SimCSE 提供了无监督(上图 a)和有监督(上图 b)两种架构,由于业务需要我们只用了无监督方式,其基本思路是:
1. 同一个 batch 内的数据两次输入模型。
2. 由于有 dropout 机制存在,对于同一句子的两次输出是不同的,两次输出互为正例,其他为负例。
3. 最小化目标函数,进行参数更新。
论文中,在一个 batch 中,样本 i 的损失函数为对比学习的 InfoNCE Loss[8]:
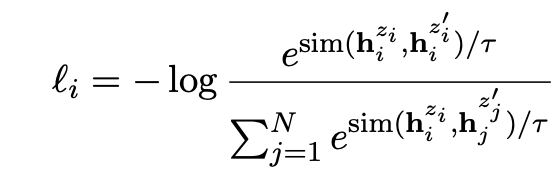
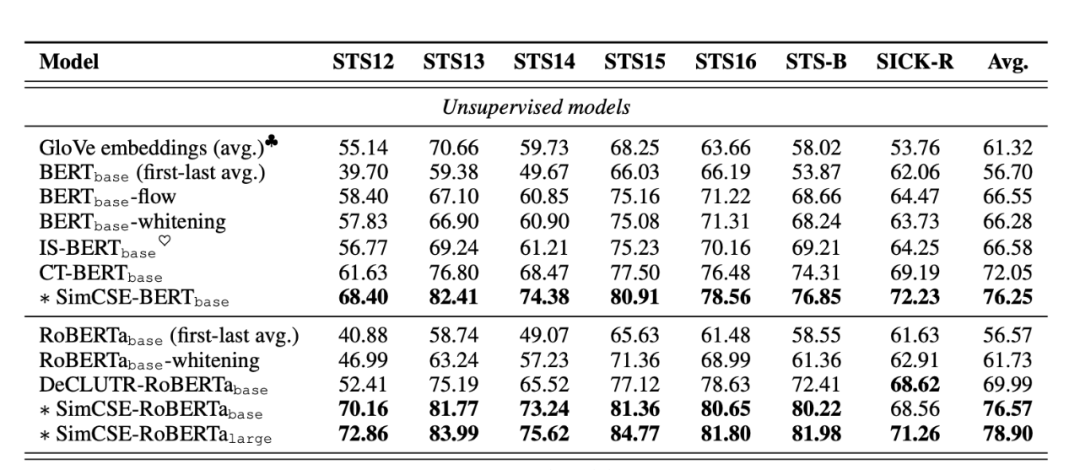
最终模型的效果在各个数据集上基本处于碾压的存在。
03 应用
由于业务需求是当有新增提问时,获取历史相似提问簇,因此整个过程分为三个阶段:
step1:训练 ernie-SimCSE,获取句子 encoder,本阶段主要获取编码器用来获取句子的语义向量;
step2:构建语义索引库,本阶段主要是得到语义索引,用于检索相似向量;
step3:反作弊策略,将相似向量用于反作弊策略,用于识别群发推广。
3.1 ernie-SimCSE
目前对于预训练模型的应用从『预训练』+『子任务 finetune』的模式过渡为『预训练』+『领域预训练』+『子任务 finetune』,我们选取的 encoder 模型为当前中文领域最好的 ernie 模型,在 ernie 模型基础上增加 SimCSE,训练过程为:
-
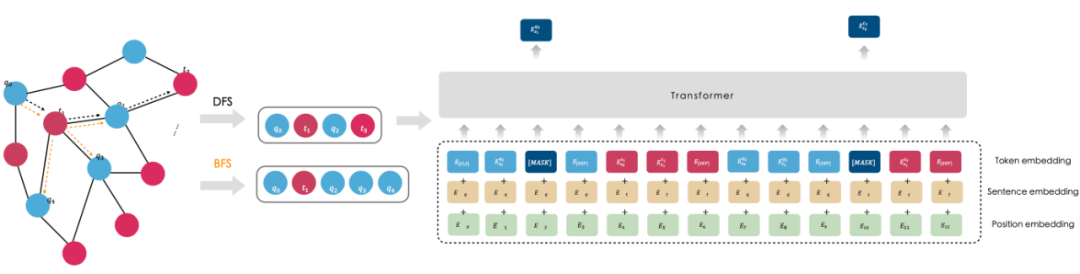
在预训练基础上添加搜索 Q-T 匹配任务的训练,得到 Ernie-Search,通过大规模点击日志构建 Q-T 图,我们在这张图上通过随机游走采样出 q-t-q-t 序列 S = [q0 , t1 , …, qN-1 , tN] ,然后在这个序列上执行针对序列 S 的遮盖词预测完成预训练任务;
-
在 Ernie-Search 的基础上利用,单独利用知道提问数据进行进一步 post-train,得到 Ernie-Search-ZD;
-
在 Ernie-Search-ZD,添加 SimCSE 对比学习,获取最终的模型 Ernie-SearchCSE。
3.2 问题及优化
论文中的损失没有计算增强后的样本之间的损失,原因可能是由于计算成本的考虑,我们对损失进行了改进,对于增强后的数据也纳入负例的损失计算:
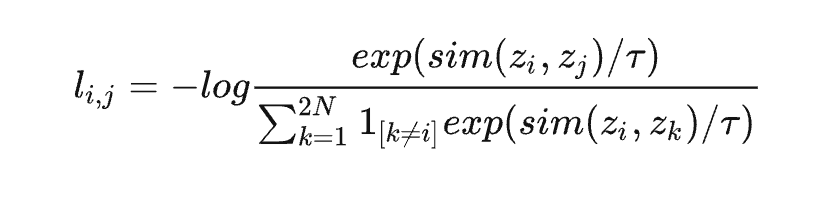
3.3 模型效果
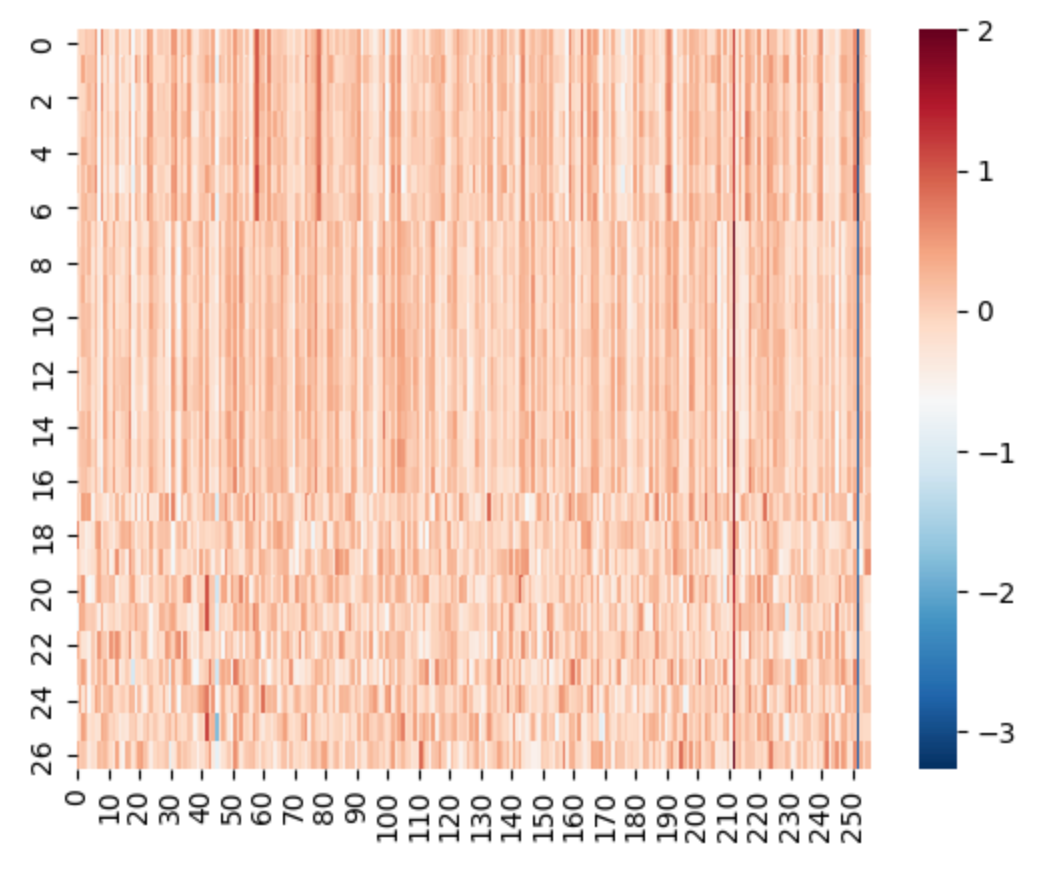
为了观测模型的最终效果,我们选取了之前的 17 个目标 case,以及随机选取 10 个其它句子:
由下方热力图可以看出,符合当初模型预期,前 10 个的相似性远大于后 10 个的相似性。对于提问『北京肋软骨隆鼻刘彦军做的怎么样?』检索索引库中语义最相似 TOP 10 获取疑似变形推广。

![[附源码]SSM计算机毕业设计基于社区生鲜配送系统JAVA](https://img-blog.csdnimg.cn/37fc810373d64b4e84bd8f10018f2977.png)



![[附源码]计算机毕业设计JAVA篮球装备商城系统](https://img-blog.csdnimg.cn/eca4c536b1104aeca9ae2d8939dc3d54.png)