在大模型推理的世界里,速度与精度往往难以兼得。但今天要介绍的这篇论文带来了名为SpecReason的创新系统,它打破常规,能让大模型推理既快速又准确,大幅提升性能。想知道它是如何做到的吗?快来一探究竟!
论文标题
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
来源
arXiv:2504.07891v1 [cs.LG] + https://arxiv.org/abs/2504.07891
文章核心
研究背景
大型推理模型(LRMs)在复杂任务上取得了很高的准确率,但推理延迟高的问题限制了其在交互式应用中的使用。
研究问题
- LRMs生成的长推理序列以及解码的自回归特性导致推理延迟高,严重影响用户体验。
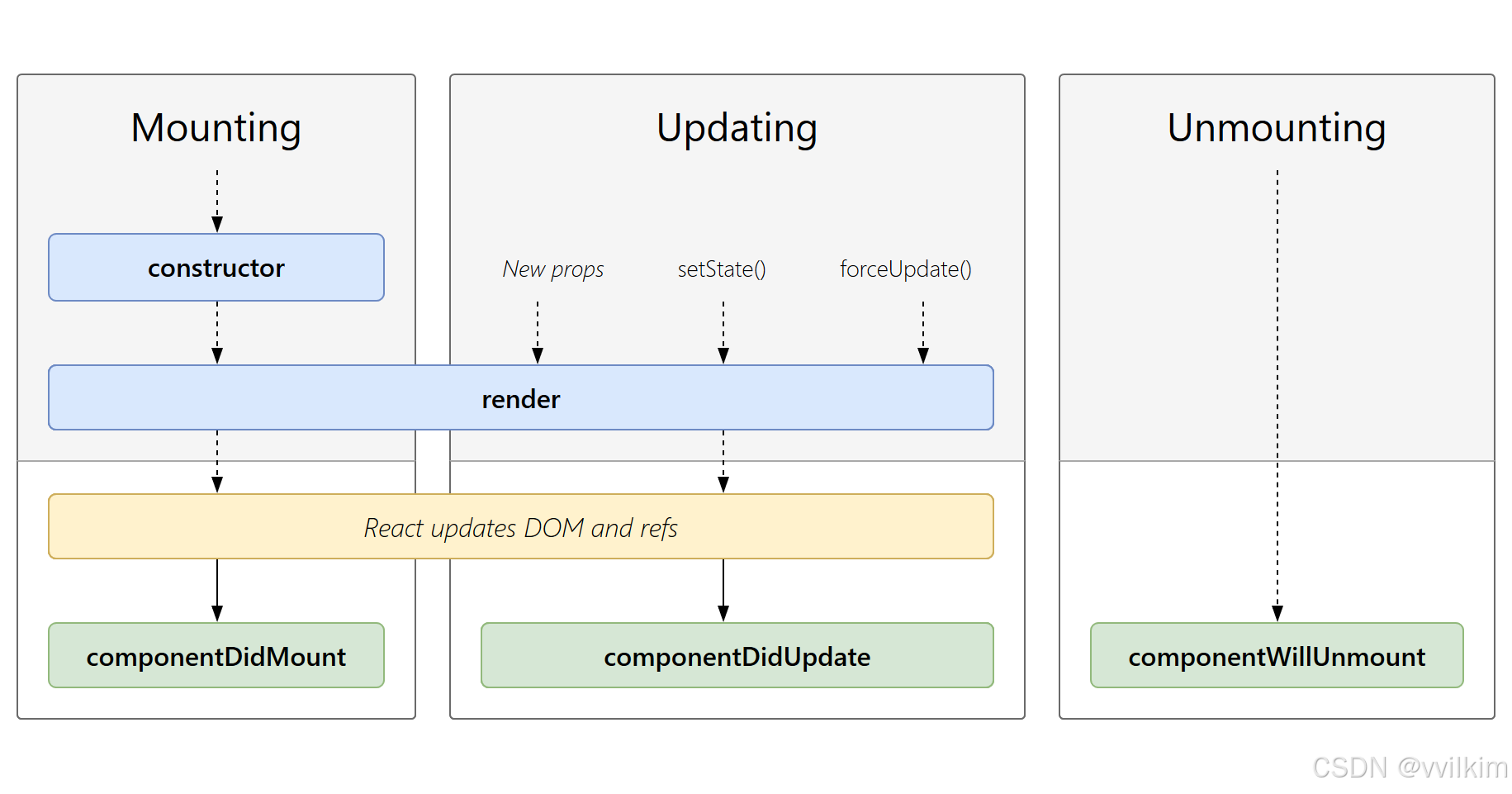
- 传统的推理加速方法,如投机解码(Speculative decoding),要求小模型和基础模型在token级别等价,无法充分利用推理过程对近似的容忍性。
主要贡献
- 提出SpecReason系统:利用轻量级模型推测执行简单的中间推理步骤,基础模型仅用于评估和纠正推测结果,在保持或提高准确率的同时,显著降低推理延迟,相比传统LRM推理实现1.5 - 2.5倍的加速。
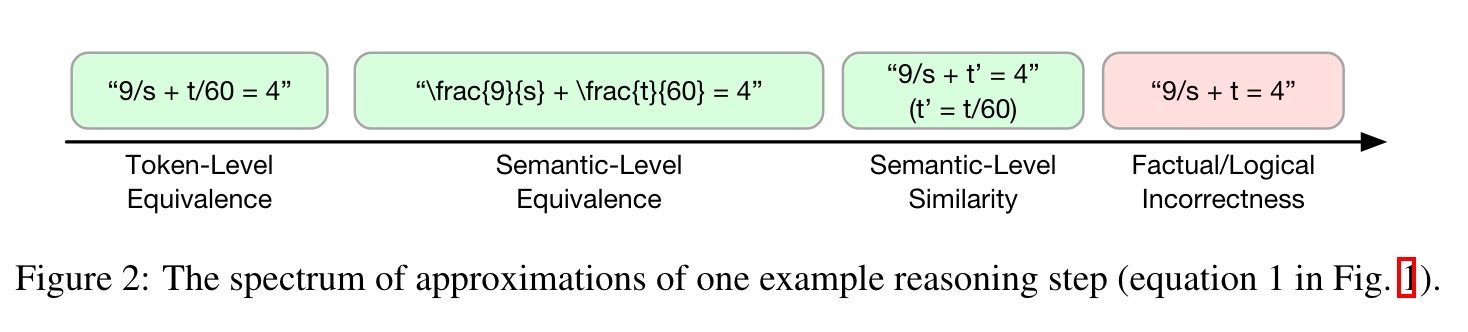
- 突破传统要求:与投机解码不同,SpecReason聚焦于思维token的语义相似性,放宽了严格的token级别等价要求,为降低LRM推理延迟开辟了新途径。
- 互补优化策略:发现SpecReason与投机解码可互补,两者结合能进一步降低延迟,相比单独的投机解码,延迟可额外减少19.4 - 44.2%。
方法论精要
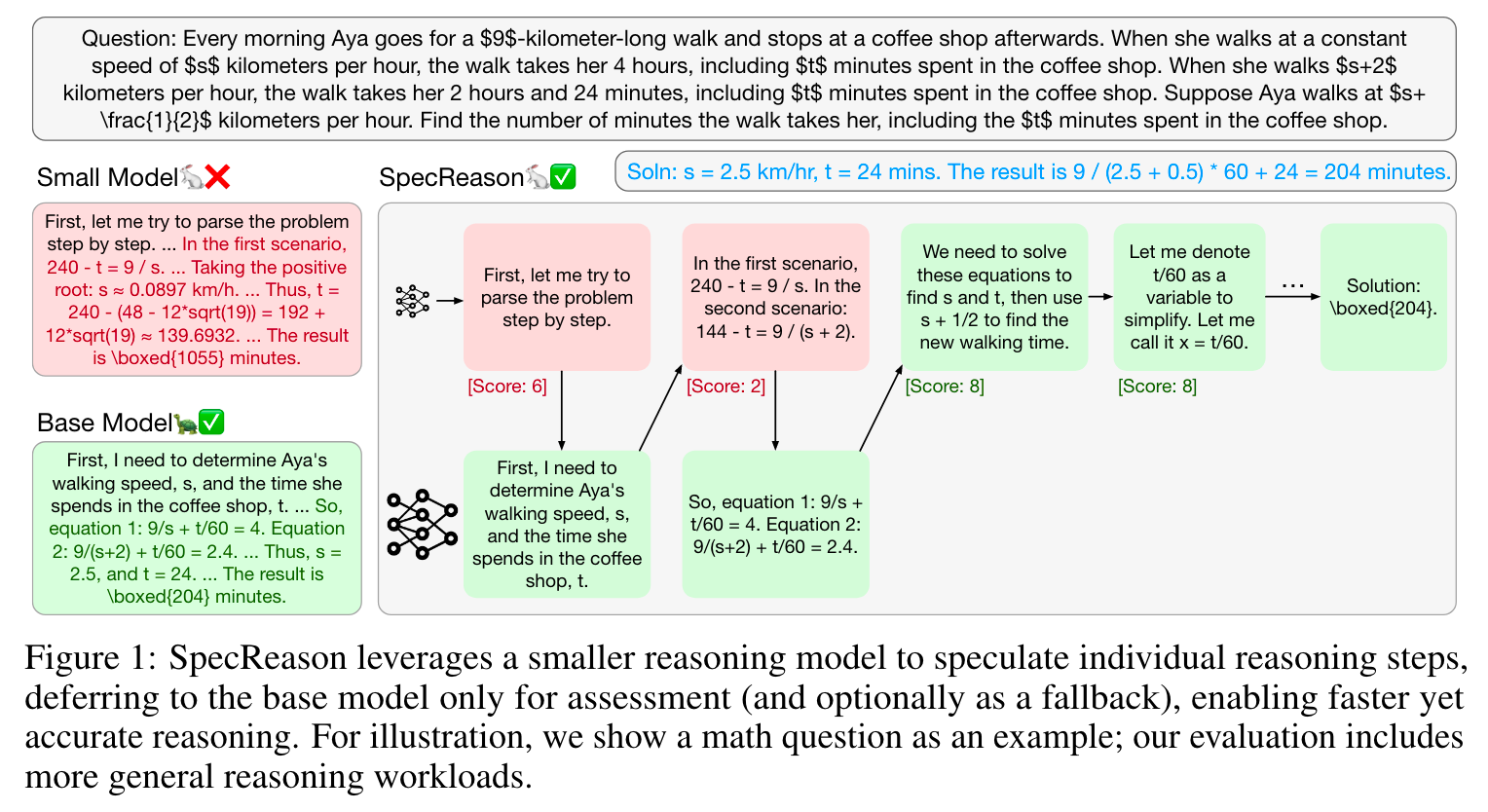
- 核心算法/框架:SpecReason采用一种新的推测执行形式,将较简单或不太关键的推理步骤(如完整的推理步骤或句子这样语义自包含的单元)卸载到轻量级模型进行推测,再由基础模型评估其效用。
- 关键参数设计原理:通过设置基础模型评估推测步骤效用的分数阈值(如静态阈值score ≥7 )来决定是否接受推测步骤。该阈值可调整,控制推测的激进程度,进而平衡推理延迟和准确率。
- 创新性技术组合:结合轻量级模型的快速推测和基础模型的精准评估,利用LRM推理对近似的容忍性,在语义层面而非token层面追求相似性,实现高效推理加速。
- 实验验证方式:使用QwQ - 32B作为基础模型,蒸馏版DeepSeek - R1(R1 - 1.5B)作为小模型,在AIME、MATH500和GPQA三个推理基准数据集上进行实验。对比基线包括使用小模型和基础模型的普通推理,以及以R1 - 1.5B为草稿模型的投机解码,还测试了将SpecReason与投机解码结合的“SpecReason+Decode”方法。
实验洞察
- 性能优势:在MATH、AIME和GPQA数据集上,SpecReason相比基础模型的普通推理,延迟分别降低2.5倍、1.9倍和1.5倍,准确率分别提高1.0%、3.1%和9.9%。与投机解码相比,SpecReason处于准确率 - 延迟权衡的帕累托前沿,且SpecReason+Decode相比单独的投机解码,延迟进一步降低44.2%、33.8%和19.4%。
- 效率突破:SpecReason实现了1.5 - 2.5倍的推理加速,减少了端到端的推理延迟。与投机解码结合后,能进一步优化推理效率。
- 消融研究:通过调整基础模型评估推测步骤的接受阈值,发现提高阈值会减少小模型推测步骤的接受率,使延迟增加但准确率提高。在不同数据集上,这种趋势有所不同,如AIME数据集上小模型与基础模型性能差距大,放宽阈值对准确率影响更明显,证明了SpecReason中基础模型评估和阈值设置对整体性能的重要性。
本文由AI辅助完成。