在 Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由Scaled Dot Product Attention 和Feed Forward Neural Network组成。一个基于 Transformer 的可训练的神经网络可以通过堆叠 Transformer 的形式进行搭建,Attention is All You Need论文中通过搭建编码器(encoder)和解码器(decoder)各 6 层,总共 12 层的Encoder-Decoder,并在机器翻译中取得了 BLEU 值的新高。
作者采用 Attention 机制的原因是考虑到 RNN(或者 LSTM,GRU 等)的计算限制为是顺序的,也就是说 RNN 相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管 LSTM 等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象 LSTM 依旧无能为力。
Transformer 的提出解决了上面两个问题:
- 首先它使用了 Attention 机制,将序列中的任意两个位置之间的距离是缩小为一个常量;
- 其次它不是类似 RNN 的顺序结构,因此具有更好的并行性,符合现有的 GPU 框架。
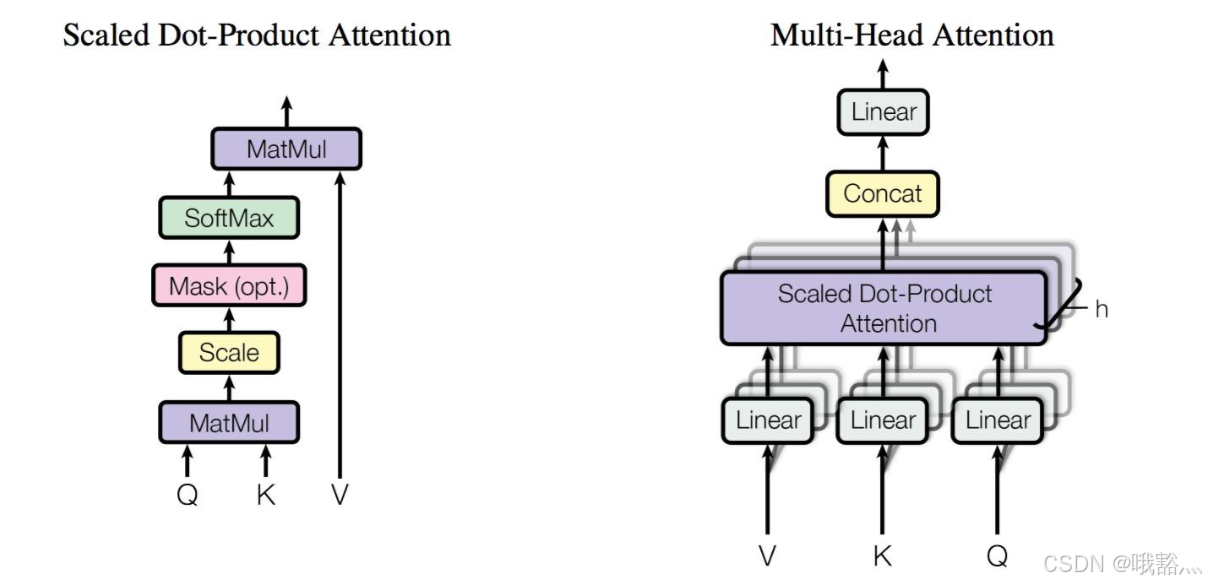
Scaled Dot Product Attention作为 Transformer 模型结构最核心的组件,pytorch 对其做了融合实现支持,并提供了丰富的 python 接口供用户轻松搭建 Transformer:
torch.nn.functional.scaled_dot_product_attention,
torch.nn.MultiheadAttention,
torch.nn.TransformerEncoderLayer,
torch.nn.Transformer,
torch.nn.TransformerDecoderLayer,
torch.ops.aten._scaled_dot_product_flash_attention,
torch.ops.aten._scaled_dot_product_efficient_attention_cuda
这里先之看torch.nn.functional.scaled_dot_product_attention这个接口。
1 Fused implementations
给定 CUDA 张量输入,torch.nn.functional.scaled_dot_product_attention函数将分派到以下实现之一:
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- Memory-Efficient Attention
- C++ 定义的原生 PyTorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
device = "cuda" if torch.cuda.is_available() else "cpu"
# Example Usage:
query, key, value = torch.randn(2, 3, 8, device=device), torch.randn(2, 3, 8, device=device), torch.randn(2, 3, 8, device=device)
F.scaled_dot_product_attention(query, key, value)
2 Explicit Dispatcher Control
torch.nn.functional.scaled_dot_product_attention函数将隐式分派到三个实现之一,但用户也可以通过使用上下文管理器显式控制分派。此上下文管理器允许用户明确禁用某些实现。如果用户确定对于特定输入某种实现是最快的实现的话,则可以使用上下文管理器来扫描测量性能。
# Lets define a helpful benchmarking function:
import torch.utils.benchmark as benchmark
def benchmark_torch_function_in_microseconds(f, *args, **kwargs):
t0 = benchmark.Timer(
stmt="f(*args, **kwargs)", globals={"args": args, "kwargs": kwargs, "f": f}
)
return t0.blocked_autorange().mean * 1e6
# Lets define the hyper-parameters of our input
batch_size = 32
max_sequence_len = 1024
num_heads = 32
embed_dimension = 32
dtype = torch.float16
query = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
key = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
value = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
print(f"The default implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
# Lets explore the speed of each of the 3 implementations
from torch.backends.cuda import sdp_kernel, SDPBackend
# Helpful arg mapper
backend_map = {
SDPBackend.MATH: {"enable_math": True, "enable_flash": False, "enable_mem_efficient": False},
SDPBackend.FLASH_ATTENTION: {"enable_math": False, "enable_flash": True, "enable_mem_efficient": False},
SDPBackend.EFFICIENT_ATTENTION: {
"enable_math": False, "enable_flash": False, "enable_mem_efficient": True}
}
with sdp_kernel(**backend_map[SDPBackend.MATH]):
print(f"The math implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):
try:
print(f"The flash attention implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
except RuntimeError:
print("FlashAttention is not supported. See warnings for reasons.")
with sdp_kernel(**backend_map[SDPBackend.EFFICIENT_ATTENTION]):
try:
print(f"The memory efficient implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")
except RuntimeError:
print("EfficientAttention is not supported. See warnings for reasons.")
3 Causal Self Attention
下面是受 Andrej Karpathy 的 NanoGPT 仓库启发的 multi-headed causal self attention 的示例实现:
class CausalSelfAttention(nn.Module):
def __init__(self, num_heads: int, embed_dimension: int, bias: bool=False, is_causal: bool=False, dropout:float=0.0):
super().__init__()
assert embed_dimension % num_heads == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(embed_dimension, 3 * embed_dimension, bias=bias)
# output projection
self.c_proj = nn.Linear(embed_dimension, embed_dimension, bias=bias)
# regularization
self.dropout = dropout
self.resid_dropout = nn.Dropout(dropout)
self.num_heads = num_heads
self.embed_dimension = embed_dimension
# Perform causal masking
self.is_causal = is_causal
def forward(self, x):
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
query_projected = self.c_attn(x)
batch_size = query_projected.size(0)
embed_dim = query_projected.size(2)
head_dim = embed_dim // (self.num_heads * 3)
query, key, value = query_projected.chunk(3, -1)
query = query.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)
if self.training:
dropout = self.dropout
is_causal = self.is_causal
else:
dropout = 0.0
is_causal = False
y = F.scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=dropout, is_causal=is_causal)
y = y.transpose(1, 2).view(batch_size, -1, self.num_heads * head_dim)
y = self.resid_dropout(self.c_proj(y))
return y
num_heads = 8
heads_per_dim = 64
embed_dimension = num_heads * heads_per_dim
dtype = torch.float16
model = CausalSelfAttention(num_heads=num_heads, embed_dimension=embed_dimension, bias=False, is_causal=True, dropout=0.1).to("cuda").to(dtype).eval()
print(model)
4 NestedTensor and Dense tensor support
SDPA 支持 NestedTensor 和 Dense 张量输入。NestedTensors 处理输入是一批可变长度序列的情况,而不需要将每个序列填充到批中的最大长度。
import random
def generate_rand_batch(
batch_size,
max_sequence_len,
embed_dimension,
pad_percentage=None,
dtype=torch.float16,
device="cuda",
):
if not pad_percentage:
return (
torch.randn(
batch_size,
max_sequence_len,
embed_dimension,
dtype=dtype,
device=device,
),
None,
)
# Random sequence lengths
seq_len_list = [
int(max_sequence_len * (1 - random.gauss(pad_percentage, 0.01)))
for _ in range(batch_size)
]
# Make random entry in the batch have max sequence length
seq_len_list[random.randint(0, batch_size - 1)] = max_sequence_len
return (
torch.nested.nested_tensor(
[
torch.randn(seq_len, embed_dimension,
dtype=dtype, device=device)
for seq_len in seq_len_list
]
),
seq_len_list,
)
random_nt, _ = generate_rand_batch(32, 512, embed_dimension, pad_percentage=0.5, dtype=dtype, device=device)
random_dense, _ = generate_rand_batch(32, 512, embed_dimension, pad_percentage=None, dtype=dtype, device=device)
# Currently the fused implementations don't support NestedTensor for training
model.eval()
with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):
try:
print(f"Random NT runs in {benchmark_torch_function_in_microseconds(model, random_nt):.3f} microseconds")
print(f"Random Dense runs in {benchmark_torch_function_in_microseconds(model, random_dense):.3f} microseconds")
except RuntimeError:
print("FlashAttention is not supported. See warnings for reasons.")
5 Scaled Dot Product Attention (SDPA) 在 CPU 上的 性能优化
PyTorch 2.0 的主要 feature 是 compile,一起 release 的还有一个很重要的 feature 是 SDPA: Scaled Dot Product Attention 的优化。一共包含三个算法:
- Math: 把原始实现从 Python 挪到了 C++
- Efficient Attention
- Flash Attention
后两种算法是无损加速,不同于使用 low rank 或者 sparse 的方式,从数学上来说计算没有发生变化,所以不影响精度。
SDPA 主要是为了解决 LLM 中的两方面痛点:
- memory footprint: attn 的尺寸是 {B, H, T, T}。和 T 是 O(n2) 的关系,随着 sequence 变长,memory 开销太大;
- performance speedup: 针对 attn 的 pointwise 操作都是 memory bandwidth bound,速度太慢了
目前的版本中,后两种算法都只支持 CUDA device。
5.1 Previous Work
1.3 版本出现了 nn.MultiheadAttention 的优化,具体应用的 API 是 HuggingFace Optimum 的 BetterTransformer。思路是把 gemm 之间的 pointwise 统统 fuse 起来。
最大的收益来自于对 attn 操作的 fusion,因为 QKV 尺寸是和 T * K 成正比,而 attn 是和 T * T 成正比。这里的 K 是每个 head 上的 feature size,T 是 sequence length,一般来讲 T 会 比 K 大很多。
原始实现对于 masked softmax 的处理一共需要 4 reads + 5 writes:
对于 mask 的处理会非常繁琐:需要 4 次操作: ones, tril, not, masked_fill。共需要 3 reads + 4 writes。softmax 由于需要保障数值稳定性,需要 4 个 steps 完成,不过这 4 步只有 1 read + 1 write,原因在于 transformer 里面是在 lastdim 上做 softmax,正常情况下数据 parallel 的方式保障 L1 cache hit,所以只有 1 read + 1 write。
做了 fuse 之后,masked_softmax 一共需要 1 read + 1 write。attn 是个很大的 tensor,所以主要的性能收益来自这个地方。但即使只有 1次读和1次写,还是不够快,另外这个算法解决不了内存开销太大的问题。为了解决这些问题, SDPA 应运而生了,不管是 efficient attention 还是 flash attention,核心都是如何通过 blocking (或者叫 tiling)避免直接分配一块 {B, H, T, T} 这么大的 attn。通过让数据停留在 cache 上面,达到对 pointwise 操作的加速。
5.2 SDPA 优化
efficient attention 和 flash attention 2 在经过 fully optimized 之后这两种算法本质上没有区别。
5.2.1 naive
整个 scaled dot product attention 的原始计算过程如下图,对于每一个 {B, H} 的 slice:
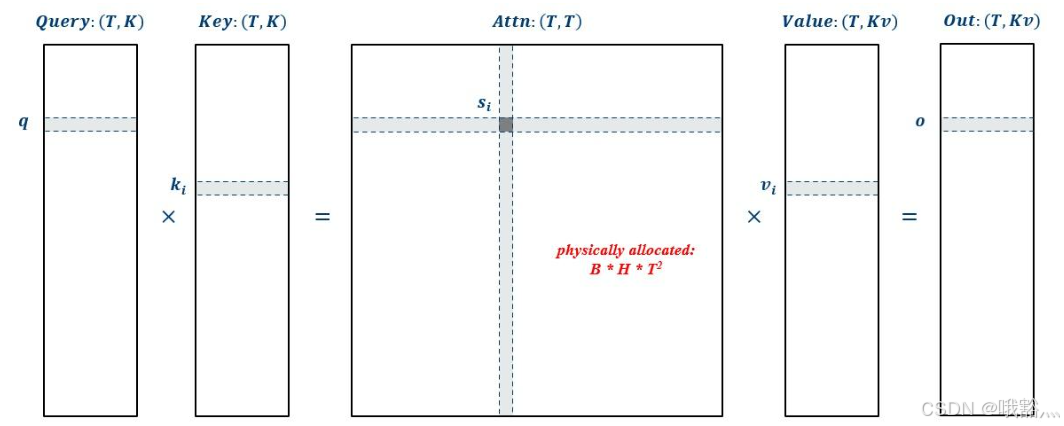
这里,把 V 看作一个 v 0 , v 1 , . . . , {v0, v1, ..., } v0,v1,..., 的向量会比较好理解。另外,我们认为这里 attn 还是做了实际的内存分配。
整个过程可以分解为 3 步:
- 一个 vec-vec 的 Dot Product
- 针对 attn 每一行元素的 pointwise
- 一个 vec-mat 的 GEMV
5.2.2 Lazy Softmax
引入 lazy softmax 可以避免为 attn 实际分配内存,在每个 thread 保留一些 momentum 信息即可:
m*记录当前的 max value;s*记录 sum value;v*记录 out 中每一行的累计值。
那么,可以很容易地算出来每个 thread 需要的额外内存只有:1 + 1 + Kv (Kv 是 V 每个 head 的 feature size)。
从性能角度出发我们更关心计算的性质,与原始形态计算量实际上发生了退化,不过好在不需要分配 {B, H, T, T} 这么大一个 tensor 了:
但是,这种实现依旧很原始,性能并不好,这个 kernel 大概会比原版还慢十几倍。主要原因有两点:
- 对于每一个
q_i,都需要遍历整个 K,才能完成 attn 中一行的计算; s_i需要和v_i相乘并累加到o_i中,这个过程中同样对于 V 有重复访问,并且要多次写入 O;
按模型中实际尺寸来算,KV是不可能被 cache 命中的,所以就是在不停地刷内存带宽,肯定快不了。
5.2.3 在 KV 上做 Blocking
在 KV 上做 blocking,即每一个 iteration 计算 q_i 和 一个 K block 和 V block,这么做是为了减少对 O 的写入次数,KV block 的数量就是减少写入次数的倍数。这个时候计算的性质已经发生了变化,每一步的计算量被放大了 NB 倍。
也需要一个额外的 s_i 来记录 qk 的内积结果,那么每个 thread 的额外内存变为:1 + 1 + NB + Kv
不过这样还是不能解决对 KV 的重复访问。
5.2.4 在 Q 上做 Blocking
在 Q 上做 blocking,即每一个 iteration 计算 一个 Q block 和 一个 KV block,这么做是为了减少对 KV 的读取次数,Q block 的数量就是减少读取次数的倍数。
每一步的计算量被再次放大了 MB 倍。
每个 thread 的额外内存变为:MB * (1 + 1 + NB + Kv),扩大了 MB 倍。不过我们还是可以通过计算保障这个 buffer 被 L2 命中(L1 大小是 32KB,L2 是 1MB,这个 buffer 大小可以设置 L2 的 25%)。
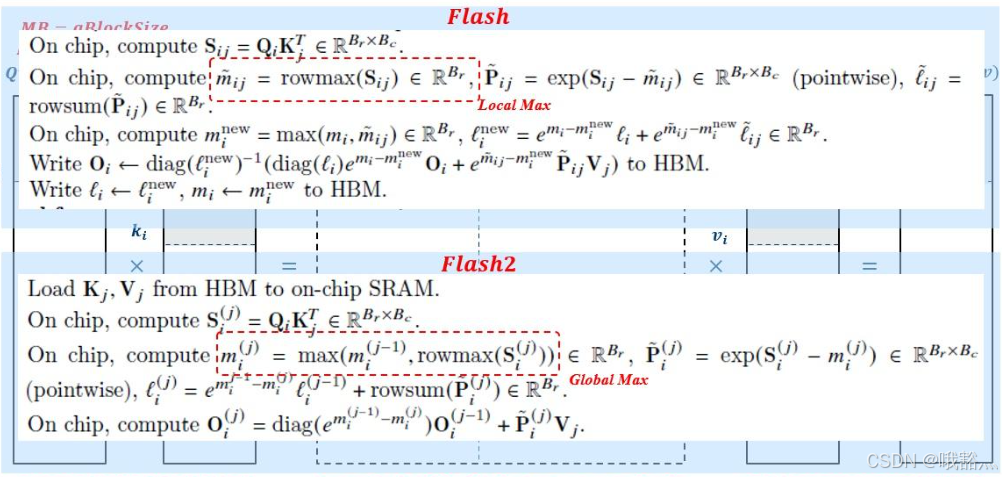
至此,我们完成了对 SDPA 基本形态的推导,从 efficient 算法入手,可以得到数学上和 flash2 完全一致的过程:
5.2.5 Float16 和 BFloat16 的实现
基本原则是用 float32 来做 accumulation。当然在 intel xeon 上得益于 AMX 的硬件加速,code 中使用了 MKL 中的 cblas_gemm_bf16bf16f32 函数,即 A(bf16) x B(bf16) = C(fp32)
5.2.6 Causal Mask
SDPA 对于 Causal mask 的处理是在 s_i 这个 buffer 里面加 mask,配合上 blocking,可以额外省掉上三角的 GEMM,所以在 causal mask 的情况下 SDPA 能拿到更大的加速比:
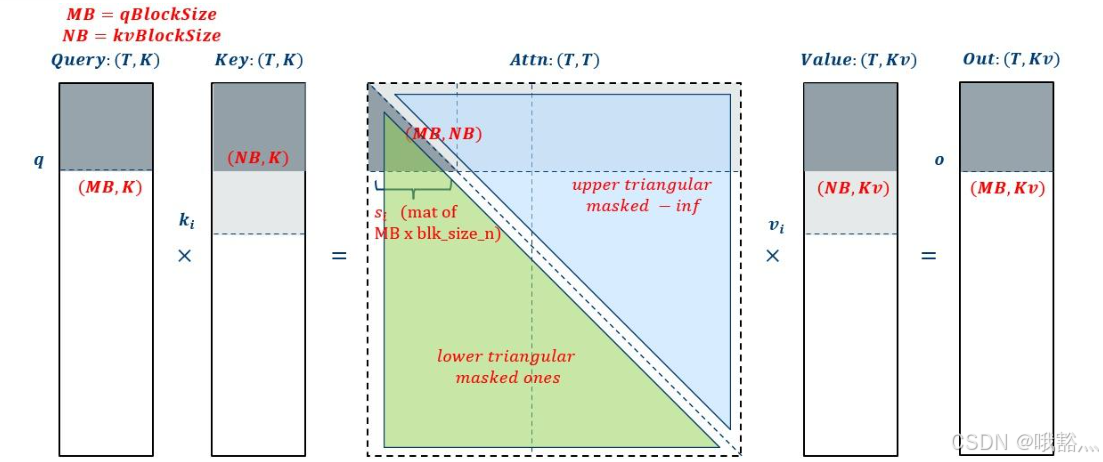
实际中因为配合了 blocking,所以中间的那条线应该是个阶梯状的,阶梯上面的 GEMM 会被省略掉。
5.2.7 一些问题
首先最显著的一个问题就是 load imbalance, 我们依赖在 B-H-MB (batch-head-q_block) 这三个维度上做 parallel,但每一个 q block 对应访问的 kv block 数量是不一样的,可能会导致 load imbalance:

这个问题其实很好解决,因为我们预先就可以算出每个 q block 对应几个 kv block。
还有一个比较难处理的问题是每个 thread memory 访问不均衡的问题。比如我们有 10 个 q block,但每个 thread 只能计算 8 个,那么 T0 只会访问一组 KV (都来自 Head_0);而 T2 会访问两组 KV (来自于 Head_0 和 Head_1)。
另外还有一个让 amx 和 avx512 并行的问题,也就是如何让 GEMM 和 pointwise 并行起来。



















