利用bbbrisk一步一步实现评分卡
- 一、什么是评分卡
- 1.1.什么是评分卡
- 1.2.评分卡有哪些
- 二、评分卡怎么弄出来的
- 2.1.如何制作评分卡
- 2.2.制作评分卡的流程
- 三、变量的分箱
- 3.1.数据介绍
- 3.2.变量自动分箱
- 3.3.变量的筛选
- 四、构建评分卡
- 4.1.评分卡实现代码
- 4.2.评分卡表
- 4.3.阈值表与分数分布图
一、什么是评分卡
1.1.什么是评分卡
评分卡,一般是指用于小贷客户质量评分的评分卡表。
评分卡样式如下:
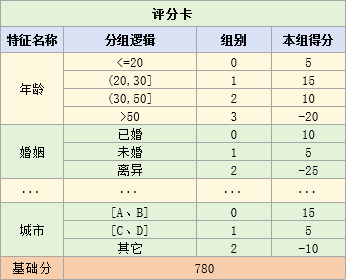
来了一个新客户,先根据客户的数据,判断客户在各个特征上属于哪一组
然后在评分卡表中找到对应的分数,对所有特征得分求和,并加上基本分,就是客户的总评分
假设客户在rev、due30、due90、city上的组别为【0、3、1、1】
那么客户在rev、due30、due90、city上的得分为【28、-30、-20、5】
则客户的总得分为28-30-20+5+780=763
1.2.评分卡有哪些
针对评分的使用不同场景,一般分为A、B、C、F卡
- A卡:Application scorecard,申请评分卡
A卡用申请数据,建立模型,评估用户是否会坏账
作用:用于审批放款 - B卡:Behavior scorecard,行为评分卡
C卡作用于借贷中的客户。加入贷后还款等行为数据
多种作用:可用于老客户提额 - C卡:Collection scorecard,催收评分卡
作用于借贷中的客户
作用:预测用户是否会逾期,提前催收 - F卡:(Fraud scorecard):欺诈评级评分卡
作用于申请阶段,针对欺诈客户的判断
二、评分卡怎么弄出来的
2.1.如何制作评分卡
评分卡建模的思路与流程如下: 先在原始数据中,衍生并选择出建模的变量, 然后用建模变量与好坏客户标签建立逻辑回归模型。这样就能通过建模变量预测样本是坏客户的概率,最后,把逻辑回归模型的线性部分抽取出来,生成评分卡。
最后的最后,还需要分析当前业务应以哪个分数作为拒绝客户的临界值,以临界值作为评分阈值。
2.2.制作评分卡的流程
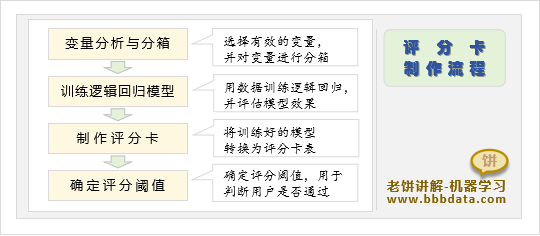
- 建模数据准备
数据准备主要是建模之前,对原始数据进行分箱与变量分析
筛选出与客户质量相关的变量,作为建模的输入特征 - 建模
(1)数据预处理:归一化,并预留测试数据
(2)用逐步回归选出尽量少的特征(同时保持建模效果)
(3)训练逻辑回归模型
(4)检验AUC是否达标,并检查系数是否都为正 - 制作评分卡
制作评分卡也俗称“模型转评分”
将3中得到的逻辑回归模型,制作成评分卡表 - 确定评分阈值
确定生产上判定为坏客户的分数阈值
当分数低于该阈值时,就拒绝客户
三、变量的分箱
在构建评分卡之前,需要先对变量进行分析与分箱,并选择出有效的变量作为建模变量。
3.1.数据介绍
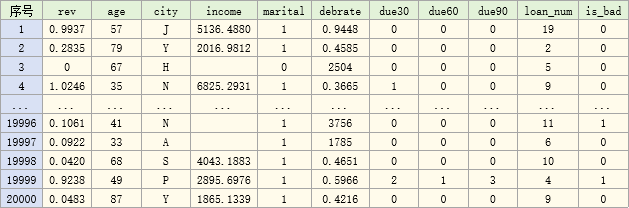
bbbrisk自带的小贷数据共包含10个变量与客户好坏标签,数据包含的10变量和标签如下:

数据共2万条,示例如下:
3.2.变量自动分箱
变量的分箱可以使用算法进行自动分箱,常用的分箱算法有:等频分箱、等距分箱、决策树分箱、KS分箱和卡方分箱等等。
bbbrisk包提供了bins.autoBin函数来对多个变量进行自动分箱,具体代码如下:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 自动分箱
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱,如果有枚举变量,必须指出哪些是枚举变量
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 统计各个变量的分箱情况
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
for var in bin_stats: # 逐个变量打印分箱结果
print('\n变量'+var+'的分箱结果:\n',bin_stats[var]) # 打印当前变量的分箱统计结果
# 选择iv足够大的变量
select_bin_set = {} # 初始化选择的变量的分箱
for var,stat in bin_stats.items(): # 逐个变量循环
if (stat['iv'].iloc[-1]>0.1): # 当前变量的iv值是否满足要求
select_bin_set[var] = bin_sets[var] # 如果满足,则添加到选择池
print('\n iv > 0.1 的变量与分箱结果:\n',select_bin_set) # 最终选择的变量的分箱
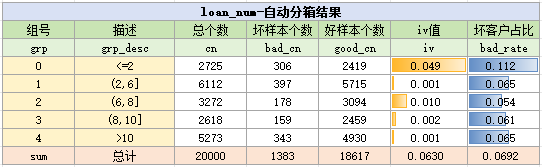
通过以上的代码,就对变量进行分箱了,它的结果如下:
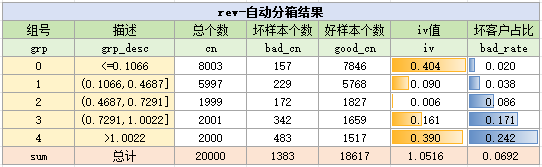
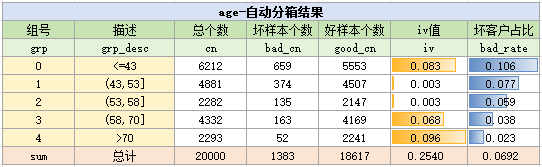
…
3.3.变量的筛选
一般来说,需要通过iv值来筛选出有效的变量。
IV全称为信息价值(Information Value),它常在评分卡中用于筛选变量。IV的原理是通过评估好、坏样本在变量分布上的差异,从而评估变量对y的信息价值。
IV值越高,变量的价值越高,一般来说,IV值与变量对好坏客户的区分度的关系如下:
IV < 0.02 :几乎没有区分度,
0.02 <= IV < 0.1 :有微弱的区分度;
0.1 <= IV < 0.3 :有明显的区分度;
0.3 <= IV :较强的区分度
通考上述的值,来筛选出有效的变量。在本例中,所有变量都是有效的。
四、构建评分卡
在完成变量分箱后,就可以直接使用bbbrisk的评分卡包来构建评分卡,以及打印相关报告
如果没有bbbrisk的包,需要先通过pip安装
pip install bbbrisk
4.1.评分卡实现代码
用bbbrisk构建评分卡的具体代码如下:
import bbbrisk as br
#加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 构建评分卡
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱,必须指出哪些是枚举变量
model,card = br.model.scoreCard(x,y,bin_sets) # 构建评分卡
score = card.predict(x[card.var]) # 用评分卡进行评分
# 打印结果
print('\n-----【 模型性能评估 】----')
print('* 模型训练AUC:',model.train_auc) # 打印模型训练数据集的AUC
print('* 模型测试AUC:',model.test_auc) # 打印模型测试数据集的AUC
print('* 模型训练KS:',model.train_ks) # 打印模型训练数据集的KS
print('* 模型测试KS:',model.test_ks) # 打印模型测试数据集的KS
print('\n--------【 模型 】---------')
print('* 模型使用的变量:',model.var) # 模型最终使用的变量
print('* 模型权重:',model.w) # 模型的变量权重
print('* 模型阈值:',model.b) # 模型的阈值
print('\n--------【 评分卡 】---------')
print('\n* 特征得分featureScore: \n' ,card.featureScore ) # 特征得分
print('\n* 基础得分baseScore: ' ,card.baseScore ) # 基础分
运行结果如下:
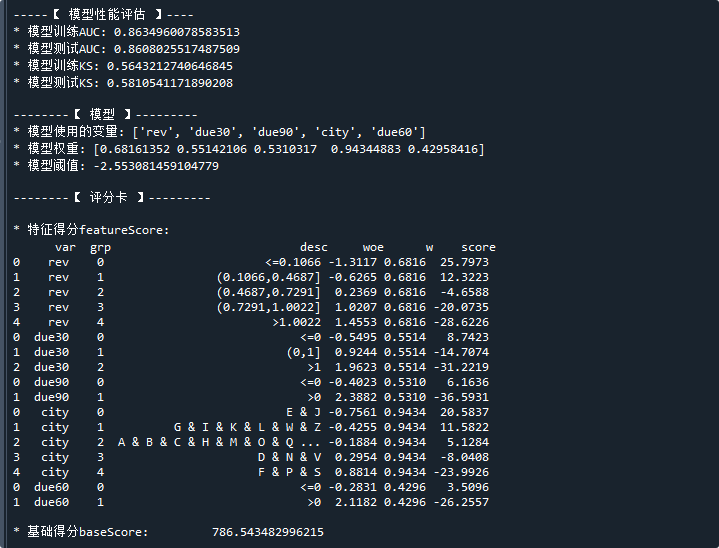
可以看到,通过简单的代码,就可以得到评分卡模型的AUC/KS,以及模型的参数、评分卡表。
4.2.评分卡表
card.featureScore和card.baseScore里分别存放了特征得分与基础,两者合并后就是最终的评分卡表,如下:
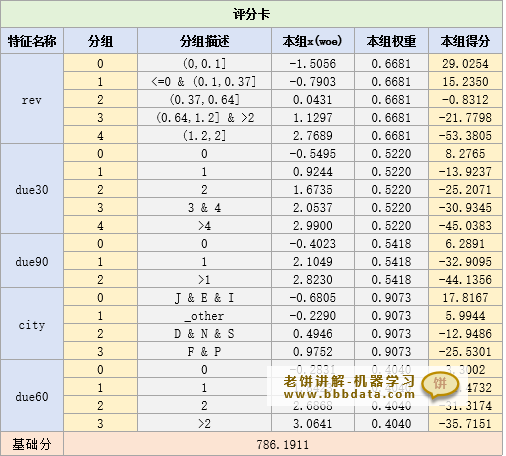
4.3.阈值表与分数分布图
阈值表与分数分布图,可以进一步使用report.get_threshold_tb来计算阈值表,以及用report.draw_score_disb则用于绘制分数分布图。代码如下:
# 计算阈值表与分数分布图
thd_tb = br.report.get_threshold_tb(score,y,bin_step=10) # 阈值表
br.report.draw_score_disb(score,y,bin_step=10,figsize=(14, 4)) # 分数分布
评分阈值表的结果如下:

样本的分数分布结果如下:
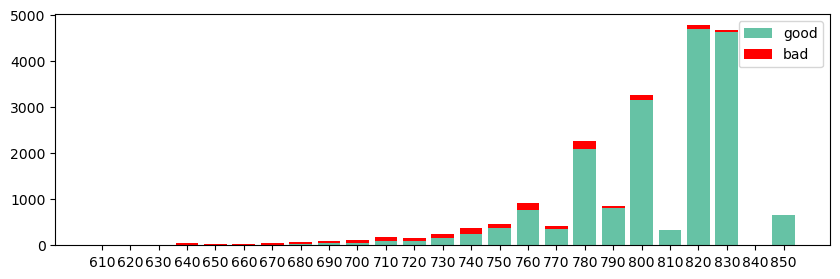
好了,以上就是如何制作一个评分卡了。
更多可以参考:
【1】老饼讲解-评分卡
【2】bbbrisk评分卡API说明