在网络上找了很多关于深度学习的资料,也总结了一点小心得,于是就有了下面这篇文章。这里内容较为简单,适合初学者查看,所以大佬看到这里就可以走了。
话不多说,上图
从上图可以看出,传统神经网络算是另外两个神经网络的母体,所以这三者之间真要比较也一般都是拿CNN与RNN进行比较,很少看到拿三者一起比较的,很多初学者在这里就有所误解,以为三个神经网络是同时期的不同网络架构。
为了让大家更容易理解,这里整理了一组思维导图,解析三者神经网络的区别:
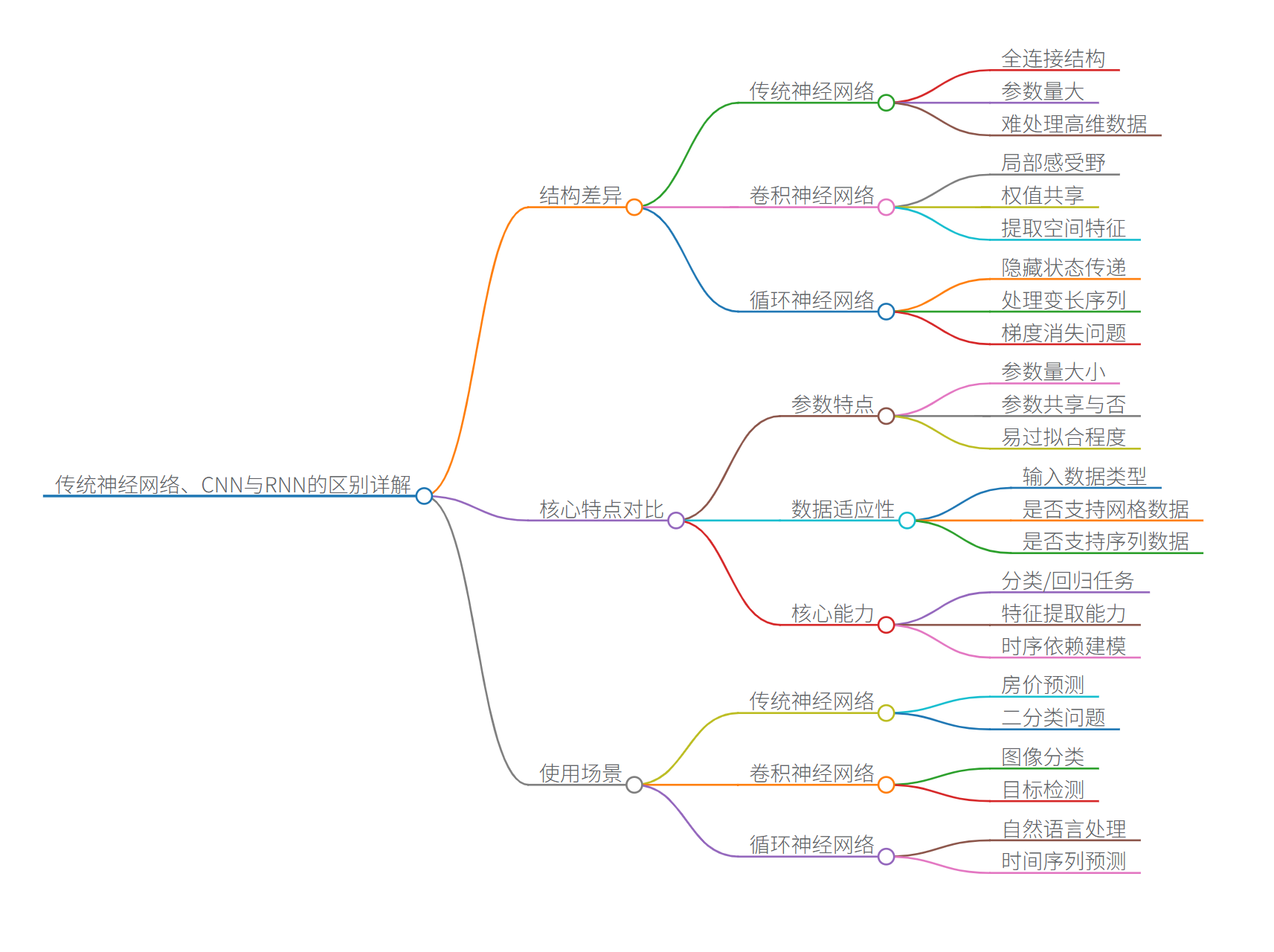
一、传统神经网络
传统神经网络(Traditional Neural Network)是指没有采用现代深度学习技术(如残差连接、批归一化、注意力机制等)的早期人工神经网络。它们通常由简单的全连接层或卷积层堆叠而成,其结构和训练方法相对基础。以下是传统神经网络的详细解释:
传统神经网络是一种基于生物学神经元模型的计算模型,通过多层非线性变换处理输入数据。其核心思想是通过“逐层传递”的方式将输入数据映射到输出结果,每一层的神经元通过权重和激活函数进行计算。
1.1 典型结构
传统神经网络的结构通常包括以下部分:
(1) 输入层
- 功能:接收原始数据(如像素值、文本特征)。
- 示例:MNIST 手写数字识别的输入层是 784 维向量(28×28 像素)。
(2) 隐藏层
- 全连接层(Dense Layer):
- 每个神经元与前一层的所有神经元相连。
- 计算公式: z = W ⋅ x + b , a = σ ( z ) z=W\cdot x+b, a=\sigma (z) z=W⋅x+b,a=σ(z),( σ \sigma σ为激活函数)。
- 激活函数:
- Sigmoid:将输出压缩到 [0,1],但存在梯度消失问题。
- Tanh:输出范围 [-1,1],缓解梯度消失但未彻底解决。
- ReLU:早期传统网络较少使用,因其可能导致神经元死亡。
(3) 输出层
- 多分类任务:使用 Softmax 激活函数,输出类别概率。
- 回归任务:使用线性激活函数(无激活函数)。
1.2 典型网络
传统神经网络算是人工智能领域的奠基性模型,典型结构包含输入层、隐藏层和输出层,通过非线性激活函数和权重连接实现特征映射。根据连接方式,可分为三大类:
-
前馈神经网络
- 结构:单向传递信息,无反馈连接(如感知机、BP神经网络)。
- 应用:简单分类、回归问题(如手写数字识别)。
- 局限性:无法捕捉数据中的时序依赖或空间相关性。
-
反馈神经网络
- 结构:包含循环连接(如Hopfield网络、Elman网络)。
- 应用:联想记忆、动态系统建模。
- 局限性:梯度消失/爆炸问题显著,难以处理长序列。
-
自组织神经网络
- 结构:无监督学习,自动聚类输入数据(如Kohonen网络)。
- 应用:数据降维、模式发现。
代码示例:
from keras.models import Sequential
from keras.layers import Dense
# MNIST手写数字识别示例
dnn_model = Sequential([
Dense(512, activation='relu', input_shape=(784,)),
Dense(256, activation='relu'),
Dense(10, activation='softmax')
])
dnn_model.compile(optimizer='adam', loss='categorical_crossentropy')
1.3 训练问题
传统神经网络在训练中面临以下挑战:
(1) 梯度消失/爆炸
- 原因:链式求导导致梯度在反向传播中指数级衰减(消失)或增长(爆炸)。
- 影响:深层网络无法有效更新权重,训练停滞。
(2) 过拟合
- 原因:网络容量过大,记忆噪声数据。
- 解决方案:
- 正则化(如 L2 正则化)。
- Dropout(早期传统网络较少使用)。
(3) 优化困难
- 问题:梯度方向不准确,陷入局部最优。
- 改进:使用更优的优化器(如 Adam),但传统网络通常依赖 SGD。
1.4 局限性
虽然对当时的来说传统神经网络以及很优秀,但是我们现在来看,传统神经网络还是有很大的缺点,其中最为限制其性能的就是以下三点:
- 深度限制:难以训练超过 20 层的网络。
- 特征提取能力:依赖手工特征(如 SIFT、HOG),而非端到端学习。
- 计算效率:全连接层参数量巨大,如 1000 层的网络可能包含数亿参数。
1.5 典型应用
在了解了上面的这些之后我们再来了解一下它的发展历史,传统神经网络的应用总共有以下在节点:
- 图像识别:LeNet-5(1998 年,手写数字识别)。
- 语音识别:深度信念网络(DBNs)。
- 自然语言处理:循环神经网络(RNNs)的早期应用。
1.6 与现代网络的对比
将传统神经网络拿到现在来对比,可以看出传统神经网络架构还是较为单一:
| 特性 | 传统神经网络 | 现代神经网络(如 ResNet) |
|---|---|---|
| 残差连接 | 无 | 有(解决梯度消失) |
| 激活函数 | Sigmoid/Tanh 为主 | ReLU/Swish/GELU 为主 |
| 归一化 | 无 | 批归一化(BatchNorm) |
| 深度 | 浅(通常 <20 层) | 深(如 ResNet-152 有 152 层) |
| 特征学习 | 依赖手工特征 | 端到端学习 |
总结:从上述的介绍我们可以看出,传统神经网络是深度学习的基础,但受限于梯度消失、过拟合和计算效率等问题,难以构建更深层、更复杂的模型。现代网络(如 ResNet、Transformer)通过引入残差连接、批归一化、注意力机制等创新,突破了这些限制,推动了 AI 技术的革命性发展。
二、卷积神经网络(CNN):空间特征的提取专家
卷积神经网络(Convolutional Neural Network, CNN)是一种专门设计用于处理网格状数据(如图像、音频、视频)的深度学习模型。它通过卷积层、池化层和全连接层的组合,能够自动提取数据的层次化特征,在计算机视觉领域取得了革命性突破。其核心优势在于局部连接和权重共享,大幅减少参数数量并提升平移不变性。
2.1 CNN的核心思想
- 局部连接:每个神经元仅连接输入的局部区域(如图像的一个小窗口),而非全部像素。
- 参数共享:同一卷积核的参数在整个输入中共享,大幅减少参数量。
- 层级特征提取:浅层学习边缘、纹理等低级特征,深层学习形状、物体部件等高级特征。
2.2 典型结构
CNN的结构通常包含以下模块:
(1) 输入层
- 图像输入:形状为
(高度, 宽度, 通道数),如RGB图像为(224, 224, 3)。 - 预处理:归一化(如像素值缩放到 [0,1])和标准化(均值为0,方差为1)。
(2) 卷积层(Convolutional Layer)
- 功能:通过滑动窗口(卷积核)提取局部特征。
- 关键参数:
- 核大小:如
3x3、5x5,决定感受野大小。 - 步长(Stride):窗口滑动的步幅,步长为2时特征图尺寸减半。
- 填充(Padding):在输入边缘填充0,保持特征图尺寸。
- 核大小:如
- 输出形状:
输出尺寸 = 输入尺寸 − 核大小 + 2 × 填充 步长 + 1 \text{输出尺寸} = \frac{\text{输入尺寸} - \text{核大小} + 2 \times \text{填充}}{\text{步长}} + 1 输出尺寸=步长输入尺寸−核大小+2×填充+1
(3) 激活函数
- ReLU:最常用激活函数,公式为 ( f(x) = \max(0, x) ),解决梯度消失问题。
- Swish/GELU:更平滑的激活函数,提升深层网络性能。
(4) 池化层(Pooling Layer)
- 功能:降低特征图尺寸,减少计算量,增强平移不变性。
- 类型:
- 最大池化(Max Pooling):取窗口内最大值。
- 平均池化(Average Pooling):取窗口内平均值。
- 示例:
MaxPool2D(pool_size=(2,2))将特征图尺寸减半。
(5) 全连接层(Fully Connected Layer)
- 功能:将提取的特征映射到最终分类结果。
- 结构:每个神经元与前一层所有神经元相连。
- 输出层:
- 多分类任务:使用 Softmax 激活函数,输出类别概率。
- 回归任务:使用线性激活函数。
(6) 正则化技术
- 批量归一化(BatchNorm):标准化特征分布,加速训练。
- Dropout:随机丢弃神经元,防止过拟合。
2.3 CNN的优势
| 特性 | 传统神经网络 | CNN |
|---|---|---|
| 局部连接 | 全连接,参数量爆炸 | 局部连接,参数大幅减少 |
| 平移不变性 | 需手动设计特征 | 自动学习平移不变特征 |
| 层级特征 | 依赖手工特征 | 端到端学习层次化特征 |
| 计算效率 | 高(全连接层参数量大) | 低(卷积层参数共享) |
2.4 经典CNN模型
| 模型 | 特点 | 应用场景 |
|---|---|---|
| LeNet-5 | 首个成功的CNN(1998),用于手写数字识别 | MNIST、OCR |
| AlexNet | 现代CNN的奠基模型(2012),引入ReLU和Dropout | ImageNet分类 |
| VGGNet | 加深网络(16-19层),验证深度重要性 | 图像分类、特征提取 |
| ResNet | 引入残差连接,解决梯度消失问题 | 图像分类、目标检测 |
| YOLO | 实时目标检测模型,融合CNN与回归 | 自动驾驶、安防监控 |
2.5 工作流程示例(MNIST识别)
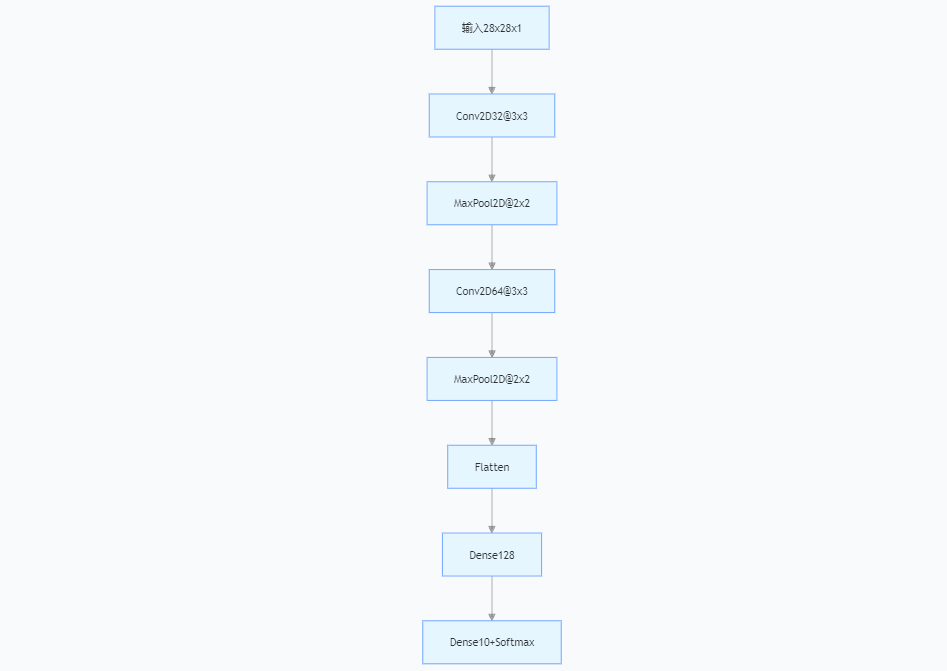
- 卷积层:提取边缘、曲线等低级特征。
- 池化层:降低特征图尺寸,保留关键信息。
- 全连接层:整合全局特征,输出数字概率。
代码示例:
from keras.layers import Conv2D, MaxPooling2D, Flatten
# CIFAR-10图像分类
cnn_model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
6. 应用领域
- 图像分类:识别物体类别(如ImageNet挑战赛)。
- 目标检测:定位并分类图像中的多个物体(如COCO数据集)。
- 语义分割:像素级分类(如医学影像分析)。
- 视频分析:动作识别、异常检测(如UCF101数据集)。
- 自然语言处理:文本分类、情感分析(如TextCNN)。
总结: CNN通过局部连接、参数共享和层级特征提取,成为处理图像和视频数据的首选模型。其成功推动了计算机视觉的革命,并为后续模型(如Transformer)奠定了基础。理解CNN的结构和原理是深入学习深度学习的关键一步。
三、循环神经网络(RNN)
RNN(循环神经网络,Recurrent Neural Network)是一种专门处理序列数据(如文本、语音、时间序列等)的神经网络架构。与传统前馈神经网络(如CNN)不同,RNN通过循环连接(Recurrent Connection)引入了时间维度上的记忆能力,允许信息在网络中传递和保留。
其通过隐藏状态传递机制捕捉长期依赖。经典公式如下:
h
t
=
tanh
(
W
x
h
x
t
+
W
h
h
h
t
−
1
+
b
h
)
h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1} + b_h)
ht=tanh(Wxhxt+Whhht−1+bh)
y
t
=
softmax
(
W
h
y
h
t
+
b
y
)
y_t = \text{softmax}(W_{hy}h_t + b_y)
yt=softmax(Whyht+by)
3.1 核心特点
-
循环结构
RNN的隐藏层不仅接收当前输入,还接收上一时刻的隐藏状态,形成“循环”信息流。公式表示为:
h t = σ ( W x h x t + W h h h t − 1 + b h ) h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h) ht=σ(Wxhxt+Whhht−1+bh)
其中, h t h_t ht是当前时刻的隐藏状态, x t x_t xt是输入, σ \sigma σ是激活函数(如tanh)。 -
时间依赖性
能够捕捉序列中的长期依赖关系(如句子中的上下文关联),但传统RNN存在梯度消失/爆炸问题,导致难以学习长期依赖。 -
变体改进
- LSTM(长短期记忆网络):通过门控机制(输入门、遗忘门、输出门)解决长期依赖问题。
- GRU(门控循环单元):简化版LSTM,参数更少,训练效率更高。
核心挑战:梯度消失/爆炸
- 解决方案:
- 使用ReLU激活函数
-引入门控机制(LSTM、GRU)
-梯度裁剪
- 使用ReLU激活函数
LSTM结构解析:
- 遗忘门:决定保留多少历史信息
- 输入门:控制新信息的流入
- 输出门:调节隐藏状态的输出
3.2 与CNN的对比
| 特性 | CNN | RNN |
|---|---|---|
| 结构 | 前馈,空间局部连接 | 循环,时间序列连接 |
| 适用数据 | 图像、网格数据 | 文本、语音、时间序列 |
| 记忆能力 | 无 | 有(短期依赖为主) |
| 典型应用 | 图像分类、目标检测 | 语言模型、语音识别 |
3.3 应用领域
- 自然语言处理(NLP)
- 语言模型(如GPT系列)
- 机器翻译、情感分析、文本生成
- 时间序列预测
- 股票走势预测、天气预测
- 语音处理
- 语音识别、说话人识别
- 视频分析
- 动作识别、视频描述生成
优缺点
- 优点:
- 擅长处理序列数据中的时间依赖关系。
- 结构灵活,可根据任务调整层数和单元类型(LSTM/GRU)。
- 缺点:
- 传统RNN存在梯度消失问题,难以捕捉长期依赖。
- 并行计算能力差,训练速度较慢(LSTM/GRU有所改善)。
代码示例(文本生成):
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(128, input_shape=(seq_length, vocab_size)),
Dense(vocab_size, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy')
总结:RNN是处理序列数据的核心模型,其循环结构赋予了对时间信息的建模能力。尽管存在一些局限性,但其变体(如LSTM、GRU)在实际任务中表现出色,是自然语言处理和时间序列分析的基石。
四、三者对比
4. 1 特征提取方式对比
# 可视化中间层输出
from keras.models import Model
# CNN特征可视化
conv_layer = Model(inputs=cnn_model.input,
outputs=cnn_model.layers[2].output)
feature_maps = conv_layer.predict(img_array)
# RNN隐藏状态可视化
lstm_layer = Model(inputs=rnn_model.input,
outputs=rnn_model.layers[2].output)
hidden_states = lstm_layer.predict(text_sequence)
4.2 各自特点对比
| 特征 | 传统神经网络(DNN) | 卷积神经网络(CNN) | 循环神经网络(RNN) |
|---|---|---|---|
| 连接方式 | 全连接 | 局部连接+参数共享 | 时序递归连接 |
| 核心优势 | 简单快速 | 空间特征提取 | 时序依赖捕捉 |
| 参数数量 | O(n²)级增长 | O(k²×c)级增长(k为卷积核尺寸) | O(n×h)级增长(h为隐藏单元) |
| 特征提取 | 全局特征 | 空间局部特征 | 时序特征 |
| 典型应用 | 简单分类/回归 | 图像处理 | 自然语言处理 |
| 并行计算能力 | 高 | 极高 | 低 |
| 记忆能力 | 无 | 无 | 有时序记忆 |
| 处理序列能力 | 需展开为向量 | 需转换为图像格式 | 原生支持 |
| 训练难度 | 容易过拟合 | 中等 | 梯度消失/爆炸问题严重 |
4.3 计算效率提升方案
| 网络类型 | 优化策略 | 效果提升幅度 |
|---|---|---|
| DNN | 参数剪枝+量化 | 50-70% |
| CNN | 深度可分离卷积 | 3-5倍加速 |
| RNN | 使用GRU代替LSTM | 30%提速 |
| 混合架构 | 层间融合+知识蒸馏 | 2-3倍加速 |
4.4 内存优化代码示例
# 混合精度训练
from keras.mixed_precision import set_global_policy
set_global_policy('mixed_float16')
# 梯度累积
optimizer = Adam(learning_rate=1e-4, gradient_accumulation_steps=4)
# 内存映射数据集
dataset = tf.data.Dataset.from_generator(data_gen, output_types=(tf.float32, tf.int32))
4.5 参数共享机制对比
- DNN:无共享机制
- CNN:卷积核滑动共享
- RNN:时间步参数共享
# 参数数量计算示例
def print_params(model):
trainable_params = np.sum([K.count_params(w) for w in model.trainable_weights])
print(f"可训练参数数量: {trainable_params:,}")
print_params(dnn_model) # 约 669,706 参数
print_params(cnn_model) # 约 121,866 参数
print_params(rnn_model) # 约 1,313,793 参数
五、组合应用:CNN+RNN的协同效应
- 图像描述生成
- CNN提取图像特征 → RNN生成自然语言描述
- 视频分类
- CNN处理空间信息 → RNN分析时间序列动态
- 对话系统
- CNN编码视觉输入 → RNN生成回复
示例架构:
# CNN特征提取
image_input = Input(shape=(224,224,3))
cnn_features = VGG16(weights='imagenet', include_top=False)(image_input)
cnn_features = GlobalAveragePooling2D()(cnn_features)
# RNN文本生成
text_input = Input(shape=(max_length,))
embedding = Embedding(vocab_size, 128)(text_input)
lstm_output = LSTM(256)(embedding)
# 合并输出
concat = Concatenate()([cnn_features, lstm_output])
output = Dense(1000, activation='softmax')(concat)
model = Model(inputs=[image_input, text_input], outputs=output)
六、写在最后(小结一下)
6.1 行业应用风向标
- 传统DNN:适合小规模、结构化数据,已逐步被CNN/RNN替代
- CNN:计算机视觉领域的绝对主力,向轻量化(MobileNet)和3D扩展
- RNN:LSTM/GRU仍是序列建模的主流,但Transformer架构在长距离依赖上表现更优
6.2 行业应用风向标
相信读完这篇文章,你对与三大网络架构有了一个大体的了解,掌握三大神经网络的本质差异,犹如获得打开深度学习世界的三把钥匙。无论是处理空间信息、时序序列还是简单结构化数据,选择合适的网络架构往往能事半功倍。如果有任何问题欢迎留言,也期待各位的批评指正!



















