《动手学深度学习》-4.5-笔记
权重衰减就像给模型“勒紧裤腰带”,不让它太贪心、不让它学太多。
你在学英语单词,别背太多冷门单词,只背常见的就行,这样考试时更容易拿分。”
—— 这其实就是在“限制你学的内容复杂度”。
在训练一个模型的时候,也要防止它“死记硬背”训练集的数据。
权重衰减就是给模型一个规则: “你可以学,但不能太激进,尽量简单点!”
因为模型在训练的时候可能会过拟合,就是它把训练数据背得滚瓜烂熟,但换一套题就不会了。
权重衰减就像提醒它:“你不能只靠死记硬背,要理解和归纳。”
权重衰减是一种正则化方法,用于防止模型过拟合。它的核心思想是:在训练模型时,对模型的权重(参数)进行约束,让权重的值不要变得太大。具体来说,就是在损失函数中加入一个额外的惩罚项,这个惩罚项与权重的大小有关。
将原来的训练目标(最小化训练标签上的预测损失)调整为:最小化预测损失 + 惩罚项
即:原本模型只关心“预测对不对”,现在还要关心“学得是不是太复杂”。
那什么是“权重”呢?
“权重”就是模型中学到的参数,相当于它的“记忆”或“经验”。
-
没有衰减:模型会很用力去记住训练数据,容易“死记硬背”。
-
有衰减:模型会被“约束”,学得更稳,考试(预测新数据)更容易拿分。
-
权重衰减 = 不让模型的“记忆力”太强,逼它学得简单一点,防止它考试(泛化)翻车。
权重(weight) 模型的记忆 衰减(decay) 给它一点压力,让它别太极端 权重衰减 限制模型学得太多,防止过拟合
假设原本的损失函数是:Loss=预测误差
加了权重衰减以后变成:
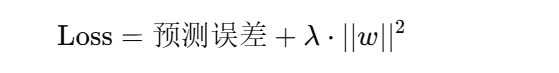
-
w:模型的权重
-
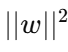 :所有权重平方加起来(L2 范数)
:所有权重平方加起来(L2 范数) -
λ:惩罚项的强度(可以调节)
# 定义训练集和测试集的大小,以及输入特征数量和批量大小
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
# n_train:训练样本数量为 20
# n_test:测试样本数量为 100
# num_inputs:每个样本有 200 个特征(就是输入维度)
# batch_size:每次训练时喂给模型 5 个样本(小批量训练)
# 生成“真实的”权重和偏置,用于生成数据时使用
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
# true_w:一个 shape 为 (200, 1) 的向量,每个元素是 0.01
# true_b:偏置是 0.05
# 这两个值是我们“人为设定”的,用来生成“假的数据”(方便我们验证模型能不能学出来)
# 生成训练数据(特征 + 标签),使用上面设定的权重和偏置
train_data = d2l.synthetic_data(true_w, true_b, n_train)
# synthetic_data:是 d2l 提供的函数,用来生成 y = Xw + b + 噪声 的假数据
# train_data 是一个二元组:(features, labels),大小是 (20, 200) 和 (20, 1)
# 把训练数据放进“迭代器”,每次取 batch_size 个样本
train_iter = d2l.load_array(train_data, batch_size)
# load_array:把数据打包成 PyTorch 可用的 DataLoader,支持按批次取数据
# 同样的方法,生成测试数据
test_data = d2l.synthetic_data(true_w, true_b, n_test)
# 测试数据有 100 个样本
# 把测试数据放进测试用的迭代器中(is_train=False 表示测试模式)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
下面我们将从头开始实现权重衰减,只需将L2的平方惩罚添加到原始目标函数中。
首先,随机初始化模型参数,从正态分布中随机生成数据,模拟“随机初始化权重”。
def init_params():
# 初始化权重 w,形状为 (特征数 num_inputs, 1)
# 从均值为0,标准差为1的正态分布中随机生成
# requires_grad=True 表示这个参数需要计算梯度(用于训练)
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
# 初始化偏置 b,初始为0,且也需要计算梯度
b = torch.zeros(1, requires_grad=True)
# 返回这两个参数,供模型使用
return [w, b]
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。(核心)
def l2_penalty(w):
# 计算权重 w 的 L2 范数平方,并除以 2
# 这是 L2 正则化中常用的形式
return torch.sum(w.pow(2)) / 2
L2 正则化项的数学形式是: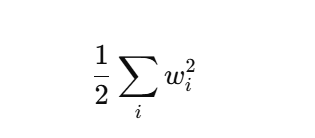
def train(lambd):
# 初始化模型参数 w 和 b(包含梯度信息)
w, b = init_params()
# 定义模型 net(就是线性回归函数)和损失函数(平方损失)
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
# 设置训练轮数和学习率
num_epochs, lr = 100, 0.003
# 动画器,用来实时画出训练/测试集的损失变化(log坐标轴)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
# 开始训练模型
for epoch in range(num_epochs):
for X, y in train_iter: # 遍历一个个 batch
# 计算损失:平方损失 + L2惩罚项(权重衰减)
# l2_penalty(w) 是一个数,广播后加到每个样本的损失上
l = loss(net(X), y) + lambd * l2_penalty(w)
# 反向传播,计算梯度
l.sum().backward()
# 使用随机梯度下降法更新参数 w 和 b
d2l.sgd([w, b], lr, batch_size)
# 每训练5轮画一次图
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (
d2l.evaluate_loss(net, train_iter, loss), # 训练集损失
d2l.evaluate_loss(net, test_iter, loss) # 测试集损失
))
# 最后输出训练好的权重向量的 L2 范数
print('w 的 L2 范数是:', torch.norm(w).item())
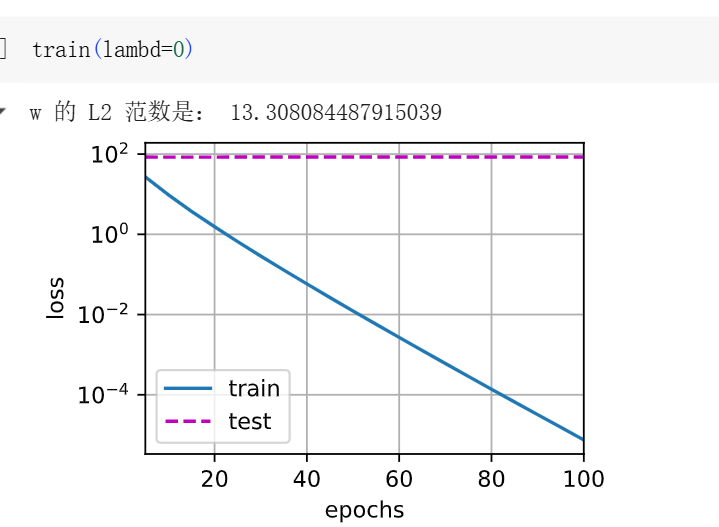
忽略正则化直接训练,“不使用正则化(也就是不加权重惩罚项),进行模型训练。”
def train(lambd):
...
l = loss(...) + lambd * l2_penalty(w)
里面这个 lambd * l2_penalty(w) 是控制“正则化强度”的。
打印
| 正则化情况 | 影响 |
|---|---|
lambd = 0 | 没有权重惩罚,模型容易过拟合 |
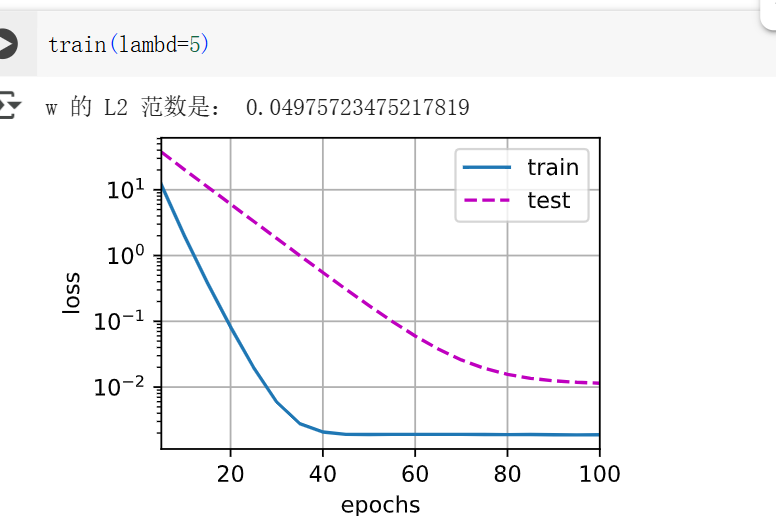
lambd > 0 | 会限制权重变大,提升泛化能力(防止过拟合) |
简单实现:
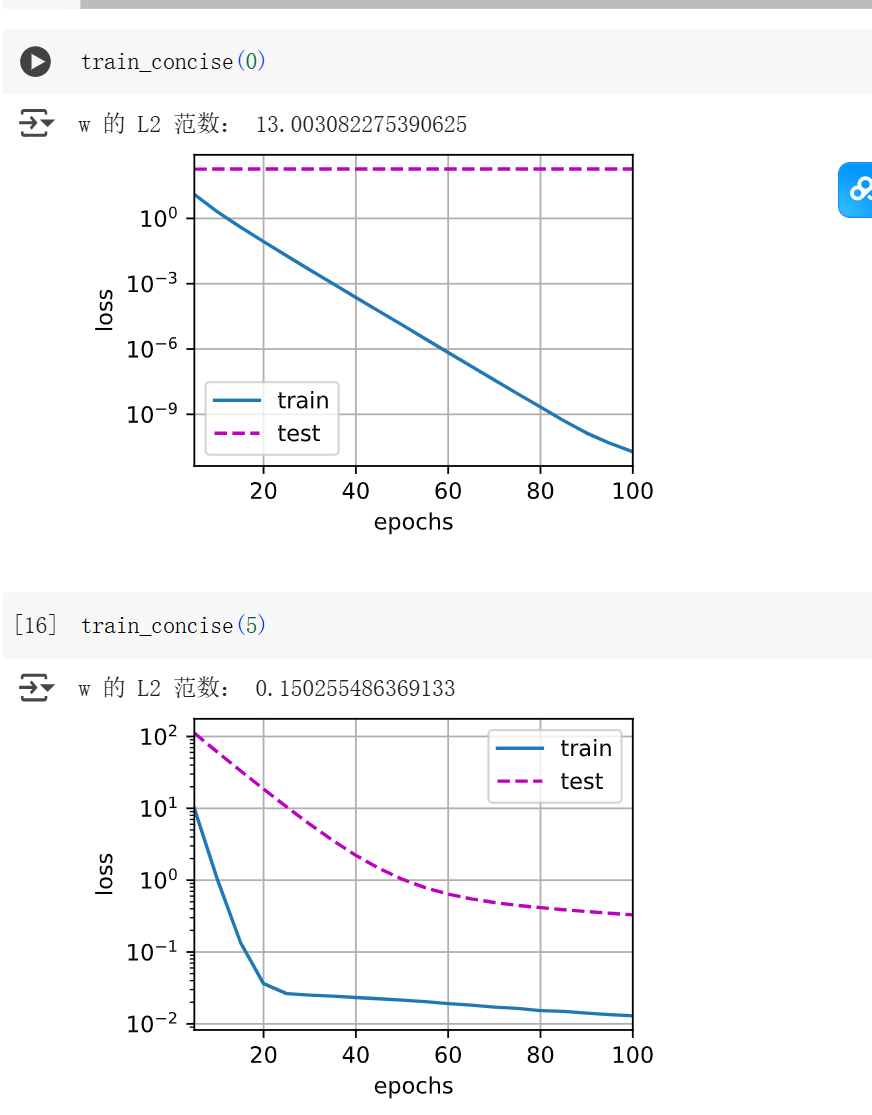
def train_concise(wd): # wd 就是 weight decay 权重衰减系数(λ)
# 定义一个线性回归模型:输入是 num_inputs 维,输出是 1 维
net = nn.Sequential(nn.Linear(num_inputs, 1))
# 初始化模型参数为服从正态分布(均值0,标准差1)
for param in net.parameters():
param.data.normal_()
# 定义损失函数为 MSE(均方误差),每个样本独立输出,不求平均
loss = nn.MSELoss(reduction='none')
# 设置训练轮数和学习率
num_epochs, lr = 100, 0.003
# 定义优化器:使用 SGD(随机梯度下降)
# 注意:只有权重使用 weight_decay,偏置 bias 不加惩罚项
trainer = torch.optim.SGD([
{"params": net[0].weight, "weight_decay": wd}, # 对 weight 使用正则化
{"params": net[0].bias} # 对 bias 不使用正则化
], lr=lr)
# 用于画图:训练过程中的 train/test 损失变化(对数坐标)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
# 开始训练
for epoch in range(num_epochs):
for X, y in train_iter: # 遍历训练数据的小批量
trainer.zero_grad() # 梯度清零
l = loss(net(X), y) # 计算当前 batch 的损失
l.mean().backward() # 求平均后反向传播计算梯度
trainer.step() # 优化器更新参数
# 每隔 5 个 epoch 可视化一次 train/test 的损失
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss), # 训练集损失
d2l.evaluate_loss(net, test_iter, loss))) # 测试集损失
# 打印训练后模型的权重大小(L2 范数)
print('w 的 L2 范数:', net[0].weight.norm().item())