文章目录
- 概述
- Managed State
- Operator State
- ListState
- BroadcastState
- Keyed State
- ValueState
- ListState
- MapState
- ReducingState
- AggregatingState
- 状态后端
- Appendix
概述
流式计算 分为 无状态计算 和 有状态计算
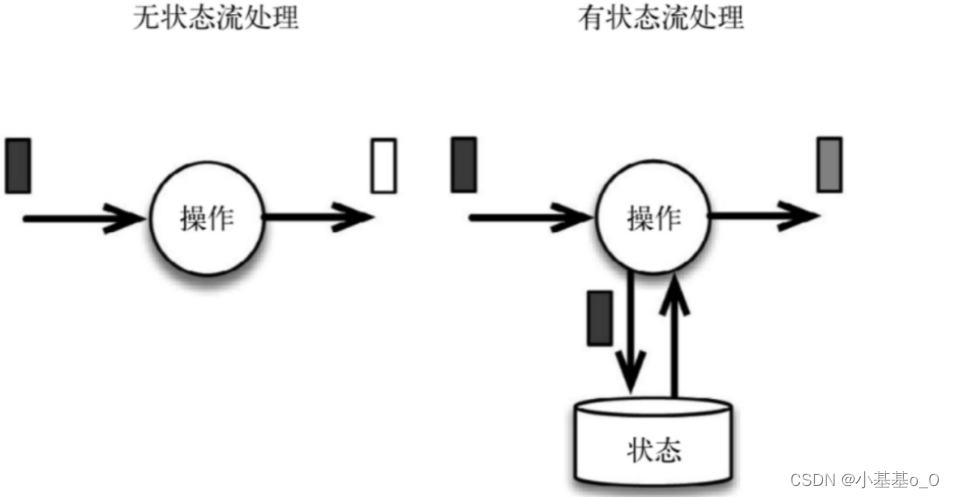
流处理的状态功能:去重、监控……
| 状态分类 | Managed State | Raw State |
|---|---|---|
| 状态管理方式 | Flink Runtime托管,自动存储,自动恢复,自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供多种数据结构,例如:ListState、MapState等 | 字节数组:byte[] |
| 使用场景 | 多数Flink算子 | 所有算子 |
Managed State
RawState是在已有算子和ManagedState不够用时才使用
一般来说,ManagedState已经够用,下面重点学习
| Managed State 分类 | Operator State | Keyed State |
|---|---|---|
| 译名 | 算子状态 | 键控状态 |
| 状态分配 | 1个算子的子任务对应1个State | 1个算子处理多个Key,1个Key对应1个State |
| 出场率 | 较低 | 较高 |
本文开发环境是WIN10+IDEA;Flink版本是1.14
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.6</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>2.0.3</slf4j.version>
<log4j.version>2.17.2</log4j.version>
<fastjson.version>2.0.19</fastjson.version>
<lombok.version>1.18.24</lombok.version>
</properties>
<!-- https://mvnrepository.com/ -->
<dependencies>
<!-- Flink -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
Operator State
- 算子状态可用在所有算子上,每个算子子任务(SubTask)共享一个状态
算子子任务之间的状态不能互相访问 - 下面以列表状态和广播状态为例
ListState
列表状态 可与 检查点 合用,来 定期保存和清空状态
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class Hello {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//每3秒1次Checkpointing
env.enableCheckpointing(3000L);
//创建数据源,每秒1个数据
DataStreamSource<Integer> dss = env.addSource(new MySource());
//测试状态和检查点
dss.map(new MyMapFunction()).print();
//流环境执行
env.execute();
}
private static class MyMapFunction implements MapFunction<Integer, String>, CheckpointedFunction {
private ListState<Integer> state;
@Override
public String map(Integer value) throws Exception {
state.add(value);
return state.get().toString();
}
@Override
public void snapshotState(FunctionSnapshotContext context) {
System.out.println("Checkpoint时调用snapshotState,清空状态");
state.clear();
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("创建状态");
state = context.getOperatorStateStore().getListState(new ListStateDescriptor<>("", Integer.class));
}
}
public static class MySource implements SourceFunction<Integer> {
public MySource() {}
@Override
public void run(SourceContext<Integer> sc) throws InterruptedException {
for (int i = 0; i < 99; i++) {
sc.collect(i);
Thread.sleep(1000L);
}
}
@Override
public void cancel() {}
}
}
测试结果
创建状态
[0]
[0, 1]
Checkpoint时调用snapshotState,清空状态
[2]
[2, 3]
[2, 3, 4]
Checkpoint时调用snapshotState,清空状态
[5]
[5, 6]
[5, 6, 7]
Checkpoint时调用snapshotState,清空状态
[8]
……
BroadcastState
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.util.Scanner;
public class Hello {
final static String STATE_KEY = "";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(3);
//1、主数据流
DataStreamSource<Integer> mainStream = env.addSource(new AutomatedSource());
//1、控制主数据的辅助流
DataStreamSource<String> branchStream = env.addSource(new ManualSource());
//2、创建状态描述符
MapStateDescriptor<String, Long> stateDescriptor = new MapStateDescriptor<>("", String.class, Long.class);
//2、创建广播流
BroadcastStream<String> broadcastStream = branchStream.broadcast(stateDescriptor);
//3、主数据流 连接 广播流
BroadcastConnectedStream<Integer, String> b = mainStream.connect(broadcastStream);
//BroadcastProcessFunction<IN1, IN2, OUT>
b.process(new BroadcastProcessFunction<Integer, String, String>() {
//processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out)
@Override
public void processBroadcastElement(String value, Context ctx, Collector<String> out) throws Exception {
//4、获取广播状态
BroadcastState<String, Long> state = ctx.getBroadcastState(stateDescriptor);
//4、修改广播状态
state.put(STATE_KEY, Long.valueOf(value));
}
//processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out)
@Override
public void processElement(Integer value, ReadOnlyContext ctx, Collector<String> out) throws Exception {
//5、获取只读广播状态
ReadOnlyBroadcastState<String, Long> state = ctx.getBroadcastState(stateDescriptor);
//5、从广播状态中取值
Long stateValue = state.get(STATE_KEY);
//6、输出
if (stateValue != null) {
out.collect("有请" + value + "号佳丽进入" + stateValue + "号舞台");
}
}
}).print();
//流环境执行
env.execute();
}
/** 手动输入的数据源 */
public static class ManualSource implements SourceFunction<String> {
public ManualSource() {}
@Override
public void run(SourceFunction.SourceContext<String> sc) {
Scanner scanner = new Scanner(System.in);
while (true) {
String str = scanner.nextLine().trim();
if (str.equals("STOP")) {break;}
if (!str.equals("")) {sc.collect(str);}
}
scanner.close();
}
@Override
public void cancel() {}
}
/** 自动输入的数据源 */
public static class AutomatedSource implements SourceFunction<Integer> {
public AutomatedSource() {}
@Override
public void run(SourceFunction.SourceContext<Integer> sc) throws InterruptedException {
for (int i = 0; i < 999; i++) {
Thread.sleep(2000);
sc.collect(i);
}
}
@Override
public void cancel() {}
}
}
测试结果截图

Keyed State
ValueState<T>
存储单个值ListState<T>
存储元素列表MapState<UK, UV>
存储键值对ReducingState<T>
存储单个值;当使用add时,ReducingState会使用指定的ReduceFunction进行聚合AggregatingState<IN, OUT>
类似ReducingState,区别是:AggregatingState的 聚合结果OUT与 输入IN可以不同
ValueState
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Hello {
public static void main(String[] args) throws Exception {
//创建流执行环境,并行度=1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建数据源
DataStreamSource<Integer> dss = env.fromElements(9, 5, 2, 7);
dss
.keyBy(i -> true)
.process(new KeyedProcessFunction<Boolean, Integer, String>() {
//1、声明状态变量
private ValueState<Integer> state;
@Override
public void open(Configuration parameters) {
//2、key范围内,实例化状态变量,状态变量是单例的
state = getRuntimeContext().getState(new ValueStateDescriptor<>("", Integer.class));
}
@Override
public void processElement(Integer i, Context context, Collector<String> out) throws Exception {
//3、获取上一次状态的值
Integer lastStateValue = state.value();
if (lastStateValue != null) {
//输出
out.collect("当前输入:" + i + ";上次状态值:" + lastStateValue);
}
//4、更新状态的值
state.update(i);
}
})
.print();
env.execute();
}
}
-
print
-
当前输入:5;上次状态值:9
当前输入:2;上次状态值:5
当前输入:7;上次状态值:2
ListState
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Hello {
public static void main(String[] args) throws Exception {
//创建流执行环境,并行度=1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建数据源
DataStreamSource<Integer> dss = env.fromElements(9, 5, 2, 7);
dss
.keyBy(i -> true)
.process(new KeyedProcessFunction<Boolean, Integer, String>() {
//1、声明状态列表
private ListState<Integer> state;
@Override
public void open(Configuration parameters) {
//2、实例化状态列表(key范围内单例)
state = getRuntimeContext().getListState(new ListStateDescriptor<>("", Integer.class));
}
@Override
public void processElement(Integer i, Context context, Collector<String> out) throws Exception {
//3、添加状态值
state.add(i);
//4、获取并收集状态列表
out.collect(state.get().toString());
}
})
.print();
env.execute();
}
}
-
print
-
[9]
[9, 5]
[9, 5, 2]
[9, 5, 2, 7]
MapState
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Hello {
public static void main(String[] args) throws Exception {
//创建流执行环境,并行度=1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建数据源
DataStreamSource<Integer> dss = env.fromElements(9, 5, 2, 7);
dss
.keyBy(i -> true)
.process(new KeyedProcessFunction<Boolean, Integer, String>() {
//1、声明状态映射
private MapState<String, Integer> state;
@Override
public void open(Configuration parameters) {
//2、实例化状态映射(分区范围内单例)
state = getRuntimeContext()
.getMapState(new MapStateDescriptor<>("", String.class, Integer.class));
}
@Override
public void processElement(Integer i, Context context, Collector<String> out) throws Exception {
//3、添加键值对put(key,value)
state.put(i.toString(), i);
//4、并收集状态
out.collect("keys:" + state.keys().toString());
out.collect("values:" + state.values().toString());
}
})
.print();
env.execute();
}
}
-
print
-
keys:[9]
values:[9]
keys:[5, 9]
values:[5, 9]
keys:[2, 5, 9]
values:[2, 5, 9]
keys:[2, 5, 7, 9]
values:[2, 5, 7, 9]
ReducingState
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Hello {
public static void main(String[] args) throws Exception {
//创建流执行环境,并行度=1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建数据源
DataStreamSource<Integer> dss = env.fromElements(9, 5, 2, 7);
dss
.keyBy(i -> true)
.process(new KeyedProcessFunction<Boolean, Integer, String>() {
//1、声明状态
private ReducingState<Integer> state;
@Override
public void open(Configuration parameters) {
//2、实例化状态列表(key范围内单例)
state = getRuntimeContext()
.getReducingState(new ReducingStateDescriptor<>("", Integer::sum, Integer.class));
}
@Override
public void processElement(Integer i, Context context, Collector<String> out) throws Exception {
//3、添加状态值
state.add(i);
//4、获取并收集状态结果
out.collect("归约值:" + state.get());
}
})
.print();
env.execute();
}
}
-
print
-
归约值:9
归约值:14
归约值:16
归约值:23
AggregatingState
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Hello {
public static void main(String[] args) throws Exception {
//创建流执行环境,并行度=1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//创建数据源
DataStreamSource<Long> dss = env.fromElements(9L, 5L, 2L, 7L);
dss
.keyBy(i -> true)
//KeyedProcessFunction<K, I, O>
.process(new KeyedProcessFunction<Boolean, Long, Integer>() {
//1、声明状态AggregatingState<IN, OUT>
private AggregatingState<Long, Integer> state;
@Override
public void open(Configuration parameters) {
//2、创建状态描述器;AggregatingStateDescriptor<IN, ACC, OUT>
AggregatingStateDescriptor<Long, String, Integer> stateDescriptor =
//AggregatingStateDescriptor(String name,aggFunction,TypeInformation<ACC> stateType)
new AggregatingStateDescriptor<>("",
//aggFunction:AggregateFunction<IN, ACC, OUT>
new AggregateFunction<Long, String, Integer>() {
@Override
public String createAccumulator() {
return "";
}
@Override
public String add(Long value, String accumulator) {
return accumulator + value;
}
@Override
public Integer getResult(String accumulator) {
return Integer.valueOf(accumulator);
}
@Override
public String merge(String a1, String a2) {
return a1 + a2; //合并两个累加器
}
}, Types.STRING);
//3、分区范围内创建状态单例对象
state = getRuntimeContext().getAggregatingState(stateDescriptor);
}
@Override
public void processElement(Long value, Context ctx, Collector<Integer> out) throws Exception {
//5、添加到状态
state.add(value);
//6、获取并收集状态列表
out.collect(state.get());
}
})
.print();
env.execute();
}
}
-
print
-
9
95
952
9527
状态后端
- 状态后端(state backend)
一个可插入的组件,用来 存储、访问以及维护 状态 - 作用:
本地的状态管理(本地状态存储在TaskManager的内存中)
将checkpoint状态写入文件系统(如HDFS)
| 分类 | 本地状态存储 | checkpoint状态存储 | 特点 | 备注 |
|---|---|---|---|---|
| MemoryStateBackend | TaskManager的内存 | JobManager的内存 | 快、不稳 | 弃用的 |
| FsStateBackend | TaskManager的内存 | 文件系统 | 稳 | 弃用的 |
| RocksDBStateBackend | TaskManager的内存和RocksDB | 文件系统 | 稳 | 超大状态的作业 |
然而发现Flink1.14.6弃用了MemoryStateBackend和FsStateBackend的写法
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new FsStateBackend(String checkpointDataUri));
//URI (e.g., 'file://', 'hdfs://', or 'S3://')
于是改用下面
//允许Checkpointing,每3秒1次
env.enableCheckpointing(3000L);
//设置状态后端
env.setStateBackend(new HashMapStateBackend());
//获取Checkpointing配置
CheckpointConfig config = env.getCheckpointConfig();
//检查点状态 存储到 JobManager的内存
config.setCheckpointStorage(new JobManagerCheckpointStorage());
//检查点状态 存储到 文件系统
config.setCheckpointStorage(new FileSystemCheckpointStorage(String checkpointDirectory));
Appendix
| 英 | 🔉 | 中 |
|---|---|---|
| runtime | ˈrʌntaɪm | n. 运行时间;运行时(环境) |
| context | ˈkɑːntekst | n. 上下文,语境 |
| managed | ˈmænɪdʒd | adj. 受监督的;v. 经营(manage 的过去式及过去分词) |
| operator | ˈɑːpəreɪtər | n. (机器的)操作员;运算符号;算子 |
| descriptor | dɪˈskrɪptər | n. 描述符号 |