项目背景
LatentSync1.5 是由 ByteDance 开发的一款先进的 AI 模型,专门针对视频唇同步(lip synchronization)任务设计,旨在实现音频与视频唇部动作的高质量、自然匹配。随着 AI 技术的快速发展,视频生成和编辑的需求在多个领域(如影视制作、虚拟现实、游戏开发)日益增长,高精度的唇同步技术成为关键需求之一。传统的唇同步方法通常依赖复杂的中间表示,例如 3D 面部模型或关键点检测,这些方法不仅计算成本高昂,而且在复杂场景下的表现往往不够理想。
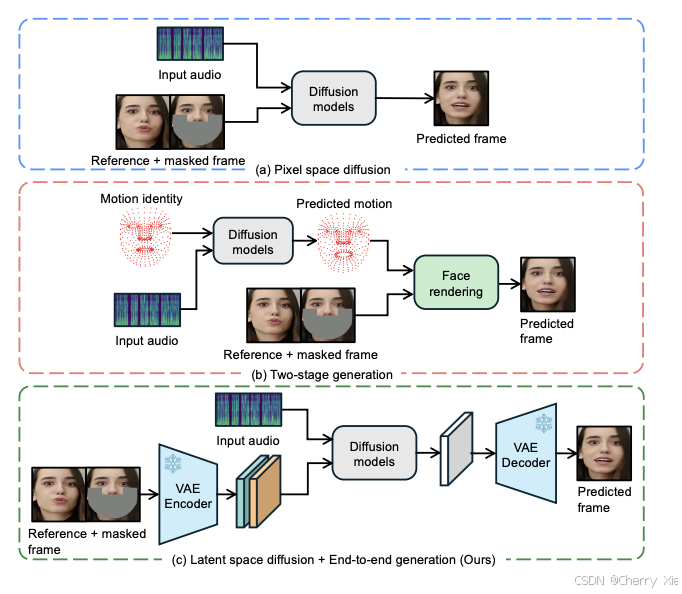
LatentSync1.5 的研发初衷正是为了改进这些不足。它通过创新的潜在扩散模型(Latent Diffusion Model, LDM)技术,实现了从音频到唇同步视频的端到端生成,显著提升了生成效率和质量。这一模型不仅适用于专业内容创作,还推动了虚拟化身和游戏角色动画等领域的技术进步。
技术架构
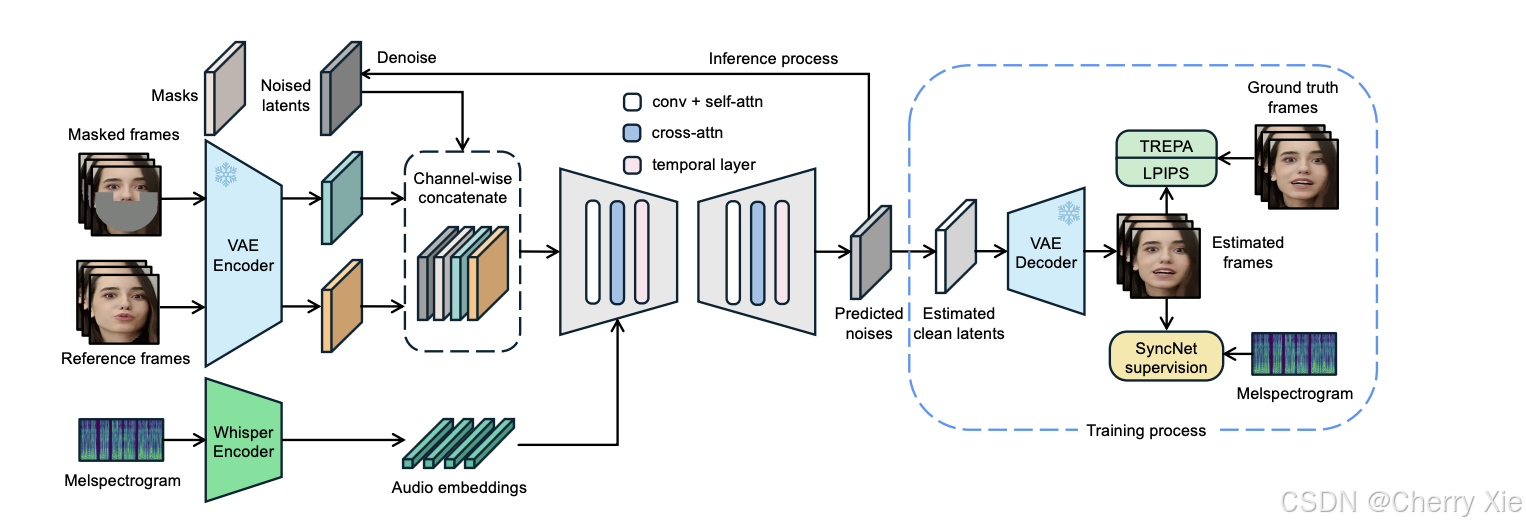
LatentSync1.5 的技术架构以 Stable Diffusion 模型为基础,并结合多项创新优化,形成了高效且强大的唇同步生成系统。
音频处理
-
Whisper 模型
LatentSync1.5 利用 Whisper(一种先进的语音识别模型)将音频的梅尔频谱图(melspectrogram)转换为音频嵌入(audio embeddings)。这些嵌入包含了音频的语义和时序信息,为后续的唇同步提供了精确的特征输入。
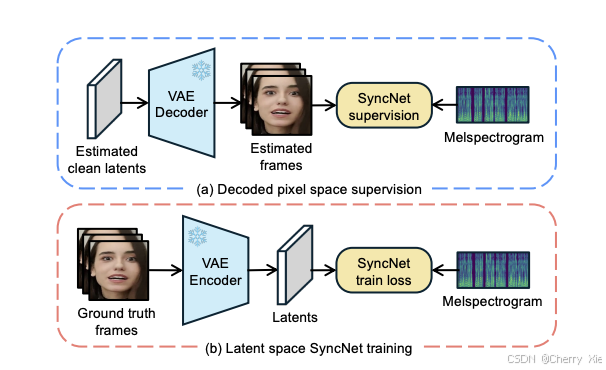
-
交叉注意力机制
通过交叉注意力层(cross-attention layers),音频嵌入与视频帧的潜在表示实现对齐。这种机制确保了生成的每一帧视频与音频内容保持高度同步。
潜在扩散模型(LDM)
-
U-Net 架构
LatentSync1.5 的核心扩散模型采用 U-Net 架构,这是一种广泛应用于图像生成和分割的网络结构,具备出色的特征提取和图像重建能力。 -
潜在空间操作
与传统在像素级进行处理的扩散模型不同,LatentSync1.5 在低维潜在空间中进行建模和生成。这种方法大幅降低了计算复杂度,同时保留了高分辨率图像的视觉质量。
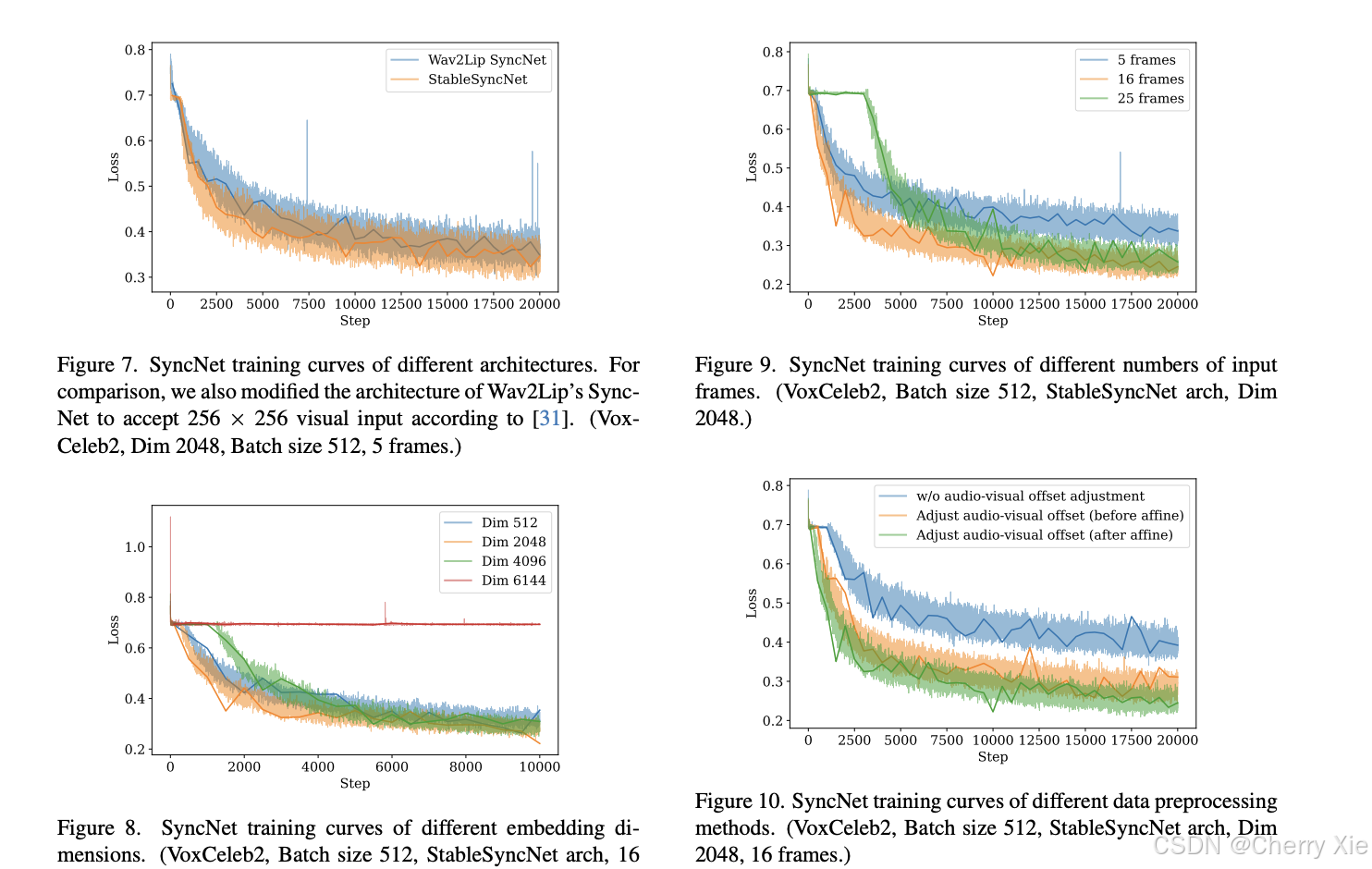
时序表示对齐(TREPA)
-
时序层(Temporal Layer)
为解决扩散过程中帧间不连贯的问题,LatentSync1.5 引入了时序层,专门处理视频帧之间的时序关系,确保生成的视频流畅自然。 -
自监督视频模型
利用大规模自监督视频模型(如 VideoMAE)提取的时序表示,LatentSync1.5 将生成的视频帧与真实帧对齐。这种技术有效减少了闪烁伪影(flickering artifacts),显著提升了视频的时序一致性。
训练优化
-
梯度检查点(Gradient Checkpointing)
在 U-Net、VAE、SyncNet 和 VideoMAE 等模块中应用梯度检查点技术,降低了训练过程中的内存占用。 -
FlashAttention-2
采用 PyTorch 原生的 FlashAttention-2 替代传统的 xFormers,进一步提升了内存效率和计算速度。 -
多阶段训练
LatentSync1.5 支持多阶段训练模式,用户可根据硬件条件选择 Stage 1 或 Stage 2。优化后的 Stage 2 将显存需求降至 20GB,使模型能在消费级 GPU(如 NVIDIA RTX 3090)上运行。
技术创新亮点
端到端生成
LatentSync1.5 无需依赖复杂的中间表示,直接从音频生成唇同步视频,简化了生成流程。
时序一致性
通过 TREPA 技术和时序层优化,生成的视频帧间过渡更加平滑,减少了跳跃和闪烁。
中文视频优化
针对中文唇同步效果不佳的问题,模型在训练中加入了中文数据,提升了中文音频与唇部动作的匹配度。
硬件友好性
通过训练优化和资源管理,降低了硬件门槛,使更多用户能够使用该模型。
性能对比
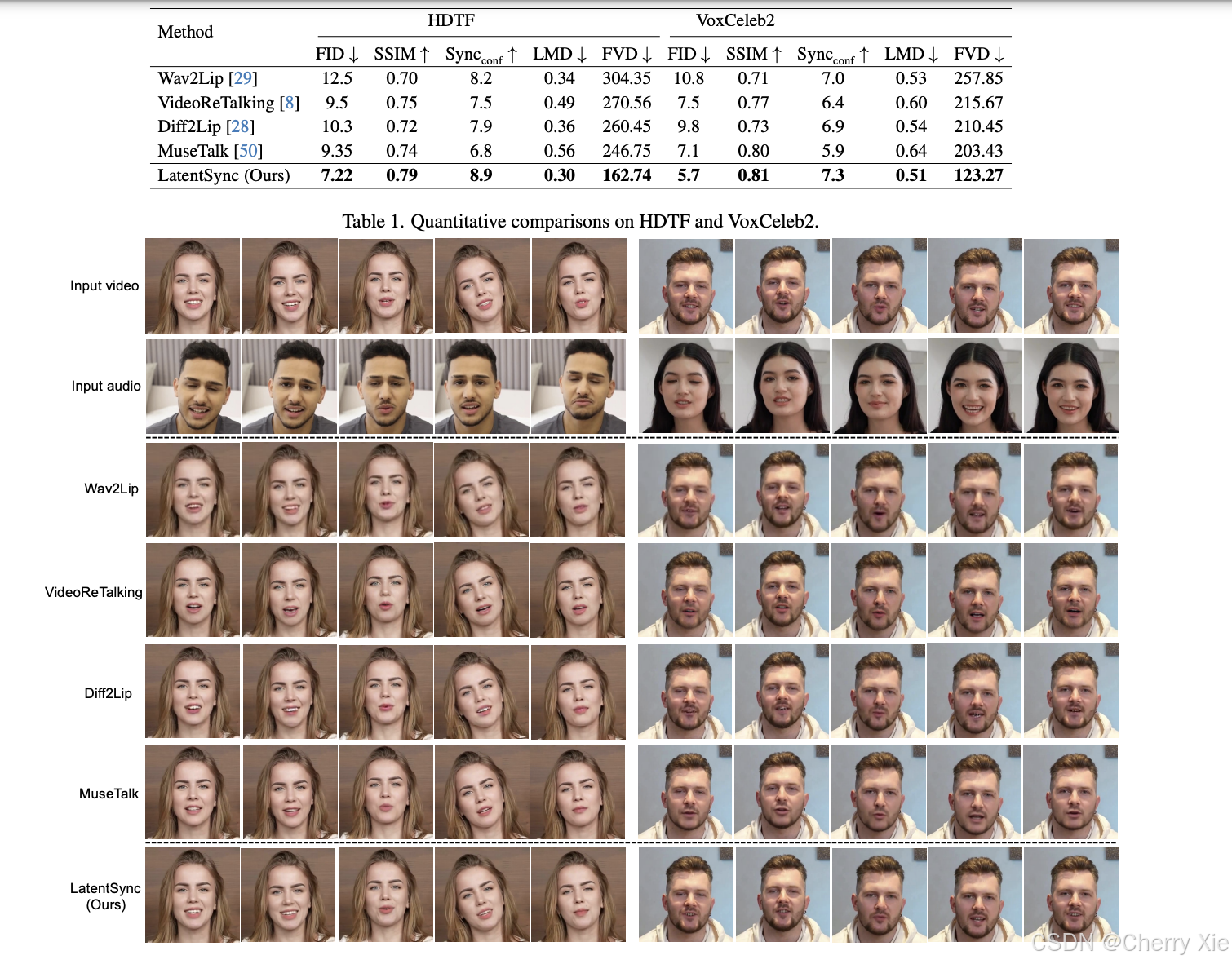
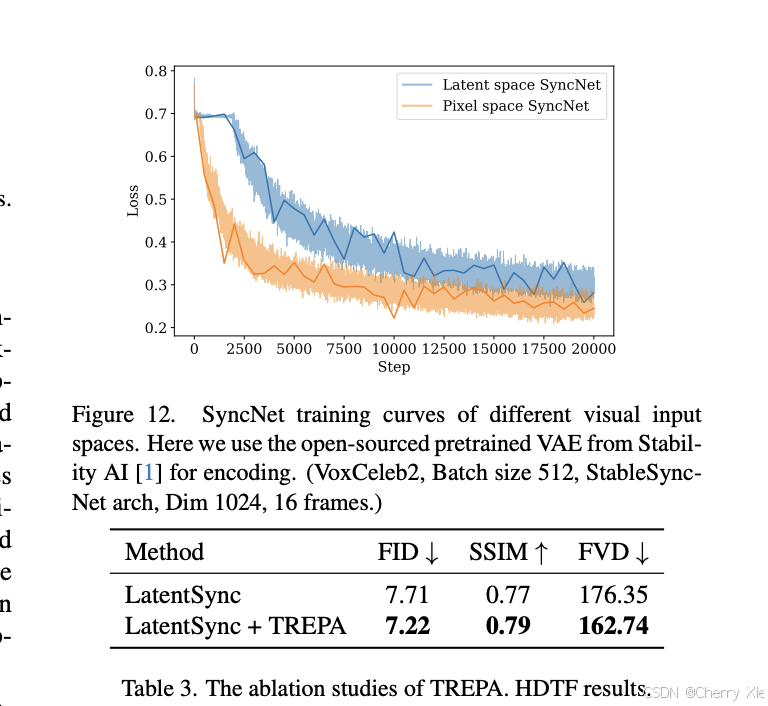
看看效果
相关文献
github地址:https://github.com/bytedance/LatentSync?tab=readme-ov-file
技术报告:https://arxiv.org/pdf/2412.09262
模型下载:https://huggingface.co/ByteDance/LatentSync-1.5