目录
一、509. 斐波那契数 - 力扣(LeetCode)
算法代码:
1. 动态规划 (fib 函数)
初始化:
递推计算:
返回结果:
2. 记忆化搜索 (dfs 函数)
备忘录初始化:
递归终止条件:
递归计算:
返回结果:
3. 代码优化建议
4. 优化后的动态规划代码
5. 优化后的记忆化搜索代码
总结
二、 62. 不同路径 - 力扣(LeetCode)
算法代码:
1. 问题描述
2. 动态规划 (uniquePaths 函数)
思路:
状态定义:
初始条件:
状态转移方程:
边界条件:
最终结果:
代码实现:
3. 记忆化搜索 (dfs 函数)
思路:
备忘录定义:
递归终止条件:
递归计算:
记录结果:
代码实现:
4. 代码优化建议
动态规划的空间优化
记忆化搜索的边界处理
5. 总结
三、 300. 最长递增子序列 - 力扣(LeetCode)
算法代码:
1. 问题描述
示例:
2. 动态规划 (lengthOfLIS 函数)
思路:
状态定义:
初始条件:
状态转移方程:
填表顺序:
最终结果:
代码实现:
3. 记忆化搜索 (dfs 函数)
思路:
备忘录定义:
递归终止条件:
递归计算:
记录结果:
代码实现:
4. 代码优化建议
动态规划的优化
记忆化搜索的边界处理
5. 总结
四、 375. 猜数字大小 II - 力扣(LeetCode)
算法代码:
1. 问题描述
2. 记忆化搜索 (dfs 函数)
思路:
状态定义:
递归终止条件:
递归计算:
记录结果:
代码实现:
3. 动态规划的思路
动态规划的状态转移方程:
动态规划的填表顺序:
动态规划的代码实现:
4. 代码优化建议
记忆化搜索的优化
动态规划的空间优化
5. 总结
五、329. 矩阵中的最长递增路径 - 力扣(LeetCode)
算法代码:
1. 问题描述
2. 代码思路
(1)变量定义
(2)主函数 longestIncreasingPath
(3)DFS 函数 dfs
递归终止条件:
递归计算:
记录结果:
3. 代码实现
4. 代码优化建议
(1)边界检查优化
(2)空间优化
(3)方向数组优化
5. 总结
DFS + 记忆化搜索:
时间复杂度:
空间复杂度:
一、509. 斐波那契数 - 力扣(LeetCode)

算法代码:
class Solution {
public:
int memo[31]; // memory 备忘录
int dp[31];
int fib(int n) {
// 动态规划
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++)
dp[i] = dp[i - 1] + dp[i - 2];
return dp[n];
}
// 记忆化搜索
int dfs(int n) {
if (memo[n] != -1) {
return memo[n]; // 直接去备忘录⾥⾯拿值
}
if (n == 0 || n == 1) {
memo[n] = n; // 记录到备忘录⾥⾯
return n;
}
memo[n] = dfs(n - 1) + dfs(n - 2); // 记录到备忘录⾥⾯
return memo[n];
}
}; 这段代码实现了计算斐波那契数列的第 n 项,使用了两种不同的方法:动态规划和记忆化搜索。下面是对代码的思路和实现细节的详细解释:

1. 动态规划 (fib 函数)
动态规划是一种自底向上的方法,通过递推公式逐步计算斐波那契数列的值。
-
初始化:
-
dp[0] = 0:斐波那契数列的第 0 项是 0。 -
dp[1] = 1:斐波那契数列的第 1 项是 1。
-
-
递推计算:
-
从第 2 项开始,每一项的值等于前两项的和,即
dp[i] = dp[i - 1] + dp[i - 2]。 -
通过循环从
i = 2到i = n,逐步计算每一项的值。
-
-
返回结果:
-
最终返回
dp[n],即第n项的值。
-
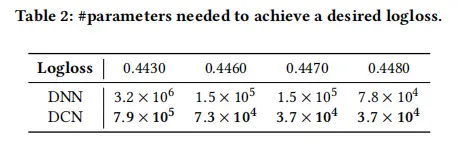
2. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算斐波那契数列的值,并使用备忘录 (memo) 来避免重复计算。
-
备忘录初始化:
-
在调用
dfs函数之前,需要将memo数组初始化为-1,表示尚未计算过的值。
-
-
递归终止条件:
-
如果
n == 0或n == 1,直接返回n,并将结果记录到备忘录中。
-
-
递归计算:
-
如果
memo[n]不为-1,说明已经计算过,直接返回memo[n]。 -
否则,递归计算
dfs(n - 1)和dfs(n - 2),并将结果相加,记录到备忘录中。
-
-
返回结果:
-
最终返回
memo[n],即第n项的值。
-
3. 代码优化建议
-
备忘录初始化:在
dfs函数中,memo数组应该在调用dfs之前初始化为-1,否则可能会导致错误的结果。 -
空间优化:对于动态规划方法,可以只使用两个变量来存储前两项的值,而不需要维护整个
dp数组,从而将空间复杂度从O(n)降低到O(1)。
4. 优化后的动态规划代码
int fib(int n) {
if (n == 0) return 0;
if (n == 1) return 1;
int prev2 = 0; // dp[0]
int prev1 = 1; // dp[1]
int result = 0;
for (int i = 2; i <= n; i++) {
result = prev1 + prev2;
prev2 = prev1;
prev1 = result;
}
return result;
}5. 优化后的记忆化搜索代码
int memo[31]; // 备忘录
int dfs(int n) {
if (memo[n] != -1) {
return memo[n];
}
if (n == 0 || n == 1) {
memo[n] = n;
return n;
}
memo[n] = dfs(n - 1) + dfs(n - 2);
return memo[n];
}
int fib(int n) {
memset(memo, -1, sizeof(memo)); // 初始化备忘录
return dfs(n);
}总结
-
动态规划:适合自底向上的计算,空间复杂度可以优化到
O(1)。 -
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
二、 62. 不同路径 - 力扣(LeetCode)

算法代码:
class Solution {
public:
int uniquePaths(int m, int n) {
// 动态规划
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
dp[1][1] = 1;
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++) {
if (i == 1 && j == 1)
continue;
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
return dp[m][n];
// 记忆化搜索
// vector<vector<int>> memo(m + 1, vector<int>(n + 1));
// return dfs(m, n, memo);
}
int dfs(int i, int j, vector<vector<int>>& memo) {
if (memo[i][j] != 0) {
return memo[i][j];
}
if (i == 0 || j == 0)
return 0;
if (i == 1 && j == 1) {
memo[i][j] = 1;
return 1;
}
memo[i][j] = dfs(i - 1, j, memo) + dfs(i, j - 1, memo);
return memo[i][j];
}
};这段代码解决了机器人从网格左上角到右下角的唯一路径数问题,使用了两种方法:动态规划和记忆化搜索。以下是代码的思路和实现细节的详细解释:
1. 问题描述
在一个 m x n 的网格中,机器人从左上角 (1, 1) 出发,每次只能向右或向下移动,问到达右下角 (m, n) 有多少条唯一的路径。

2. 动态规划 (uniquePaths 函数)
动态规划是一种自底向上的方法,通过递推公式逐步计算每个位置的路径数。
思路:
-
状态定义:
-
dp[i][j]表示从起点(1, 1)到达位置(i, j)的唯一路径数。
-
-
初始条件:
-
起点
(1, 1)的路径数为 1,即dp[1][1] = 1。
-
-
状态转移方程:
-
对于位置
(i, j),机器人只能从上方(i-1, j)或左方(i, j-1)到达。 -
因此,
dp[i][j] = dp[i-1][j] + dp[i][j-1]。
-
-
边界条件:
-
如果
i == 1 && j == 1,跳过计算,因为初始值已经设置为 1。 -
如果
i == 0或j == 0,表示越界,路径数为 0。
-
-
最终结果:
-
返回
dp[m][n],即从(1, 1)到(m, n)的唯一路径数。
-
代码实现:
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0)); // 初始化 dp 数组
dp[1][1] = 1; // 起点路径数为 1
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (i == 1 && j == 1) continue; // 跳过起点
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]; // 状态转移
}
}
return dp[m][n]; // 返回结果
}3. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算每个位置的路径数,并使用备忘录 (memo) 来避免重复计算。
思路:
-
备忘录定义:
-
memo[i][j]表示从位置(i, j)到终点(m, n)的唯一路径数。
-
-
递归终止条件:
-
如果
i == 1 && j == 1,表示到达起点,路径数为 1。 -
如果
i == 0或j == 0,表示越界,路径数为 0。
-
-
递归计算:
-
如果
memo[i][j]已经计算过,直接返回memo[i][j]。 -
否则,递归计算从上方
(i-1, j)和左方(i, j-1)的路径数,并相加。
-
-
记录结果:
-
将计算结果记录到
memo[i][j]中,避免重复计算。
-
代码实现:
int dfs(int i, int j, vector<vector<int>>& memo) {
if (memo[i][j] != 0) {
return memo[i][j]; // 如果已经计算过,直接返回
}
if (i == 0 || j == 0) {
return 0; // 越界,路径数为 0
}
if (i == 1 && j == 1) {
memo[i][j] = 1; // 起点,路径数为 1
return 1;
}
memo[i][j] = dfs(i - 1, j, memo) + dfs(i, j - 1, memo); // 递归计算
return memo[i][j];
}
int uniquePaths(int m, int n) {
vector<vector<int>> memo(m + 1, vector<int>(n + 1, 0)); // 初始化备忘录
return dfs(m, n, memo); // 调用记忆化搜索
}4. 代码优化建议
动态规划的空间优化
-
当前动态规划的空间复杂度为
O(m * n),可以优化为O(n)。 -
使用一维数组
dp,每次更新时覆盖旧值。
优化后的代码:
int uniquePaths(int m, int n) {
vector<int> dp(n + 1, 0);
dp[1] = 1; // 起点路径数为 1
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (i == 1 && j == 1) continue; // 跳过起点
dp[j] += dp[j - 1]; // 状态转移
}
}
return dp[n]; // 返回结果
}记忆化搜索的边界处理
-
在
dfs函数中,可以提前判断i和j是否越界,避免无效递归。
5. 总结
-
动态规划:适合自底向上的计算,空间复杂度可以优化到
O(n)。 -
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
三、 300. 最长递增子序列 - 力扣(LeetCode)

算法代码:
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
// 动态规划
int n = nums.size();
vector<int> dp(n, 1);
int ret = 0;
// 填表顺序:从后往前
for (int i = n - 1; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
if (nums[j] > nums[i]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
ret = max(ret, dp[i]);
}
return ret;
// 记忆化搜索
//
// vector<int> memo(n);
// int ret = 0;
// for(int i = 0; i < n; i++)
// ret = max(ret, dfs(i, nums, memo));
// return ret;
}
int dfs(int pos, vector<int>& nums, vector<int>& memo) {
if (memo[pos] != 0)
return memo[pos];
int ret = 1;
for (int i = pos + 1; i < nums.size(); i++) {
if (nums[i] > nums[pos]) {
ret = max(ret, dfs(i, nums, memo) + 1);
}
}
memo[pos] = ret;
return ret;
}
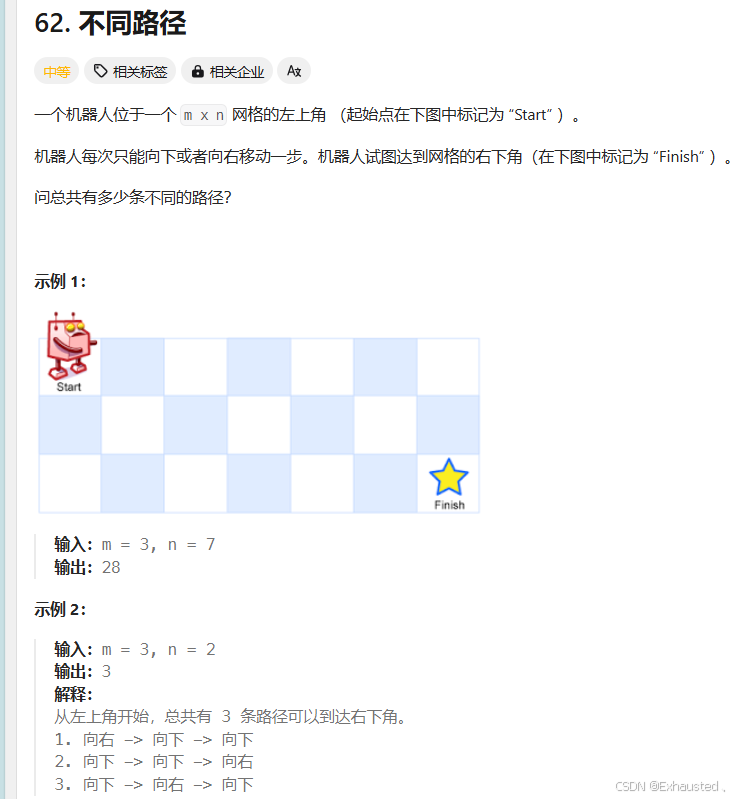
};这段代码解决了最长递增子序列(Longest Increasing Subsequence, LIS)问题,使用了两种方法:动态规划和记忆化搜索。以下是代码的思路和实现细节的详细解释:
1. 问题描述
给定一个整数数组 nums,找到其中最长的严格递增子序列的长度。
示例:
-
输入:
nums = [10, 9, 2, 5, 3, 7, 101, 18] -
输出:
4 -
解释:最长的递增子序列是
[2, 3, 7, 101],长度为 4。
2. 动态规划 (lengthOfLIS 函数)
动态规划是一种自底向上的方法,通过递推公式逐步计算以每个位置结尾的最长递增子序列的长度。
思路:
-
状态定义:
-
dp[i]表示以nums[i]结尾的最长递增子序列的长度。
-
-
初始条件:
-
每个元素本身就是一个长度为 1 的递增子序列,因此
dp[i] = 1。
-
-
状态转移方程:
-
对于每个位置
i,遍历其后面的所有位置j(j > i)。 -
如果
nums[j] > nums[i],说明nums[j]可以接在nums[i]后面,形成一个更长的递增子序列。 -
因此,
dp[i] = max(dp[i], dp[j] + 1)。
-
-
填表顺序:
-
从后往前填表,确保在计算
dp[i]时,dp[j]已经计算过。
-
-
最终结果:
-
遍历
dp数组,找到最大值,即为最长递增子序列的长度。
-
代码实现:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n, 1); // 初始化 dp 数组,每个元素至少是一个长度为 1 的递增子序列
int ret = 0; // 记录最终结果
for (int i = n - 1; i >= 0; i--) { // 从后往前填表
for (int j = i + 1; j < n; j++) { // 遍历后面的元素
if (nums[j] > nums[i]) {
dp[i] = max(dp[i], dp[j] + 1); // 状态转移
}
}
ret = max(ret, dp[i]); // 更新最大值
}
return ret; // 返回结果
}3. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算以每个位置结尾的最长递增子序列的长度,并使用备忘录 (memo) 来避免重复计算。
思路:
-
备忘录定义:
-
memo[pos]表示以nums[pos]结尾的最长递增子序列的长度。
-
-
递归终止条件:
-
如果
memo[pos]已经计算过,直接返回memo[pos]。
-
-
递归计算:
-
对于当前位置
pos,遍历其后面的所有位置i(i > pos)。 -
如果
nums[i] > nums[pos],说明nums[i]可以接在nums[pos]后面,形成一个更长的递增子序列。 -
因此,递归计算
dfs(i, nums, memo),并更新当前结果。
-
-
记录结果:
-
将计算结果记录到
memo[pos]中,避免重复计算。
-
代码实现:
int dfs(int pos, vector<int>& nums, vector<int>& memo) {
if (memo[pos] != 0) {
return memo[pos]; // 如果已经计算过,直接返回
}
int ret = 1; // 至少是一个长度为 1 的递增子序列
for (int i = pos + 1; i < nums.size(); i++) { // 遍历后面的元素
if (nums[i] > nums[pos]) {
ret = max(ret, dfs(i, nums, memo) + 1); // 递归计算
}
}
memo[pos] = ret; // 记录结果
return ret;
}
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int> memo(n, 0); // 初始化备忘录
int ret = 0;
for (int i = 0; i < n; i++) {
ret = max(ret, dfs(i, nums, memo)); // 计算以每个位置结尾的最长递增子序列
}
return ret; // 返回结果
}4. 代码优化建议
动态规划的优化
-
当前动态规划的时间复杂度为
O(n^2),可以使用二分查找将时间复杂度优化到O(n log n)。 -
使用一个辅助数组
tails,其中tails[i]表示长度为i+1的递增子序列的最小末尾元素。
优化后的代码:
int lengthOfLIS(vector<int>& nums) {
vector<int> tails;
for (int num : nums) {
auto it = lower_bound(tails.begin(), tails.end(), num); // 二分查找
if (it == tails.end()) {
tails.push_back(num); // 如果 num 比所有元素都大,直接添加到末尾
} else {
*it = num; // 否则替换第一个大于等于 num 的元素
}
}
return tails.size(); // tails 的长度即为最长递增子序列的长度
}记忆化搜索的边界处理
-
在
dfs函数中,可以提前判断pos是否越界,避免无效递归。
5. 总结
-
动态规划:适合自底向上的计算,时间复杂度为
O(n^2),可以通过二分查找优化到O(n log n)。 -
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
四、 375. 猜数字大小 II - 力扣(LeetCode)
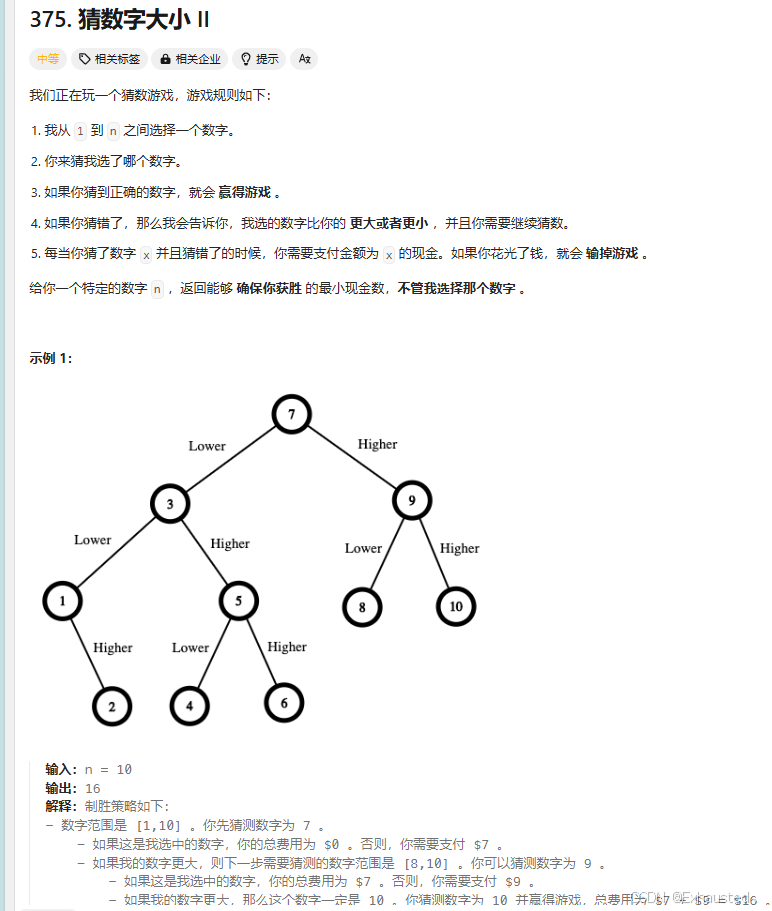

算法代码:
class Solution {
int memo[201][201];
public:
int getMoneyAmount(int n) { return dfs(1, n); }
int dfs(int left, int right) {
if (left >= right)
return 0;
if (memo[left][right] != 0)
return memo[left][right];
int ret = INT_MAX;
for (int head = left; head <= right; head++) // 选择头结点
{
int x = dfs(left, head - 1);
int y = dfs(head + 1, right);
ret = min(ret, head + max(x, y));
}
memo[left][right] = ret;
return ret;
}
};这段代码解决了猜数字游戏的最小代价问题,使用了记忆化搜索的方法。以下是代码的思路和实现细节的详细解释:
1. 问题描述
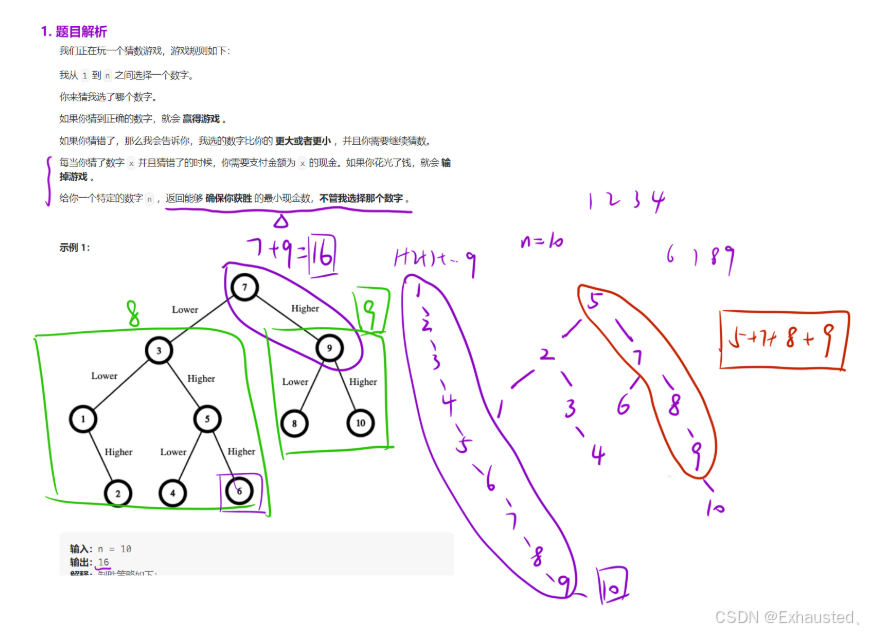
-
给定一个范围
[1, n],你需要猜一个目标数字。 -
每次猜错后,会被告知猜的数字是大于还是小于目标数字。
-
每次猜测的代价是猜测的数字本身。
-
目标是找到一种策略,使得最坏情况下的总代价最小。
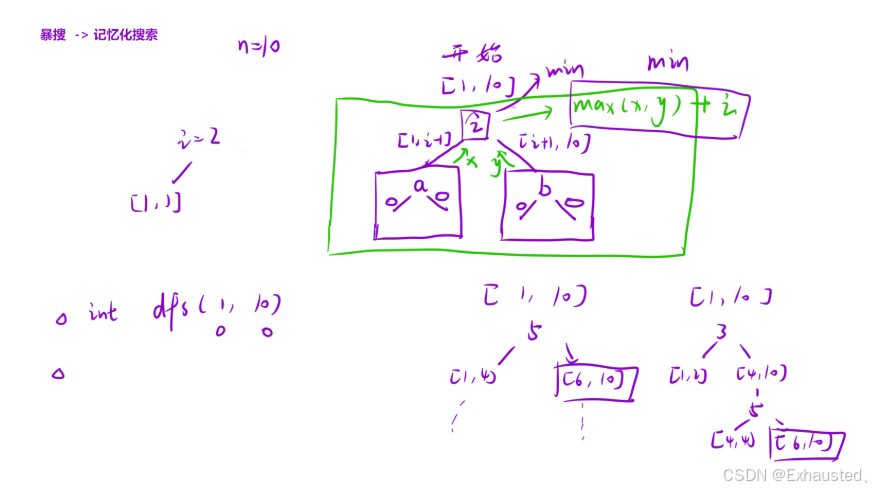
2. 记忆化搜索 (dfs 函数)
记忆化搜索是一种自顶向下的方法,通过递归计算每个子问题的最小代价,并使用备忘录 (memo) 来避免重复计算。
思路:
-
状态定义:
-
dfs(left, right)表示在范围[left, right]内猜数字的最小代价。
-
-
递归终止条件:
-
如果
left >= right,说明范围内没有数字或只有一个数字,不需要猜测,代价为 0。
-
-
递归计算:
-
遍历范围内的每个数字
head,作为猜测的起点。 -
将问题分为两部分:
-
左部分:
[left, head - 1]。 -
右部分:
[head + 1, right]。
-
-
计算左部分和右部分的最小代价,并取最大值(因为是最坏情况)。
-
当前猜测的代价为
head + max(左部分代价, 右部分代价)。 -
选择所有猜测中代价最小的一个。
-
-
记录结果:
-
将计算结果记录到
memo[left][right]中,避免重复计算。
-
代码实现:
int memo[201][201]; // 备忘录
int dfs(int left, int right) {
if (left >= right) {
return 0; // 范围内没有数字或只有一个数字,代价为 0
}
if (memo[left][right] != 0) {
return memo[left][right]; // 如果已经计算过,直接返回
}
int ret = INT_MAX; // 初始化最小代价为最大值
for (int head = left; head <= right; head++) { // 遍历范围内的每个数字
int x = dfs(left, head - 1); // 左部分代价
int y = dfs(head + 1, right); // 右部分代价
ret = min(ret, head + max(x, y)); // 更新最小代价
}
memo[left][right] = ret; // 记录结果
return ret;
}
int getMoneyAmount(int n) {
return dfs(1, n); // 调用记忆化搜索
}3. 动态规划的思路
虽然代码中使用了记忆化搜索,但这个问题也可以用动态规划来解决。动态规划是一种自底向上的方法,通过填表逐步计算每个子问题的最小代价。
动态规划的状态转移方程:
-
定义
dp[i][j]表示在范围[i, j]内猜数字的最小代价。 -
状态转移方程:
dp[i][j] = min(dp[i][j], head + max(dp[i][head - 1], dp[head + 1][j]));其中
head是当前猜测的数字。
动态规划的填表顺序:
-
从小到大枚举范围的长度
len。 -
对于每个长度
len,枚举起点i,计算j = i + len - 1。
动态规划的代码实现:
int getMoneyAmount(int n) {
vector<vector<int>> dp(n + 2, vector<int>(n + 2, 0)); // 初始化 dp 数组
for (int len = 2; len <= n; len++) { // 枚举范围的长度
for (int i = 1; i + len - 1 <= n; i++) { // 枚举起点
int j = i + len - 1; // 终点
dp[i][j] = INT_MAX; // 初始化最小代价为最大值
for (int head = i; head <= j; head++) { // 遍历范围内的每个数字
int cost = head + max(dp[i][head - 1], dp[head + 1][j]); // 当前猜测的代价
dp[i][j] = min(dp[i][j], cost); // 更新最小代价
}
}
}
return dp[1][n]; // 返回结果
}4. 代码优化建议
记忆化搜索的优化
-
在
dfs函数中,可以提前判断left和right是否越界,避免无效递归。
动态规划的空间优化
-
当前动态规划的空间复杂度为
O(n^2),无法进一步优化。
5. 总结
-
记忆化搜索:适合自顶向下的计算,通过备忘录避免重复计算,但需要额外的空间来存储中间结果。
-
动态规划:适合自底向上的计算,通过填表逐步计算每个子问题的最小代价。
两种方法各有优缺点,选择哪种方法取决于具体问题的需求和约束条件。
五、329. 矩阵中的最长递增路径 - 力扣(LeetCode)


算法代码:
class Solution {
int m, n;
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
int memo[201][201];
public:
int longestIncreasingPath(vector<vector<int>>& matrix) {
int ret = 0;
m = matrix.size(), n = matrix[0].size();
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++) {
ret = max(ret, dfs(matrix, i, j));
}
return ret;
}
int dfs(vector<vector<int>>& matrix, int i, int j) {
if (memo[i][j] != 0)
return memo[i][j];
int ret = 1;
for (int k = 0; k < 4; k++) {
int x = i + dx[k], y = j + dy[k];
if (x >= 0 && x < m && y >= 0 && y < n &&
matrix[x][y] > matrix[i][j]) {
ret = max(ret, dfs(matrix, x, y) + 1);
}
}
memo[i][j] = ret;
return ret;
}
};这段代码解决了矩阵中的最长递增路径问题,使用了深度优先搜索(DFS)和记忆化搜索的方法。以下是代码的思路和实现细节的详细解释:
1. 问题描述
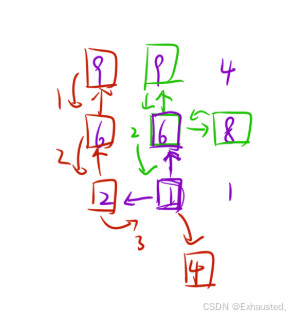
-
给定一个
m x n的整数矩阵matrix,找到其中最长的递增路径的长度。 -
对于每个单元格,你可以向上下左右四个方向移动,但不能移动到边界外或移动到值小于等于当前单元格的单元格。
2. 代码思路
(1)变量定义
-
m和n:矩阵的行数和列数。 -
dx和dy:表示四个方向的偏移量(右、左、下、上)。 -
memo[i][j]:记录从单元格(i, j)出发的最长递增路径的长度。
(2)主函数 longestIncreasingPath
-
遍历矩阵中的每个单元格
(i, j),调用dfs函数计算从该单元格出发的最长递增路径。 -
更新全局最大值
ret。
(3)DFS 函数 dfs
-
递归终止条件:
-
如果
memo[i][j]已经计算过,直接返回memo[i][j]。
-
-
递归计算:
-
初始化当前单元格的最长路径长度为 1。
-
遍历四个方向,检查是否可以移动到相邻单元格
(x, y):-
如果
(x, y)在矩阵范围内,并且matrix[x][y] > matrix[i][j],则递归计算dfs(matrix, x, y)。 -
更新当前单元格的最长路径长度
ret = max(ret, dfs(matrix, x, y) + 1)。
-
-
-
记录结果:
-
将计算结果
ret记录到memo[i][j]中。 -
返回
ret。
-
3. 代码实现
class Solution {
int m, n; // 矩阵的行数和列数
int dx[4] = {0, 0, 1, -1}; // 四个方向的 x 偏移量
int dy[4] = {1, -1, 0, 0}; // 四个方向的 y 偏移量
int memo[201][201]; // 备忘录,记录从每个单元格出发的最长递增路径长度
public:
int longestIncreasingPath(vector<vector<int>>& matrix) {
int ret = 0; // 记录全局最大值
m = matrix.size(), n = matrix[0].size(); // 初始化矩阵的行数和列数
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
ret = max(ret, dfs(matrix, i, j)); // 计算从每个单元格出发的最长递增路径
}
}
return ret; // 返回全局最大值
}
int dfs(vector<vector<int>>& matrix, int i, int j) {
if (memo[i][j] != 0) {
return memo[i][j]; // 如果已经计算过,直接返回
}
int ret = 1; // 初始化当前单元格的最长路径长度为 1
for (int k = 0; k < 4; k++) { // 遍历四个方向
int x = i + dx[k], y = j + dy[k]; // 计算相邻单元格的坐标
if (x >= 0 && x < m && y >= 0 && y < n && matrix[x][y] > matrix[i][j]) {
ret = max(ret, dfs(matrix, x, y) + 1); // 递归计算并更新最长路径长度
}
}
memo[i][j] = ret; // 记录结果
return ret; // 返回当前单元格的最长路径长度
}
};4. 代码优化建议
(1)边界检查优化
-
在
dfs函数中,可以提前判断(x, y)是否在矩阵范围内,避免无效递归。
(2)空间优化
-
当前备忘录
memo的大小为201 x 201,可以动态分配内存,避免空间浪费。
(3)方向数组优化
-
方向数组
dx和dy可以定义为静态常量,避免重复初始化。
5. 总结
-
DFS + 记忆化搜索:
-
通过深度优先搜索遍历矩阵中的每个单元格。
-
使用备忘录
memo记录每个单元格的最长递增路径长度,避免重复计算。
-
-
时间复杂度:
-
每个单元格最多计算一次,时间复杂度为
O(m * n)。
-
-
空间复杂度:
-
备忘录
memo的空间复杂度为O(m * n)。
-
通过 DFS 和记忆化搜索的结合,可以高效地解决矩阵中的最长递增路径问题。