文章总结自视频:【1080P】安德烈·卡帕西:深入探索像ChatGPT这样的大语言模型|Andrej Karpathy_哔哩哔哩_bilibili
1. 准备训练集
详细的数据集准备方法可参考视频,或者huggingFace

2. 分词(Tokenizer)
分词(Tokenization) 是将连续的自然语言文本(如句子、段落)分割成有意义的独立单元(称为 “词” 或 “Token”)的过程。这些单元可以是词语、子词(如词缀)、字符甚至字节,具体取决于语言特性和模型需求。
分词的本质是将人类语言的 “模糊性” 转化为机器可计算的 “离散符号”,其质量直接决定了 NLP 系统的上限。

分词工具:https://tiktokenizer.vercel.app/
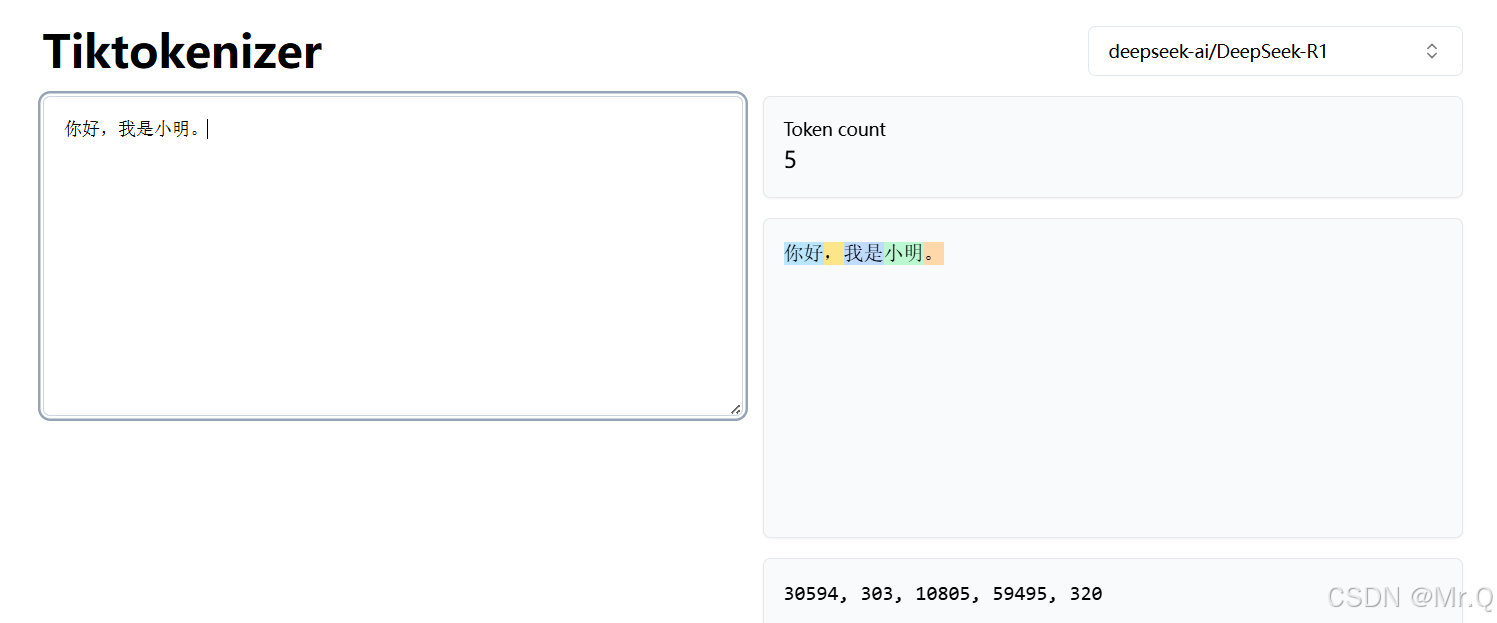
如下,gpt-4o分词工具,将"hello, how are you?"分成6个tokens,分别是:
24912, 11, 1495, 553, 481, 30
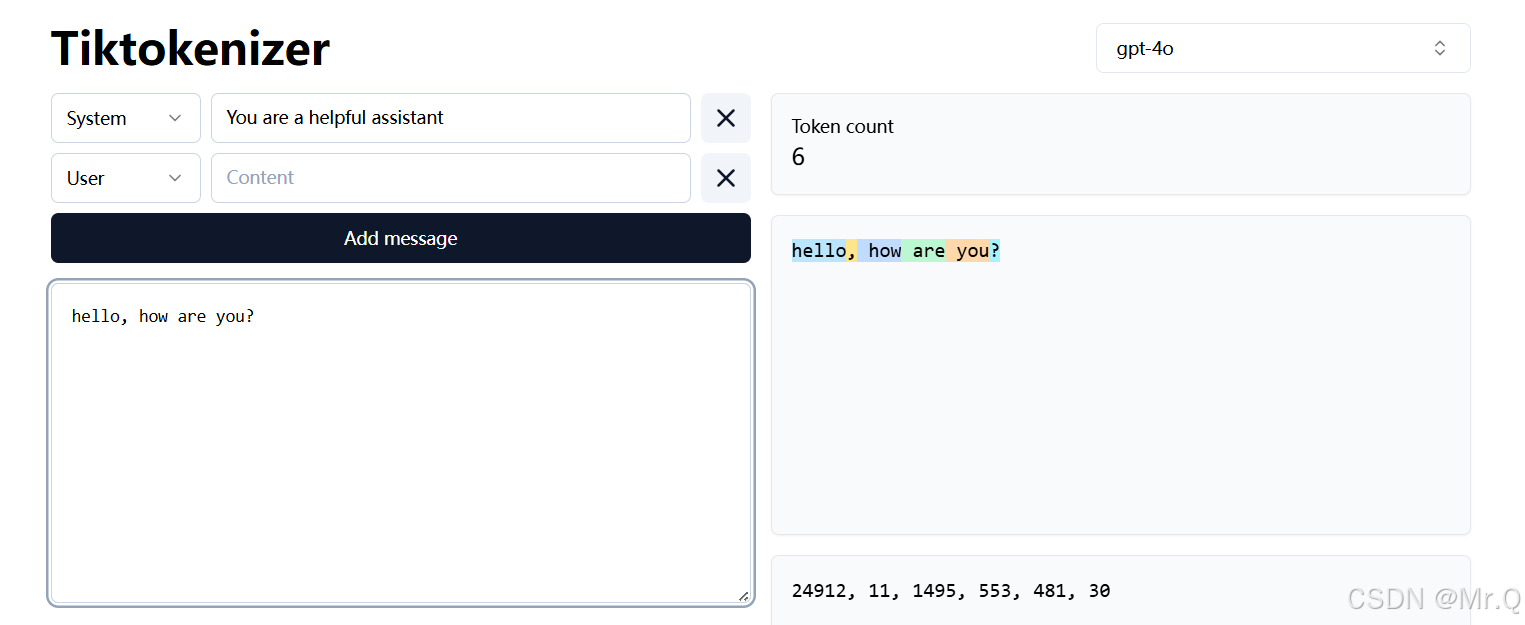
deepseek-r1分词情况(中文)如下。
那么一次分词器需要多少个不同的tokens来表示编码所有文本内容呢?gpt需要100277个。
3. 训练
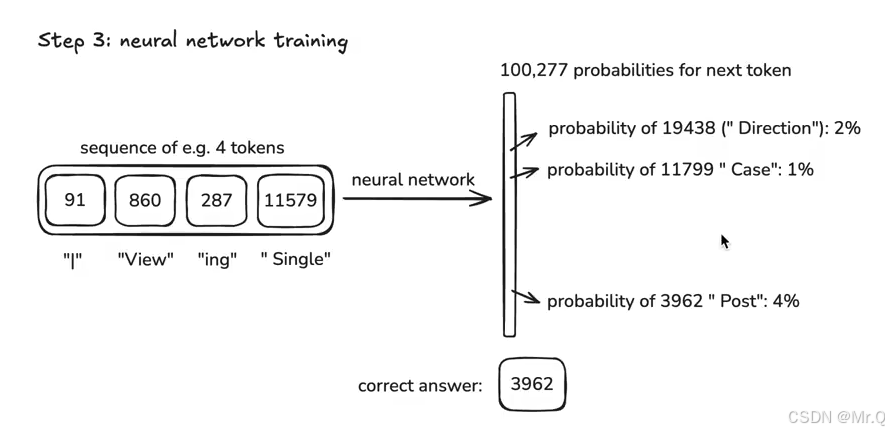
语言模型训练的核心逻辑:基于上下文序列,预测下一个 token 的概率分布,并通过监督学习优化模型参数。
如下上下文输入的是前4个tokens(逐渐增加输入tokens,理论上可以无限多个,但是实际计算量太大,会限制输入个数作为最大上下文长度),下一个token是3962,预测此token的概率。网络输出的是一个 100277维度的概率分布,每一个位置表示下一个是对应token的概率。如下3962位置的概率是4%,目标是通过有监督学习使得此概率越大越好。
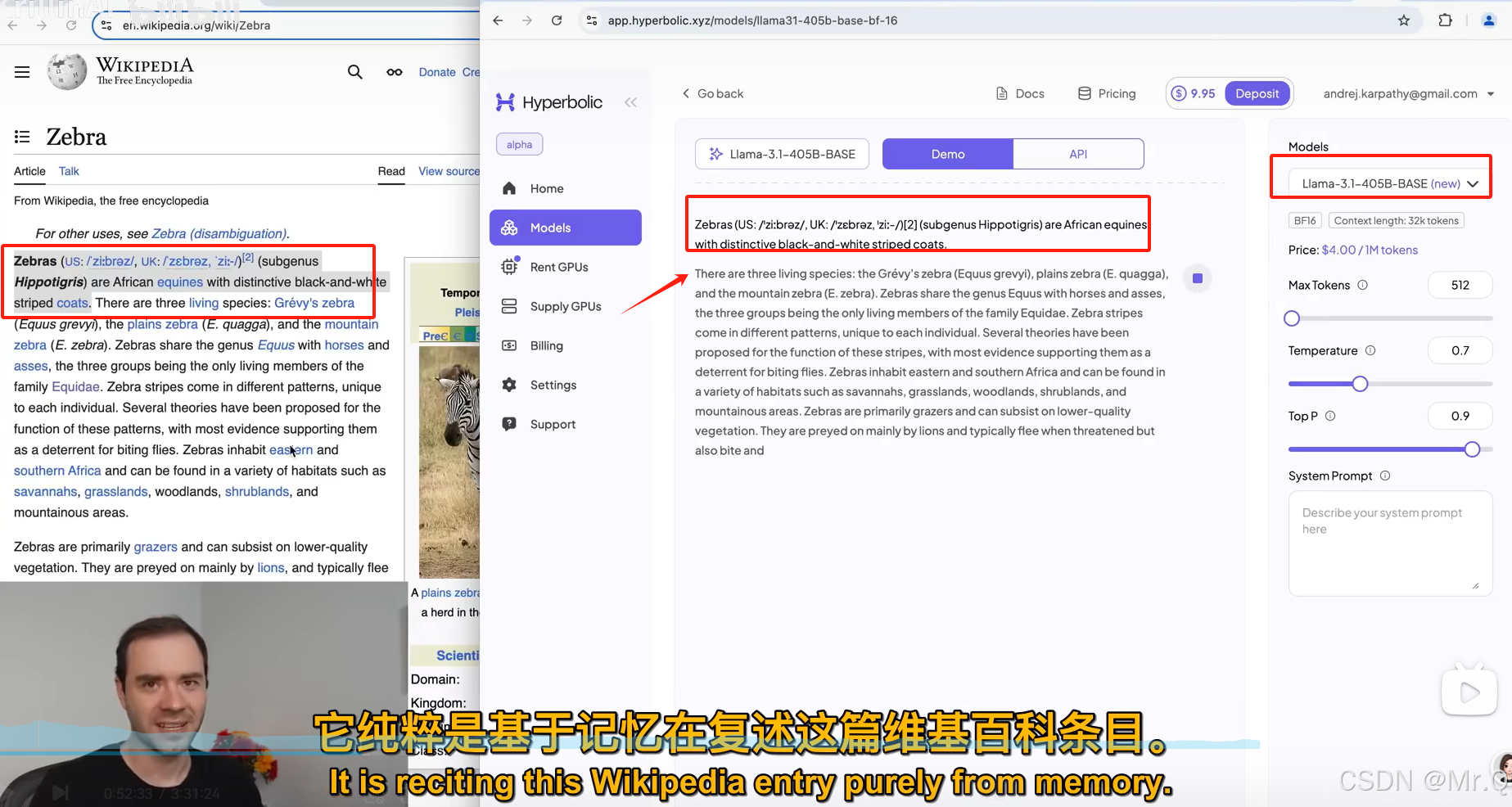
注意:这样训练得到的只是一个base model;他只会根据输入,随机概率出后续内容。它不是instruct model。如下图所示,直接复制输入维基百科内容,base model会填充后续的维基百科内容内容。这些base model非常删除记忆训练的数据,所以输入前面的内容,他会补充后续的内容。
4. 推理
LLM 的自回归特性:生成下一个 Token 时,始终基于已生成的历史内容,逐步扩展序列,直至满足终止条件(如达到指定长度或生成结束符)。


















![[数据结构]排序之希尔排序( 缩小增量排序 )](https://i-blog.csdnimg.cn/direct/95fbbeccb48d4b5b92eff8571bfe6ec1.png)
