#测试拼音分词
POST /_analyze
{
"text":"如家酒店真不错",
"analyzer": "pinyin"
}
#这里把拼音的首字母放到这里,也说明了这句话没有被分词,而是作为一个整体出现的
#还把每一个字都形成了一个拼音,这也没什么用 大多数情况下我们想用中文搜索#自定义分词器 创建test索引库的时候指定字段使用自定义的分词
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter":{
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}#删除索引库
DELETE /test#查询索引库
GET /test
#在分词分词的汉字拼音都有,而且还有分词的首字母拼音
POST /test/_analyze
{
"text":["如家酒店真不错"],
"analyzer": "my_analyzer"
}#在索引库test中插入一些文档
POST /test/_doc/1
{
"id":1,
"name":"狮子"
}POST /test/_doc/2
{
"id":2,
"name":"虱子"
}#搜索:有点问题搜索拼音,把同音字也搜到了
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}#在创建的时候可以用拼音选择器,在搜索的时候不应该用拼音选择器,搜索用search_analyzer,在搜索是用户输入的是中文,用户用中文去搜,输入的是拼音,才拿拼音去搜
#自定义分词器 创建test索引库的时候指定字段使用自定义的分词
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter":{
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenize":false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
#现在搜索是用户输入的是中文,用户用中文去搜,输入的是拼音,才拿拼音去搜
GET /test/_search
{
"query": {
"match": {
"name": "虱子"
}
}
}
#自动补全 参与自动补全的的字段必须是completion类型,字段的内容一般是用来补全的多个词条形成的数组
#创建索引库
PUT /test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}#查询索引库
GET /test2#删除索引库
DELETE /test2#插入数据
POST test2/_doc
{
"title":["Sorry","WH-1000XM3"]
}POST test2/_doc
{
"title":["SK-IT","PITERA"]
}POST test2/_doc
{
"title":["Nintendo","switch"]
}#自动补全查询
GET /test2/_search
{
"suggest":{
"titleSuggest":{
"text":"s",
"completion":{
"field":"title",
"skip_duplicates":true,
"size":10
}
}
}
}GET /test2/_search
{
"suggest":{
"titleSuggest":{
"text":"so",
"completion":{
"field":"title",
"skip_duplicates":true,
"size":10
}
}
}
}#查看索引库的结构
GET /hotel/_mapping#删除索引库
DELETE /hotel#酒店数据索引库
#定义了两个分词器,全文检索用text_anlyzer,自动补全用completion_analyzer
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
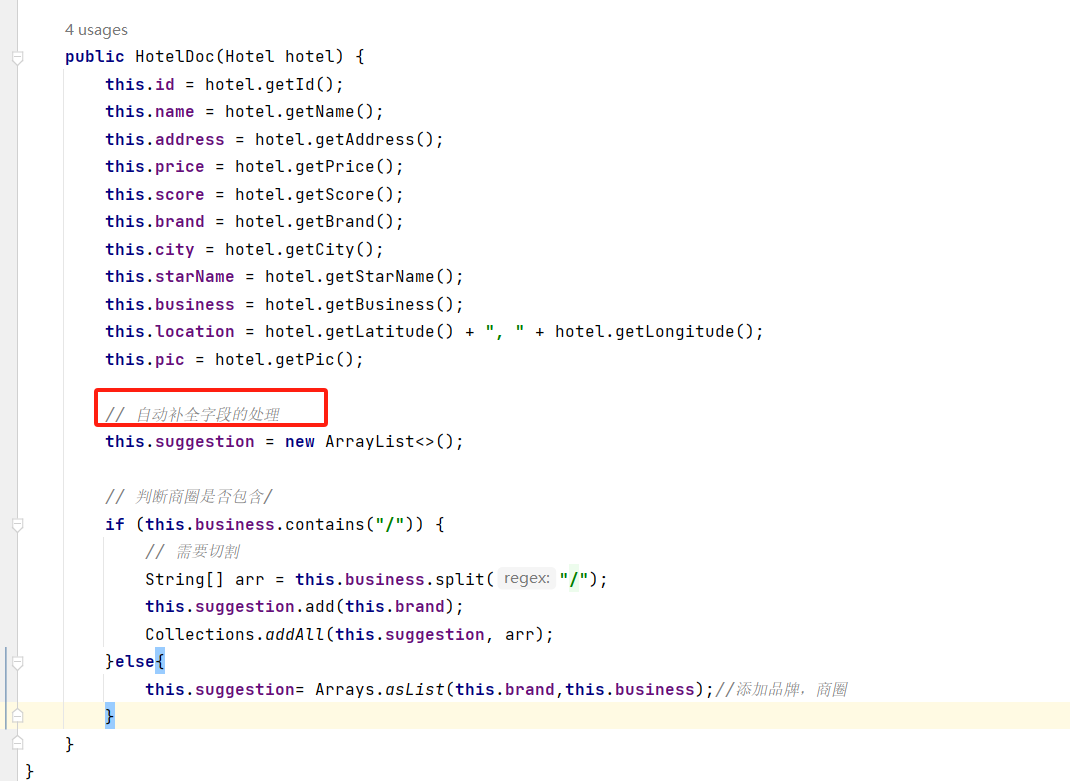
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}#查询所有
GET /hotel/_search
{
"query":{
"match_all": {}
}
}#自动补全查询
GET /hotel/_search
{
"suggest":{
"suggestions":{
"text":"h",
"completion":{
"field":"suggestion",
"skip_duplicates":true,
"size":10
}
}
}
}
//自动补全查询:
@Test
void testSuggest() throws IOException {
//准备requuest
SearchRequest request=new SearchRequest("hotel");
//准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("hz")
.skipDuplicates(true)
.size(10)
));
//发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析结果
System.out.println(response);
Suggest suggest = response.getSuggest();
//根据补全查询名称,获取补全结果
CompletionSuggestion suggestions= suggest.getSuggestion("suggestions");
//获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
//遍历
for (CompletionSuggestion.Entry.Option option:options){
String text = option.getText().toString();
System.out.println(text);
}
}

@Override
public List<String> getSuggestions(String prefix) {
//准备requuest
SearchRequest request=new SearchRequest("hotel");
//准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
try {
//发起请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//解析结果
System.out.println(response);
Suggest suggest = response.getSuggest();
//根据补全查询名称,获取补全结果
CompletionSuggestion suggestions= suggest.getSuggestion("suggestions");
//获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
//遍历
List<String> list=new ArrayList<>(options.size());
for (CompletionSuggestion.Entry.Option option:options){
String text = option.getText().toString();
System.out.println(text);
list.add(text);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
}

















![[Linux]基础IO](https://i-blog.csdnimg.cn/direct/c834a4a353d947e9829b3cd42d25a7ca.png)