文章目录
- 题目链接:
- 题目描述:
- 解法
- C++ 算法代码:
题目链接:
23. 合并 K 个升序链表
题目描述:

解法
解法一:暴力解法
每个链表的平均长度为n,有k个链表,时间复杂度
O(nk^2)合并两个有序链表
先把其中的两个链表有序合并,然后把合并后的链表和后面一个链表有序合并,每次合并两个直到结束。
解法二:利用优先级队列做优化
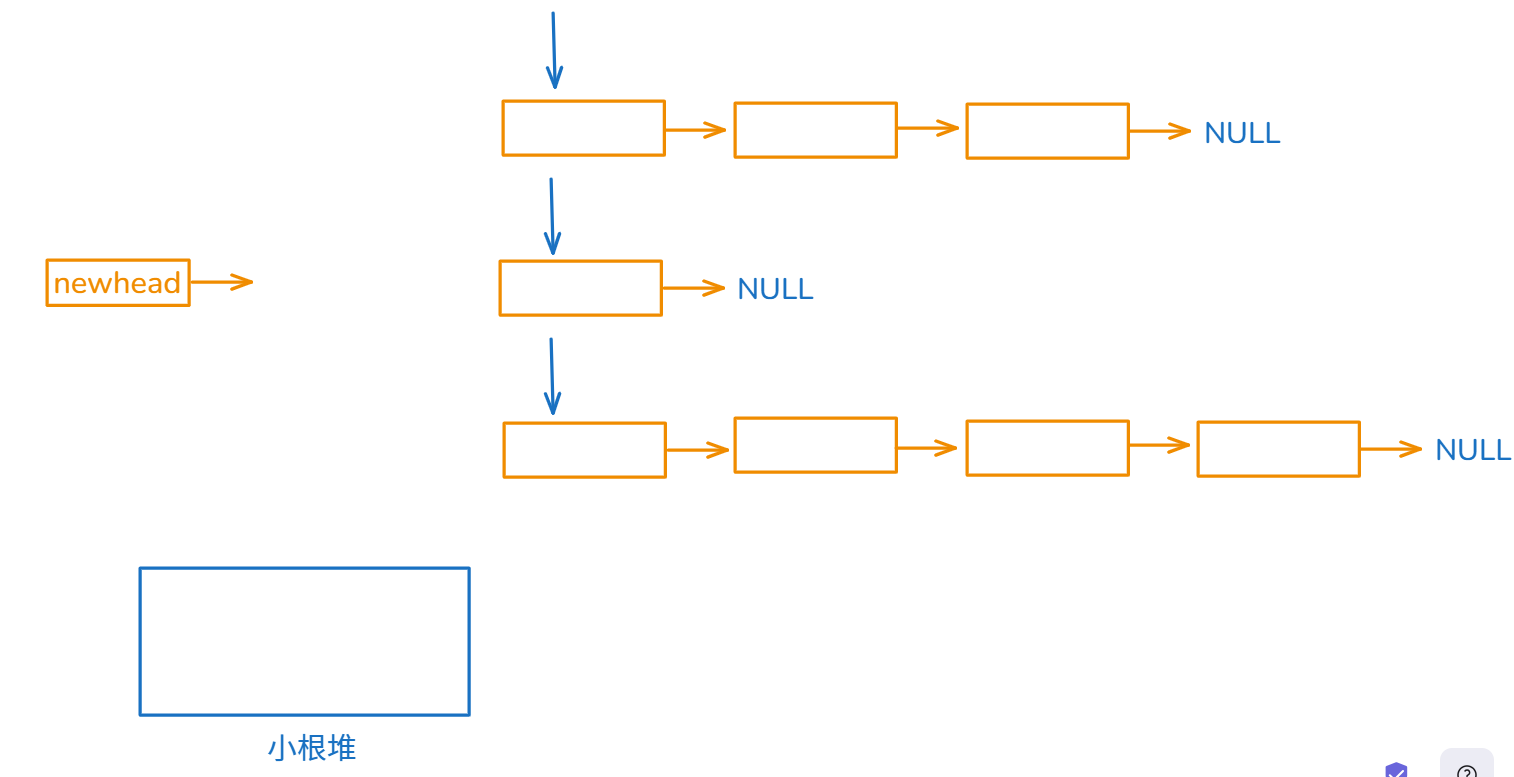
O(n*k*logk)先给
n个链表设置n个指针,然后把每个链表的第一个指针放入小根堆里面,取走堆顶元素放入newhead节点,哪一个链表的指针取走了就让那个链表指针的后一个位置放进小根堆,直到所有链表指针都指向NULL。
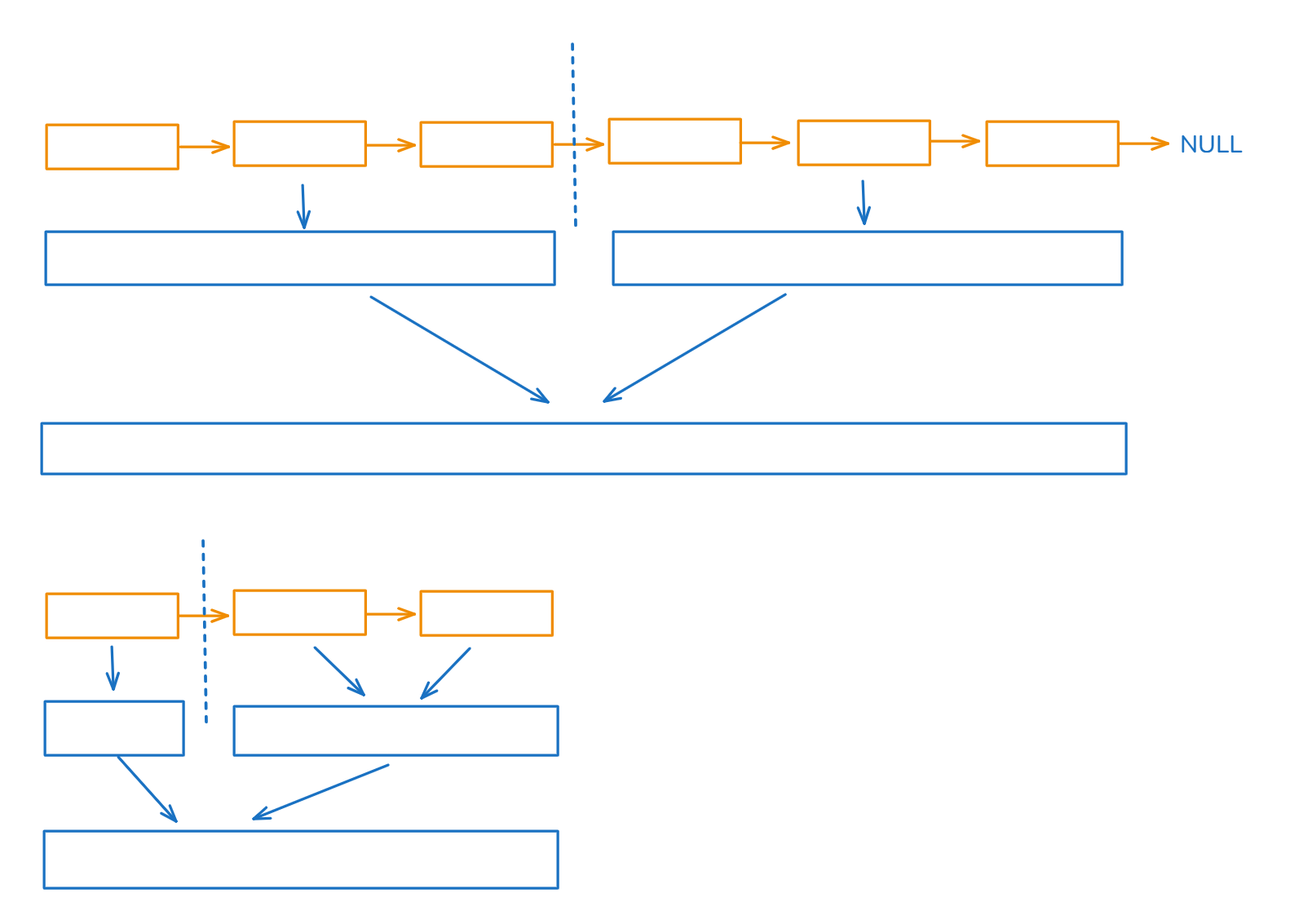
解法三:归并排序,递归
O(n*k*logk)
C++ 算法代码:
解法二(利用堆)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
// 定义比较器结构体,用于小根堆的节点比较
struct cmp
{
// 重载函数调用运算符,定义节点比较规则
// 对于小根堆,我们需要大值返回true(表示优先级低)
bool operator()(const ListNode* l1, const ListNode* l2)
{
return l1->val > l2->val; // 如果l1值大于l2,就向下调整,返回true,实现小根堆
}
};
public:
ListNode* mergeKLists(vector<ListNode*>& lists)
{
// 创建一个小根堆,存储ListNode指针
// 堆会根据节点的val值自动排序,最小的在堆顶
// 第一个参数 ListNode*: 指定了队列中存储的元素类型,这里是链表节点的指针
// 第二个参数 vector<ListNode*>: 指定了底层容器类型,这里使用vector存储ListNode指针
// 第三个参数 cmp: 指定了元素比较的方式,是一个自定义的比较器结构体
priority_queue<ListNode*, vector<ListNode*>, cmp> heap;
// 将所有链表的头节点加入小根堆
// 只有非空链表的头节点才会被加入
// auto l 会依次获取数组中的每个元素,即每个链表的头指针
for(auto l : lists)
if(l) heap.push(l);
// 创建虚拟头节点,简化链表构建过程
ListNode* ret = new ListNode(0);
ListNode* prev = ret; // 使用prev作为结果链表的尾指针
// 不断从堆中取出最小节点,加入结果链表
while(!heap.empty())
{
ListNode* t = heap.top(); // 取出堆顶元素(当前所有节点中值最小的)
heap.pop(); // 移除堆顶元素
prev->next = t; // 将最小节点添加到结果链表
prev = t; // 更新尾指针
// 如果当前取出的节点还有下一个节点,将其加入堆中
if(t->next) heap.push(t->next);
}
// 获取结果链表的头节点(跳过虚拟头节点)
prev = ret->next;
delete ret; // 释放虚拟头节点
return prev; // 返回合并后的链表头
}
};
解法三(递归/分治)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* mergeKLists(vector<ListNode*>& lists)
{
// 主函数入口:调用递归函数处理整个链表数组
return merge(lists, 0, lists.size() - 1);
}
// 分治递归函数:合并区间[left, right]内的链表
ListNode* merge(vector<ListNode*>& lists, int left, int right)
{
// 边界情况:如果left大于right,说明没有链表可合并
if(left > right) return nullptr;
// 边界情况:如果只有一个链表,直接返回
if(left == right) return lists[left];
// 1. 计算中间位置,将链表数组分为两部分
int mid = left + right >> 1; // 等价于 (left + right) / 2
// 2. 递归处理左右两个区间
// 左区间: [left, mid]
ListNode* l1 = merge(lists, left, mid);
// 右区间: [mid + 1, right]
ListNode* l2 = merge(lists, mid + 1, right);
// 3. 合并两个区间返回的链表
return mergeTowList(l1, l2);
}
// 合并两个有序链表
ListNode* mergeTowList(ListNode* l1, ListNode* l2)
{
// 处理边界情况
if(l1 == nullptr) return l2;
if(l2 == nullptr) return l1;
// 创建一个临时头节点,简化合并逻辑
ListNode head;
ListNode* cur1 = l1; // 指向第一个链表的当前节点
ListNode* cur2 = l2; // 指向第二个链表的当前节点
ListNode* prev = &head; // 指向合并结果的尾节点
head.next = nullptr; // 初始化临时头节点
// 合并两个链表,每次取值较小的节点
while(cur1 && cur2)
{
if(cur1->val <= cur2->val)
{
// 第一个链表的当前节点值更小,加入结果
prev = prev->next = cur1;
cur1 = cur1->next;
}
else
{
// 第二个链表的当前节点值更小,加入结果
prev = prev->next = cur2;
cur2 = cur2->next;
}
}
// 处理剩余节点(只需处理一个链表的剩余部分)
if(cur1) prev->next = cur1;
if(cur2) prev->next = cur2;
// 返回合并后的链表头节点
return head.next;
}
};