查重是数据库管理和数据分析中的常见需求,以下是各种查重方法的全面总结,涵盖不同场景和技术手段。
更多Oracle学习内容请查看:Oracle保姆级超详细系列教程_Tyler先森的博客-CSDN博客
目录
一、基础SQL查重方法
1. 使用GROUP BY和HAVING
2. 使用窗口函数
3. 使用自连接
二、高级查重技术
1. 模糊查重(相似度匹配)
1.1 使用SOUNDEX函数(语音相似)
1.2 使用Levenshtein距离(编辑距离)
1.3 使用UTL_MATCH包(Oracle)
2. 大数据量查重优化
2.1 使用HASH值比较
2.2 分区查重
3. 跨表查重
三、数据库特定查重方法
1. Oracle查重技术
1.1 使用分析函数
1.2 使用Oracle GoldenGate或Data Compare工具
2. MySQL查重技术
2.1 使用临时表删除重复
2.2 使用INSERT IGNORE
3. SQL Server查重技术
3.1 使用MERGE语句
3.2 使用SSIS数据流任务
四、程序化查重方法
1. Python + Pandas
2. Java查重示例
3. 使用Apache Spark(大数据场景)
五、数据质量工具集成
1. 专业数据质量工具
2. 开源工具
六、查重后的处理策略
1. 删除重复数据
2. 合并重复记录
3. 标记重复记录
七、预防重复数据的策略
1. 数据库约束
2. 使用序列/自增ID
3. 应用层校验
4. 使用MERGE/UPSERT
八、特殊数据类型查重
1. JSON数据查重
2. 时空数据查重
3. 图像/二进制数据查重
九、性能优化建议
十、行业特定查重案例
1. 金融行业(反洗钱)
2. 电商行业(刷单检测)
3. 医疗行业(重复就诊)
一、基础SQL查重方法
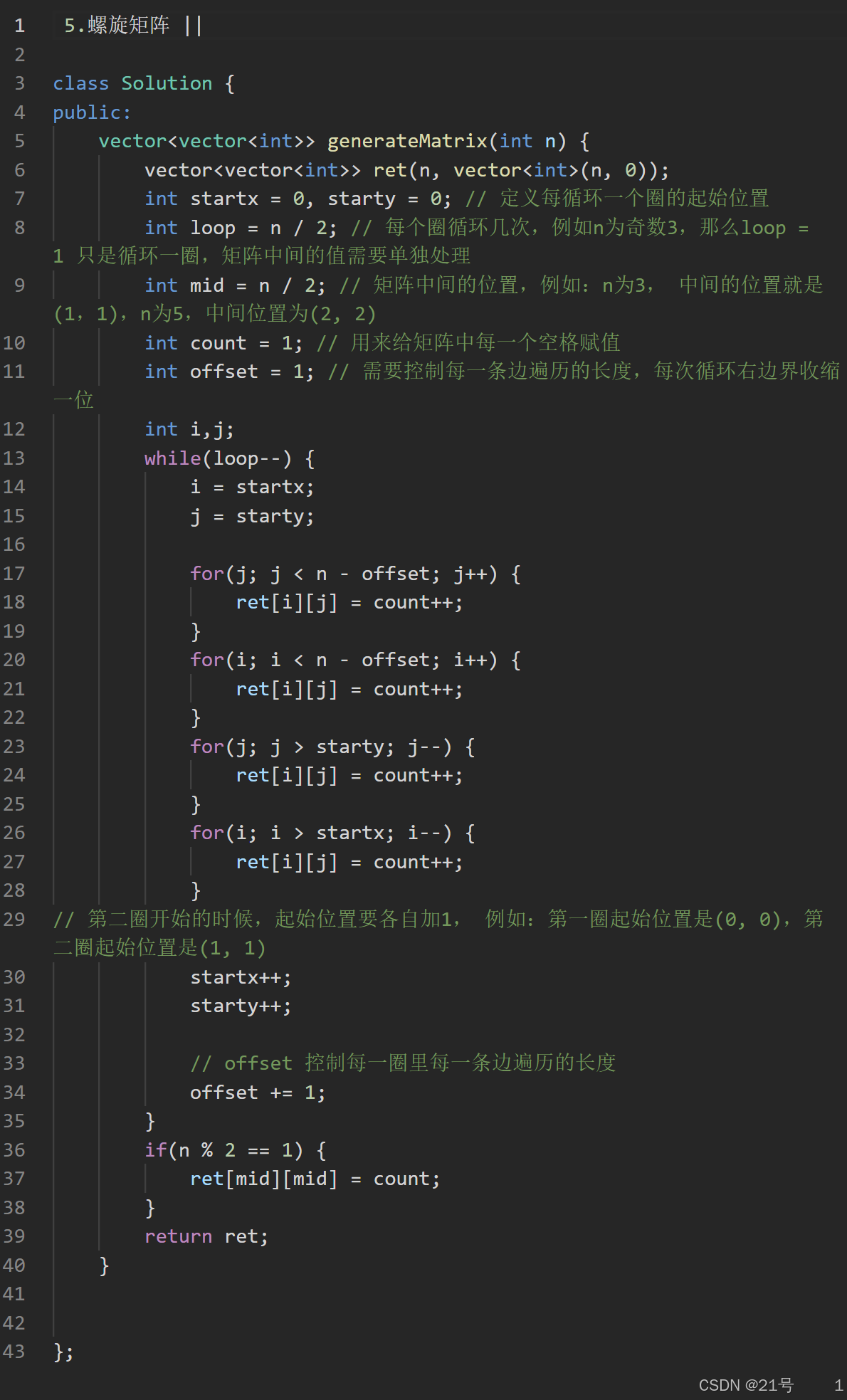
1. 使用GROUP BY和HAVING
-- 单列查重
SELECT column_name, COUNT(*)
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1;
-- 多列组合查重
SELECT column1, column2, COUNT(*)
FROM table_name
GROUP BY column1, column2
HAVING COUNT(*) > 1;2. 使用窗口函数
-- 使用ROW_NUMBER()标记重复行
SELECT *,
ROW_NUMBER() OVER(PARTITION BY column1, column2 ORDER BY id) AS rn
FROM table_name;
-- 提取重复记录
WITH dup_check AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY column1, column2 ORDER BY id) AS rn
FROM table_name
)
SELECT * FROM dup_check WHERE rn > 1;3. 使用自连接
-- 查找完全重复的行
SELECT a.*
FROM table_name a
JOIN table_name b
ON a.column1 = b.column1
AND a.column2 = b.column2
AND a.id <> b.id; -- 排除自连接二、高级查重技术
1. 模糊查重(相似度匹配)
1.1 使用SOUNDEX函数(语音相似)
SELECT a.name, b.name
FROM customers a, customers b
WHERE a.id < b.id -- 避免重复比较
AND SOUNDEX(a.name) = SOUNDEX(b.name);1.2 使用Levenshtein距离(编辑距离)
-- Oracle需要自定义函数
CREATE OR REPLACE FUNCTION levenshtein( s1 IN VARCHAR2, s2 IN VARCHAR2 )
RETURN NUMBER IS [...];
SELECT a.name, b.name
FROM products a, products b
WHERE a.id < b.id
AND levenshtein(a.name, b.name) <= 3; -- 允许3个字符差异1.3 使用UTL_MATCH包(Oracle)
SELECT a.name, b.name,
UTL_MATCH.JARO_WINKLER_SIMILARITY(a.name, b.name) AS similarity
FROM customers a, customers b
WHERE a.id < b.id
AND UTL_MATCH.JARO_WINKLER_SIMILARITY(a.name, b.name) > 90; -- 相似度>90%2. 大数据量查重优化
2.1 使用HASH值比较
-- 创建哈希列
ALTER TABLE large_table ADD hash_value RAW(16);
-- 更新哈希值(组合关键列)
UPDATE large_table
SET hash_value = DBMS_CRYPTO.HASH(
UTL_I18N.STRING_TO_RAW(column1||column2||column3, 'AL32UTF8'),
2); -- 2=MD4算法
-- 查找重复哈希
SELECT hash_value, COUNT(*)
FROM large_table
GROUP BY hash_value
HAVING COUNT(*) > 1;2.2 分区查重
-- 按日期分区查重
SELECT user_id, action_date, COUNT(*)
FROM user_actions
PARTITION (p_2023_01) -- 指定分区
GROUP BY user_id, action_date
HAVING COUNT(*) > 1;3. 跨表查重
-- 查找两个表中都存在的记录
SELECT a.*
FROM table1 a
WHERE EXISTS (
SELECT 1 FROM table2 b
WHERE a.key_column = b.key_column
);
-- 使用INTERSECT
SELECT key_column FROM table1
INTERSECT
SELECT key_column FROM table2;三、数据库特定查重方法
1. Oracle查重技术
1.1 使用分析函数
-- 查找重复并保留最新记录
SELECT *
FROM (
SELECT t.*,
ROW_NUMBER() OVER(PARTITION BY id_number, name ORDER BY create_date DESC) AS rn
FROM persons
)
WHERE rn = 1; -- 只保留每组最新记录1.2 使用Oracle GoldenGate或Data Compare工具
专业工具提供可视化比较和同步功能。
2. MySQL查重技术
2.1 使用临时表删除重复
-- 创建临时表存储唯一记录
CREATE TABLE temp_table AS
SELECT DISTINCT * FROM original_table;
-- 替换原表
RENAME TABLE original_table TO old_table, temp_table TO original_table;2.2 使用INSERT IGNORE
-- 跳过重复记录插入
INSERT IGNORE INTO target_table
SELECT * FROM source_table;3. SQL Server查重技术
3.1 使用MERGE语句
MERGE INTO target_table t
USING source_table s
ON t.key_column = s.key_column
WHEN NOT MATCHED THEN
INSERT (col1, col2) VALUES (s.col1, s.col2);3.2 使用SSIS数据流任务
SQL Server Integration Services提供图形化查重组件。
四、程序化查重方法
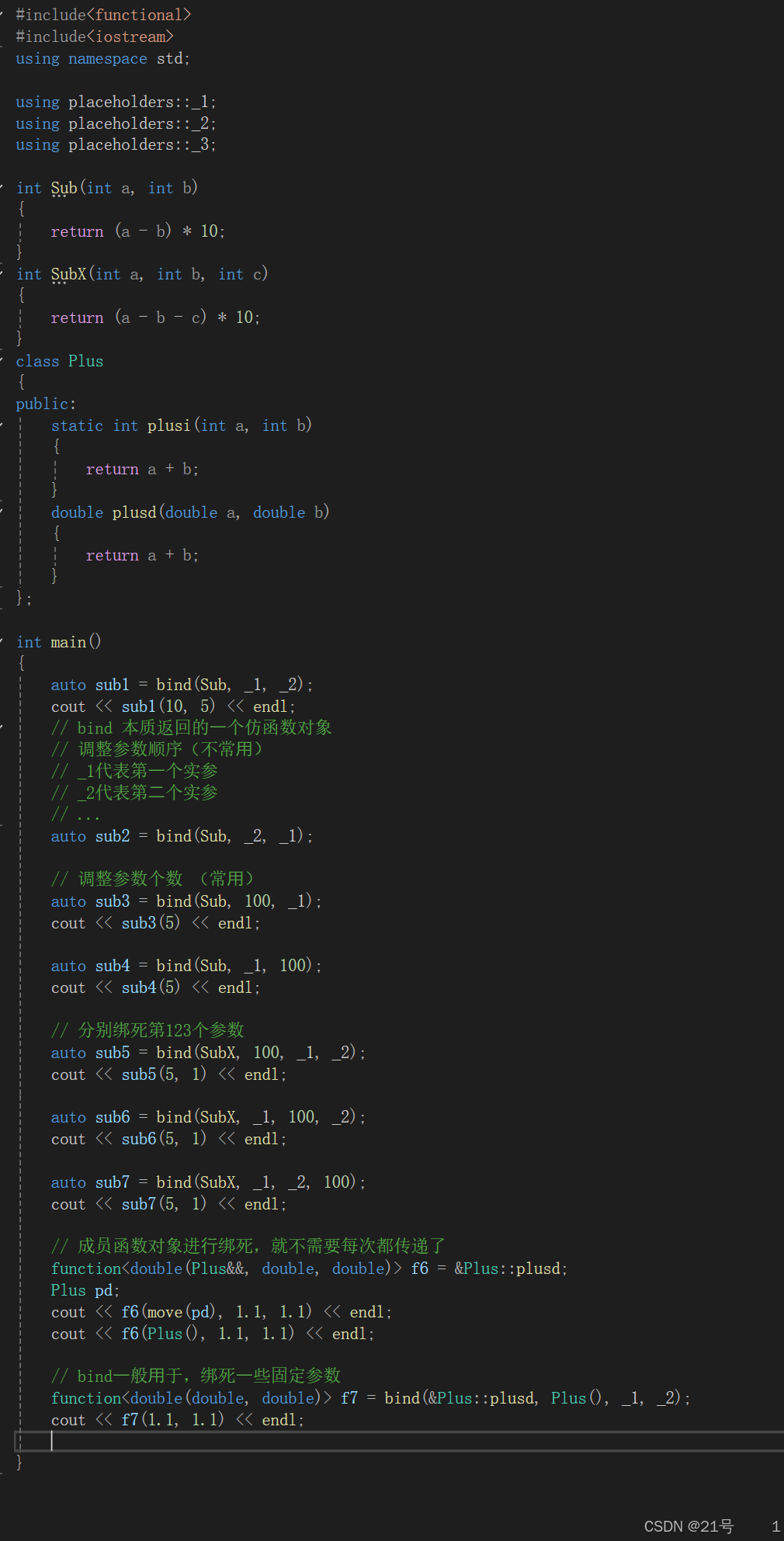
1. Python + Pandas
import pandas as pd
# 读取数据
df = pd.read_sql("SELECT * FROM table_name", engine)
# 简单查重
duplicates = df[df.duplicated(subset=['col1', 'col2'], keep=False)]
# 模糊查重(使用fuzzywuzzy)
from fuzzywuzzy import fuzz
dupe_pairs = []
for i, row1 in df.iterrows():
for j, row2 in df.iterrows():
if i < j and fuzz.ratio(row1['name'], row2['name']) > 85:
dupe_pairs.append((i, j))2. Java查重示例
// 使用内存哈希集查重
Set<String> uniqueKeys = new HashSet<>();
List<Record> duplicates = new ArrayList<>();
for (Record record : records) {
String compositeKey = record.getField1() + "|" + record.getField2();
if (!uniqueKeys.add(compositeKey)) {
duplicates.add(record);
}
}3. 使用Apache Spark(大数据场景)
val df = spark.read.jdbc(...) // 从数据库读取
// 精确查重
val duplicates = df.groupBy("col1", "col2")
.count()
.filter("count > 1")
// 近似查重(使用MinHash)
import org.apache.spark.ml.feature.MinHashLSH
val mh = new MinHashLSH().setInputCol("features").setOutputCol("hashes")
val model = mh.fit(featurizedData)
val dupCandidates = model.approxSimilarityJoin(featurizedData, featurizedData, 0.8)五、数据质量工具集成
1. 专业数据质量工具
- Informatica Data Quality
- IBM InfoSphere QualityStage
- Talend Data Quality
- Oracle Enterprise Data Quality
2. 开源工具
- OpenRefine:强大的数据清洗和查重工具
- DataCleaner:提供可视化查重规则配置
- Dedupe.io:基于机器学习的智能去重
六、查重后的处理策略
1. 删除重复数据
-- Oracle使用ROWID删除重复
DELETE FROM table_name
WHERE ROWID NOT IN (
SELECT MIN(ROWID)
FROM table_name
GROUP BY column1, column2
);
-- MySQL使用临时表
CREATE TABLE temp_table AS SELECT DISTINCT * FROM original_table;
TRUNCATE TABLE original_table;
INSERT INTO original_table SELECT * FROM temp_table;
DROP TABLE temp_table;2. 合并重复记录
-- 合并重复客户记录
UPDATE customers c1
SET (address, phone) = (
SELECT COALESCE(c1.address, c2.address),
COALESCE(c1.phone, c2.phone)
FROM customers c2
WHERE c1.email = c2.email
AND c2.ROWID = (
SELECT MIN(ROWID)
FROM customers c3
WHERE c3.email = c1.email
)
)
WHERE c1.ROWID <> (
SELECT MIN(ROWID)
FROM customers c4
WHERE c4.email = c1.email
);3. 标记重复记录
-- 添加重复标记列
ALTER TABLE customers ADD is_duplicate NUMBER(1) DEFAULT 0;
-- 标记重复记录
UPDATE customers c
SET is_duplicate = 1
WHERE EXISTS (
SELECT 1 FROM customers c2
WHERE c.email = c2.email
AND c.ROWID > c2.ROWID
);七、预防重复数据的策略
1. 数据库约束
-- 唯一约束
ALTER TABLE products ADD CONSTRAINT uk_product_code UNIQUE (product_code);
-- 复合唯一约束
ALTER TABLE orders ADD CONSTRAINT uk_order_item UNIQUE (order_id, product_id);2. 使用序列/自增ID
-- Oracle序列
CREATE SEQUENCE customer_id_seq START WITH 1 INCREMENT BY 1;
-- MySQL自增
CREATE TABLE customers (
id INT AUTO_INCREMENT PRIMARY KEY,
...
);3. 应用层校验
// Java示例-插入前检查
public boolean isCustomerExist(String email) {
String sql = "SELECT 1 FROM customers WHERE email = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement stmt = conn.prepareStatement(sql)) {
stmt.setString(1, email);
try (ResultSet rs = stmt.executeQuery()) {
return rs.next();
}
}
}4. 使用MERGE/UPSERT
-- Oracle MERGE
MERGE INTO customers t
USING (SELECT 'john@example.com' email, 'John' name FROM dual) s
ON (t.email = s.email)
WHEN NOT MATCHED THEN
INSERT (email, name) VALUES (s.email, s.name)
WHEN MATCHED THEN
UPDATE SET t.name = s.name;八、特殊数据类型查重
1. JSON数据查重
-- PostgreSQL JSONB查重
SELECT json_column->>'id', COUNT(*)
FROM json_table
GROUP BY json_column->>'id'
HAVING COUNT(*) > 1;
-- Oracle JSON查重
SELECT JSON_VALUE(json_column, '$.id'), COUNT(*)
FROM json_table
GROUP BY JSON_VALUE(json_column, '$.id')
HAVING COUNT(*) > 1;2. 时空数据查重
-- 地理位置相近查重(PostGIS)
SELECT a.id, b.id
FROM locations a, locations b
WHERE a.id < b.id
AND ST_DWithin(a.geom, b.geom, 100); -- 100米范围内视为重复
-- 时间范围重叠查重
SELECT a.event_id, b.event_id
FROM events a, events b
WHERE a.event_id < b.event_id
AND a.end_time > b.start_time
AND a.start_time < b.end_time;3. 图像/二进制数据查重
-- 使用哈希比较图像
SELECT image_hash, COUNT(*)
FROM images
GROUP BY image_hash
HAVING COUNT(*) > 1;
-- Oracle使用DBMS_CRYPTO
SELECT DBMS_CRYPTO.HASH(image_data, 2) AS img_hash
FROM images;九、性能优化建议
- 索引优化:为查重字段创建合适索引
CREATE INDEX idx_customer_email ON customers(email); - 分批处理:大数据集分批次查重
-- 按时间范围分批 SELECT * FROM orders WHERE order_date BETWEEN TO_DATE('2023-01-01') AND TO_DATE('2023-01-31') GROUP BY customer_id, product_id HAVING COUNT(*) > 1; - 物化视图:预计算重复数据
CREATE MATERIALIZED VIEW duplicate_orders_mv REFRESH COMPLETE ON DEMAND AS SELECT customer_id, product_id, COUNT(*) FROM orders GROUP BY customer_id, product_id HAVING COUNT(*) > 1; - 并行查询:
SELECT /*+ PARALLEL(4) */ column1, COUNT(*) FROM large_table GROUP BY column1 HAVING COUNT(*) > 1; -
使用NoSQL解决方案:对于超大规模数据,考虑Redis或MongoDB等方案
十、行业特定查重案例
1. 金融行业(反洗钱)
-- 查找同一天多笔大额交易
SELECT customer_id, transaction_date, COUNT(*), SUM(amount)
FROM transactions
GROUP BY customer_id, transaction_date
HAVING COUNT(*) > 3 AND SUM(amount) > 100000;2. 电商行业(刷单检测)
-- 检测相同IP短时间内下单
SELECT ip_address, COUNT(DISTINCT user_id), COUNT(*)
FROM orders
WHERE order_time > SYSDATE - 1/24 -- 最近1小时
GROUP BY ip_address
HAVING COUNT(DISTINCT user_id) > 3 OR COUNT(*) > 5;3. 医疗行业(重复就诊)
-- 查找同一患者相同诊断重复挂号
SELECT patient_id, diagnosis, visit_date, COUNT(*)
FROM medical_records
GROUP BY patient_id, diagnosis, TRUNC(visit_date)
HAVING COUNT(*) > 1;以上方法涵盖了从基础到高级的各种查重技术,实际应用中应根据数据特点、系统环境和业务需求选择合适的方法组合。对于关键业务系统,建议建立常态化的数据质量检查机制,而不仅仅是临时查重。