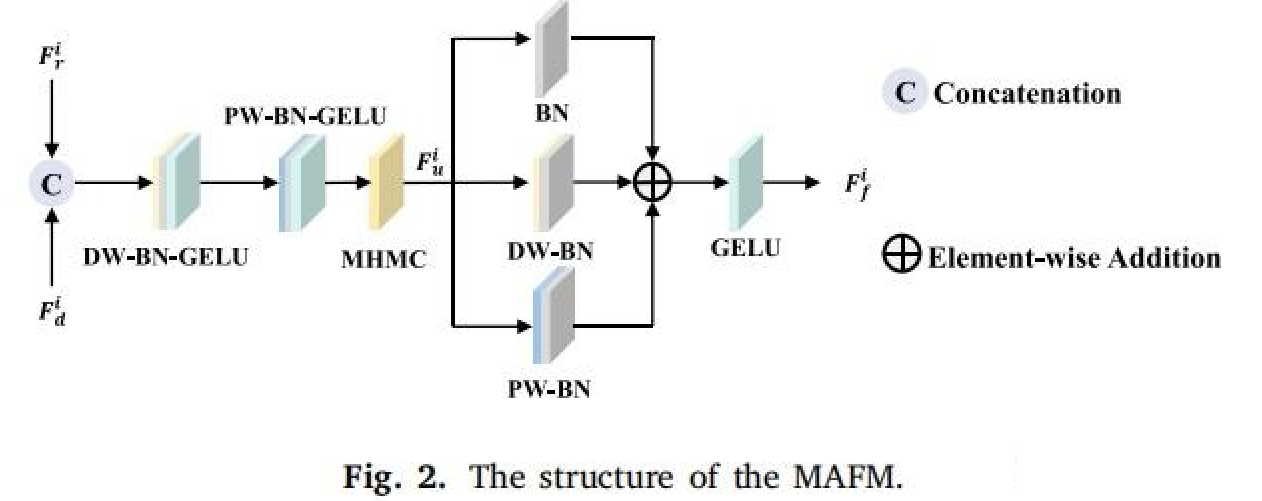
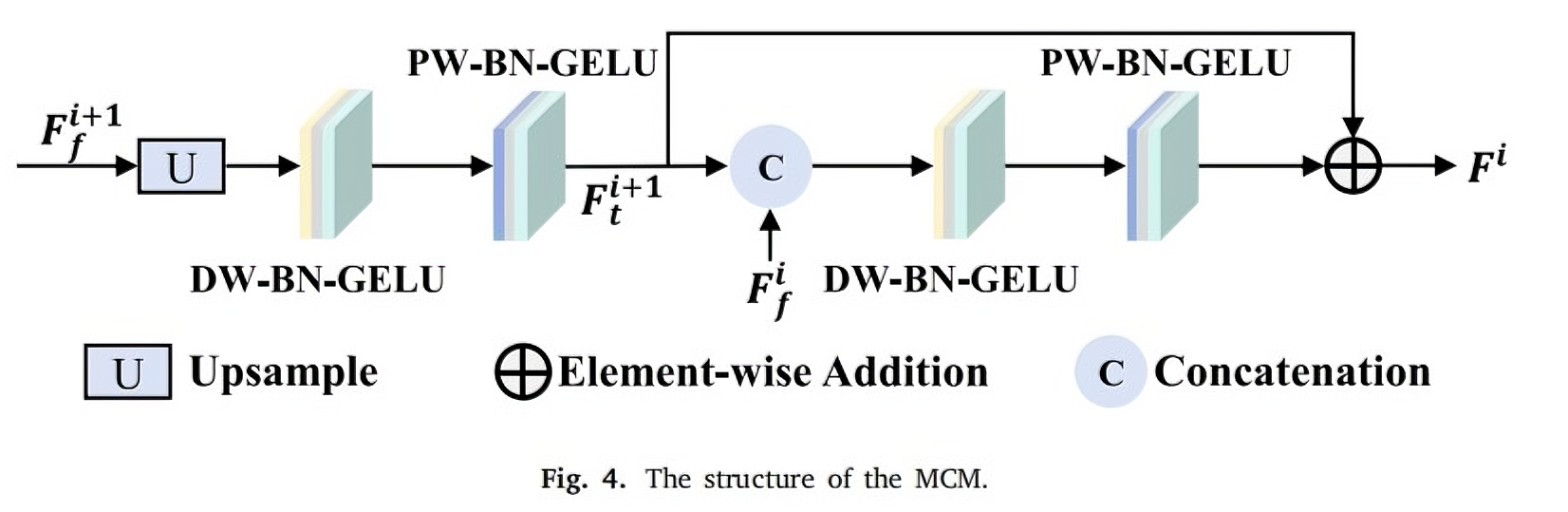
(即插即用模块-特征处理部分) 一、(2024) MAFM&MCM 特征融合+特征解码

paper:MAGNet: Multi-scale Awareness and Global fusion Network for RGB-D salient object detection
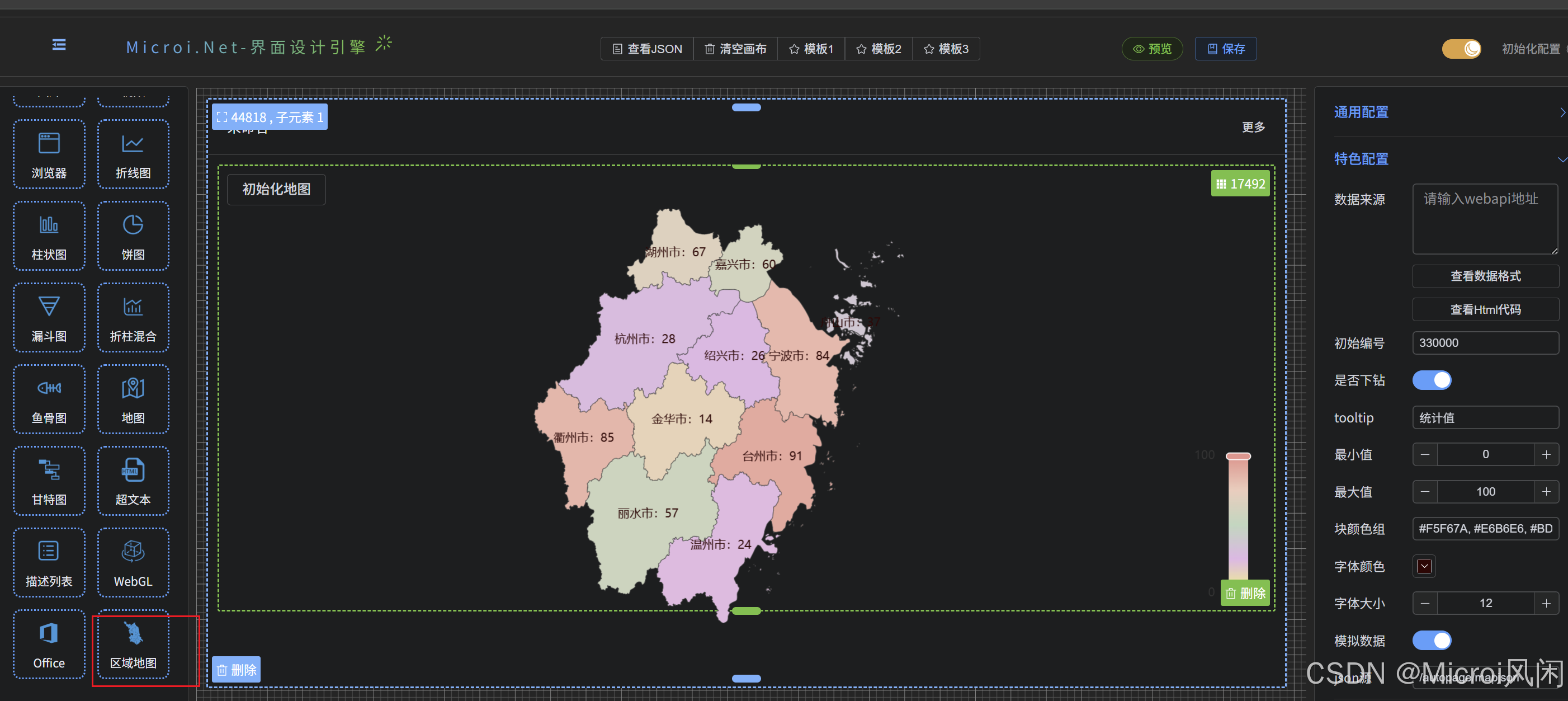
1. 多尺度感知融合模块 (MAFM)
多尺度感知融合模块 (MAFM) 旨在高效融合 RGB 和深度模态的互补信息,充分利用 RGB 图像的丰富纹理细节和深度图像的空间结构特性,同时克服 RGB 对光照变化的敏感性以及深度图像细节不足的局限性。通过多尺度特征整合和非线性变换,MAFM 实现高效的特征融合,同时降低计算复杂度。
实现流程:
- 特征拼接:将 RGB 和深度特征图沿通道维度拼接,形成统一的多模态特征表示,保留各模态的独特信息。
- 深度可分离卷积 (DW 层):应用深度可分离卷积高效提取空间局部特征,随后进行批归一化 (BN) 以稳定训练,并通过 GELU 激活函数引入非线性,提升特征表达能力。
- 点卷积 (PW 层):通过点卷积优化通道间交互,再次应用 BN 和 GELU 激活,确保特征的有效 recalibration。
- 多头多尺度卷积 (MHMC):将融合特征输入 MHMC 模块,通过多尺度卷积捕捉不同尺度的上下文信息,进一步增强特征融合效果。
- 残差融合:通过残差结构和元素级求和,整合不同分支的特征图,保留全局和局部信息。
- 非线性变换:最终通过 GELU 激活函数进行非线性变换,生成融合特征图。
Multi-scale Awareness Fusion Module 结构图:
2. 多级卷积模块 (MCM)
多级卷积模块 (MCM) 旨在通过多尺度特征融合,逐步生成包含丰富细节的噪声目标预测图。MCM 采用残差结构,包含多个卷积块,通过整合不同尺度的特征图显著提升解码器的学习能力和泛化性能。
实现流程:
- 特征上采样与拼接:对高级特征图进行上采样,并与下一级特征图沿通道维度拼接,构建多尺度特征表示。
- 深度可分离卷积 (DW 层):使用深度可分离卷积提取空间特征,随后进行 BN 和 GELU 激活,以高效处理多尺度信息。
- 点卷积 (PW 层):通过点卷积优化通道间特征交互,再次应用 BN 和 GELU 激活,确保特征鲁棒性。
- 残差连接:将融合特征图与残差连接的结果进行元素级求和,生成最终输出,保留细节并增强稳定性。
Multi-level Convolution Module 结构图:
3、代码实现
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
from timm.models.layers import trunc_normal_
# Conv_One_Identity
class COI(nn.Module):
def __init__(self, inc, k=3, p=1):
super().__init__()
self.outc = inc
self.dw = nn.Conv2d(inc, self.outc, kernel_size=k, padding=p, groups=inc)
self.conv1_1 = nn.Conv2d(inc, self.outc, kernel_size=1, stride=1)
self.bn1 = nn.BatchNorm2d(self.outc)
self.bn2 = nn.BatchNorm2d(self.outc)
self.bn3 = nn.BatchNorm2d(self.outc)
self.act = nn.GELU()
self.apply(self._init_weights)
def forward(self, x):
shortcut = self.bn1(x)
x_dw = self.bn2(self.dw(x))
x_conv1_1 = self.bn3(self.conv1_1(x))
return self.act(shortcut + x_dw + x_conv1_1)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
class MHMC(nn.Module):
def __init__(self, dim, ca_num_heads=4, qkv_bias=True, proj_drop=0., ca_attention=1, expand_ratio=2):
super().__init__()
self.ca_attention = ca_attention
self.dim = dim
self.ca_num_heads = ca_num_heads
assert dim % ca_num_heads == 0, f"dim {dim} should be divided by num_heads {ca_num_heads}."
self.act = nn.GELU()
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.split_groups = self.dim // ca_num_heads
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.s = nn.Linear(dim, dim, bias=qkv_bias)
for i in range(self.ca_num_heads):
local_conv = nn.Conv2d(dim // self.ca_num_heads, dim // self.ca_num_heads, kernel_size=(3 + i * 2),
padding=(1 + i), stride=1,
groups=dim // self.ca_num_heads) # kernel_size 3,5,7,9 大核dw卷积,padding 1,2,3,4
setattr(self, f"local_conv_{i + 1}", local_conv)
self.proj0 = nn.Conv2d(dim, dim * expand_ratio, kernel_size=1, padding=0, stride=1,
groups=self.split_groups)
self.bn = nn.BatchNorm2d(dim * expand_ratio)
self.proj1 = nn.Conv2d(dim * expand_ratio, dim, kernel_size=1, padding=0, stride=1)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
B, N, C = x.shape
v = self.v(x)
s = self.s(x).reshape(B, H, W, self.ca_num_heads, C // self.ca_num_heads).permute(3, 0, 4, 1,
2) # num_heads,B,C,H,W
for i in range(self.ca_num_heads):
local_conv = getattr(self, f"local_conv_{i + 1}")
s_i = s[i] # B,C,H,W
s_i = local_conv(s_i).reshape(B, self.split_groups, -1, H, W)
if i == 0:
s_out = s_i
else:
s_out = torch.cat([s_out, s_i], 2)
s_out = s_out.reshape(B, C, H, W)
s_out = self.proj1(self.act(self.bn(self.proj0(s_out))))
self.modulator = s_out
s_out = s_out.reshape(B, C, N).permute(0, 2, 1)
x = s_out * v
x = self.proj(x)
x = self.proj_drop(x)
return x
# Multi-scale Awareness Fusion Module
class MAFM(nn.Module):
def __init__(self, inc):
super().__init__()
self.outc = inc
self.attention = MHMC(dim=inc)
self.coi = COI(inc)
self.pw = nn.Sequential(
nn.Conv2d(in_channels=inc, out_channels=inc, kernel_size=1, stride=1),
nn.BatchNorm2d(inc),
nn.GELU()
)
self.pre_att = nn.Sequential(
nn.Conv2d(inc * 2, inc * 2, kernel_size=3, padding=1, groups=inc * 2),
nn.BatchNorm2d(inc * 2),
nn.GELU(),
nn.Conv2d(inc * 2, inc, kernel_size=1),
nn.BatchNorm2d(inc),
nn.GELU()
)
self.apply(self._init_weights)
def forward(self, x, d):
B, C, H, W = x.shape
x_cat = torch.cat((x, d), dim=1)
x_pre = self.pre_att(x_cat)
# Attention
x_reshape = x_pre.flatten(2).permute(0, 2, 1) # B,C,H,W to B,N,C
attention = self.attention(x_reshape, H, W) # attention
attention = attention.permute(0, 2, 1).reshape(B, C, H, W) # B,N,C to B,C,H,W
# COI
x_conv = self.coi(attention) # dw3*3,1*1,identity
x_conv = self.pw(x_conv) # pw
return x_conv
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
# Decoder
class MCM(nn.Module):
def __init__(self, inc, outc):
super().__init__()
self.upsample2 = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.rc = nn.Sequential(
nn.Conv2d(in_channels=inc, out_channels=inc, kernel_size=3, padding=1, stride=1, groups=inc),
nn.BatchNorm2d(inc),
nn.GELU(),
nn.Conv2d(in_channels=inc, out_channels=outc, kernel_size=1, stride=1),
nn.BatchNorm2d(outc),
nn.GELU()
)
self.predtrans = nn.Sequential(
nn.Conv2d(in_channels=outc, out_channels=outc, kernel_size=3, padding=1, groups=outc),
nn.BatchNorm2d(outc),
nn.GELU(),
nn.Conv2d(in_channels=outc, out_channels=1, kernel_size=1)
)
self.rc2 = nn.Sequential(
nn.Conv2d(in_channels=outc * 2, out_channels=outc * 2, kernel_size=3, padding=1, groups=outc * 2),
nn.BatchNorm2d(outc * 2),
nn.GELU(),
nn.Conv2d(in_channels=outc * 2, out_channels=outc, kernel_size=1, stride=1),
nn.BatchNorm2d(outc),
nn.GELU()
)
self.apply(self._init_weights)
def forward(self, x1, x2):
x2_upsample = self.upsample2(x2) # 上采样
x2_rc = self.rc(x2_upsample) # 减少通道数
shortcut = x2_rc
x_cat = torch.cat((x1, x2_rc), dim=1) # 拼接
x_forward = self.rc2(x_cat) # 减少通道数2
x_forward = x_forward + shortcut
pred = F.interpolate(self.predtrans(x_forward), 384, mode="bilinear", align_corners=True) # 预测图
return pred, x_forward
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
if __name__ == '__main__':
x = torch.randn(4, 16, 128, 128).cuda()
y = torch.randn(4, 16, 128, 128).cuda()
z = torch.randn(4, 32, 64, 64).cuda()
model = MAFM(16).cuda()
out = model(x, y)
# model = MCM(32, 16).cuda()
# _, out = model(x, z)
# print(out.shape)
':
x = torch.randn(4, 16, 128, 128).cuda()
y = torch.randn(4, 16, 128, 128).cuda()
z = torch.randn(4, 32, 64, 64).cuda()
model = MAFM(16).cuda()
out = model(x, y)
# model = MCM(32, 16).cuda()
# _, out = model(x, z)
# print(out.shape)


![[Swift]Xcode模拟器无法请求http接口问题](https://i-blog.csdnimg.cn/direct/31cfc77051954e119b8b388ef13a5eb7.png)