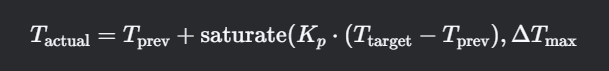Redis 主从复制概述
Redis 的主从复制是一种机制,允许一个主节点(主实例)将数据复制到一个或多个从节点(从实例)。通过这一机制,从节点可以获取主节点的数据并与之保持同步。
复制流程
- 开始同步:从节点通过向主节点发送
PSYNC命令请求同步。 - 全量复制:如果是第一次连接或之前的连接失效,从节点会请求进行全量复制,主节点会将当前数据快照(RDB 文件)发送给从节点。
- 增量复制:全量复制完成后,主从之间保持一个长连接,主节点会通过此连接将后续的写操作传递给从节点,从而确保数据一致性。
Redis 主从架构
下图展示了一个 Redis 主从架构:
在这一架构中,仅主节点可以进行写入操作,而其他从节点通过复制来保持数据的一致性。这种机制不仅保障了数据一致性,还通过将读请求分散到多个节点,提高了系统的吞吐量和可用性。
主从复制原理详解
Redis 的主从复制主要有两种同步方式:全量同步和增量同步。
1. 全量同步
下图描述了全量同步的流程:
- 流程:
- 从节点发送命令
psync ? -1触发全量同步请求。 - 主节点接收到请求后,发现从节点传递的 run ID 为“?”(表示未知),因此判断为需要进行全量同步,并返回其自身的 run ID 以及当前的复制进度。
- 主节点执行
bgsave生成 RDB 文件,同时将新接收到的写入命令存储在一个名为 replication buffer 的临时缓冲区中。 - RDB 文件生成完成后,主节点将其发送给从节点,从节点在接收后清空旧数据并加载新的 RDB 数据。
- 加载完成后,主节点将 replication buffer 中缓存的写入命令发送给从节点,以确保数据的一致性。
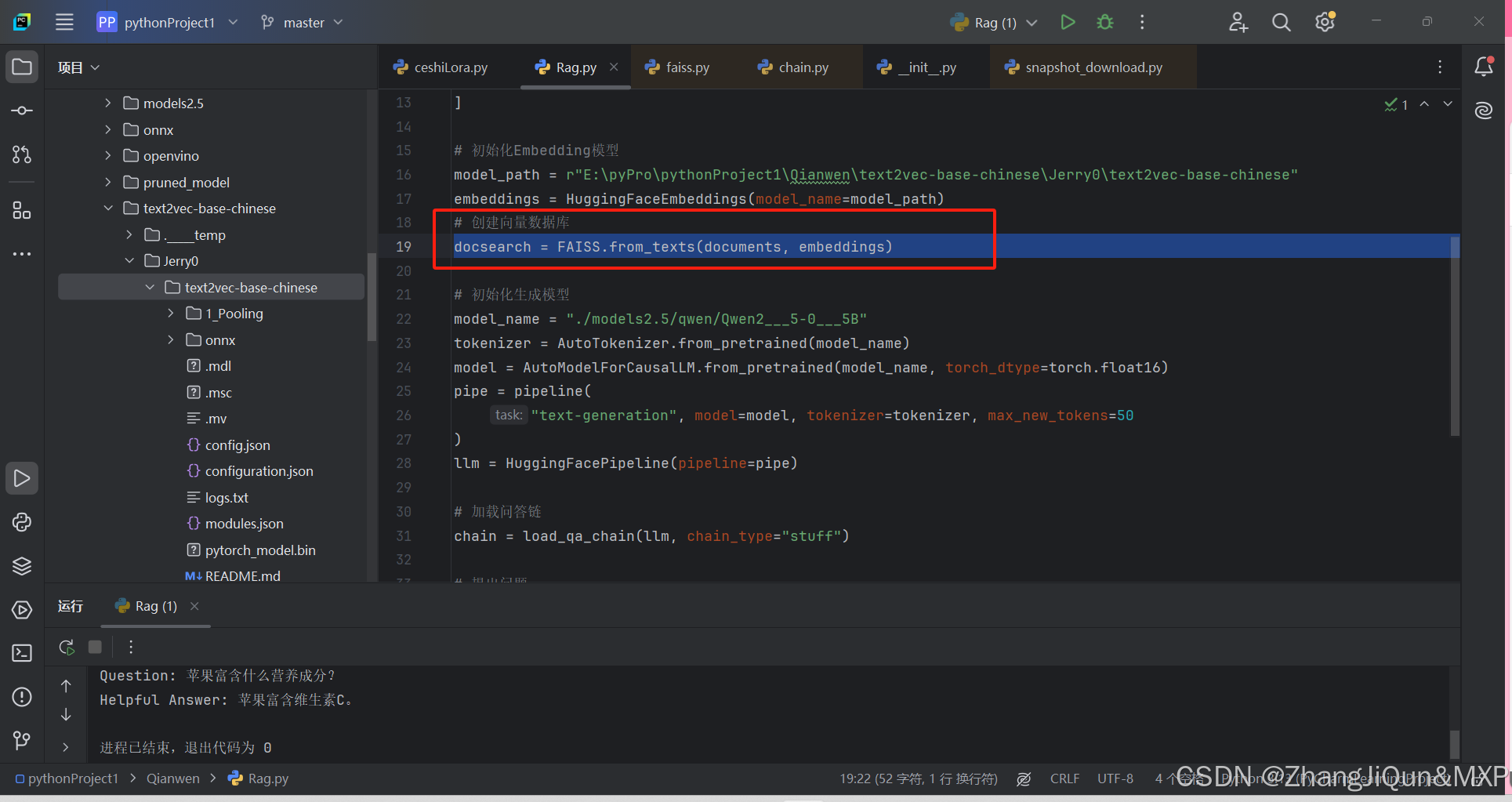
- 从节点发送命令
2. 增量同步
- 背景:在网络不稳定的情况下,主节点的一部分写操作可能未能成功传递给从节点。全量同步的数据量较大且耗时,因此 Redis 引入了增量同步(从 Redis 2.8 版本开始)。
- 使用
repl_backlog_buffer:repl_backlog_buffer是一个环形缓冲区,默认大小为 1 MB,用于存储主节点最近的写入命令。- 当从节点重新连接时,如果它的 run ID 与主节点一致,并且 offset 值在
repl_backlog_buffer中,主节点将从缓冲区中查找相应的命令并发送给从节点,以实现增量同步。
replication buffer 与 repl_backlog_buffer 的区别
-
replication buffer:
- 每个从节点都有一个独立的
replication buffer,用于实时传输写命令。其大小是动态调整的。可以通过配置client-output-buffer-limit来控制其大小,以防止缓冲区过大导致的连接问题。
- 每个从节点都有一个独立的
-
repl_backlog_buffer:
repl_backlog_buffer在主节点上是唯一的,主要用于存储最近的写命令,以便从节点在重新连接时能够进行部分重同步。该缓冲区的大小是固定的,主要用于支持增量同步。
通过以上设计,Redis 能够实现高可用性和高性能的数据管理。
当然可以!下面是你要的 Markdown 格式:题目和选项部分在前,所有答案和解析统一放在最后,方便做题和核对。
Redis 主从复制选择题(共 5 题)
1. 在 Redis 主从复制中,如果从节点是第一次连接主节点,或者之前的连接失效,从节点会如何进行同步?
A. 从节点会请求全量复制,主节点将当前数据快照(RDB 文件)发送给从节点
B. 从节点会请求全量复制,主节点将当前内存快照以流的形式发送
C. 从节点会请求主节点的 AOF 日志文件
D. 从节点请求主节点的 replication buffer 中的数据
2. Redis 主从复制中,以下哪个缓冲区是用于存储最近的写命令,并用于从节点重新连接进行部分重同步?
A. replication buffer
B. client-output-buffer-limit
C. repl_backlog_buffer
D. psync命令缓冲区
3. 如何避免 Redis 主从复制中频繁进行全量同步?
A. 增强主节点内存大小
B. 增加从节点数量
C. 增加 repl_backlog_buffer 和 client-output-buffer-limit 的大小
D. 增加主节点 CPU 数量
4. 对于从节点延迟较大的情况,如何控制从节点使用的内存缓冲?
A. 调整主节点的 RDB 文件生成频率
B. 限制从节点的 client-output-buffer-limit
C. 调整 client-output-buffer-limit 控制主节点的 replication buffer 大小
D. 增加网络带宽
5. 当增量同步失败后,为什么 Redis 会选择进行全量同步?
A. repl_backlog_buffer 中的数据已经被覆盖
B. repl_backlog_buffer 中的数据被误删
C. 主节点丢失了队列内的 runid
D. 从节点数据损坏
✅ 答案与解析
1. 正确答案:A
解析:当从节点首次连接或失联重新连接时,主节点会向其发送全量数据快照(RDB 文件)进行同步。
2. 正确答案:C
解析:repl_backlog_buffer 是用于部分同步的缓冲区,记录最近的写命令。
3. 正确答案:C
解析:增加相关 buffer 的大小可以有效避免 offset 被覆盖,从而减少全量同步频率。
4. 正确答案:B
解析:client-output-buffer-limit 控制从节点在主节点上的输出缓存,限制可避免资源过度消耗。
5. 正确答案:A
解析:如果从节点 offset 太旧,而 repl_backlog_buffer 已被覆盖,则只能重新进行全量同步。

![[创业之路-366]:投资尽职调查 - 尽调核心逻辑与核心影响因素:价值、估值、退出、风险、策略](https://i-blog.csdnimg.cn/img_convert/e89b45843e25ffa70c9fc54c3bec98b8.png)