of the projection domain shift. On
the other hand, study [146] incorporates a sparse coding
technique to construct a dictionary for each projection, i.e.,
visual-latent and semantic-latent, and applies an orthogonal
projection to make the model discriminative.
Since the information obtained from the semantic repre-
sentations, in particular human-defined attributes, is limited
and less discriminative, recognizing data samples from dif-
ferent classes in a specific domain is difficult. The studies
in [72], [145], [147], [148] aim to address this issue. The
study [72] decomposes the semantic vectors of the training
set into K subsets using the k-means clustering algorithm,
and projects them to the visual space. This decomposition
allows the model to construct a uniform embedding space
with a large local relative distance. Similar to [72], Li et
al. [103] used super-classes, which are generated by data-
driven clustering, across the seen and unseen class domains
to tune two domains. Jin et al. [147] projected the semantic
vector of each class to a high-order attribute space by apply-
ing the Gaussian random projection. The model proposed
in [148] defines a discriminative label space and projects the visual features via a linear projection matrix to that space. Specifically, it fixes the labels of the seen classes and uses the attributes to map the label of the unseen classes into the label space。
总结
本篇文章先到此为止,后续文章的学习,先将上面部分文章搞清楚,
接下来在开始其他的文章学习,全部都将其搞彻底都行啦的回事与打算。
了解以下总共的概览。(停四五天,再开始搞生成式方法)全部将其搞定都行啦的理由与打算。
Generative-based Methods
学习心得
停下来,先不搞的,将前面学习的模型大致先弄透彻,慢慢的再开始研究其他的东西,全部将其搞定再说的样子与打算。现在学习后面的与没学一球样。没一点意思。
*
学习心得
- 读文章的时候,有舍去,有丢失。会捡重要的去读,挑取少的阅读。这个是根本的含义。
- 写论文的时候,用Xmind将写一个文章关键词的笔记,全部都将其搞定都行啦的理由与打算。
- 总结学习笔记的时候,将各种问题及其偏移情况都给总结以下,将各种问题都总结以下。
- 翻译不恰当的地方会自己结合原文将问题进行总结以下。
- 学习文章的时候,会自己重视,各种域问题,全部将其搞定都行啦的理由与打算。
- 各种问题会自己全部将其搞定都行,会进行分析与透彻掌握!
- 啥球栏东西呀,给这方面的每个模型都好好研究一波,全部将其搞 透彻,并且将这方面的所有模型都深入了解,了解其优缺点,学习其套路,全部将其搞定都行啦。