第七章 内置容器(五)
8.正则表达式
(1)正则表达式用于描述字符串的复杂文本规则的代码,一般用于查询匹配
(2)常见元字符
<1> 作用:表示特殊含义,一般为范围性的,不好确切描述的字符串
<2> 单字符匹配的元字符:
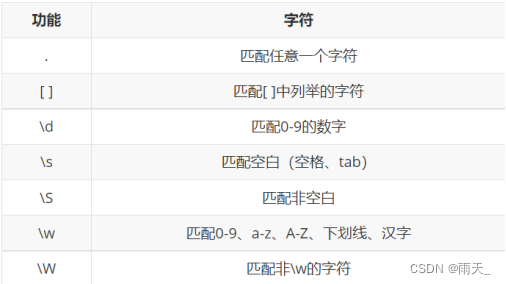
<2> 数量元字符
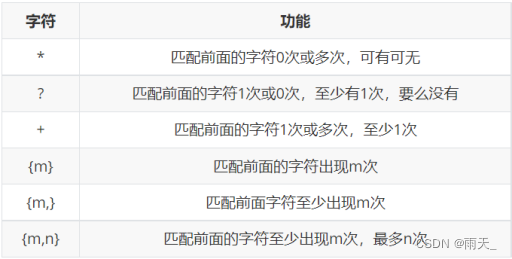
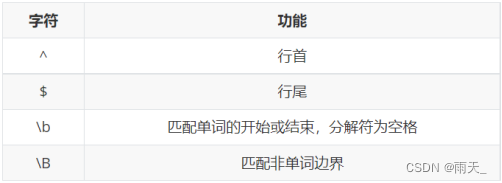
<3> 边界字符
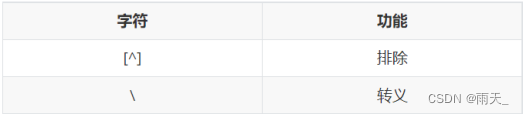
<4> 其他元字符
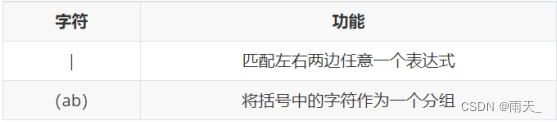
<5> 分组元字符
(3)示例:
<1> 匹配8位qq号
^\d{8}$
<2> 匹配任意元音字母
[aeiou]
<3> 匹配身份证号:18位,前17位数字时,最后一位为x或X进行校验
(^\d{17})(\d|x|x)$
<4> 匹配输入的163、126、qq邮箱,前面至少5位最多11位
r|'\w{5,11}@(163|126|qq).(com|cn)'
<5> 检索python文件名为:xxxx.py
r'\w+\.py\b'
(4)re模块
<1> 需要加载:import re
<2> math()方法
格式:re.math(pattern,string,[flags])
作用:从字符串起始位置开始查找匹配,成功返回math对象,否则返回None,只能匹配一个
- pattern:使用正则表达式表示的模式字符串
- string:要匹配的字符串
- flags:可省略,表示标志位,控制匹配方法。如:是否区分大小写字母
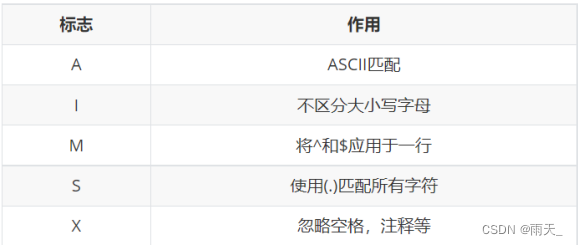
<3> 例:匹配字符串是否以mr_开头,不区分大小写。
import re as s
p = r'mr_\w+' # 模式字符串
str1 = 'MR_SHOP mr_shop'
m = s.match(p, str1, s.I)
print(m)
# <re.Match object; span=(0, 7), match='MR_SHOP'>
# 返回的对象内置多个功能方法
print('匹配值的起始位置:',m.start()) # 0
print('匹配值的结束位置:',m.end()) # 7
print('匹配位置的元组:',m.span()) # (0, 7)
print('匹配的数据:',m.group()) # MR_SHOP
str2 = '123MR_SHOP mr_shop'
n = a.match(p, str2, a.I)
print(n) # None
# 只能在起始位置匹配<4> 例:验证输入的手机号是否为中国移动的号码
import re as a
m = input('请输入手机号:')
p = r'(13[4-9]\d{8})$|(14[01289]\d{8})$'
mt = a.match(p, m)
if mt == None:
print('不是移动号段')
else:
print(m, '是有效的中国移动手机号段')
# 请输入手机号:13512345678
# 13512345678 是有效的中国移动手机号段<5> search()方法匹配:
- 作用:在字符串任意位置进行检索第一个匹配的值,成功则返回search对象,不成功返回None
- 格式:re.search(pattern,string,[flags])
import re as s
p = r'mr_\w+' # 模式字符串
str1 = '123MR_SHOP mr_shop'
m = s.search(p, str1, s.I)
print(m)
# <re.Match object; span=(3, 10), match='MR_SHOP'><6> findall()方法
- 作用:在字符串中检索所有符合正则表达式规则的字符串,并以列表的形式返回,不成功返回空列表
- 格式:re.findall(pattern,string,[flags])




![[附源码]Python计算机毕业设计大学生兼职系统](https://img-blog.csdnimg.cn/bdbe79a1430e4203b0b57123a31d86a8.png)