0.前言
起因: 本人深度学习,无奈组内没有好的显卡,只有我自己拥有的一张4060卡跑CV,稍微大一点的模型跑不了,我的模型主打一个轻量化... 在找模型与我的模型进行比较的时候,看的RT-DETR-R18版本(GFLPOS也是相当高...),但是也是一个开源的比较好的模型。但是,官方开源的代码一直跑不了,总是出现各种错误... 而且本人也习惯用ultralytics的模型了,而且我看文件夹里面只有RT-DETR-R50版本,但是参数量太大。但是网上一直没有分享该yaml与该改法,因此有了本文。
当我拿ultralytics公司版本的rt-detr-r50,发现和官方版本的差别很大,但是对比发现,其实官方版本做了封装而已,下面来对比一下
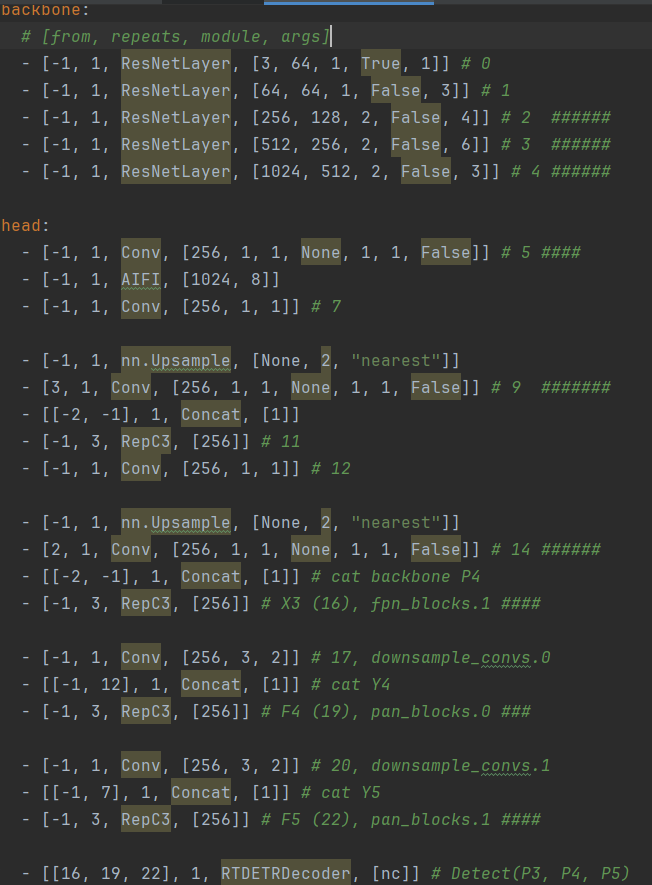
U版本的rt-detr-r50.yaml
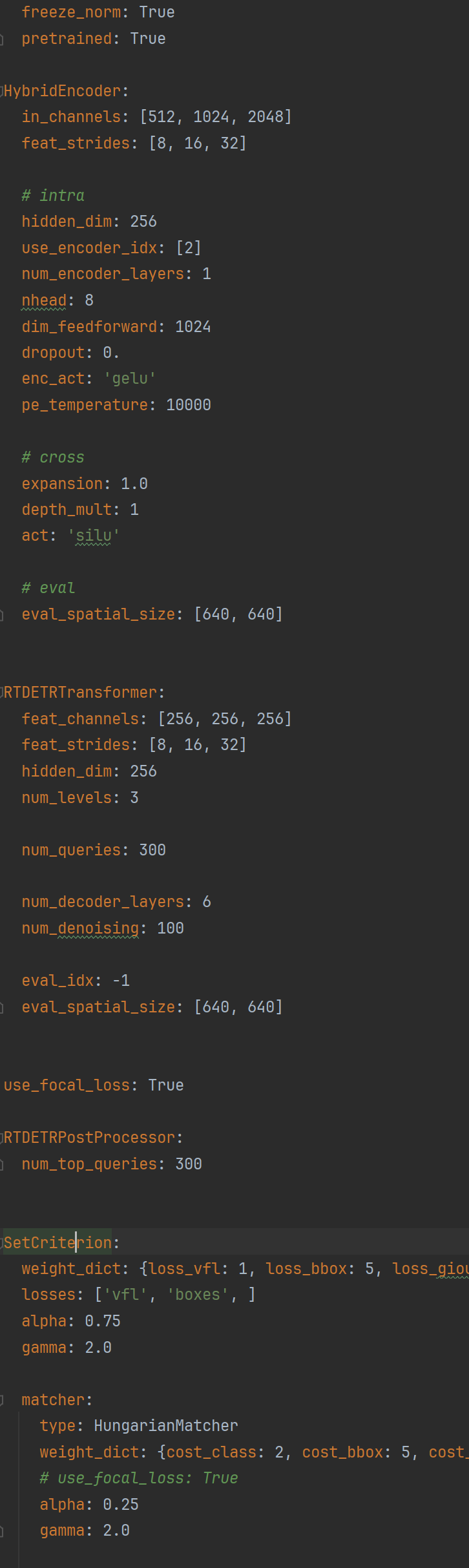
官方版本
对比发现:
1. U版本的检测头是官方的检测头没问题。最主要的还是HybridEncoder,U版本没有进行封装,而是采用习惯的写法(个人还是蛮喜欢的)。
2. 在官方文档r18和r50参数对比中发现,r18的backbone从ResNet50换成了ResNet18,HybridEncoder的参数有些改变,检测头一个参数更改了
3.U版本的RT-DETR其实没有完全按照官方的RT-DETR进行编写,有些函数有些不同... 但总的区别不大。
因此,本文从U版本的rt-detr-r50.yaml的参数开始修改,变成rt-detr-r18。
1.Backbone修改: 从ResNet50变成ResNet18
首先,在U的模块文件中,是没有ResNet18/34的基础块的,有了解的小伙伴就知道ResNet50/101的基础层和ResNet18/34是不同的。因此,我们需要添加ResNet18/34的基础块,这个是通用的,关于ResNet在网上的教程特别多,这里我只贴代码。
class BasicBlock(nn.Module):
"""Basic ResNet block for ResNet18/34"""
expansion = 1 # No expansion in basic blocks
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * self.expansion)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# 命名为了和U版本中的ResNetLayer区分开
class ResNetBasic(nn.Module):
def __init__(self, c1, c2, s=1, is_first=False, n=2, e=1): # 修改默认n=2,e=1
super().__init__()
self.is_first = is_first
if self.is_first:
self.layer = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
else:
blocks = [BasicBlock(c1, c2, s)]
blocks.extend([BasicBlock(c2, c2, 1) for _ in range(n - 1)])
self.layer = nn.Sequential(*blocks)
def forward(self, x):
return self.layer(x)关于该模块怎么用,请搜索yolo8如何添加模块,这个教程十分多且详细~这里就不多赘述
2. HybridEncoder的参数修改:在原yaml文件基础上修改
我们首先来对比,官方版本的rt-detr-r18和rt-detr-r50的HybridEncoder的区别在哪,区别在参数上
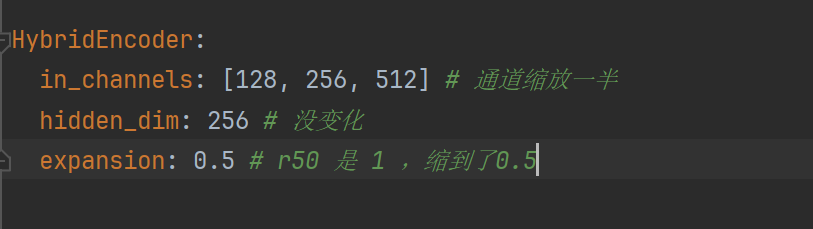
a) 可以看到,in_channels整体缩小了,但是,由于我们的backbone变化了,实际上in_channels是随着Backbone变化而变化了。这一点只需要按照1来操作换掉backbone即可
b) hidden_dim是没有变化的,r50也是256,r18也是256
c)expansion从1变化到了0.5,这个expansion在官方版本是修改CSPRepLayer的参数
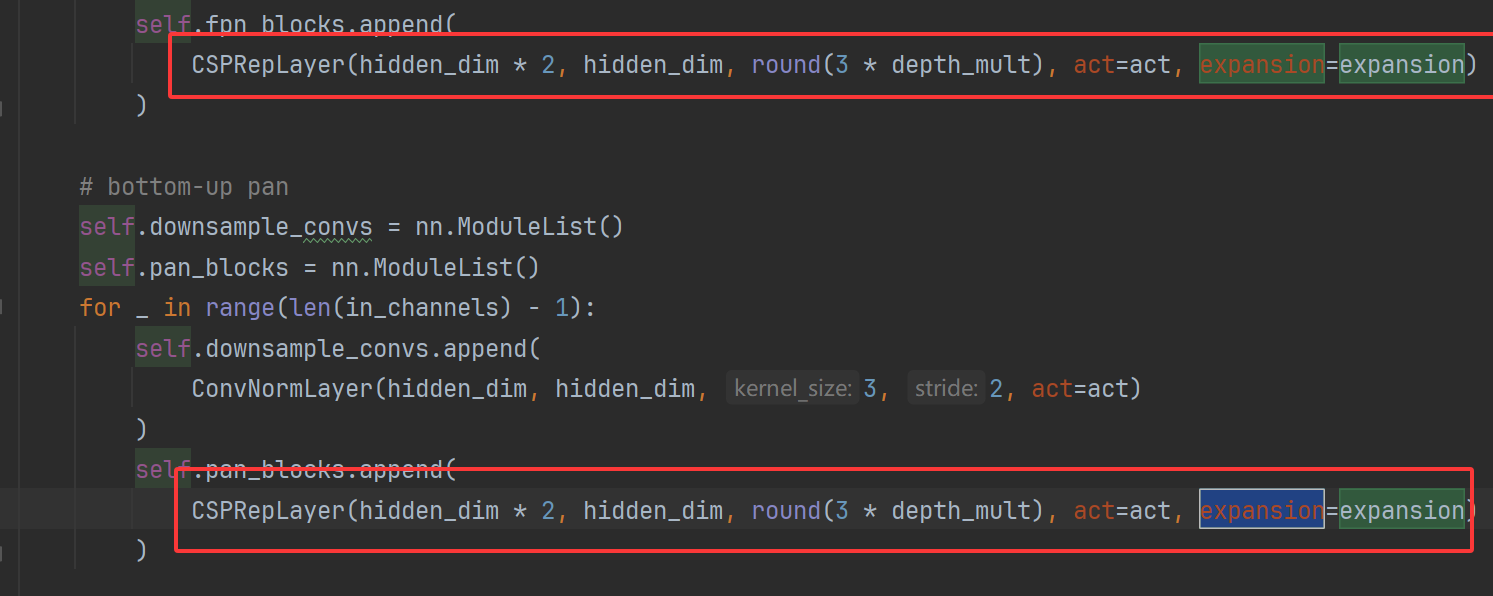
那在U版本中,实际上是RepC3的参数(注意,RepC3和CSPRepLayer实际上是有一些差别的,差别在一些激活的处理... 所以,能用官方的跑就用官方的跑),所以我们只需要修改RepC3中的expansion从1变到0.5即可,这里不用动,知道原理就可以了,yaml修改就行。
3. 检测头的参数修改
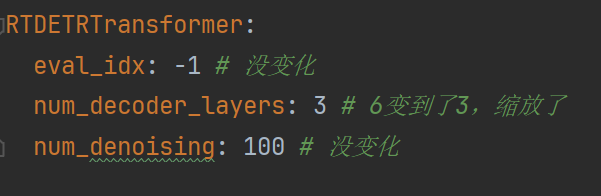
检测头的num_decoder_layers从6变到了3,由于该检测头在U版本的参数十分多,所以我们直接去U版本的检测头函数,修改默认参数从1变到0.5即可
检测头的路径
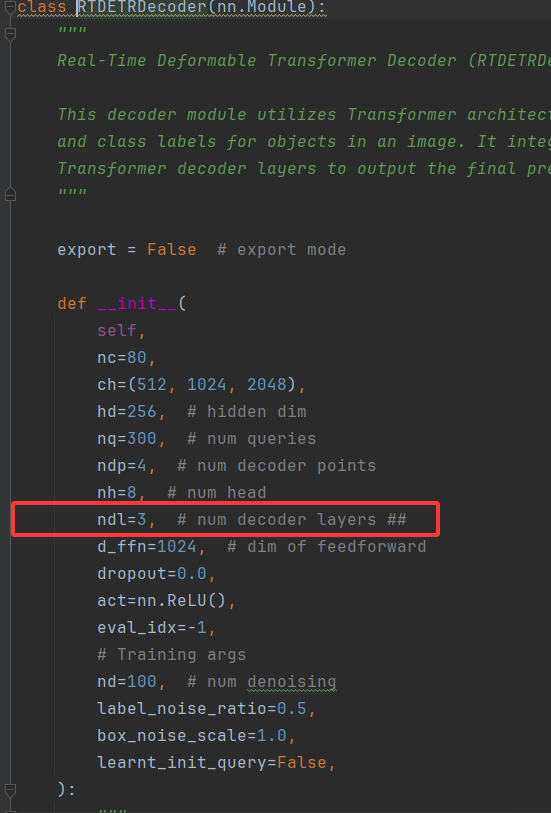
把这里的6改成3即可(图中已经改过了)
4. rt-detr-r18的yaml代码
在做上述修改后,再使用
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-ResNet50 object detection model with P3-P5 outputs.
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ResNetBasic, [3, 64, 2, True, 2]] # Stage 0 (初始conv7x7+maxpool)
- [-1, 1, ResNetBasic, [64, 64, 1, False, 2]] # Stage1 (2个基本块)
- [-1, 1, ResNetBasic, [64, 128, 2, False, 2]] # Stage2 (下采样) ###
- [-1, 1, ResNetBasic, [128, 256, 2, False, 2]] # Stage3 (下采样) ###
- [-1, 1, ResNetBasic, [256, 512, 2, False, 2]] # Stage4 (下采样) ###
head: # hidden dim = 256
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 5 #### input Channel
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 7
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 9 ####### input Channel
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256, 0.5]] # 11
- [-1, 1, Conv, [256, 1, 1]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [2, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 ###### input Channel
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256, 0.5]] # X3 (16), fpn_blocks.1 ####
- [-1, 1, Conv, [256, 3, 2]] # 17, downsample_convs.0
- [[-1, 12], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256, 0.5]] # F4 (19), pan_blocks.0 ###
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.1
- [[-1, 7], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256, 0.5]] # F5 (22), pan_blocks.1 ####
- [[16, 19, 22], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
注意,head层的RepC3参数有所调整,复制即可,根据修改后的rt-detr-r18参数如下
![]()
本人对比了,已有的u版本rt-detr和官方所给的参数,发现都有些差别,所以最好是用官方的rt-detr,如果用不了再用u版本的。
本人代码能力有限,根据官方版本,尽力的还原成原来版本的rt-detr-r18。如果有错误,请大佬们一定及时给我指出来!!希望能帮助到各位小伙伴们~~~