文章目录
- 前言
- 一、Java中线程池概览
- 1.1 类图
- 1.2 内部流程图
- 二、源码探索
- 2.1 构造参数
- 2.2 线程池状态
- 2.3 Worker 的添加和运行
- 2.4 阻塞队列
- 2.5 任务拒绝策略
- 三、实际使用
- 3.1 动态线程池
- 3.2 拓展使用
- 3.3 springboot 中线程池
- 参考
前言
在高并发的 Java 程序设计中,编写多线程代码可以最大限度发挥现代多核处理器的计算能力,提升系统的吞吐和性能。线程是多线程代码的基础工具,但不能无限制增加线程的数量,线程的创建和销毁、所占内存都要消耗系统资源,如果处理不当,可能会导致 OOM,并且大量线程的回收也会给 GC 带来压力,延长停顿时间。
在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。和数据库连接池类似,使用线程池有以下优点:
- 降低资源消耗:减少新建和销毁线程所调用的资源
- 提高响应速度:任务到达时,不需要等待新建线程后执行任务
- 提高线程的可管理性:线程是有限的资源,如果创建太多可能会导致系统故障,使用线程池可以做到统一的分配,调用和监控
一、Java中线程池概览
在 Java 中讲线程池一般是指 JDK 中提供的 ThreadPoolExecutor 类,这是由 Doug Lea 操刀实现的线程池类。
JDK 中并发包 java.util.concurrent(简称 JUC )是由这位大佬开发的,包含很多Java开发者常用的并发类如 ConcurrentHashMap、ReentrantLock、AtomicInteger、CountDownLatch 等等
下面会从类图,线程池运行流程图来简单概览
1.1 类图

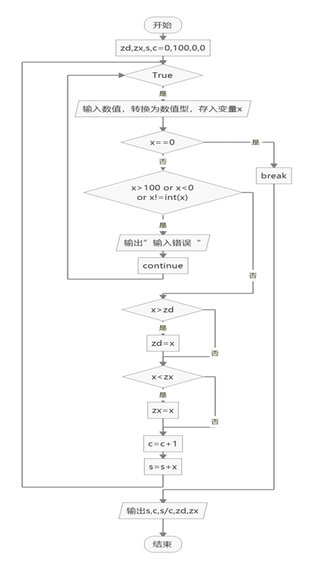
1.2 内部流程图
二、源码探索
下面会从源码分析 ThreadPoolExecutor
2.1 构造参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
| 构造函数参数名 | 是否必填 | 范围或类型 | 含义 |
|---|---|---|---|
| corePoolSize | 是 | 0 到 Integer.MAX_VALUE | 核心线程数 |
| maximumPoolSize | 是 | 1到 Integer.MAX_VALUE,并且要 > corePoolSize | 最大线程数 |
| keepAliveTime | 是 | 0 到 Long.MAX_VALUE | 当线程数大于核心线程时,空闲线程存活时间 |
| unit | 是 | TimeUnit | keepAliveTime 时间单位 |
| workQueue | 是 | BlockingQueue<Runnable> | 任务队列 |
| threadFactory | 否 | ThreadFactory | 线程工厂,默认提供工厂,名字以"pool-" + poolNumber.getAndIncrement() + “-thread-” 为前缀 |
| handler | 否 | RejectedExecutionHandler | 拒绝策略,默认 AbortPolicy,直接抛异常 |
2.2 线程池状态
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3; // 29
private static final int CAPACITY = (1 << COUNT_BITS) - 1; //0x1fffffff
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS; //0xe0000000
private static final int SHUTDOWN = 0 << COUNT_BITS; //0x00000000
private static final int STOP = 1 << COUNT_BITS; //0x20000000
private static final int TIDYING = 2 << COUNT_BITS; //0x40000000
private static final int TERMINATED = 3 << COUNT_BITS; //0x60000000
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
线程池的状态,主要保存在 ctl 这个 AtomicInteger 变量中,由两部分构成,runState 和 workerCount。前3位存状态,后面29位存worker数量
- workerCount 线程worker 数量, 这是允许启动而不允许停止的worker的数量。该值可能暂时不同于实际的活动线程数。
- runState 提供线程池主要的生命周期控制
- RUNNING: 接受新任务并处理队列任务
- SHUTDOWN:不接受新任务,但处理队列任务
- STOP:不接受任务,不处理队列任务,并中断正在进行的任务
- TIDYING:所有任务都已终止,workerCount为零,转换到状态TIDYING的线程将运行terminated()钩子方法
- TERMINATED:terminated() 执行完成
线程池状态转化:
线程池的 toString 方法会返回线程池的状态,不过只返回三种,会将上述五种状态中间的三种状态归于一种
- Running RUNNING
- Shutting down SHUTDOWN、STOP、TIDYING
- Terminated TERMINATED
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
String rs = (runStateLessThan(c, SHUTDOWN) ? "Running" :
(runStateAtLeast(c, TERMINATED) ? "Terminated" :
"Shutting down"));
2.3 Worker 的添加和运行
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程 Worker。
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
...
}
-
增加Worker
worker 的增加由方法
boolean addWorker(Runnable firstTask, boolean core)实现,内部流程如下:
 在在Worker类中的run方法调用了runWorker方法来执行任务,runWorker方法的执行过程如下:
在在Worker类中的run方法调用了runWorker方法来执行任务,runWorker方法的执行过程如下:
- while循环不断地通过getTask()方法获取任务。
- getTask()方法从阻塞队列中取任务。
- 如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态。
- 执行任务。
- 如果getTask结果为null则跳出循环,执行processWorkerExit()方法,销毁线程。

2.4 阻塞队列
用于保存任务并移交给工作线程的队列.
常用队列如下表所示:
| 队列名 | 元素出入顺序 | 描述 |
|---|---|---|
| ArrayBlockingQueue | 队列元素FIFO | 数组实现的有界阻塞队列,支持公平锁和非公平锁 |
| LinkedBlockingQueue | 队列元素FIFO | 链表实现的有界阻塞队列. 链表队列通常比数组队列具有更高的吞吐量,但在大多数并发应用程序中,其性能不可预测。 容量(可选)可通过构造函数参数配置,用于防止过度的队列扩展。如果未指定,则容量等于Intger.MAX_VALUE。 |
| PriorityBlockingQueue | 根据优先级,但是不能保证同优先级的顺序 | 元素具有优先级的无界阻塞队列,无界在逻辑上是无限,但在OOM的情况下会添加失败。 队列内元素必须是可比较的,且不能为null。 |
| DelayQueue | 根据到期时间排列,队列的头部是延迟过期时间最长的延迟元素 | 具有延迟元素的无界阻塞队列,延迟元素指元素需要在队列中等待一段时间才能被取用。 |
| SynchronousQueue | 队列的元素插入完成必须等待另一个线程取出,反之亦然 | 一种不存储元素的阻塞队列,支持公平锁和非公平锁 |
| LinkedTransferQueue | 无界阻塞队列,队列的头部是某个生产者在队列中停留时间最长的元素,尾部是某个生产者在队列中停留时间最短的元素 可以看做是 LinkedBolckingQueue 和 SynchronousQueue 的合体 | |
| LinkedBlockingDeque | 对头和对尾都可出入 | 链表实现的双端有界阻塞队列,高并发时可将锁的竞争最多下降一半 |
2.5 任务拒绝策略
线程池的任务拒绝策略都实现了 RejectedExecutionHandler 接口,ThreadPoolExecutor 内部提供了四种拒绝策略,也可以自定义实现
| 策略类名 | 含义 | 备注 |
|---|---|---|
| AbortPolicy | 直接抛异常,这是默认策略 | 比较关键的业务推荐使用此策略,能够及时发现异常 |
| CallerRunsPolicy | 由提交任务的线程执行,会调用任务的run方法,而不是start | 如果线程池关闭了,任务会被丢弃。这种策略一般是需要任务都要执行,但是当任务数量过多就会把提交任务的线程阻塞住。需要权衡考虑 |
| DiscardPolicy | 直接丢弃 | 不重要的任务可以使用此策略 |
| DiscardOldestPolicy | 丢弃队列头部的任务,重新提交 | 队列头部的任务是最老的任务,需要根据业务衡量是否采用此种策略 |
三、实际使用
3.1 动态线程池
线程池使用面临的核心的问题在于:线程池的参数并不好配置。如果要修改运行中应用线程池参数,需要停止线上应用,调整成功后再发布,而这个过程异常的繁琐,如果能在运行中动态调整线程池的参数多好。
美团技术团队基于这些痛点,推出了 动态线程池 的概念,催生了一批动态线程池框架,hippo4j 也是其一。
动态化线程池的核心设计包括以下三个方面:
-
简化线程池配置:线程池构造参数有8个,但是最核心的是3个:corePoolSize、maximumPoolSize,workQueue,它们最大程度地决定了线程池的任务分配和线程分配策略。考虑到在实际应用中我们获取并发性的场景主要是两种:
- 并行执行子任务,提高响应速度。这种情况下,应该使用同步队列,没有什么任务应该被缓存下来,而是应该立即执行。
- 并行执行大批次任务,提升吞吐量。这种情况下,应该使用有界队列,使用队列去缓冲大批量的任务,队列容量必须声明,防止任务无限制堆积。
所以线程池只需要提供这三个关键参数的配置,并且提供两种队列的选择,就可以满足绝大多数的业务需求,Less is More。
-
参数可动态修改:为了解决参数不好配,修改参数成本高等问题。在Java线程池留有高扩展性的基础上,封装线程池,允许线程池监听同步外部的消息,根据消息进行修改配置。将线程池的配置放置在平台侧,允许开发同学简单的查看、修改线程池配置。
-
增加线程池监控:对某事物缺乏状态的观测,就对其改进无从下手。在线程池执行任务的生命周期添加监控能力,帮助开发同学了解线程池状态。
hippo4j github 地址:https://github.com/opengoofy/hippo4j
3.2 拓展使用
线程池提供了可被子类拓展的方法 beforeExecute 和 afterExecute ,能够在线程执行前后回调。
3.3 springboot 中线程池
当开启@EnableAsync,使用@Async标记方法时,会通过默认线程池执行。默认线程池
- corePoolSize :8
- maximumPoolSize :Integet.MAX_VALUE,
- workQueue:LinkedBlockingQueue,容量是:Integet.MAX_VALUE,
- keepAliveTime :60
- unit:second
- handler:AbortPolicy
可以看到默认线程池会无限创建线程,实际使用中会手动配置线程池
@EnableAsync
@Configuration
public class ThreadPoolConfig {
@Bean(name = AsyncExecutionAspectSupport.DEFAULT_TASK_EXECUTOR_BEAN_NAME)
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//核心线程池大小
executor.setCorePoolSize(10);
//最大线程数
executor.setMaxPoolSize(30);
//队列容量
executor.setQueueCapacity(100);
//活跃时间
executor.setKeepAliveSeconds(60);
//线程名字前缀
executor.setThreadNamePrefix("taskExecutor-");
// 设置线程池关闭的时候等待所有任务都完成再继续销毁其他的Bean
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
参考
- Java线程池实现原理及其在美团业务中的实践





![[iOS]使用MonkeyDev完成Hook](https://img-blog.csdnimg.cn/9ed53a16f583449086cdd19e3c66a056.png)