根本解决的问题:在信息过载的情况下,用户如何高效获取感兴趣的信息。
1 逻辑架构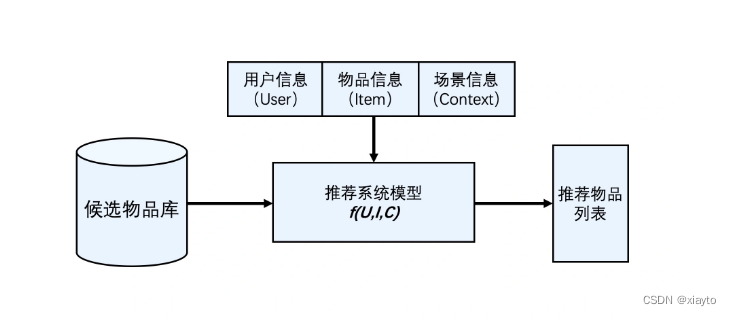
推荐系统要处理的问题就可以被形式化地定义为:对于某个用户U(User),在特定场景C(Context)下,针对海量的“物品”信息构建一个函数 ,预测用户对特定候选物品I(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题
2 技术架构
在实际的推荐系统中,工程师需要着重解决的问题有两类。
- 一类问题与数据和信息相关,即“用户信息”“物品信息”“场景信息”:逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架
- 另一类问题与推荐系统算法和模型相关:进一步细化为推荐系统中,集训练(Training)、评估(Evaluation)、部署(Deployment)、线上推断(Online Inference)为一体的模型框架。

2.1 数据部分
推荐系统的“数据部分”主要负责的是“用户”“物品”“场景”信息的收集与处理。根据处理数据量和处理实时性的不同,我们会用到三种不同的数据处理方式,按照实时性的强弱排序的话,它们依次是
- 客户端与服务器端实时数据处理
- 流处理平台准实时数据处理
- 大数据平台离线数据处理
数据处理后,有三个用途:
- 生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
2.2 模型部分
2.2.1 发展历史
从矩阵分解算法 -> 深度模型发展
传统模型:
深度模型的优势:
1、复杂的网络可以拟合更复杂的函数
2、注意力机制可以模拟用户兴趣变化的过程

《Deep Interest Evolution Network for Click-Through Rate Prediction》,阿里巴巴的深度学习模型——深度兴趣进化网络(如图 3),它利用了三层序列模型的结构,模拟了用户在购买商品时兴趣进化的过程,如此强大的数据拟合能力和对用户行为的理解能力,是传统机器学习模型不具备的。
2.2.2 模型各部分
一般有召回层、排序层、补充策略与算法层
- 召回层:一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品
- 排序层:利用排序模型对初筛的候选集进行精排序
- 补充策略与算法层:在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表
深度学习应用:
- 深度学习中 Embedding 技术在召回层的应用。作为深度学习中非常核心的 Embedding 技术,将它应用在推荐系统的召回层中,做相关物品的快速召回,已经是业界非常主流的解决方案了。不同结构的深度学习模型在排序层的应用。
- 排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域。深度学习模型的灵活性高,表达能力强的特点,这让它非常适合于大数据量下的精确排序。深度学习排序模型毫无疑问是业界和学界都在不断加大投入,快速迭代的部分。增强学习在模型更新、工程模型一体化方向上的应用。
- 增强学习可以说是与深度学习密切相关的另一机器学习领域,它在推荐系统中的应用,让推荐系统可以在实时性层面更上一层楼。






![[附源码]java毕业设计小区供暖收费管理系统](https://img-blog.csdnimg.cn/0c45ec10a1184506856166b1a25cfe91.png)