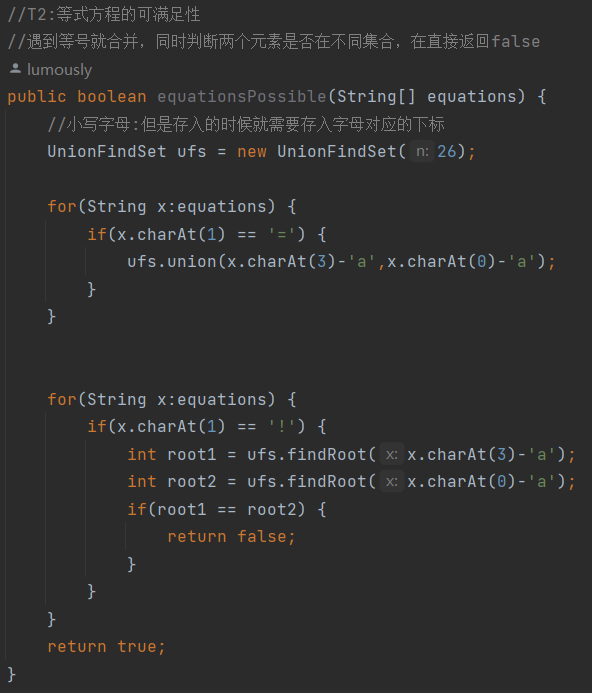
写在前面
由于合成数据目前是一个热门的研究方向,越来越多的研究者开始通过大模型合成数据来丰富训练集,为了能够从一个系统的角度去理解这个方向和目前的研究方法便写了这篇播客,希望能对这个领域感兴趣的同学有帮助! 欢迎点赞,收藏,关注!!!
第一次撰写时间: 20250304 17:27
第二次撰写时间: 20250305 08:55
未完待续!!!!
引言
大语言模型(Large Language Model)通过在大规模的语料上进行预训练,获得了强大地自然语言的理解和生成能力。随着OpenAI 提出 Scaling Law(通过增大数据量和模型参数量,可以得到更强的模型),研究者开始不断提高模型参数及数据量。但由于现实中的语料有限,所以越来越多的人开始关注合成数据。
起初,人们通过人工的方式进行标注数据,但这种方法由于成本高,且存在人类偏见(bias)。随着大模型能力的提升,人们开始关注于利用大语言模型去生成(合成)数据,用以进一步扩充数据集,提交数据集的多样性和丰富性。这种方法相较于人工方式,其成本较低且准确率也有所提高,所以越来越多的人开始利用大语言模型去合成数据以实现在下游任务上更好的性能表现。
所以本文将按照不同的分类方法对目前基于大模型的数据合成方法进行全面的介绍,主题包括:
- 方法论
通过总结现存研究的方法总结出一个统一的数据合成框架
重点关注利用大语言模型合成数据的各类方法,并强调各类方法在合成数据的两大关键质量指标做出的贡献:
- 真实性(Faithfulness): 为了提供有效的监督,生成的数据必须首先在逻辑和语法上是连贯的。然而,大型语言模型(LLMs)固有的幻觉和长尾知识分布问题可能会给生成的结果带来显著的噪音,表现为事实错误、不正确的标签或无关的内容。当生成长篇、复杂或特定领域的数据时,这些问题会更加明显。
- 多样性(Diversity):为了提高模型在下游任务的泛化能力,避免过拟合,数据的多样性非常重要。但是由于大模型自有的偏差,如果不进行控制,大模型生成的数据是很单一的,所以需要进一步控制。
问题定义
首先我们来定义一下问题生成的大致形式:
D
gen
←
M
p
(
T
,
D
sup
)
,
\mathcal{D}_{\text{gen}} \leftarrow \mathcal{M}_{\mathcal{p}}(\mathcal{T},\mathcal{D}_{\text{sup}}),
Dgen←Mp(T,Dsup),其中
D
g
e
n
\mathcal{D}_{gen}
Dgen表示生成的合成数据集,
M
\mathcal{M}
M表示给定的大模型,
p
p
p表示输入到大模型内的提示词 promot,
D
sup
\mathcal{D}_{\text{sup}}
Dsup表示小部分的有标签的数据集,后续可以通过 few-shot的形式给大模型进行更好的生成,从而提高合成数据集的质量。
为了对生成的数据集的质量进行控制, 保证该数据集存在较少的噪声且保证生成的数据的分布与真实的数据分布相差不要太远,保证了后续下游任务上数据的质量。此处重点关注两个部分(例如上述所说),真实性和多样性。所以后续的算法流程是为了更好地实现这两个目标
整体框架
整体的框架可以分为:Data Generation,Data Curation, Data Evaluation。 Data Generation重点关注数据合成的方法和流程;Data Curation重点关注为了保证数据的质量,需要把一些不好的数据(例如:具有假标签,相似度较高的数据)进行过滤,介绍各种目前主流的对数据质量控制的方法。 Data Evaluation重点介绍对数据质量的评估方法,包括最近很火的 LLM-as-a-judge 和一些通用的 benchmark评估。
Data Generation
Prompt Engineering:
基于提示词工程的方法很简单,就是通过设计一个很好的提示词在帮助大模型能够更好的遵循人类的指令而合成数据。提示词可以形式化表示为:
p
←
(
e
task
,
e
condition
,
e
demo
)
,
\mathcal{p} \leftarrow(e_{\text{task}},e_{\text{condition}},e_{\text{demo}}),
p←(etask,econdition,edemo),其中
p
\mathcal{p}
p表示为设计好的提示词,
e
task
e_{\text{task}}
etask表示为与特定任务相关的话术(类似于:rule-play的方式,你是一个在 xxx领域的专家,负责生成 xxx的数据);
e
condition
e_{\text{condition}}
econdition是为了控制问题生成的多样性从而给定生成问题的特定限制或条件(类似于生成数据的类型:复杂等),原因在于:如果不给大模型生成特定的限制或条件,大模型倾向于生成一些相似且简单的问题,不利于合成数据集的多样性。
e
demo
e_{\text{demo}}
edemo是利用大模型 few-shot或 In-context learning的能力,给大模型示例已生成与真实数据更加相似的数据。
- Task Specification:
任务特定的提示词就不过多说了,就是与特定任务相关的一些信息,包括上述说到的 rule-play,与特定任务相关的外部知识等等 - Conditional Prompting:
合成数据生成的关键是确保足够的多样性,因为直接提示大语言模型(LLMs)为某些任务生成数据,往往会导致输出高度重复,即使使用较高的问题进行采样。为了解决这个问题,一个广泛采用的策略是条件提示,它明确而具体地向大语言模型传达所需的数据类型。条件提示的核心在于通过一系列条件-值对来界定目标数据:
e condition = { ( c 1 , v 1 ) , ( c 2 , v 2 ) , ( c 3 , v 3 ) . . . ( c k , v k ) } . e_{\text{condition} = \{(c_1,v_1),(c_2,v_2),(c_3,v_3)...(c_k,v_k)\}}. econdition={(c1,v1),(c2,v2),(c3,v3)...(ck,vk)}.
通过组合不同的条件的键值对可以得到我们定义的多样性,通过这样我们能够显式地迫使大模型生成更多丰富的合成数据。
目前对于条件提示的研究主要集中在两个方面:
(1)Conditioning Scope.
这个其实在研究的是上述 e condition e_{\text{condition}} econdition中的 { c 1 , c 2 , … , c k } \{c_1,c_2,\ldots,c_k\} {c1,c2,…,ck}也就是条件的键有哪些,在对于分类问题中,我们可以根据特定地标签作为键。在后续的研究中提出,使用更细致的属性(比如主题、长度和风格进行条件提示,可以因为可能的属性组合数量庞大,从而带来更多样化的生成结果,这也适用于开放式数据。
(2)Conditioning Value.
在定义了条件范围之后,我们还需要给每个条件分配具体的值。对于分类问题来说,就可以很简单地从标签值内进行采样得到。其他的一些方法:从外部知识图谱中检索条件实例;利用大型语言模型来生成多样化的实例用于条件提示;此外,提示模板E也可以被视为一种特殊的条件。研究表明,在整个生成过程中加入一定程度的随机性的模板可以增强生成内容的多样性 - In-Context Learning:
利用大模型上下文学习能力进行 few-shot的学习。这也是控制了生成数据的真实性,通过给大模型几个示例是一种很简单但却很高效的方式。
Multi-Step Generation
在前面,我们介绍了一种最常见的方式:利用设计更好的提示词来提高大模型的能力。 然而,在大多数情况下,由于缺乏足够的推理能力,期望大型语言模型在一次参考中生成整个所需的数据集是不现实的,特别是当目标数据具有复杂的结构或语义时。为了解决这个问题,一种常见的策略是多步骤生成,通过这种方式,整体生成过程被手动分解为一系列更简单的子任务
T
1
:
k
T_{1:k}
T1:k。
所以可以分解为一步步的方式,首先对每一个子任务
T
i
T_i
Ti生成 ,所以问题生成就可以形式化为:
D
i
←
M
p
i
i
(
T
i
,
D
0
:
i
−
1
)
,
i
=
1
,
2
,
…
,
k
,
\mathcal{D}_i \leftarrow \mathcal{M}^i_{\mathcal{p_i}}(T_i,\mathcal{D}_{0:i-1}),i=1,2,\ldots,k,
Di←Mpii(Ti,D0:i−1),i=1,2,…,k, 其中
D
0
:
i
−
1
\mathcal{D}_{0:i-1}
D0:i−1表示为在生成第
i
i
i步或子任务的时候,可以利用前
i
−
1
i-1
i−1步生成的内容为前提继续生成。具体来说,任务分解有两种常见的策略:样本分解(Sample-Wise Decomposition)和数据集分解(Dataset-Wise Decomposition),主要是为了提高不同尺度上合成数据的质量。
- Sample-wise Decomposition:
对于一些推理任务等需要多步才能生成一个样本的方式,我们可以把一个样本的生成过程分解为多步,每一步只生成样本的一部分,所以最后完整的 D gen \mathcal{D}_{\text{gen}} Dgen可以表示为:
D gen ← ( D 1 , D 2 , … , D k ) , \mathcal{D}_{\text{gen}} \leftarrow (\mathcal{D}_1,\mathcal{D}_2,\ldots,\mathcal{D}_k), Dgen←(D1,D2,…,Dk), - Dataset-wise Decomposition
有时候整体合成的数据集不可能一次性生成的非常好,要生成一系列这样的数据,最终能形成一个具有良好多样性和领域覆盖率的dataset,需要长期的规划。所以我们可以通过一次合成数据之后放到下游任务上,看看表现,把那些表现不好的数据在下一次合成的时候进行补充,让下游任务在这类数据上继续训练,提高其在这类数据上的表现。所以这类分解可以形式化表述为:
D gen = ⋃ i = 1 k D i , \mathcal{D}_{\text{gen}}=\bigcup_{i=1}^k \mathcal{D_i}, Dgen=i=1⋃kDi,
具体来说,在每一轮迭代中都针对下游模型在之前生成数据上训练的性能,针对最常被错误标记的类别进行优化;一种先生成再扩展的范式,以此来提高整个数据集的多样性。还有一些方法利用特定的数据结构来模拟数据生成的路径,把领域空间建模为树状结构,并在树遍历的过程中不断优化生成数据,以此来促进生成数据的专化和领域覆盖。
Data Curation
因为合成的数据虽然通过上述方式提高了其真实性和多样性。在做了前面的步骤之后,可能会过度生成溢出和理论上无限的数据
D
gen
\mathcal{D}_{\text{gen}}
Dgen。但是,这些数据集通常包含相当一部分的噪音、无价值甚至是有害的样本,这主要是由两个原因造成的。首先,由于幻觉问题,LLMs不可避免地会产生带有错误标签的损坏样本。其次,包含模糊描述的不当提示可能会让模型生成不相关或重复的样本。因此,如果不经过适当处理就直接使用这些低质量的数据,可能会产生很大的负面影响。
为了解决这个问题,已经研究了许多数据管理方法,这些方法主要分为两大类:高质量样本过滤(hige-quality sample filtering)和标签增强(label enhancement),如下所述。

High-Quality Sample Filtering
因为大模型生成的数据集总是会有一些错误,所以我们需要进行过滤,得到一个更加干净且有用的数据集
D
curated
⊂
D
gen
\mathcal{D}_{\text{curated}} \subset \mathcal{D}_{\text{gen}}
Dcurated⊂Dgen,然后基于这种思想的方法可以分为两种:heuristic criteria,re-weighting functions 去过滤或重排名(rerank)这些合成的数据。
- heuristic criteria: 通过某一些特定的指标(启发式规则)等方式,并设定阈值直接筛选出其中比较重要且干净的数据集。
- re-weighting functions: 这类方法认为合成的数据可能是有一些是有噪声的数据,但是这类数据也是有价值的,不应该直接被过滤掉而不使用他们,而是通过给不同的数据赋予权重的方式以实现不同数据的重要性的体现。
Label Enhancement
标签增强方法努力纠正生成样本中可能存在的错误标注。因为存在确认偏误,大型语言模型很难发现自己犯的错误。为了解决这个问题,最近的研究要么依赖人工干预,要么引入学生模型来实现无人工的知识的提炼。
- Human Intervention
一个简单的标签修正策略是让人类重新标注受损的样本。尽管这些方法很简单,但在实际应用中可能会导致相当高的标注成本,并且不太现实。 - Auxiliary Model
为了降低标注成本,开发了一种更务实的无人工干预范式,该范式涉及用于知识蒸馏和标签精炼的辅助学生模型。这些方法依赖于学生模型的弱监督能力,并假设从大型语言模型(LLM)教师中蒸馏出的学生模型可以生成更优质的标签。开创性工作FreeAL(Xiao等,2023)提出了一个协作框架,在这个框架中,学生模型被用来从弱标注中提取高质量的任务相关知识,并反馈给LLM进行标签精炼。MCKD(Zhao等,2023a)设计了一个多阶段的蒸馏流程,通过数据拆分训练和跨分区标注来避免对噪声标签的过拟合。
随着LLM能力和可用性的不断扩展,辅助学生模型的结合将作为一种成本效益高的替代方案,在人类干预中发挥更重要的作用。
Data Evaluation

在经过上述的两个过程,我们已经得到了合成的数据集,但是为了保证在下游任务上的表现,还需要对合成的数据进行评估,目前评估的方法主要分为两类:直接和非直接的方法。
- 直接评估(direct evaluation)
检查真实性(Faithfulness): 一种最方便的方式就是从中采样一些样本,然后给人类专家进行评估,样本量越大对其评估就越准确,但这类方法的弊端就是人工成本很大。所以也有一些研究利用更大的模型进行检测(LLM-as-a-judge)
检查多样性(Diversity):数据多样性的量化主要使用词汇统计和样本相关性计算。词汇统计,比如词汇量和N-gram频率(Yu等人,2023b),是一种简单直观的方法。但是,它们很难捕捉到数据集的语义信息。样本相关性的计算有效地弥补了这一不足。最常见的样本相关性度量是基于余弦相似度(Wang等人,2023b)和样本距离(Chung等人,2023b),这些方法能更好地捕捉到数据集的上下文和语义多样性。 - 间接评估(indirect evaluation)
Benchmark:核心思想在于在合成的数据集上对下游任务的模型进行训练,然后模型的表现也从侧面反应了生成的数据的质量。 对于模型性能的评估有一些方法,包括:TruthfulQA用于模型在回答真实问题上的能力。NIV2用于评估模型的自然语言的理解能力和推理能力。
Open Evauation:有的时候由于一些问题没有准确的答案,所以就要用到辅助大模型来进行评估,所以目前的研究开始设计如何能让大模型评估的更加准确,例如:response ranking,four-level rating system。然而,通用型大型语言模型可能缺乏足够的知识来完成特定领域的任务,这阻碍了它们提供有效的评估。所以,为了评估目的收集人类评估数据,对开源模型进行微调,这在现实场景中是一个很重要的做法。
- 合成数据的方式
总结合成数据的方式,类似于:data creation, data labeling data reforment Co-annotation
- Data Creation: 通过 few-shot的形式,利用少量的数据prompt大模型合成数据;
- Data Labeling: 对已有的数据进行标注;
- Data Reforment: 对先有的数据进行改写其他的数据,以增大数据集的多样性和丰富性;
- Co-annotation: human-llm 协作的方式,类似于:先用大模型生成,然后挑出其中不好的数据,在人工检查。
- 基于合成数据的学习范式
目前利用合成的数据所对下游任务任务进行训练或学习的用法,包括 in-context learning suprised instruction tuning,performance alignment 等
目前大模型的学习或训练以提高下游任务的性能方法,可以包括:不用训练的方式:上下文学习(few-shot)的方式进行;微调(训练):sft(surprised fine-tuning),performance alignment(PA)等。