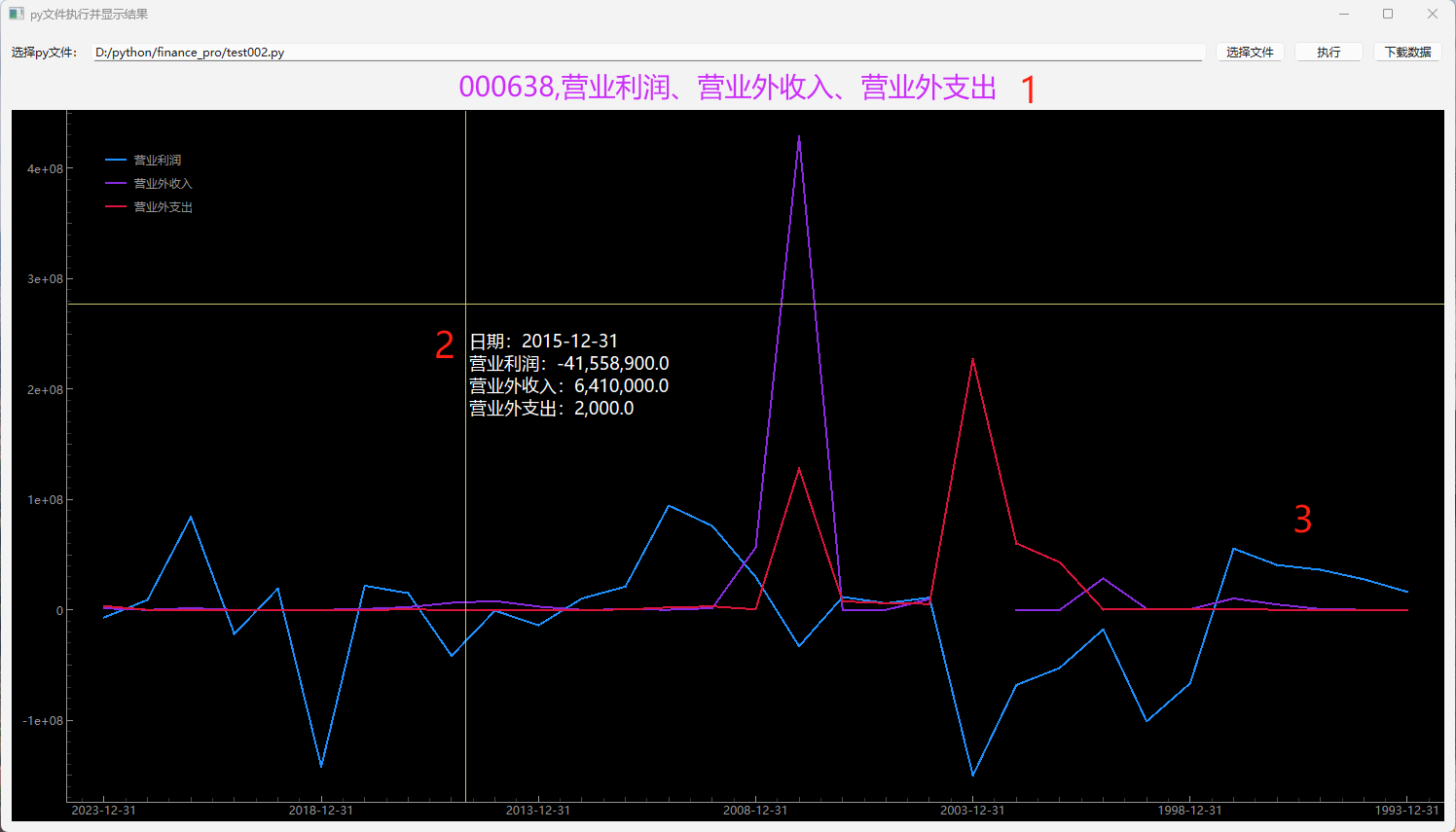
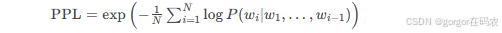RAG:检索增强,结合了检索和生成两种技术;用于提升生成模型的效果。
1.信息检索(R) :系统从一个大型文档库中检索出与查询最相关的文档片段。这一步的目标是找到那些可能包含答案或相关信息的文档。
2.生成增强(A) :将检索到的文档片段与原始查询一起输入到大模型(如chatGPT)中,注意使用合适的提示词,比如原始的问题是XXX,检索到的信息是YYY,给大模型的输入应该类似于:请基于YYY回答XXXX。
3.输出生成(G) :大模型基于输入的查询和检索到的文档片段生成最终的文本答案,并返回给用户。
通过垂直场景,通过实时更新知识库,无需重新训练模型;
实现过程中:
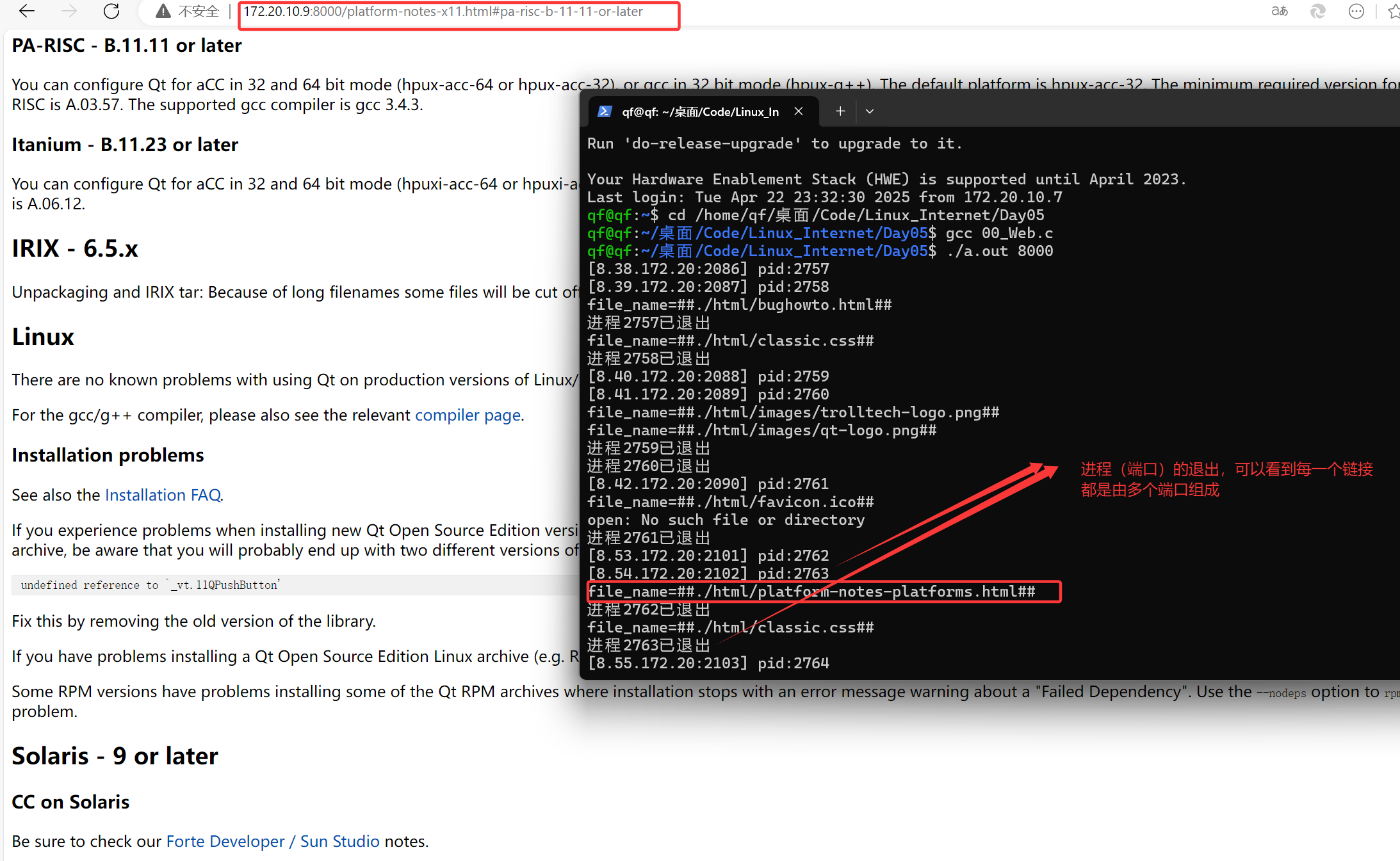
可按页进行分割,使用嵌入模型将文本转为向量表示;存储到数据库中(redis、es);
用户提出问题,生成问题对应的向量;调用api的向量检索,找到相关文档;
在此类问题中,需要先处理的是进行文档PDF的存入向量中;
保存到本地磁盘中demo
String filename = resource.getFilename();
File target = new File(Objects.requireNonNull(filename));
if (!target.exists()) {
try {
Files.copy(resource.getInputStream(), target.toPath());
} catch (IOException e) {
log.error("Failed to save PDF resource.", e);
return false;
}
}
// 2.保存映射关系
chatFiles.put(chatId, filename);
后续直接调用spring ai的接口
第一步:配置RAG Advisor
@Bean
public ChatClient pdfChatClient(OpenAiChatModel model, ChatMemory chatMemory, VectorStore vectorStore) {
return ChatClient
.builder(model)
.defaultSystem("请根据上下文回答问题,遇到上下文没有的问题,不要随意编造。")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
new MessageChatMemoryAdvisor(chatMemory),
new QuestionAnswerAdvisor(
vectorStore,
SearchRequest.builder()
.similarityThreshold(0.6)
.topK(2)
.build()
)
)
.build();
}
第二步:对话和检索
pdfChatClient.prompt()
.user(prompt)
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId))
.advisors(a -> a.param(FILTER_EXPRESSION, "file_name == '" + file.getFilename() + "'"))
.stream()
.content();
即可实现通过文档,输入垂直问题获得向量对应的答案。