为什么要分布式训练?
随着深度学习模型参数量和数据量不断增大,单卡显存和计算能力有限,单机单卡训练难以满足大模型/大数据集训练需求,因此我们需要:
单机多卡并行:利用一台机器上多张 GPU 加速训练。
多机多卡并行:多台机器协同训练,实现大规模分布式计算。
分布式训练的常见方式
数据并行(Data Parallelism):每个 GPU 拷贝一份相同模型,划分不同 batch 数据独立计算,再同步梯度更新。
模型并行(Model Parallelism):将模型拆分到不同 GPU,适合单卡放不下的超大模型。
本文聚焦 数据并行 中的 PyTorch 官方实现:DistributedDataParallel (DDP)。
1. 相关参数设置
# distribution training
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='env://', type=str,
help='url used to set up distributed training')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument("--local_rank", type=int, help='local rank for DistributedDataParallel')
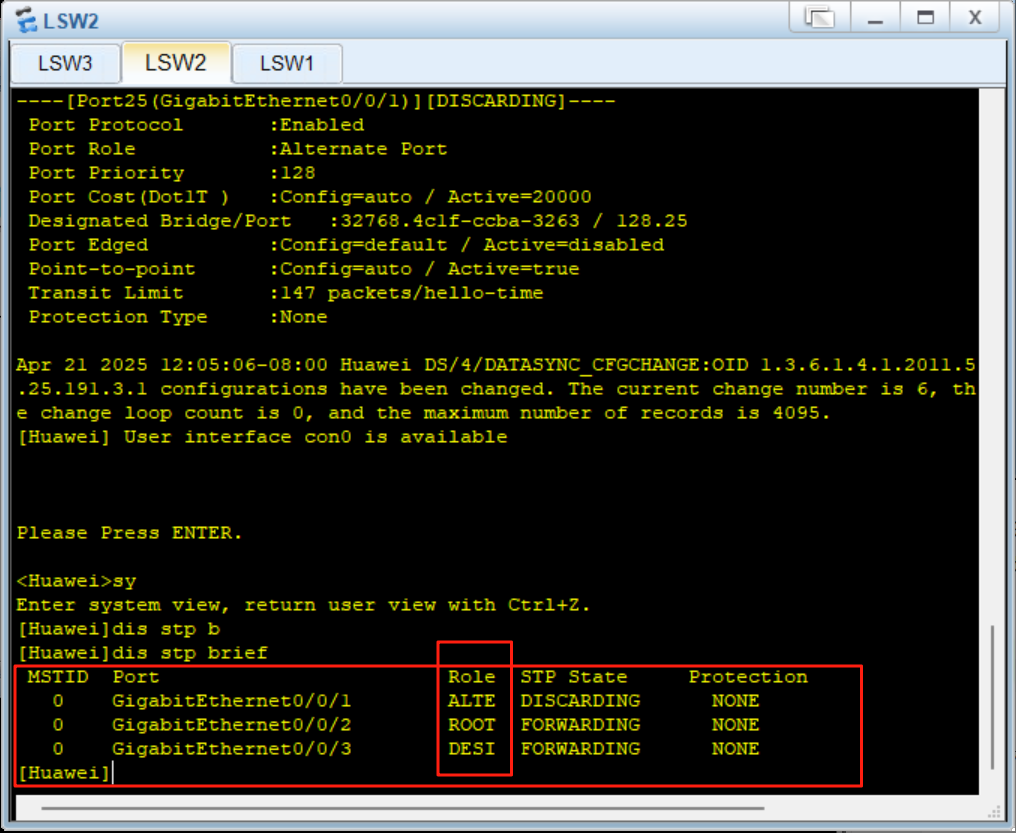
–world-size: 总的进程数(所有节点上的进程数之和)1台机器×8卡 → 8, 2台×8卡 → 16
–rank: 当前进程所在的“节点”编号,从0开始
–dist-url: 分布式进程通信的初始化地址’env://’ 用环境变量,或者 ‘tcp://ip:port’
–seed: 随机种子,保证可复现
–local_rank: 当前进程在本节点内的GPU编号,launch 或 torchrun 自动传
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --node_rank=0 --master_addr="x.x.x.x" --master_port=12345 main.py --world-size 2 --rank 0
–nproc_per_node:单个节点启动多少个进程(等于单机的 GPU 数)
比如:
2台机器,每台8张GPU
每台跑 8 个进程(–nproc_per_node=8)
world_size = nnodes × nproc_per_node = 2 × 8 = 16
rank 是全局进程编号
节点0的8个进程 → rank 0~7
节点1的8个进程 → rank 8~15
🔸 local_rank 是节点内GPU编号
节点0内 rank=0 的进程 → local_rank=0
节点0内 rank=1 的进程 → local_rank=1
…
节点1内 rank=8 的进程 → local_rank=0
节点1内 rank=9 的进程 → local_rank=1
🔸 dist_url 是所有进程用来连线通信的地址
通常是 env://,或者 tcp://192.168.1.1:12345
🔸现在推荐 torchrun(后续补充)更简洁
torchrun --nnodes=2 --nproc_per_node=8 --node_rank=0 --master_addr=192.168.1.1 --master_port=12345 main.py --seed 42
不用你 main.py 里写 --world-size 和 --rank,torchrun 自动算好放进环境变量 RANK、WORLD_SIZE、LOCAL_RANK,然后你可以直接在代码里:
local_rank = int(os.environ[“LOCAL_RANK”])
rank = int(os.environ[“RANK”])
world_size = int(os.environ[“WORLD_SIZE”])
2. 判断是否进行分布式
if 'WORLD_SIZE' in os.environ:
assert args.world_size > 0, 'please set --world-size and --rank in the command line'
# launch by torch.distributed.launch
# Single node
# python -m torch.distributed.launch --nproc_per_node=8 main.py --world-size 1 --rank 0 ...
# Multi nodes
# python -m torch.distributed.launch --nproc_per_node=8 main.py --world-size 2 --rank 0 --dist-url 'tcp://IP_OF_NODE0:FREEPORT' ...
# python -m torch.distributed.launch --nproc_per_node=8 main.py --world-size 2 --rank 1 --dist-url 'tcp://IP_OF_NODE0:FREEPORT' ...
local_world_size = int(os.environ['WORLD_SIZE'])
args.world_size = args.world_size * local_world_size
args.rank = args.rank * local_world_size + args.local_rank
print('world size: {}, world rank: {}, local rank: {}'.format(args.world_size, args.rank, args.local_rank))
print('os.environ:', os.environ)
else:
# single process, useful for debugging
# python main.py ...
args.world_size = 1
args.rank = 0
args.local_rank = 0
if args.seed is not None:
random.seed(args.seed)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
torch.distributed.launch 或 torchrun 启动的时候,会自动往 os.environ 里塞环境变量:
WORLD_SIZE:总进程数(一般 = GPU 数)
RANK:当前进程的全局 rank 编号
LOCAL_RANK:当前进程在本机内的 GPU 编号
- 获取GPU数
local_world_size = int(os.environ['WORLD_SIZE'])# --nproc_per_node=8 即8个
- 计算全局 world_size 和 rank
args.world_size = args.world_size * local_world_size
args.rank = args.rank * local_world_size + args.local_rank
3. 环境变量与 rank/world_size 设置
- 分布式环境下,每个进程代表一个 GPU,需要知道:
- local_rank → 当前机器内 GPU 编号
- rank → 全局唯一进程编号
- world_size → 全局进程数量(= 总 GPU 数)
torch.cuda.set_device(args.local_rank)
print('| distributed init (local_rank {}): {}'.format(
args.local_rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend='nccl', init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
cudnn.benchmark = True
后续记录一些logger,代码省略。。。
4. 加载模型
# build model
model = build_model(args)
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], broadcast_buffers=False)
# loss
...
# optimizer
...
# Data loading code
train_dataset, val_dataset = get_datasets(args)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
assert args.batch_size // dist.get_world_size() == args.batch_size / dist.get_world_size(), 'Batch size is not divisible by num of gpus.'
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size // dist.get_world_size(), shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=True, sampler=train_sampler, drop_last=True)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=args.batch_size // dist.get_world_size(), shuffle=False,
num_workers=args.workers, pin_memory=True, sampler=val_sampler)
总结
先整理到这里,后续在实践中不断完善相关内容。