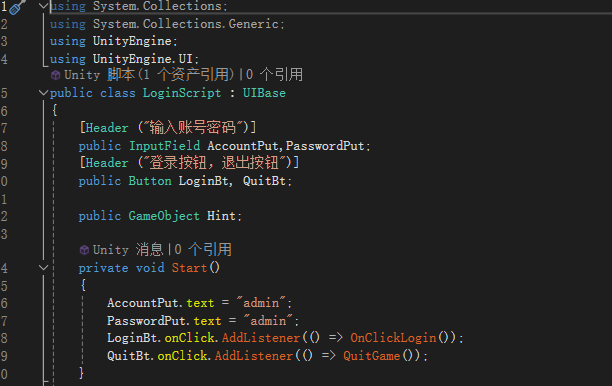
由于硬件只有两张4090卡,但是领导还想要满血版32b的性能,那就只能部署GGUF版。据说QwQ-32B比Deepseek-R1-32b要更牛逼一些,所以就选择部署QwQ-32B-GGUF,根据最终的测试--针对长文本(3-5M大小)的理解,QwQ-32B-GGUF确实要比Deepseek-R1-32b-GGUF好一些。
这里说一下QwQ-32B-GGUF与原版QwQ-32B的区别:
1. 文件格式与存储优化
-
QwQ-32B 是阿里官方发布的原始模型,通常以 PyTorch 权重文件(如
.bin或.safetensors)形式存储,需依赖深度学习框架(如 Hugging Face Transformers)加载 。 -
QwQ-32B-GGUF 是 QwQ-32B 经过 GGUF 格式转换后的版本,采用二进制存储,优化了数据结构与内存映射(mmap),显著提升加载速度和内存效率,特别适合本地部署
-
优势:
-
单文件部署,无需额外依赖库;
-
支持量化(如 4-bit Q4_K_M),显存需求低至 8GB;
-
通过 llama.cpp 或 Ollama 直接运行,无需复杂配置。
-
-
2. 部署场景与硬件要求
-
QwQ-32B
-
适用场景:研究级开发、全精度推理、微调训练;
-
硬件要求:需较高显存的 GPU(如 24GB 显存的 RTX 3090/4090)或云端算力;
-
部署方式:通过 Transformers 库或 vLLM 框架启动服务 。
-
-
QwQ-32B-GGUF
-
适用场景:消费级硬件本地部署、边缘计算、低资源推理;
-
硬件要求:支持量化后单卡(如 RTX 3060)甚至 CPU 运行;
-
部署方式:通过 llama.cpp、LM Studio 或 Ollama 一键启动,适合无编程经验的用户 。
-
3. 性能与功能差异
-
推理速度 GGUF 版本因内存映射和量化技术,推理速度更快(30-40 tokens/秒),而原版在全精度下延迟较高 。
-
功能完整性
-
原版 QwQ-32B 支持完整微调和工具集成(如代码执行、Agent 能力);
-
GGUF 版本因格式限制,通常仅支持推理任务,无法直接微调。
-
-
量化灵活性 GGUF 提供多级量化(如 2-bit/4-bit/8-bit),用户可平衡速度与精度;原版需自行实现量化 。
--------------------------------------------------------------------------------------------------------------------------------
以上内容是来自deepseek的回答,下面进入主题如何基于两张4090部署QwQ-32B-GGUF。
一、下载模型
1、下载目录
GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/QwQ-32B-GGUF.gitGIT_LFS_SKIP_SMUDGE=1 这是环境变量设置,用于指示 Git LFS 跳过自动下载大文件(即“smudge”阶段)。此时大文件会被替换为轻量级指针文件(约 1KB),而非实际内容。因为该地址下有很多量化的版本。
2、下载指定文件
nohup git lfs pull --include="qwq-32b-q8_*" > lfs_pull.log 2>&1 &下载q8_0量化版本,并设置后台下载
3、合并模型文件
下载完之后,发现是由多个文件分片组成的,需要合并为一个文件,可使用如下命令:
./llama-gguf-split --merge qwq-32b-q8_0-00001-of-00009.gguf qwq-32b-q8_0.gguf这里使用的官方推荐的llama-gguf-split命令进行合并,只需指定第一个分片即可。
二、启动模型
经过各种参数调试,最终使用如下命令,上传并理解5M左右的长文本,不会包显存溢出异常
numactl --cpunodebind=0 --membind=0 ./bin/llama-server -m /data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf --ctx-size 16000 --n-gpu-layers 99 --tensor-split 24,24 --batch-size 128 --no-mmap --mlock --parallel 1 --host 0.0.0.0 --port 8000 --temp 0.3 --top-k 38 --repeat-penalty 1.2 --mirostat 2 --mirostat-lr 0.1 --flash-attn 以下是该命令中关键参数的详细解析,结合 NUMA 绑定、大模型推理优化及服务器配置三方面进行说明:
一、NUMA 绑定优化
-
numactl --cpunodebind=0 --membind=0-
作用:将进程的 CPU 和内存绑定到 NUMA 节点 0,避免跨节点访问内存导致的延迟。
-
适用场景:多核服务器中,若模型推理对内存带宽敏感(如大模型),绑定到同一 NUMA 节点可提升性能 10%~30%。
-
二、模型加载与GPU卸载
-
-m /data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf-
作用:指定 GGUF 格式的量化模型路径。
q8_0表示 8 位整数量化,平衡精度与显存占用。
-
-
--n-gpu-layers 99-
作用:将模型的前 99 层卸载到 GPU 计算,剩余层使用 CPU 推理。数值越大,GPU 显存占用越高。
-
-
--tensor-split 24,24-
作用:在多 GPU 环境下按比例分配张量。此处表示两块 GPU 各分配 24GB 显存。
-
三、内存与性能优化
-
--ctx-size 16000-
作用:设置上下文窗口大小为 16000 tokens。适用于长文本推理,但需更多显存(每 1000 tokens 约需 1GB)。
-
-
--batch-size 128-
作用:批量处理 128 个 tokens,提升吞吐量。过大可能导致 OOM,需根据显存调整。
-
-
--no-mmap --mlock-
作用:禁用内存映射,强制锁定模型到物理内存,避免换出到磁盘。
-
四、服务器与推理参数
-
--host 0.0.0.0 --port 8000-
作用:监听所有 IP 的 8000 端口,允许外部访问服务。
-
-
--temp 0.3 --top-k 38-
作用:
-
--temp 0.3:降低生成随机性(值越小越确定,如问答任务); -
--top-k 38:仅从概率最高的 38 个候选词中采样,避免低质量输出。
-
-
-
--mirostat 2 --mirostat-lr 0.1-
作用:启用 Mirostat 2.0 算法,动态调整生成多样性,
lr为学习率,控制调整幅度。
-
-
--flash-attn-
作用:启用 Flash Attention 优化,加速注意力计算,降低显存占用 20%~40%。
-
三、调用
1、非流式调用
curl -X POST "http://192.168.1.50:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "中国的首都是哪里?"}
],
"model": "/data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf",
"temperature": 0.7
}' 2、流式调用
curl -X POST "http://192.168.1.50:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"stream": true,
"messages": [
{"role": "user", "content": "中国的首都是哪里?"}
],
"model": "/data/servers/QwQ-32B-GGUF/qwq-32b-q8_0.gguf",
"temperature": 0.7
}'OK,大功告成!