协处理器概念
一、协处理器有两种: observer 和 endpoint
1、observer协处理器
Observer 类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子, 在固定的事件发生时被调用。比如: put 操作之前有钩子函数 prePut,该函数在 put 操作执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
以 Hbase2.0.0 版本为例,它提供了三种观察者接口:
RegionObserver:提供客户端的数据操纵事件钩子: Get、 Put、 Delete、 Scan 等
WALObserver:提供 WAL 相关操作钩子。
MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。
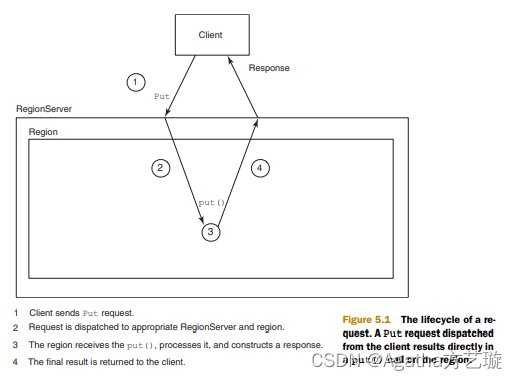
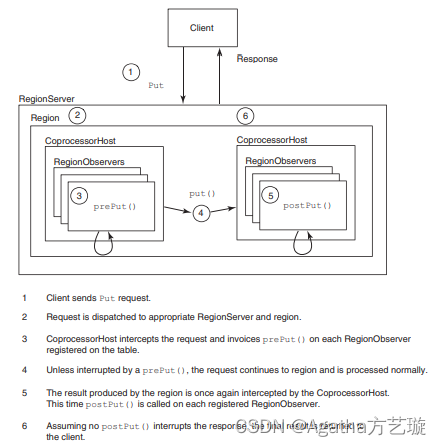
到 0.96 版本又新增一个 RegionServerObserver下图是以 RegionObserver 为例子讲解 Observer 这种协处理器的原理:
客户端发起get请求
该请求被分派给合适的RegionServer和Region
coprocessorHost拦截该请求,然后在该表上登记的每个RegionObserer上调用preGet()
如果没有被preGet拦截,该请求继续送到Region,然后进行处理
Region产生的结果再次被coprocessorHost拦截,调用posGet()处理
加入没有postGet()拦截该响应,最终结果被返回给客户端
2、endpoint 协处理器
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作
如果没有协处理器,当用户需要找出一张表中的最大数据,即max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执 行,势必效率低下。
利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内 执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多
协处理器 Java API
一、pom 配置
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.4</version>
</dependency>
二、在自定义包里创建类
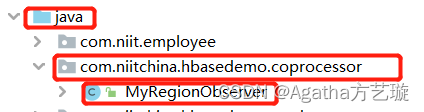
在此文件包名为 com.niitchina.hbasedemo.coprocessor,类名为MyRegionObserver,此路径与名字与后面配置有密切联系,若想偷懒可以完全跟随。
三、写入代码
package com.niitchina.hbasedemo.coprocessor;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.Coprocessor;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.*;
import org.apache.hadoop.hbase.regionserver.FlushLifeCycleTracker;
import org.apache.hadoop.hbase.regionserver.InternalScanner;
import org.apache.hadoop.hbase.regionserver.Store;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.wal.WALEdit;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
import java.util.Optional;
public class MyRegionObserver implements RegionObserver,RegionCoprocessor {
@Override
public Optional<RegionObserver> getRegionObserver() {
return Optional.of(this);
}
private static void outInfo(String str){
try {
FileWriter fw = new FileWriter("/training/hbase-2.2.4/coprocessor.txt",true);
fw.write(str + "\r\n");
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void start(CoprocessorEnvironment env) throws IOException {
RegionCoprocessor.super.start(env);
outInfo("MyRegionObserver.start()");
}
@Override
public void stop(CoprocessorEnvironment env) throws IOException {
}
@Override
public void preGetOp(ObserverContext<RegionCoprocessorEnvironment> e, Get get, List<Cell> results) throws IOException {
RegionObserver.super.preGetOp(e, get, results);
String rowkey = Bytes.toString(get.getRow());
// custom code here , this code will run before the get operation
outInfo("MyRegionObserver.preGetOp() : Before get operation rowkey = " + rowkey);
}
public void postGetOp(ObserverContext<RegionCoprocessorEnvironment> e, Get get, List<Cell> results) throws IOException {
RegionObserver.super.postGetOp(e, get, results);
String rowkey = Bytes.toString(get.getRow());
//custom code
outInfo("MyRegionObserver.postGetOp() : After Get Operation rowkey = " + rowkey);
}
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> c, Put put, WALEdit edit, Durability durability) throws IOException {
RegionObserver.super.prePut(c, put, edit, durability);
String rowkey = Bytes.toString(put.getRow());
// logic
outInfo("MyRegionObserver.prePut() : rowkey = " + rowkey);
}
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> c, Put put, WALEdit edit, Durability durability) throws IOException {
RegionObserver.super.postPut(c, put, edit, durability);
String rowkey = Bytes.toString(put.getRow());
// custom code
outInfo("MyRegionObserver.postPut() : rowkey = " + rowkey);
}
@Override
public void preDelete(ObserverContext<RegionCoprocessorEnvironment> e, Delete delete, WALEdit edit, Durability durability) throws IOException {
RegionObserver.super.preDelete(e, delete, edit, durability);
String rowkey = Bytes.toString(delete.getRow());
outInfo("MyRegionObserver.preDelete() : rowkey = " + rowkey);
}
@Override
public void postDelete(ObserverContext<RegionCoprocessorEnvironment> e, Delete delete, WALEdit edit, Durability durability) throws IOException {
RegionObserver.super.postDelete(e, delete, edit, durability);
String rowkey = Bytes.toString(delete.getRow());
// custom code
outInfo("MyRegionObserver.postDelete() : rowkey = " + rowkey);
}
}
四、项目打jar包
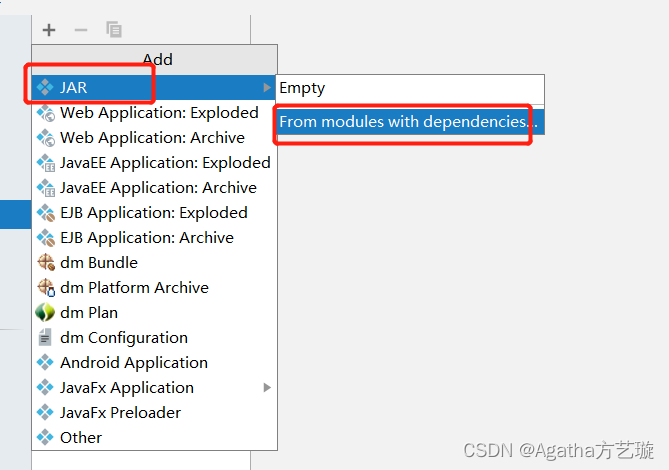
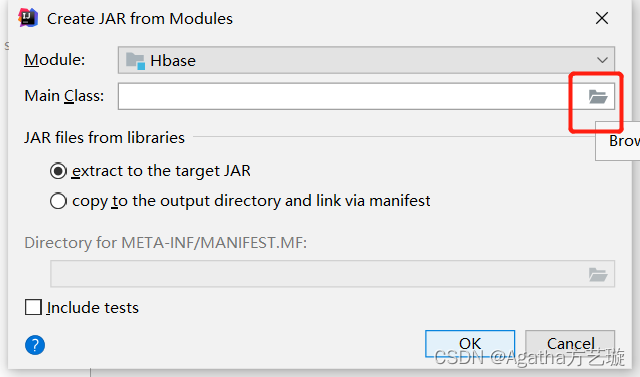
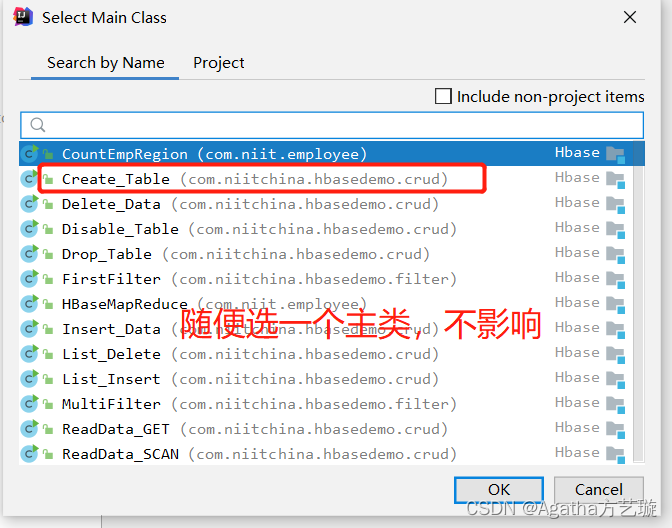
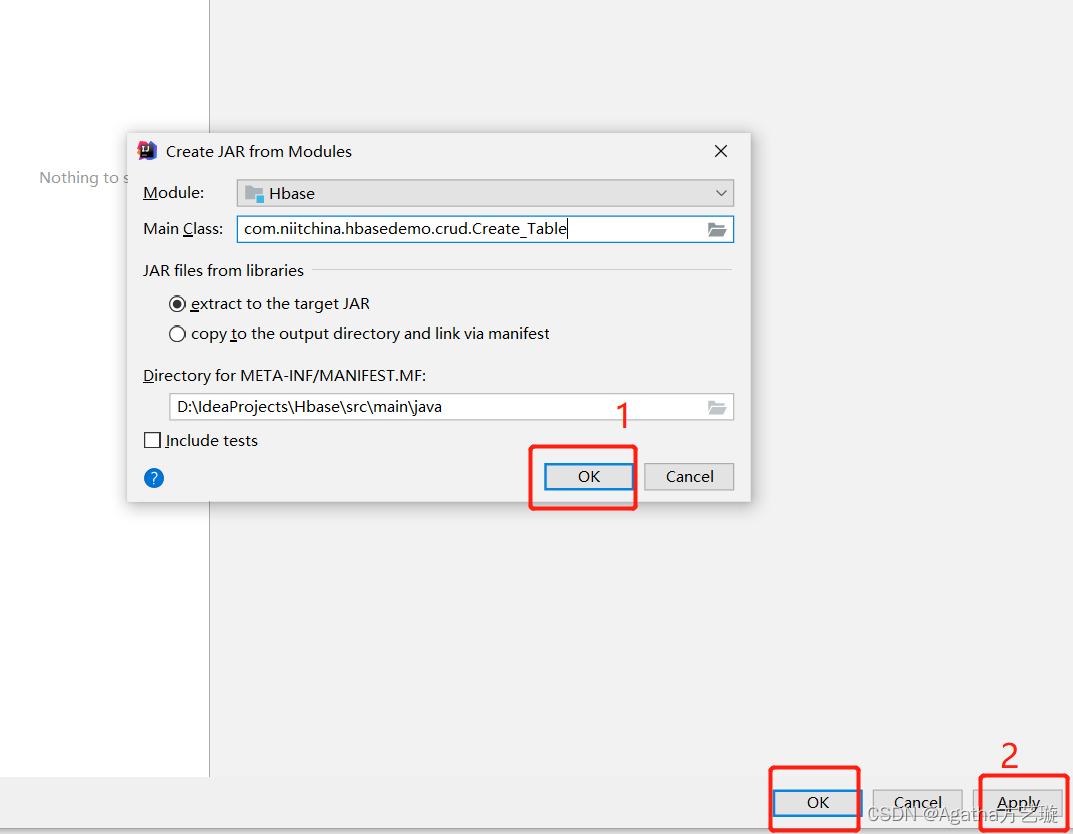
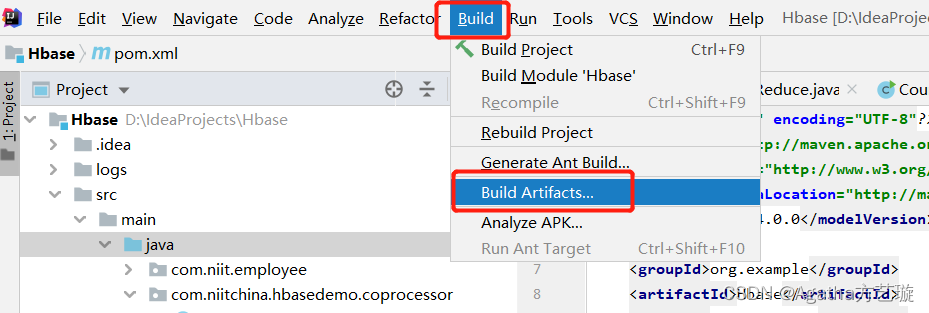
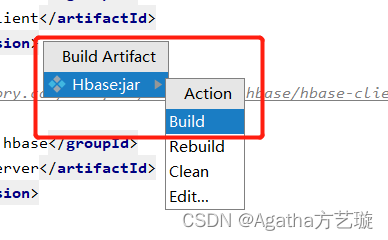


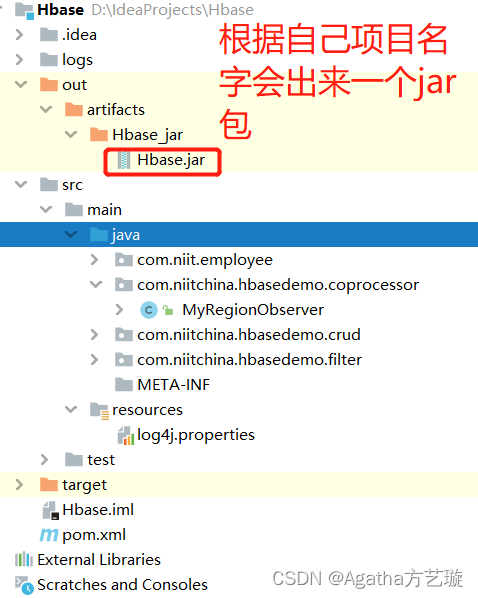
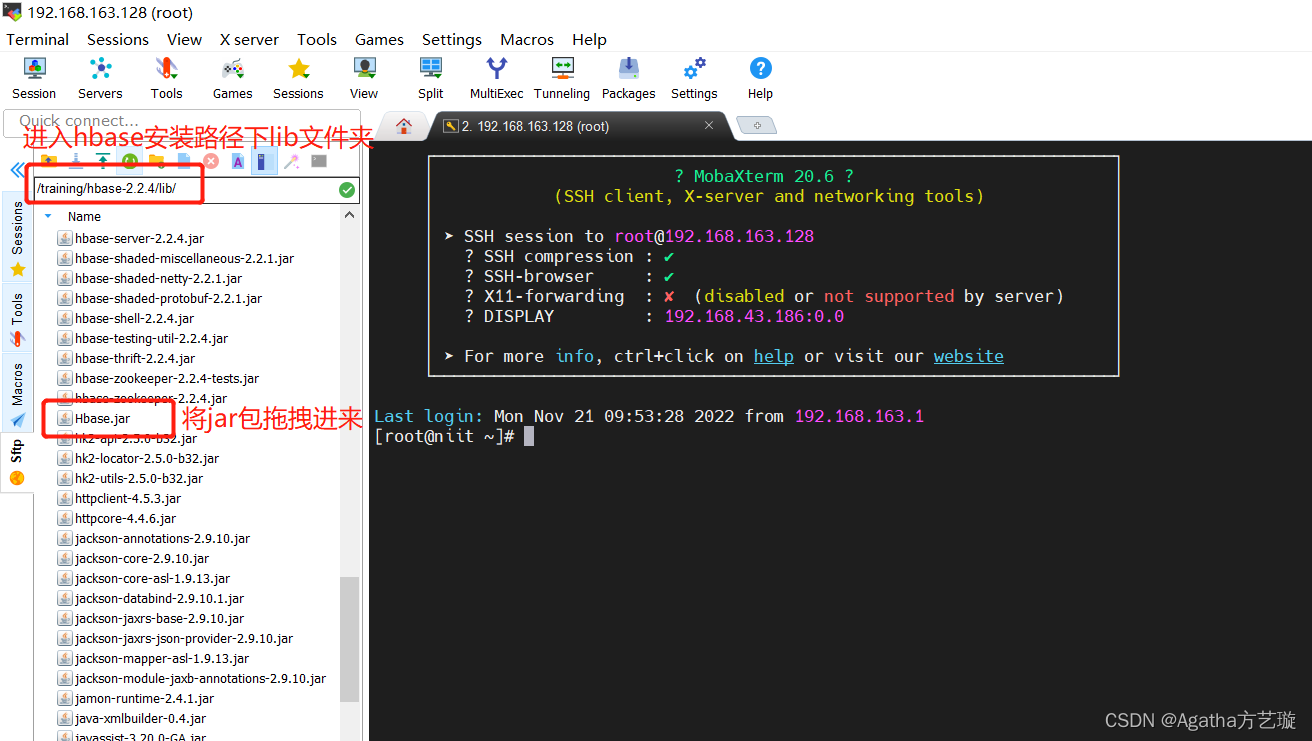
五、Hbase 文件配置
1、进入Hbase安装路径下conf文件夹对hbase-site.xml进行配置,com.niitchina.hbasedemo.coprocessor为包名,MyRegionObserver为类名,若上述步骤名称不同则这里需要更换具体内容。
<property>
<name>hbase.coprocessor.region.classes</name>
<value>com.niitchina.hbasedemo.coprocessor.MyRegionObserver</value>
</property>
2.、重启Hbase
六、运行插入、删除、查询get可以与协处理器连接
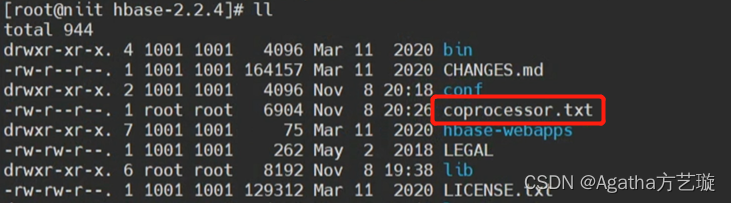
日志文件将会保存在自定义路径下,我们代码里设置的 /training/hbase-2.2.4,可以看到日志文件出来了
vi coprocessor.txt 可以看看里面日志,运行成功。




![PTA题目 计算分段函数[1]](https://img-blog.csdnimg.cn/661aa64181584fdfa0c56ecbdc51a336.png)