Flink是什么?
- Flink是什么?
- 为什么选择Flink?
- 什么场景需要处理流数据?
- 处理流的发展演变
Flink是什么?
Apache Flink 是一个在无界和有界数据流上进行状态计算的框架和分布式处理引擎。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
为什么选择Flink?
低延迟
高吞吐
结果的准确性和良好的容错性
什么场景需要处理流数据?
Flink的经典使用场景是ETL,即Extract抽取、Transform转换、Load加载,可以从一个或多个数据源读取数据,经过处理转换后,存储到另一个地方。
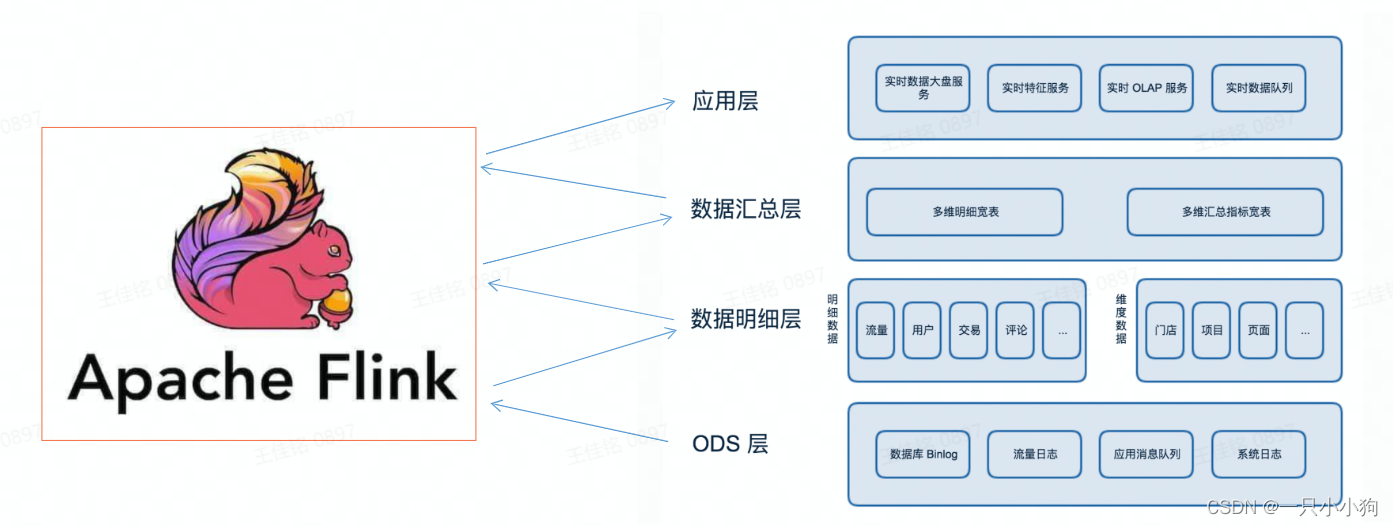
处理流的发展演变
- 传统数据处理:事务处理,需要用户进行ClickEvents发送到后台进行关系型数据库状态的CRUD or 逻辑处理,最后进行响应。
- 有状态的流式处理:来一个处理一个的流式处理,瓶颈在于需要不断的查询关系型数据库,所以这时候直接存储到本地内存的状态,由于出现了程序奔溃内存的不稳定,增加数据库的持久化,以及故障的恢复机制,从Checkpoint记录的恢复。
- lamdba架构:解决集群多程序中流处理时间顺序问题,使用两套系统,同事保证低延迟和结果精确。流处理和批处理两套
缺点:但是这个时候如果使用有变化会在不同的两套系统中进行运算,而且可能使用不同架构有不同API。
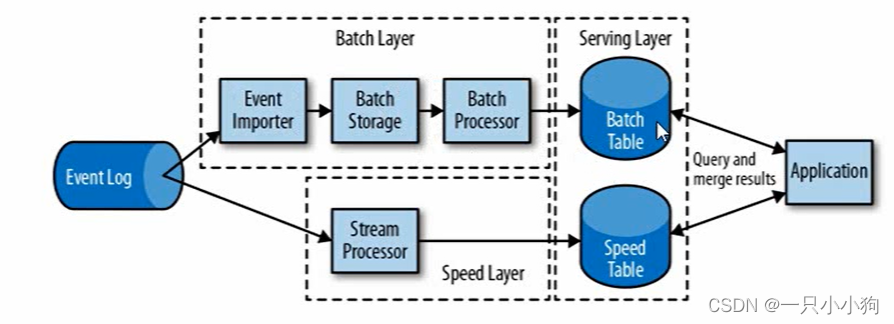
- Flink:低延迟、高吞吐、结果的准确性和良好的容错性、时间正确
如有错误欢迎指正