Hi,大家好,我是半亩花海。本实验基于汽车销量时序数据,使用LSTM网络(长短期记忆网络)构建时间序列预测模型。通过数据预处理、模型训练与评估等完整流程,验证LSTM在短期时序预测中的有效性。
目录
一、实验目标
二、实验原理
三、实验环境
四、实验步骤
1. 数据预处理
2. 构建时间序列数据集
3. 模型构建与训练
4. 预测与反归一化
5. 结果可视化
6. 模型评估
五、实验分析
1. 评估指标解读
2. 可能的原因分析
3. 改进方法
六、完整代码
一、实验目标
本实验基于汽车销量时序数据,构建LSTM神经网络模型,实现对时间序列数据的预测,并通过可视化和评估指标验证模型性能。实验目标包括:
- 掌握时间序列数据的预处理方法
- 理解LSTM网络的工作原理
- 构建端到端的时序预测模型
- 评估模型预测性能
二、实验原理
1. 核心算法:LSTM网络
长短期记忆 (Long Short-Term Memory, LSTM) 是一种时间递归神经网络(RNN),它是一种基于机器学习理论的循环网络时间序列预测方法。该模型可有效处理并解决RNN中人为很难实现的延长时间任务的问题,并预测时间序列中间隔和延迟非常长的重要事件,同时削减了RNN中梯度消失问题对预测研究的影响,总的来说LSTM模型是一种特殊的RNN循环神经网络。
RNN循环神经网络结构如图所示。

LSTM的网络结构大概为:单层LSTM(5个神经元)+ 全连接层,输入形状为(时间步长=1, 特征数=1)。LSTM网络结构如图所示。


(1)输入门(Input gate)的计算:
![]()
(2)遗忘门(Forget gate)的计算:
![]()
(3)候选记忆单元的计算:
![]()
(4)记忆单元状态更新的计算:
![]()
(5)输出门的计算:
![]()
(6)隐藏状态(output)的计算:
![]()
2. 关键技术实现
- 数据归一化:使用
MinMaxScaler将数据缩放到[0,1]区间,加速模型收敛。 - 时间序列建模:通过滑动窗口法(
look_back=1)将数据转换为监督学习格式,每个样本包含1个时间步的历史数据。 - 模型训练:采用Adam优化器和均方误差损失函数,训练150轮,批量大小为2。
三、实验环境
| 项目 | 配置/版本 |
|---|---|
| Python | 3.8+(3.8.20) |
| TensorFlow | 2.10.0 |
| 主要库 | numpy(1.21.6), matplotlib(3.6.3), pandas(1.4.4), scikit-learn(1.1.3), pillow(10.4.0) |
| 硬件环境 | CPU/GPU |
四、实验步骤
1. 数据预处理
(1)数据加载与清洗
# 加载数据(取第2列,跳过末尾3行)
dataframe = pd.read_csv("D:\Python_demo\Time Series\LSTM\car.csv", usecols=[1], skipfooter=3)- 选取CSV文件第2列数据(销量数据)
- 跳过末尾3行异常数据
- 转换为float32类型保证数值精度
(2)数据归一化
dataset = scaler.fit_transform(dataframe.values.astype('float32'))- 使用MinMaxScaler进行0-1归一化
- 消除量纲影响,加速模型收敛
- 公式:
(3)数据集划分
# 划分训练集与测试集(8:2)
train_size = int(len(dataset) * 0.80)
trainlist, testlist = dataset[:train_size], dataset[train_size:]- 按8:2比例划分训练/测试集
- 保持时序连续性,避免随机划分
2. 构建时间序列数据集
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back)] # 取look_back长度的历史数据
dataX.append(a)
dataY.append(dataset[i + look_back]) # 预测下一个时间点的值
return np.array(dataX), np.array(dataY)
# 设置时间步长(这里使用1步预测)
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
testX, testY = create_dataset(testlist, look_back)
# 调整输入格式(LSTM需要[样本数, 时间步, 特征数]的3D张量)
trainX = np.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = np.reshape(testX, (testX.shape[0], look_back, 1))
- 滑动窗口法 :
look_back=1表示用当前时刻数据预测下一时刻值。 - 输入维度 :LSTM要求输入为3D张量,此处形状为
(样本数, 1, 1)。
3. 模型构建与训练
# 构建LSTM模型
model = Sequential() # 创建序列模型
model.add(LSTM(5, input_shape=(look_back, 1))) # 添加LSTM层(5个神经元,输入形状为(时间步=1, 特征数=1))
model.add(Dense(1)) # 添加全连接输出层
model.compile(loss='mean_squared_error', optimizer='adam') # 编译模型(均方误差损失,Adam优化器)
model.fit(trainX, trainY, epochs=150, batch_size=2, verbose=2) # 训练模型(100轮,批量大小2)
- 损失函数 :均方误差(MSE)适用于回归任务。
- 优化器 :Adam动态调整学习率,平衡收敛速度与精度。
- 超参数选择 :小批量(batch_size=2)训练适合小数据集。
4. 预测与反归一化
# 对训练集和测试集进行预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 反归一化(将预测结果还原到原始数据范围)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)- 反归一化 :将预测结果还原到原始数据范围,便于计算真实误差。
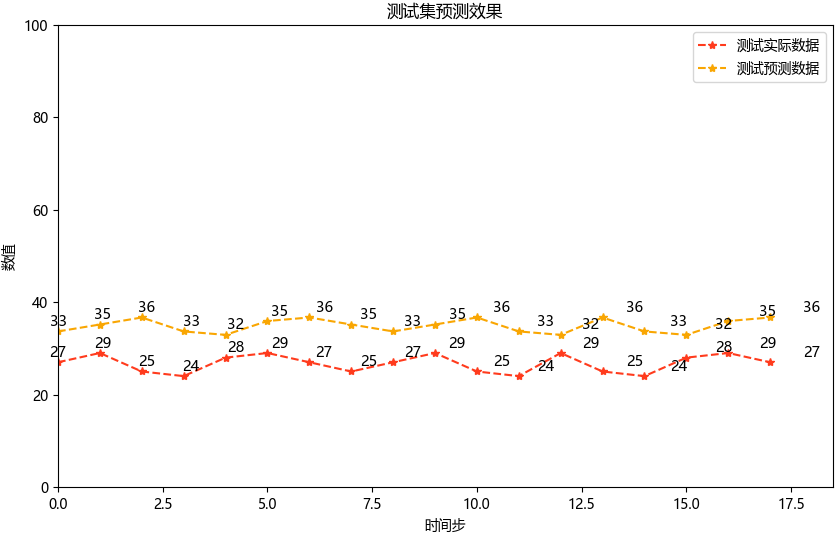
5. 结果可视化
# 绘制训练集结果
plt.figure(figsize=(10, 6))
plt.plot(trainY, label="训练实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(trainPredict[1:], label="训练预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("训练集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.legend()
plt.show()
# 绘制测试集结果
plt.figure(figsize=(10, 6))
xx = np.linspace(0, len(testY), len(testY))
plt.plot(testY, label="测试实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(testPredict, label="测试预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("测试集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.xlim(0, 18.5)
plt.ylim(0, 100)
plt.legend()
# 添加数据标签
for x, y in zip(xx, testY):
plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)
for x, y in zip(xx, testPredict):
plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)
plt.show()
- 坐标轴限制 :根据测试集数据范围手动设置,避免自动缩放失真。
- 数据标签 :通过
plt.text()标注具体数值,增强可读性。


6. 模型评估
| 指标 | 公式 |
|---|---|
| MAE(Mean Absolute Error,平均绝对误差) | |
| RMSE(Root Mean Squared Error,均方根误差) | |
| R²(Coefficient of Determination,决定系数) | |
# 计算评估指标
mae = mean_absolute_error(testPredict, testY)
rmse = np.sqrt(mean_squared_error(testPredict, testY))
r2 = r2_score(testPredict, testY)
print('测试集评估指标:')
print('MAE: %.3f' % mae)
print('RMSE: %.3f' % rmse)
print('R²: %.3f' % r2)
| 指标 | 计算结果 | 意义 |
|---|---|---|
| MAE | 6.397 | 预测值与真实值的平均绝对误差,表明平均预测误差约4.85个单位 |
| RMSE | 6.818 | 对较大误差更敏感的均方根误差 |
| R² | -25.777 | 模型解释了一定的数据方差,说明模型的解释力 |
五、实验分析
1. 评估指标解读
(1)MAE(Mean Absolute Error,平均绝对误差)
- 值:6.397
- 解释:平均绝对误差表示预测值与真实值之间的平均差距为6.397。
- 评价:MAE值本身并不算特别大,但需要结合数据的实际范围来判断。如果汽车销量数据的范围是几十到几百,则6.397的误差可能偏高。
(2)RMSE(Root Mean Squared Error,均方根误差)
- 值:6.818
- 解释:均方根误差对较大的误差更敏感,其值比MAE稍高,说明可能存在一些较大的预测偏差。
- 评价:RMSE略高于MAE,说明误差分布中存在一些较大的异常值。
(3)R²(Coefficient of Determination,决定系数)
- 值:-25.777
- 解释:R²衡量模型对数据方差的解释能力,理想值为1,负值表示模型的预测效果比直接用均值预测还要差。
- 评价 :R²为负数是一个严重的警告信号,说明模型几乎完全无法捕捉数据的趋势,甚至可能在某些情况下“反向预测”。
2. 可能的原因分析
(1)数据质量问题
①数据量不足:如果训练数据太少,模型可能无法学习到有效的模式。
②数据噪声过多:汽车销量数据可能存在大量随机波动或异常值,导致模型难以拟合。
③非平稳性:时间序列数据可能存在趋势或季节性成分,而模型未对其进行处理。
(2)模型设计问题
①LSTM结构过于简单
- 单层LSTM(仅5个神经元)可能不足以捕捉复杂的时序关系。
- 时间步长
look_back=1限制了模型利用历史信息的能力。
②超参数设置不当
- 训练轮次(epochs=150)可能过多或过少。
- 批量大小(batch_size=2)可能导致梯度更新不稳定。
(3)数据预处理问题
①归一化范围不合适:虽然使用了MinMaxScaler,但如果数据分布不均匀,归一化可能放大噪声。
②滑动窗口法不足:look_back=1仅使用最近一个时间点的数据进行预测,可能忽略长期依赖关系。
(4)测试集划分问题
①训练集和测试集分布不一致:如果测试集包含了训练集中未见过的模式(如突然的销量激增或下降),模型可能表现不佳。
②数据泄露:确保测试集数据没有被意外用于训练。
3. 改进方法
(1)数据质量优化
①检查数据完整性 :确认数据无缺失值或异常值,并剔除明显的噪声点。
②平滑处理 :对原始数据进行移动平均或其他平滑操作,减少短期波动的影响。
③分解时间序列 :使用STL分解等方法提取趋势和季节性成分,分别建模。
(2)模型结构调整
①增加LSTM层数和神经元数量
model.add(LSTM(50, return_sequences=True, input_shape=(look_back, 1))) # 第一层LSTM
model.add(LSTM(50)) # 第二层LSTM
model.add(Dense(1)) # 输出层我后续只修改了这一项,得出结果如下,感觉只有训练集效果稍微好了一些。

②调整时间步长 :尝试look_back=3或更高值,以利用更多历史信息。
③添加Dropout层 :防止过拟合,例如:
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.2))(3)超参数调优
①学习率调整 :尝试不同的学习率(如0.001或0.01)。
②批量大小优化 :将batch_size调整为更大的值(如16或32)。
③早停机制 :避免过拟合,使用EarlyStopping回调函数:
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
model.fit(trainX, trainY, epochs=200, batch_size=16, validation_split=0.2, callbacks=[early_stopping])(4)数据预处理改进
①标准化代替归一化 :如果数据分布较广,可以尝试StandardScaler(均值为0,标准差为1)。
②特征工程 :引入额外特征(如节假日、促销活动等)增强模型输入。
(5)测试集验证
①交叉验证 :使用时间序列交叉验证(TimeSeriesSplit)评估模型性能。
②重新划分数据集 :确保训练集和测试集分布一致,避免数据泄露。
六、完整代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : Time Series/LSTM/LSTM_car
@File : LSTM_car.py
@IDE : PyCharm
@Author : 半亩花海
@Date : 2025/03/10 17:36
"""
# ===================================
# 导入必要库
# ===================================
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.models import Sequential, load_model
import tensorflow as tf
# 禁用eager模式(兼容旧版本TensorFlow)
tf.compat.v1.disable_eager_execution()
# 设置中文字体显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['font.serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# ===================================
# 数据预处理
# ===================================
# 加载数据(取第2列数据,跳过末尾3行)
dataframe = pd.read_csv(r"D:\Python_demo\Time Series\LSTM\car.csv", usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values
# 数据类型转换
dataset = dataset.astype('float32')
# 数据归一化(0-1范围)
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 划分训练集和测试集(8:2比例)
train_size = int(len(dataset) * 0.80)
trainlist = dataset[:train_size]
testlist = dataset[train_size:]
# ===================================
# 构建时间序列数据集
# ===================================
def create_dataset(dataset, look_back):
"""
将时间序列数据转换为监督学习格式
:param dataset: 原始数据集
:param look_back: 时间步长(使用多少历史数据预测)
:return: 输入特征X和目标值Y
"""
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back)] # 取look_back长度的历史数据
dataX.append(a)
dataY.append(dataset[i + look_back]) # 预测下一个时间点的值
return np.array(dataX), np.array(dataY)
# 设置时间步长(这里使用1步预测)
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
testX, testY = create_dataset(testlist, look_back)
# 调整输入格式(LSTM需要[样本数, 时间步, 特征数]的3D张量)
trainX = np.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = np.reshape(testX, (testX.shape[0], look_back, 1))
# ===================================
# 构建和训练LSTM模型
# ===================================
# 构建LSTM模型
model = Sequential() # 创建序列模型
model.add(LSTM(5, input_shape=(look_back, 1))) # 添加LSTM层(5个神经元,输入形状为(时间步=1, 特征数=1))
model.add(Dense(1)) # 添加全连接输出层
model.compile(loss='mean_squared_error', optimizer='adam') # 编译模型(均方误差损失,Adam优化器)
model.fit(trainX, trainY, epochs=150, batch_size=2, verbose=2) # 训练模型(100轮,批量大小2)
# 保存并加载模型
model_path = r"D:\Python_demo\Time Series\LSTM\lstm_model.h5"
model.save(model_path)
model = load_model(model_path)
# ===================================
# 预测与反归一化
# ===================================
# 对训练集和测试集进行预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 反归一化(将预测结果还原到原始数据范围)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
# ===================================
# 可视化结果
# ===================================
# 绘制训练集结果
plt.figure(figsize=(10, 6))
plt.plot(trainY, label="训练实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(trainPredict[1:], label="训练预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("训练集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.legend()
plt.show()
# 绘制测试集结果
plt.figure(figsize=(10, 6))
xx = np.linspace(0, len(testY), len(testY))
plt.plot(testY, label="测试实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(testPredict, label="测试预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("测试集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.xlim(0, 18.5)
plt.ylim(0, 100)
plt.legend()
# 添加数据标签
for x, y in zip(xx, testY):
plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)
for x, y in zip(xx, testPredict):
plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)
plt.show()
# ===================================
# 模型评估
# ===================================
# 计算评估指标
mae = mean_absolute_error(testPredict, testY)
rmse = np.sqrt(mean_squared_error(testPredict, testY))
r2 = r2_score(testPredict, testY)
print('测试集评估指标:')
print('MAE: %.3f' % mae)
print('RMSE: %.3f' % rmse)
print('R²: %.3f' % r2)
![[Windows] 轻量级景好鼠标录制器 v2.1 单文件版,支持轨迹+鼠标键盘录制复刻](https://i-blog.csdnimg.cn/direct/16ee1cbf2f1e4d399dc7ed48bcf73b64.png)


![网络安全信息收集[web子目录]:dirsearch子目录爆破全攻略以及爆破字典结合](https://i-blog.csdnimg.cn/direct/8723c67eafb447c6909893a91b17cf03.jpeg)















