最近和大家说了不少“大问题”(中庸之道啥的),今天想和大家聊一个“小问题”——如何写日志。
在很多人的认知里面,日志的确是可有可无的小问题,因为有没有日志都不影响业务功能的运行。正因为如此,日志问题也经常被团队忽视。而事实是,日志的问题一点都不小,而是值得我们好好重视的大问题。
因为日志是我们窥见软件这个“黑盒子”内部运行情况的不二法门,特别是线上问题的监控和定位,只能依靠日志。其价值不亚于数据库中的业务数据,只不过日志是“过程数据”,而数据库是“结果数据”。
可以说,日志是影响研发效能的关键因素之一,没有好的日志规范、日志框架、日志系统、日志实践,就不可能有高的研发效率。本文我会介绍一些这些年,我积累的一些我认为比较好的日志实践,这些内容包括:
- 在开发阶段应该打印哪些日志
- 不同的环境如何配置不同的日志
- 日志框架标准化的重要性
- 如何避免到处使用ERROR
- 为什么集中式日志更好
1. 开发态的日志
在开发阶段,我们要尽可能的多打日志,因为日志可以给我们提供更多的上下文信息,减少debug的次数,debug是非常不友好且耗时间的开发方式。当你需要频繁debug代码的时候,就应该回头审视一下我是不是日志打少了。我平时在开发阶段写代码的时候,有几个地方的日志我是一定要完整打印出来的:
- 一个是API的完整入参和出参
- 另一个是数据库的SQL和参数
比如,我们有一个计费的API是charge(ChargeRequest request) ,如下所示,那么在处理请求的一开始,我会把request的完整信息打印出来。
public Response charge(ChargeRequest request) {
log.debug("begin charge : " + request);
Session session = sessionGateway.get(request.getSessionId());
int durationToCharge = request.getDuration() - session.getChargedDuration();
List<ChargeRecord> chargeRecordList = new ArrayList<>();
chargeCalling(session, durationToCharge, chargeRecordList);
chargeCalled(session, durationToCharge, chargeRecordList);
chargeGateway.saveAll(chargeRecordList);
session.setChargedDuration(request.getDuration());
return Response.buildSuccess();
}
这样,我在本地开发的时候,每次运行程序,我都能获得比较完整的请求上下文信息,当然过程中的重要节点也需要被记录,比如在真正执行charge的时候,我会把相关信息也打印出来。
DEBUG [main] c.h.c.application.ChargeServiceImpl: begin charge : ChargeRequest(sessionId=00001, duration=10)
DEBUG [main] c.h.charging.domain.account.Account: do charge: [Charge{phoneNo=15921582155, callType=CALLED, chargeDuration=10, chargePlanType=BASIC, cost=Money(amount=40)}]
Charge系统的一项重要任务是要把ChargeRecord(计费记录)保持到数据库中,通常,我们会通过观察数据库的数据是否正确来判断程序是否正确。因此,如下所示,我们应该把和数据库相关的操作详细打印出来,包括SQL和参数绑定。
DEBUG [main] o.h.e.jdbc.spi.SqlStatementLogger: insert into charge_record (call_type, charge_duration, charge_plan_type, cost, create_time, phone_no, session_id, update_time) values (?, ?, ?, ?, ?, ?, ?, ?)
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [1] as [VARCHAR] - [CALLING]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [2] as [INTEGER] - [10]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [3] as [VARCHAR] - [BASIC]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [4] as [BIGINT] - [50]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [5] as [TIMESTAMP] - [Mon Nov 14 18:07:13 CST 2022]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [6] as [BIGINT] - [13681874533]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [7] as [VARCHAR] - [00001]
TRACE [main] o.h.type.descriptor.sql.BasicBinder: binding parameter [8] as [TIMESTAMP] - [Mon Nov 14 18:07:13 CST 2022]
那么要如何才能输出这些数据库相关的日志呢?基本上每一个ORM框架都提供了这样的日志能力,就拿基于Hibernate实现的JPA框架来说,我们可以通过配置下面的logger来做输出。其它框架和语言请自行探索。
<!--SQL日志-->
<logger name="org.hibernate.SQL" level="DEBUG"/>
<!--参数绑定日志-->
<logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE"/>
此外,在开发阶段为了方便,我建议直接把日志输出到控制台(console),这会使我们在IDE里写代码、调试的时候更方便高效,以logback为例,我通常会写一个如下的logback-test.xml配置文件,即应用基础root会采用INFO级别高亮layout的方式输出到console,然后对于当前应用和其他关键信息(比如数据库相关)的采用DEBUG或者更低日志级别输出到console。
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
%highlight(%-5level) [%blue(%t)] %yellow(%C{35}): %msg%n%throwable
</Pattern>
</layout>
</appender>
<!--rootLogger是默认的logger-->
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
<!--应用日志-->
<!--这个logger没有指定appender,它会继承root节点中定义的那些appender-->
<logger name="com.huawei.charging" level="DEBUG"/>
<!--SQL日志-->
<logger name="org.hibernate.SQL" level="DEBUG"/>
<!--参数绑定日志-->
<logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE"/>
</configuration>
2. 不同环境的日志
不同的环境对日志的输出、存储的诉求是不一样的,上面给出的是开发阶段的日志输出,我的经验是尽量把详细信息输出到console就好。上线之后,我们一般就不再需要像SQL参数绑定那么详细的日志了,而且我们的日志也不是输出到console,而是输出到文件,或者通过网络输出到集中式日志系统。
由此,我们可以看到不同的环境需要有不同的日志配置策略。以logback为例,为了实现不同环境的日志配置区隔,如下图所示,我们可以分别在src/main/resources和src/test/resources下面放置不同的配置文件。
注意,想要在开发环境下使用不同的logback配置,需要将其命名为logback-test.xml,这样框架会优先加载logback-test.xml,而不是logback.xml。框架的这个自动加载机制,是通过logback的ContextInitializer的这段代码实现的:
public class ContextInitializer {
final public static String GROOVY_AUTOCONFIG_FILE = "logback.groovy";
final public static String AUTOCONFIG_FILE = "logback.xml";
final public static String TEST_AUTOCONFIG_FILE = "logback-test.xml";
public URL findURLOfDefaultConfigurationFile(boolean updateStatus) {
ClassLoader myClassLoader = Loader.getClassLoaderOfObject(this);
URL url = findConfigFileURLFromSystemProperties(myClassLoader, updateStatus);
if (url != null) {
return url;
}
url = getResource(TEST_AUTOCONFIG_FILE, myClassLoader, updateStatus);
if (url != null) {
return url;
}
url = getResource(GROOVY_AUTOCONFIG_FILE, myClassLoader, updateStatus);
if (url != null) {
return url;
}
return getResource(AUTOCONFIG_FILE, myClassLoader, updateStatus);
}
//...
}
日志框架的原理不复杂,核心概念就是Appender,Logger和Layout,鼓励大家有空多去看看源码。追源码有很多好处,一方面可以吸收到他人比较好的设计和写代码方式,另一方面是当框架部分出现问题的时候,我们可以深入到框架内部调试问题,协助我们解决问题。
3. 标准化日志框架
我之所以会深入研究Java的日志框架,是源于在阿里工作的时候一段“痛苦”经历,有一次,我在本地调试程序,搞了一天,无论怎么折腾,日志就是打印不出来。我只好深入到框架内部开始debug其源码,深入其内部之后,我才发现,这个看似简单的日志比我预想的要复杂,就那我当时处理的系统来说,其内部有一个像迷宫一样的日志框架嵌套结构(下图)。
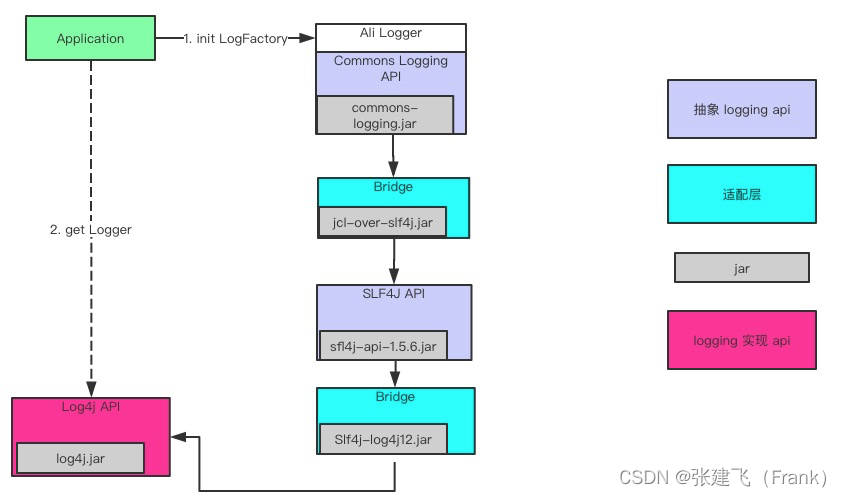
出现这个问题的根源在于日志系统标准的缺乏。日志系统在演进,作为应用,又不想改变使用日志的接口,所以就必须要使用各种Bridge(桥接)来在保证日志接口不变的情况下,替换下面的日志框架实现。比如我一开始使用的是commons-logging,现在要替换为log4j,就需要一个jcl-over-log4j的Bridge。这样虽然我代码里面使用的还是commons-logging,但底层实现已经替换为log4j了。然后再升级logback…
在技术领域,这种缺乏标准带来的麻烦经常会出现,例如早期的浏览器因为缺乏标准,我们必须要多写很多JS代码去适配不同的浏览器。所以标准很重要,好在,在Java社区,渐渐的是形成了日志标准SLF4J(Simple Logging Facade for Java),因为SLF4J是一个存抽象接口,使用SLF4J可以做到应用使用日志和具体日志框架解耦的目的,可以说SLF4J是解决上面复杂日志框架迷宫的一把利器,也是通过依赖倒置解耦的典型案例。如果你不是Java应用,最好也要有这样的“中间层”去做解耦。
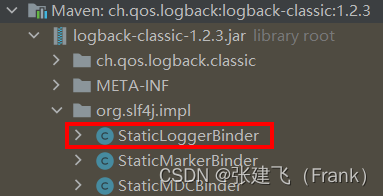
在SLF4J的众多实现中,logback是对SLF4J支持最好(原生支持),性能最好,也最简洁的框架实现。所以,我前面说推荐使用SLF4J,实际上就是推荐SLF4J+logback的组合。SLF4J找到具体实现的过程,挺有意思,它不同于我们传统的接口+实现的方式,而是通过runtime classpath绑定的方式,来实现了一个类似于SPI的机制。
它具体是这么做的。首先,SLF4J定义LoggerFactory,Logger,具体的Logger实现是通过LoggerFactory中的bind( )方法中的StaticLoggerBinder.getSingleton( )这行代码来实现的。而这个StaticLoggerBinder实际上在SLF4J组件里是没有的,是需要具体的日志框架(logback,log4j等)提供的。等一下,如果StaticLoggerBinder没有的话,SLF4J是怎么编译通过打包成组件的呢?这是因为SLF4J在源码中原本是有一个dummy StaticLoggerBinder实现,只是在打包过程中通过如下的antrun方式将其移除了:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-antrun-plugin</artifactId>
<executions>
<execution>
<phase>process-classes</phase>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
<configuration>
<tasks>
<echo>Removing slf4j-api's dummy StaticLoggerBinder and StaticMarkerBinder</echo>
<delete dir="target/classes/org/slf4j/impl"/>
</tasks>
</configuration>
</plugin>
然后在logback中,通过提供了这个StaticLoggerBinder,这样在runtime的时候,只要classpath中有logback jar包,logback中的StaticLoggerBinder就会接续SLF4J中的那段代码,完成日志初始化和绑定的工作。怎么样?是不是还挺有意思的。反正我在看到它这种实现方式之前,没想过还能这么玩。
4. 运行时的日志级别调整
前面说的详细日志一般是在开发和测试的时候用,线上环境,一般我们不需要那么详细的日志。但凡事都有例外,如果线上出现了啥疑难杂症,这些详细日志将会变得非常宝贵。这时,我们就需要调整日志的输出级别,把详细日志打开,帮助我们定位问题。比如把日志级别从WARN调整为DEBUG,打印出更多的信息帮助我们定位问题,而这就需要我们有一种在Runtime调整日志级别的能力。
之所以,会把这个问题单独拿出来强调,是因为最近看到不少项目在代码里到处使用ERROR进行普通日志输出,问起原因,说是为了定位线上问题。可是乱用ERROR不仅不优雅,而且还会扰乱报警系统。我想滥用ERROR的同学要么不知道日志级别能动态调整,要么不知道如何去动态调整。实际上,这个调整并不难。
首先,要想实现动态日志级别调整,你使用的日志框架要能支持动态调整的能力(如果没有,赶紧换一个),我们还是以logback为例,logback有两种方式可以做到runtime日志级别修改。
- 代码修改
代码修改的话,你需要写一段如下的代码,接收两个参数,一个是要修改的logger名称,另一个是要修改的级别。
public Response changeLogLevel(String logName, String logLevel) {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
Logger targetLogger = loggerContext.getLogger(logName);
Level targetLevel = Level.valueOf(logLevel);
targetLogger.setLevel(targetLevel);
verifyChange(targetLogger, targetLevel);
return Response.buildSuccess();
}
剩下的事情就是如何触发这段代码的问题了,触发的方式有很多,可以用REST,也可以用分布式配置系统的Listener,亦或是Spring Boot Actuator,Spring Boot Admin都可以, 选择一种适合自己的就好。
- 配置扫描
配置扫描就是在logback的配置文件中加上scan属性,如下所示,这个是在告诉logback没15秒钟reload一下配置文件,如果配置文件有变化会自动被pickup。这个方法不实用,了解就行,一般也不会这样去用。
<configuration scan="true" scanPeriod="15 seconds">
//......
</configuration>
总而言之,我们应该构建一个系统运行时动态调整日志级别的能力,这样在需要的时候,我们可以方便的获取到更多的日志信息,而不是靠ERROR走江湖。
5. 集中式日志管理
云原生里面有一个Immutable Infrastructure的概念,大意是说,最好不要动生产环境,因为修改生产环境会影响构建的一致性和生产系统的稳定性。我之前就碰到一个同学因为在生产机器上vi 日志文件把系统搞崩的案例。但是传统的日志文件都是在服务器本地,想要做到“不触碰”除非把日志信息转移走。实际上对于传统的把日志打印到本地文件,对于当前流行的微服务分布式架构来说,更好的做法是做集中式日志管理,这样我们就不需要去触碰生产环境,直接访问日志系统即可。
我最早接触集中式日志是在eBay工作的时候,eBay可以说是互联网分布式系统的先驱,在分布式系统的实践上积累了很多经验。当年的taobao就是请的sun的工程师借鉴eBay的分布式架构搭建起来的。在eBay工作期间,给我留下印象最深的就是CAL(Centralized Application Logging)系统,使用CAL,技术人员可以方便的通过CAL查看应用日志、以及分布式系统之间的调用链关系。CAL也是开发和测试使用最频繁的系统,测试发现一个bug,经常就会扔一个CAL的URL链接给开发,因为有些问题看日志基本就知道原因了。很多从eBay出来的工程师都对CAL赞不绝口,其中有一位把这个思想带到了大众点评,做了CAT(Centralized Application Tracking),在业界的反响也很不错。
十几年前的CAL在当时的互联网绝对算的上是典型的大数据“高科技”产品,从零搭建一套这样的系统是非常困难的。不过好在,时至今日,已经有很多商业的、开源的集中式日志系统可供选择。比如阿里的SLS,开源的Logstash等等。