参考: https://chbxw.blog.csdn.net/article/details/115078261 (datastream 实现)
一、ODS
模拟订单表及订单明细表
CREATE TABLE orders (
order_id STRING,
user_id STRING,
order_time TIMESTAMP(3),
-- 定义事件时间及 Watermark(允许5秒乱序)
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'chb1:9092',
-- 如果source被多个任务使用,不在定义时指定group.id
-- 通过hint指定 OPTIONS('properties.group.id'='test_group2') 注意是group.id 是点不是下划线
-- 'properties.group.id' = 'flink-sql-group-orders', -- 消费者组 ID
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
CREATE TABLE order_details (
detail_id STRING,
order_id STRING,
product_id STRING,
price DECIMAL(10,2),
quantity INT,
detail_time TIMESTAMP(3),
-- 定义事件时间及 Watermark(允许5秒乱序)
WATERMARK FOR detail_time AS detail_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order_details',
'properties.bootstrap.servers' = 'chb1:9092',
-- 'properties.group.id' = 'flink-sql-group-order_details', -- 消费者组 ID
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
-- 造数据
insert into order_details values ('d001', 'o001', 'car', 5000, 1, now());
insert into orders values('o001', 'u001', now());
insert into orders values('o003', 'u003', now());
insert into order_details values ('d003', 'o003', 'water', 2, 12, now());
insert into order_details values ('d003', 'o003', 'food', 50, 3, now());
二、DWD 订单和订单明细关联
-- sink
CREATE TABLE dwd_trd_order (
detail_id STRING,
order_id STRING,
product_id STRING,
price DECIMAL(10,2),
quantity INT,
detail_time TIMESTAMP(3),
user_id STRING,
order_time TIMESTAMP(3),
-- 定义事件时间及 Watermark(允许5秒乱序)
WATERMARK FOR detail_time AS detail_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'dwd_trd_order',
'properties.bootstrap.servers' = 'chb1:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
insert into dwd_trd_order
SELECT
d.detail_id,
o.order_id,
d.product_id,
d.price,
d.quantity,
d.detail_time,
user_id,
order_time
FROM orders o
JOIN order_details d
ON o.order_id = d.order_id
AND d.detail_time BETWEEN o.order_time AND o.order_time + INTERVAL '10' MINUTE;
报错:
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: The query contains more than one rowtime attribute column [detail_time, order_time] for writing into table 'default_catalog.default_database.dwd_trd_order'.
Please select the column that should be used as the event-time timestamp for the table sink by casting all other columns to regular TIMESTAMP or TIMESTAMP_LTZ.
在 Flink SQL 中,每个表只能有一个 行时间属性(rowtime attribute) 用于定义事件时间(Event Time)。当写入目标表时,若查询结果包含多个行时间属性字段(如 order_time 和 detail_time),会导致冲突。以下是解决方案:
1. 问题定位
错误信息表明目标表 dwd_trd_order 在写入时检测到多个行时间属性字段(detail_time 和 order_time)。
根本原因是:JOIN 后的结果保留了双表的事件时间字段,且未被转换为普通时间戳。
2. 解决方案
方案一:仅保留一个行时间属性
在查询中选择一个时间字段作为事件时间,将其他时间字段转为普通 TIMESTAMP 类型。
假设目标表 dwd_trd_order 使用 order_time 作为事件时间:
INSERT INTO dwd_trd_order
SELECT
o.order_id,
o.user_id,
d.product_id,
d.price,
d.quantity,
o.order_time, -- 保留为行时间属性(需与目标表定义一致)
CAST(d.detail_time AS TIMESTAMP(3)) AS detail_time -- 转为普通时间戳
FROM orders o
JOIN order_details d ON o.order_id = d.order_id;
方案二:调整目标表定义
若业务需要同时保留两个时间字段,需在目标表 DDL 中 仅定义一个行时间属性,其他字段转为普通时间戳:
CREATE TABLE dwd_trd_order (
order_id STRING,
user_id STRING,
product_id STRING,
price DECIMAL(10,2),
quantity INT,
order_time TIMESTAMP(3), -- 行时间属性
detail_time TIMESTAMP(3), -- 普通时间戳
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND -- 仅一个事件时间
) WITH (...);
3. 关键步骤说明
-
检查目标表 DDL:
确保目标表仅有一个WATERMARK定义,且对应字段为行时间属性。 -
转换多余的行时间属性:
在查询中使用CAST将非主时间字段转为普通TIMESTAMP或TIMESTAMP_LTZ:CAST(detail_time AS TIMESTAMP(3)) -- 转为非行时间属性 -
验证查询结果:
使用DESCRIBE确认查询结果的字段类型:DESCRIBE (SELECT ... FROM ...);
目标表 DDL(仅一个行时间属性)
CREATE TABLE dwd_trd_order (
order_id STRING,
user_id STRING,
product_id STRING,
price DECIMAL(10,2),
quantity INT,
order_time TIMESTAMP(3), -- 行时间属性
detail_time TIMESTAMP(3), -- 普通时间戳
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);
写入数据的 SQL(转换多余时间字段)
INSERT INTO dwd_trd_order
SELECT
o.order_id,
o.user_id,
d.product_id,
d.price,
d.quantity,
o.order_time, -- 保留为行时间属性
CAST(d.detail_time AS TIMESTAMP(3)) AS detail_time -- 转为普通时间戳
FROM orders o
JOIN order_details d ON o.order_id = d.order_id;
三、DWS
CREATE TABLE dws_trd_order (
window_start TIMESTAMP(3),
window_end TIMESTAMP(3),
product_num bigint,
uv bigint,
total_amount DECIMAL(10,2)
) WITH (
'connector' = 'kafka',
'topic' = 'dws_trd_order',
'properties.bootstrap.servers' = 'chb1:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
-- dws
insert into dws_trd_order
SELECT
window_start, window_end,
COUNT(1) AS product_num,
COUNT(DISTINCT user_id) AS uv,
SUM(price * quantity) AS total_amount
FROM TABLE(
CUMULATE(TABLE dwd_trd_order, DESCRIPTOR(detail_time), INTERVAL '5' SECOND, INTERVAL '1' DAY)
)
GROUP BY window_start, window_end;
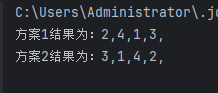
有个问题: 为什么窗口结束时间从 2025-04-02 20:48:50.000 开始???
dwd_trd_order 表的时间如下
order_time detail_time
2025-04-02 20:06:01.281 2025-04-02 20:07:35.494
2025-04-02 20:50:27.975 2025-04-02 20:50:33.233
2025-04-02 20:50:27.975 2025-04-02 20:50:34.405
累计窗口运算如下
select
window_start, window_end,
count(1) product_num,
count(distinct user_id) uv,
sum(price*quantity) as total_amount
from TABLE(
CUMULATE(TABLE dwd_trd_order, DESCRIPTOR(detail_time ), INTERVAL '5' SECOND, INTERVAL '1' DAY)
)
group by window_start,window_end;
为什么窗口结束时间从 2025-04-02 20:48:50.000 开始???
window_start window_end product_num uv total_amount
2025-04-02 00:00:00.000 2025-04-02 20:48:50.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:48:55.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:00.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:05.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:10.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:15.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:20.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:25.000 1 1 5000.00
2025-04-02 00:00:00.000 2025-04-02 20:49:30.000