写在前面
- 博文内容涉及 基于 Deepseek LLM 的本地知识库搭建
- 使用 ollama 部署 Deepseek-R1 LLM
- 知识库能力通过 Ragflow、Dify 、AnythingLLM、Cherry 提供
- 理解不足小伙伴帮忙指正 😃,生活加油
我站在人潮中央,思考这日日重复的生活。我突然想,如果有一天,垂老和年轻都难以惊起心中涟漪,一潭死水的沉闷,鲜花和蛋糕也撼动不了。如果人开始不能为微小事物而感动,那么地震山洪的噩耗想必也惊闻不了。如果活着和死亡的本质无异,那便没有了存在的意义。我没有快乐,也没有痛苦,只是麻木的置身于平静的绝望之中,和世界一起下沉。我甚至病态的渴望,心中掀起一场风暴或是海啸,将我席卷撕裂。可那片黑洞里什么也没有,它吞噬万物,它带走了我的生命 情绪 活力,我眼睁睁的看着,我对此无能为力。 这一刻我明白了我看远山,远山悲悯。远山知道我的苦闷,却改变不了什么,只能悲悯,悲悯我的麻木,悲悯我的无奈
持续分享技术干货,感兴趣小伙伴可以关注下 _
本地 LLM 部署
LLM 本身只是一些 神经网络参数, 就拿 DeepSeek-R1 来讲,模型本身存储了 权重矩阵,以及 混合专家(MoE)架构, 实际运行起来需要行业级别的服务器配置, 消费级别的个人电脑不能直接运行,实际还涉及到硬件适配,需手动配置 CUDA/PyTorch 环境,编写分布式推理代码,处理量化与内存溢出问题
现在通过 ollama 可以在消费级别电脑部署,上面涉及到的问题 ollama 帮我们完成,同时还涉及模型的管理,推理服务构建
ollama 开源项目地址: https://github.com/ollama/ollama
它在项目中这样介绍自己:Get up and running with large language models.
ollama安装
下载 ollama:之后直接安装就可以,下载地址, https://ollama.com/download
ollama 专注于在本地设备(如个人电脑或服务器)快速部署和运行开源大语言模型(如 DeepSeek-R1),支持模型下载、环境配置及基础推理服务。
适用需本地化运行 LLM 的场景,强调数据隐私与低成本(无需高性能服务器),但是不提供知识库管理、RAG 或应用开发功能,需配合其他工具使用
安装成功会自动配置环境变量
PS C:\Users\Administrator> ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
。。。。。。
Ollama 采用 Client-Server(C/S)架构,C 端通过命令行(CLI)或桌面应用与用户交互,发起模型请求。S 端负责处理客户端请求,管理模型下载与元数据,推理引擎,负责加载模型并执行计算
Ollama 资源优化技术:
权重量化:支持 INT8/INT4 量化,显存占用降低至原始模型的 1/2 至 1/4,使 65B 参数模型可在 16GB 内存设备运行分块加载:长文本分块处理,避免显存溢出GPU/CPU 调度:优先调用 NVIDIA/AMD GPU 加速,无 GPU 时通过 Metal 或分布式计算优化 CPU 模式
模型管理机制:
本地存储:模型文件(如 blobs 数据)和元数据(如 manifests)默认存储在 $HOME/.ollama,支持离线使用,数据无需上传云端,适合医疗、金融等隐私敏感场景。模型拉取:客户端通过 ollama run <模型名> 触发服务端从远程仓库下载并缓存模型
通过下面的地址选择对应的参数的模型即可:
https://ollama.com/library/deepseek-r1
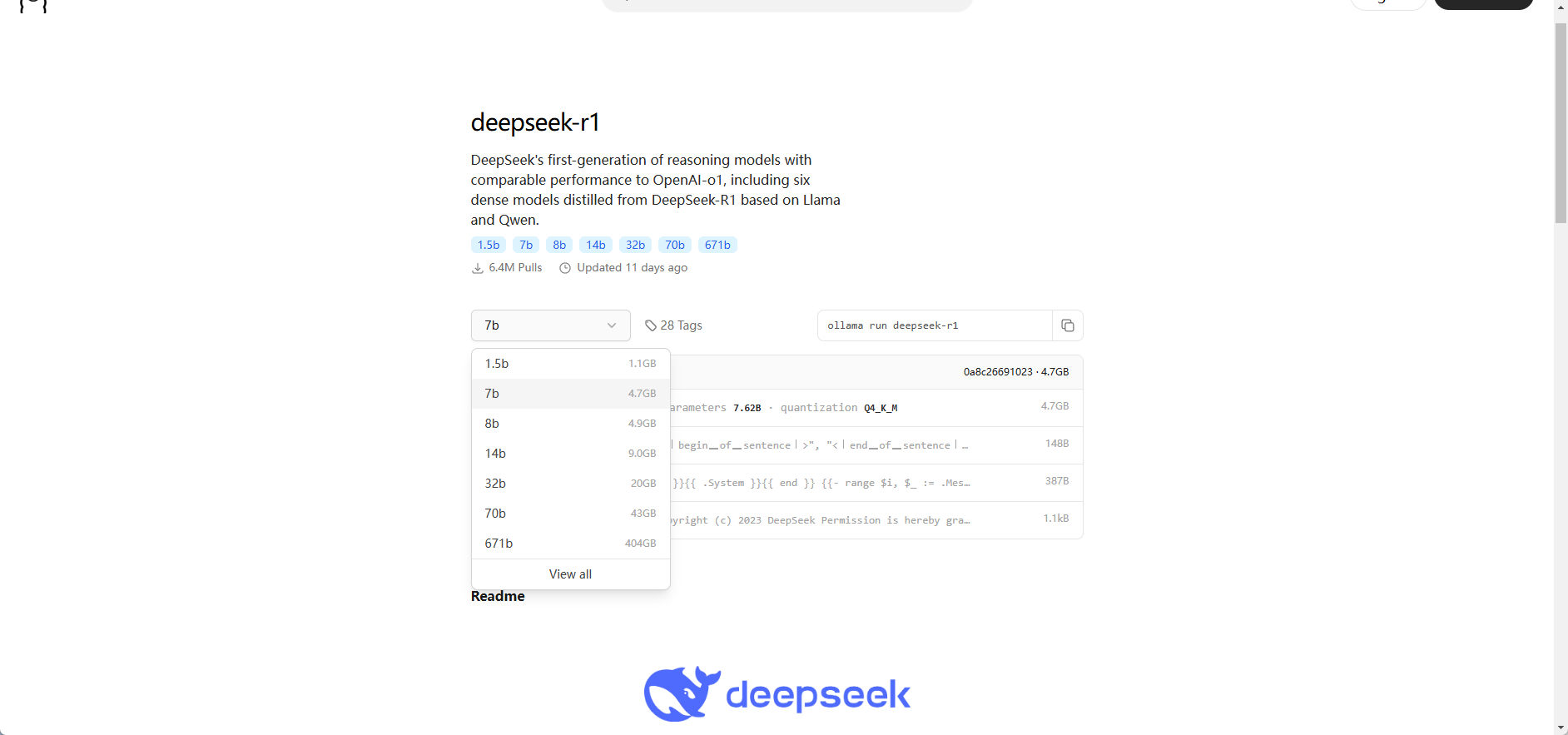
deepseek R1 蒸馏模型部署
关于什么是蒸馏模型,小伙伴可以看我之前的文章
模型下载成功就可以用了,默认会自动下载 DeepSeek-R1-Distill-Qwen-7B 模型
PS C:\Users\Administrator> ollama run deepseek-r1
pulling manifest
pulling 96c415656d37... 100% ▕████████████████████████████████████████████████████████▏ 4.7 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
pulling 40fb844194b2... 100% ▕████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
直接命令行就可以交互了,算一道数学题
PS C:\Users\Administrator> ollama run deepseek-r1
>>> 1+2+3+4+54654+213=?
<think>
To solve the equation \(1 + 2 + 3 + 4 + 54654 + 213\), I will follow these steps:
First, add the numbers from 1 to 4.
Next, add the result to 54654.
Finally, add this sum to 213 to get the final answer.
</think>
To solve the equation \(1 + 2 + 3 + 4 + 54654 + 213\), follow these steps:
1. **Add the numbers from 1 to 4:**
\[
1 + 2 + 3 + 4 = 10
\]
2. **Add this sum to 54654:**
\[
10 + 54654 = 54664
\]
3. **Finally, add the result to 213:**
\[
54664 + 213 = 54877
\]
**Final Answer:**
\boxed{54877}
>>> Send a message
这里通过命令行的方式启动服务端,配置,$env:OLLAMA_HOST="0.0.0.0" 的作用是 将 Ollama 服务绑定到所有网络接口,因为后面涉及到和其他工具交互。
PS C:\Users\Administrator> $env:OLLAMA_HOST="0.0.0.0" # 设置环境变量
服务启动涉及到的环境变量在项目中位置:
https://github.com/ollama/ollama/blob/main/envconfig/config.go
PS C:\Users\Administrator> ollama serve # 启动服务
2025/02/20 08:47:44 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\Administrator\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
time=2025-02-20T08:47:44.747+08:00 level=INFO source=images.go:432 msg="total blobs: 14"
time=2025-02-20T08:47:44.748+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0"
time=2025-02-20T08:47:44.748+08:00 level=INFO source=routes.go:1238 msg="Listening on [::]:11434 (version 0.5.7)"
time=2025-02-20T08:47:44.749+08:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cpu_avx cpu_avx2 cuda_v11_avx cuda_v12_avx rocm_avx cpu]"
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu_windows.go:183 msg="efficiency cores detected" maxEfficiencyClass=1
time=2025-02-20T08:47:44.749+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=12 efficiency=4 threads=20
time=2025-02-20T08:47:44.872+08:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-e65029a6-c2f9-44b1-bd76-c12e4083fa4c library=cuda variant=v12 compute=8.6 driver=12.8 name="NVIDIA GeForce RTX 3060" total="12.0 GiB" available="11.0 GiB"
[GIN] 2025/02/20 - 08:47:57 | 200 | 0s | 172.19.16.1 | GET "/"
[GIN] 2025/02/20 - 08:47:57 | 404 | 0s | 172.19.16.1 | GET "/favicon.ico"
同时项目启动之后会输出当前推理服务的环境变量
2025/02/20 08:47:44 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\Administrator\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
如果有需要部署生产级别的小伙伴需要详细了解,这里简单看几个常用的:
OLLAMA_HOST
- 作用:指定服务器监听的 IP 地址和端口。它定义了客户端可以访问服务器的地址。
- 当前值:http://0.0.0.0:11434,表示服务器将监听所有可用的网络接口,端口为 11434,使用 HTTP 协议。
OLLAMA_KEEP_ALIVE
- 作用:设置模型在内存中保持加载的时间。如果在这个时间内没有新的请求,模型可能会被卸载以释放内存。
- 当前值:5m0s,即 5 分钟,意味着模型在 5 分钟内没有被使用就可能会被卸载。
OLLAMA_LOAD_TIMEOUT
- 作用:设置模型加载的超时时间。如果模型在这个时间内没有加载完成,服务器可能会放弃加载操作。
- 当前值:5m0s,表示模型加载的最长时间为 5 分钟。
OLLAMA_MAX_LOADED_MODELS
- 作用:限制每个 GPU 上最多可以加载的模型数量。这有助于控制 GPU 的资源使用。
- 当前值:0,表示没有对每个 GPU 加载的模型数量进行限制。
OLLAMA_MAX_QUEUE
- 作用:设置请
求队列的最大长度。当请求数量超过这个值时,新的请求可能会被拒绝。 - 当前值:512,表示请求队列最多可以容纳 512 个请求。
OLLAMA_MODELS
- 作用:指定模型文件存储的目录。服务器会从这个目录中加载模型。
- 当前值:C:\Users\Administrator.ollama\models,表示模型文件存储在该 Windows 用户目录下的 .
ollama\models 文件夹中。
OLLAMA_NUM_PARALLEL
- 作用:设置服务器
可以同时处理的并行模型请求数量。 - 当前值:0,表示没有对并行请求数量进行限制。
知识库搭建
在知识库搭建的时候,我们还需要一个基本的嵌入模型,用于理解分析已有的知识库内容
嵌入模型
这里我们使用的是 BGE-M3 ,嵌入模型是什么,通俗的话讲,它把文本信息翻译成计算机能够理解和处理的数字形式,也就是向量。它就像是给每一段文本生成了一个独一无二的 “数字指纹”,凭借这个 “指纹”,计算机就能对文本进行各种分析和操作。
有了嵌入模型分析知识库的文本内容,那么是如何和问答结合的,这就需要 RAG
RAG
检索增强生成(RAG)是一种将外部知识检索与大语言模型(LLM)相结合的技术。传统的大语言模型虽然拥有丰富的知识,但知识更新可能不及时,或者在特定领域的知识储备不足。RAG 通过在生成回答之前,先从外部知识源(如文档数据库、网页等)中检索相关信息,然后将这些信息与用户的问题一起输入到大语言模型中,从而生成更准确、更具时效性的回答。
需要注意的事项
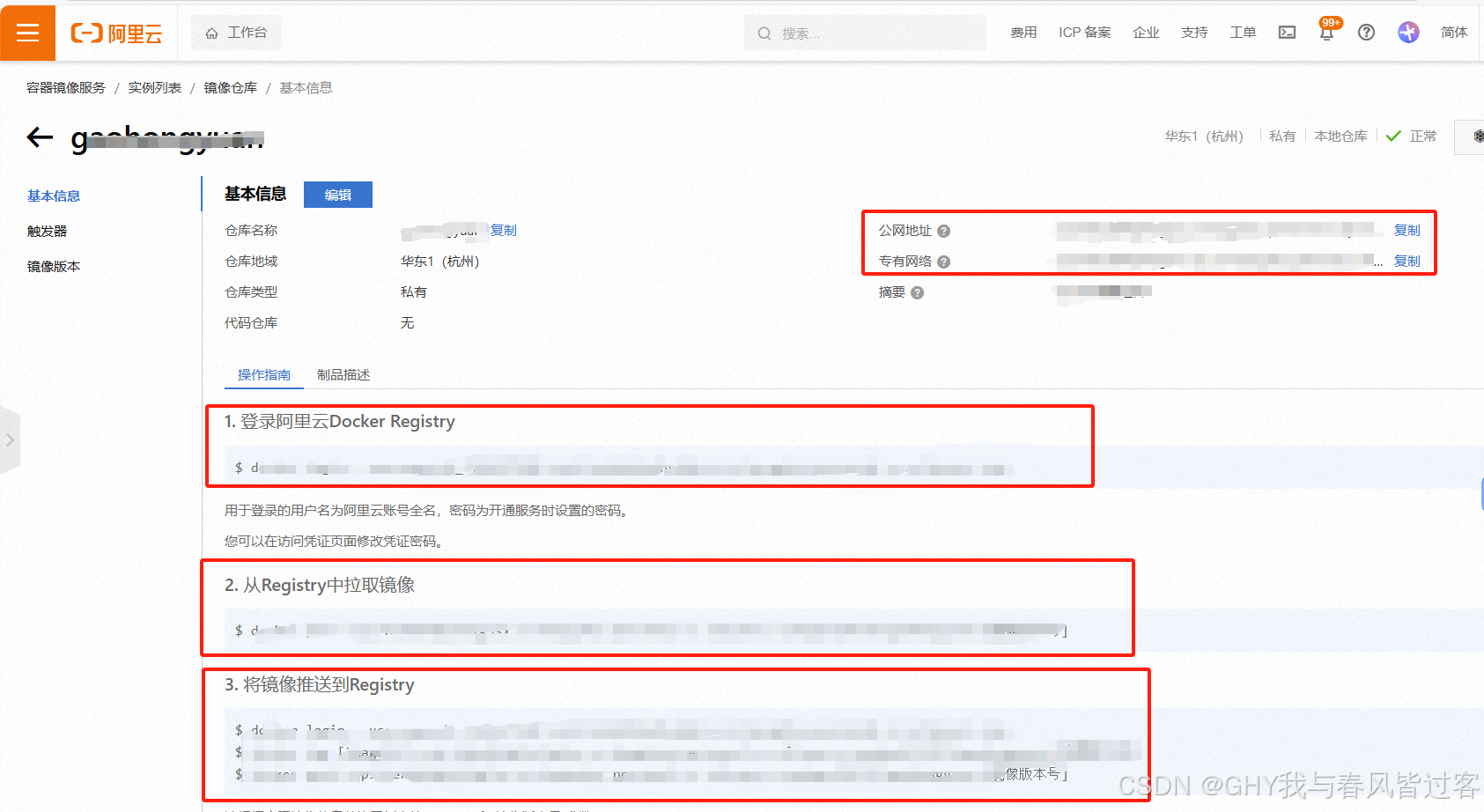
知识库的搭建部分使用的是容器的方式,所以调用 ollama 提供的推理能力的时候,通过 127.0.0.0:11434 访问是访问不通的,所以需要一个能代表宿主机但是IP地址或者域名不是 127.0.0.0或localhost 的地址。
在windos 上面会有这个一个虚拟交换设备, 在其他服务调用 ollama 的时候,需要本地ID:11434 的方式访问,这里我们选用这个 IP , 172.29.176.1:11434,至于这个 设备如何创建的,一般开启虚拟化 Hyper - V 的时候会自动创建
以太网适配器 vEthernet (Default Switch):
连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::c872:92b3:b00a:6ce0%25
IPv4 地址 . . . . . . . . . . . . : 172.29.176.1
子网掩码 . . . . . . . . . . . . : 255.255.240.0
默认网关. . . . . . . . . . . . . :
对于通过客户端的方式直接部署的,我们可以之间使用 127.0.0.0:11434 或者 localhost 来访问推理服务
Ragflow + DeepSeek
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation,检索增强生成)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
官网地址:https://ragflow.io
项目地址: https://github.com/infiniflow/ragflow
这里需要使用 docker 来部署,安装dockr, 克隆项目,执行 docker-compose 就可以了
git clone https://github.com/infiniflow/ragflow.git
然后参考 readme 部署即可
$ cd ragflow/docker
$ docker compose -f docker-compose.yml up -d
这里需要说明一下,有些 docker-compose 维护不及时,可能部署有问题,所以我们用 readme 推荐的方式
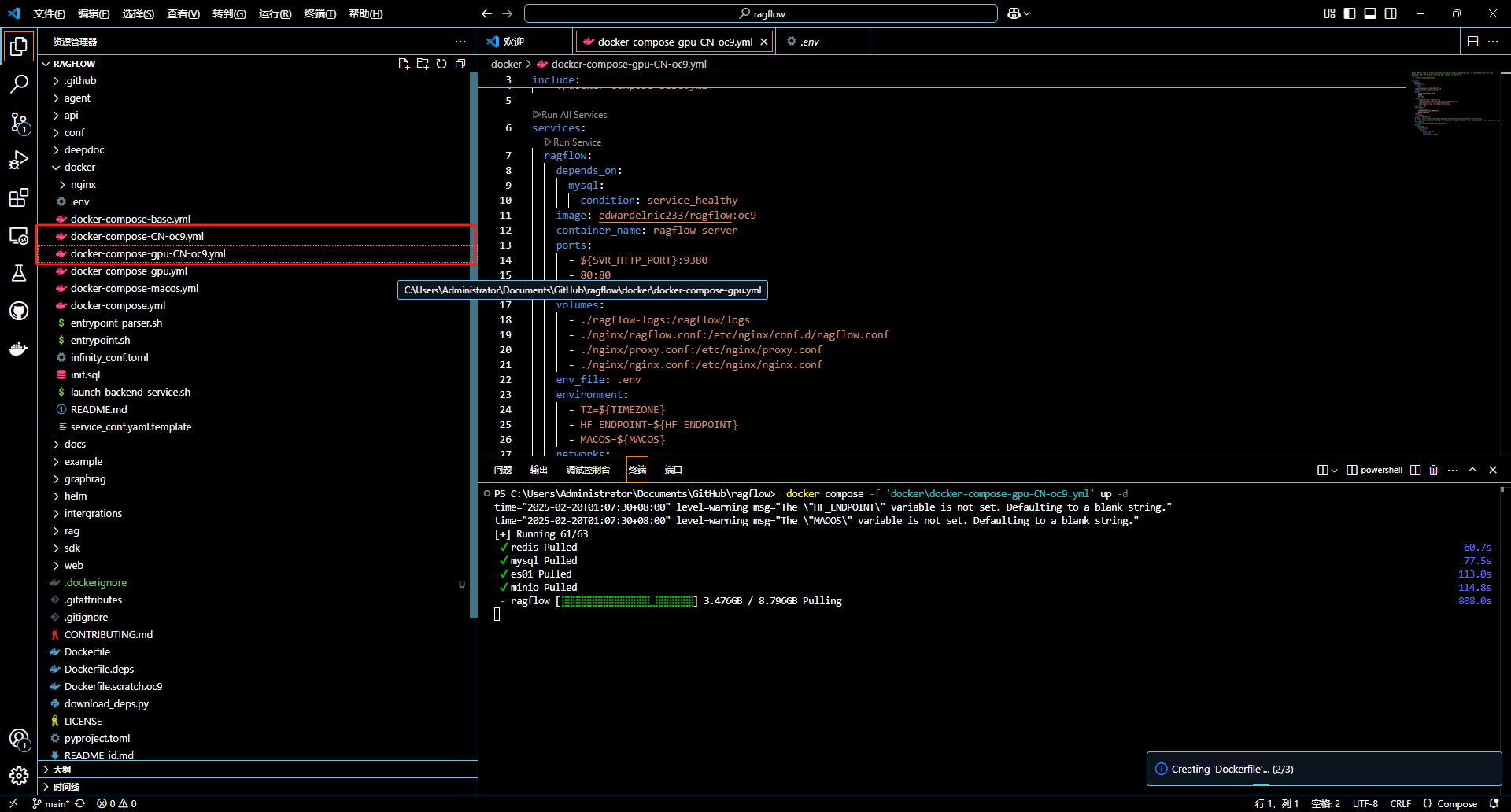
上面截图中 GPU 版本的 我尝试了好久,server 启动链接 es 报错,未果,用了默认的 compose。
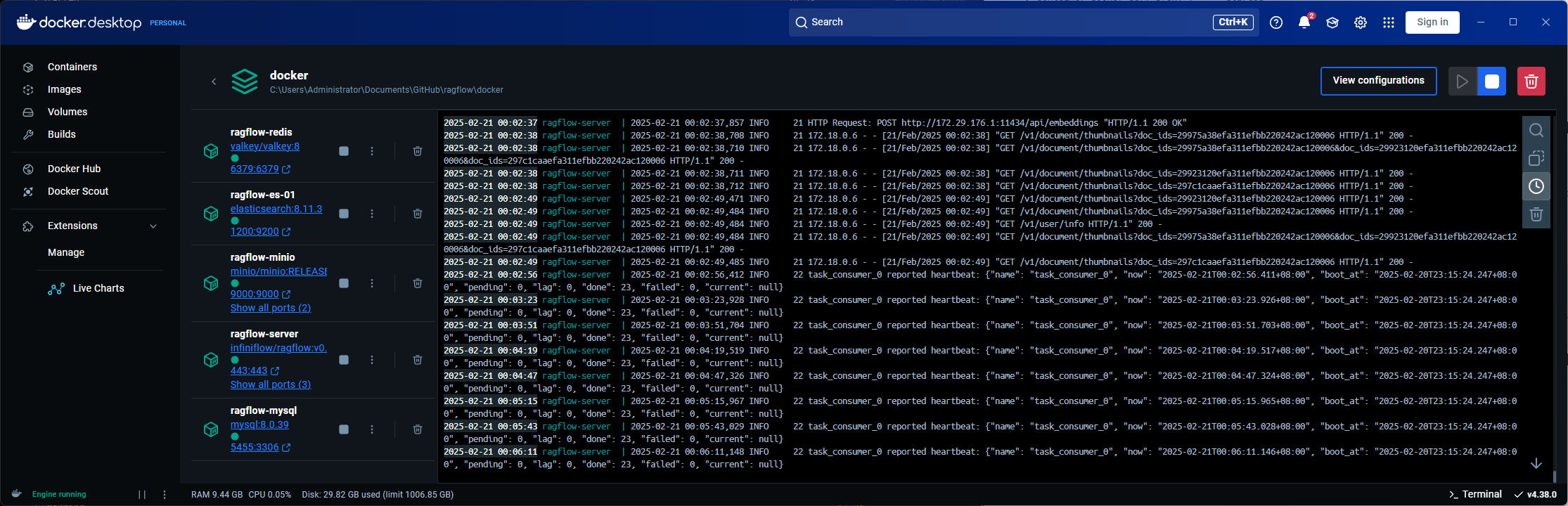
部署成功之后可以在docker 桌面版中看到容器,核心服务是一个 server
默认 80 端口,需要注册账号登陆
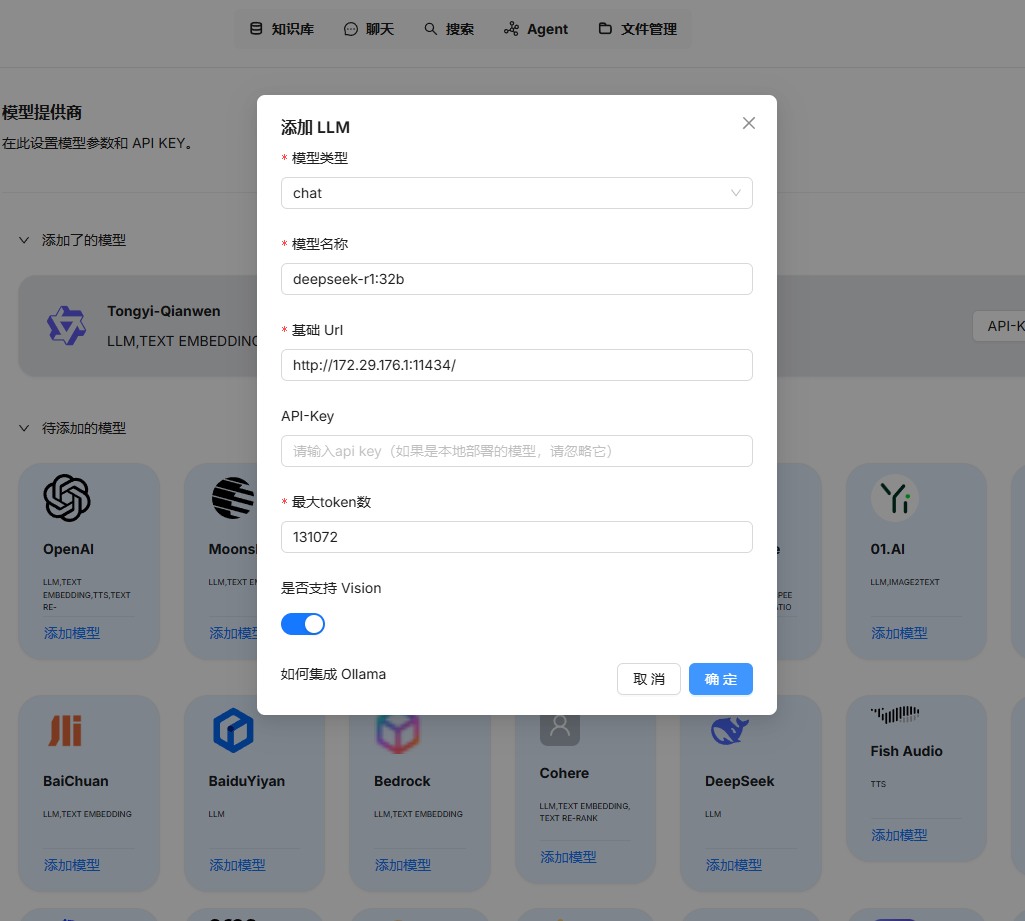
需要先配置基础模型,需要注意这里的地址不能写 127.0.0.1

选择本地模型 LLM 模型
选择嵌入模型

在系统模型设置添加对应的模型
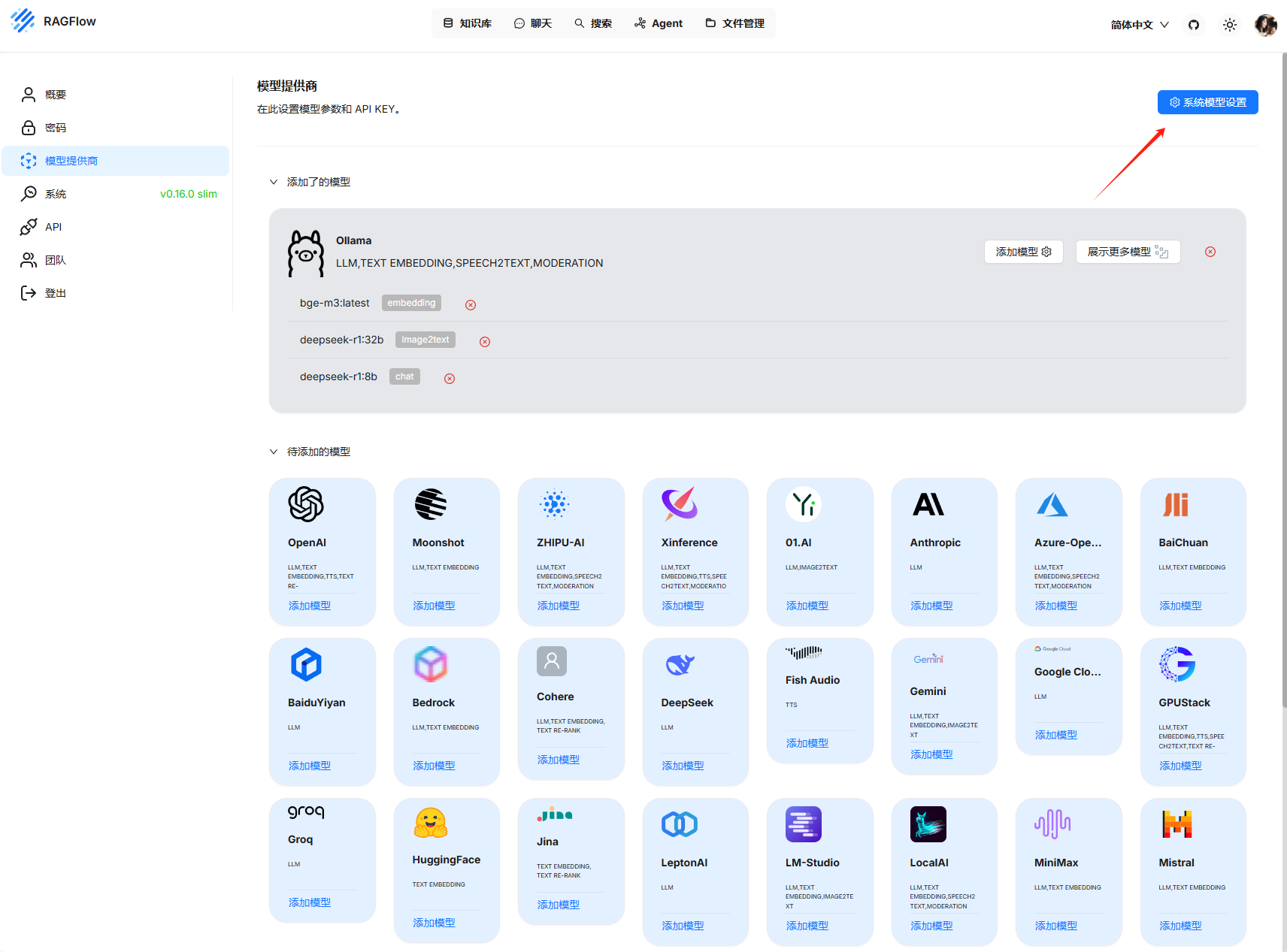
选择知识库
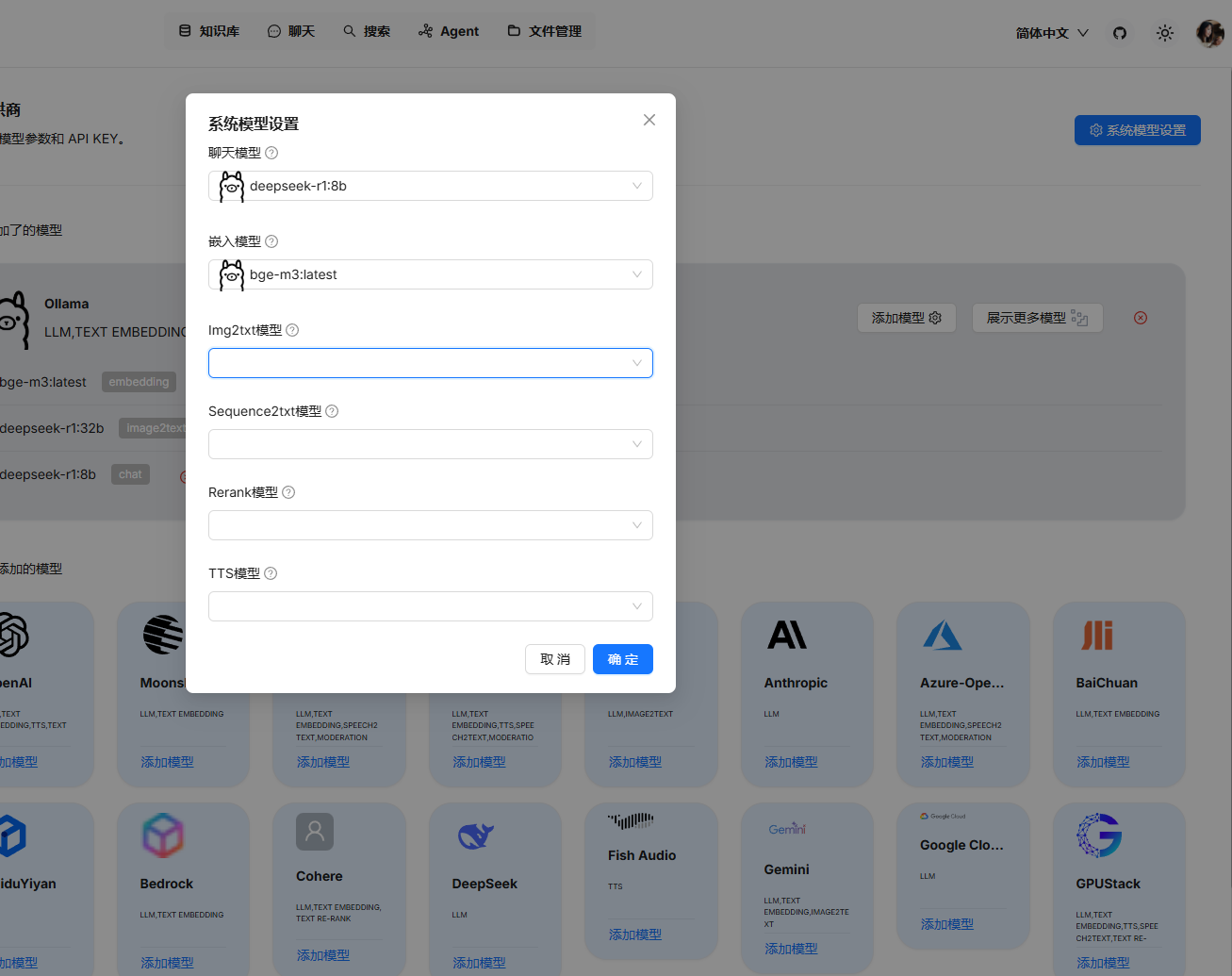
创建知识库
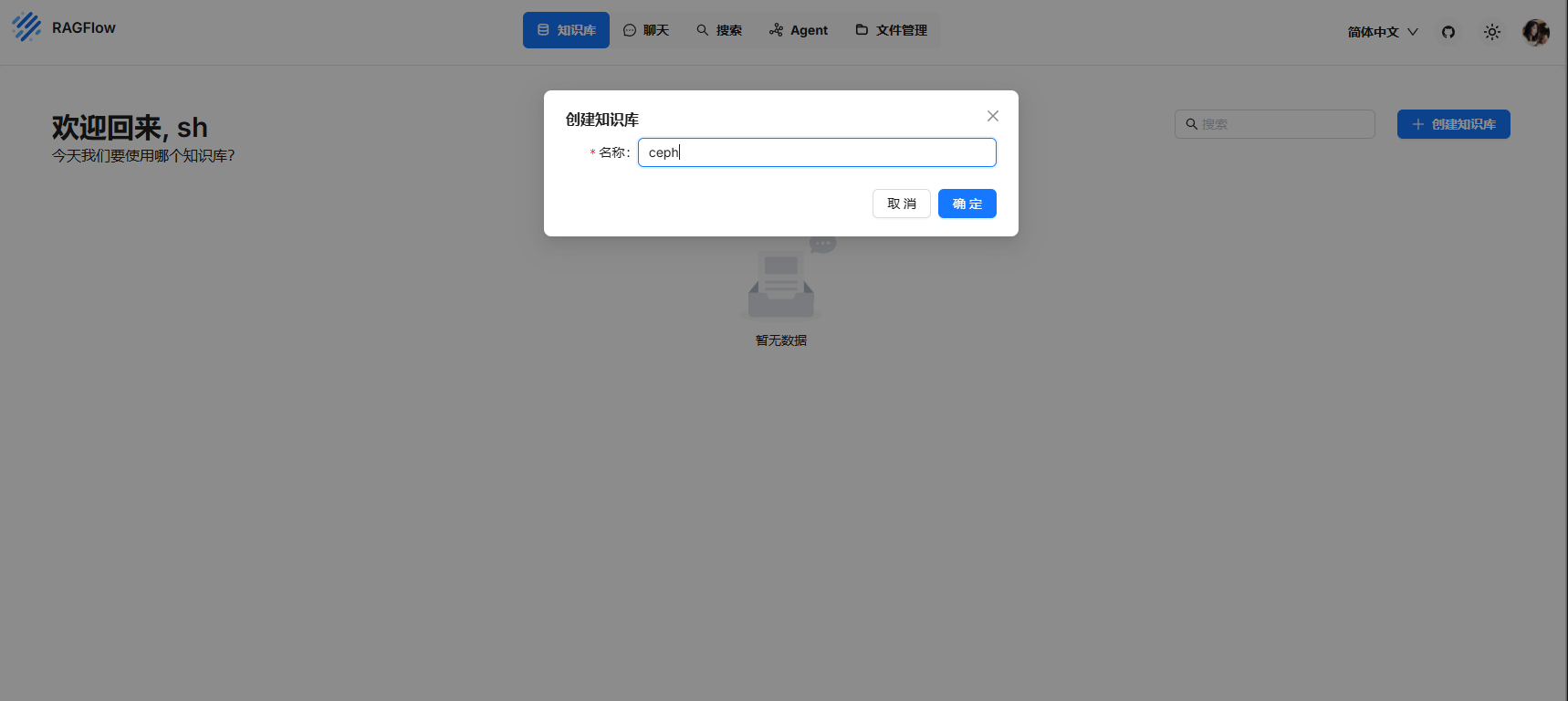
在配置中配置需要的数据
上传本地的知识库内容
全选,解析启用
之后在聊天配置中选择对应的知识库
模型参数调整
简单测试
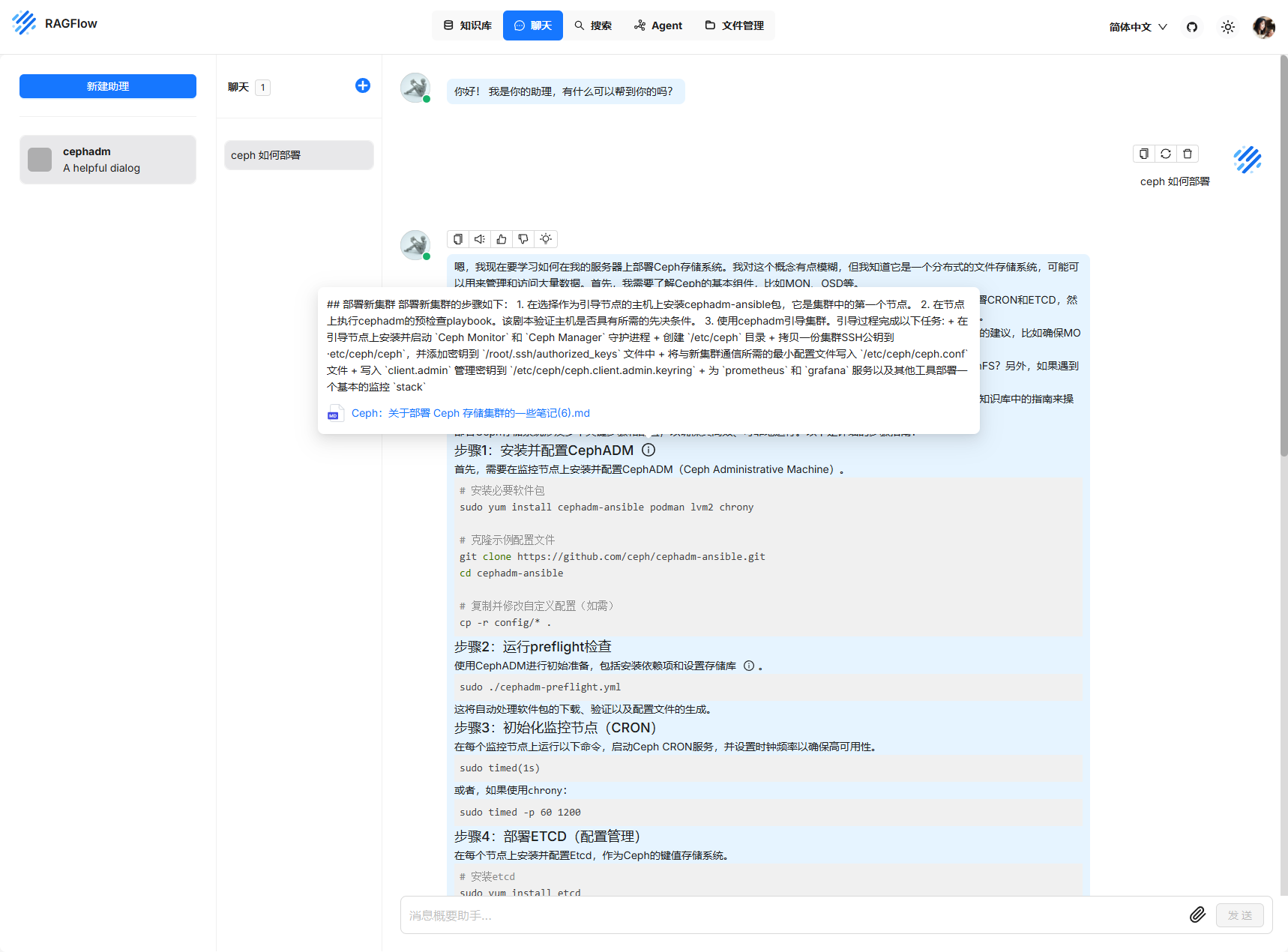
每次提问会显示对应的文本内容
Dify + DeepSeek
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,可以快速从原型到生产。
官网地址: https://dify.ai/zh
项目地址: https://github.com/langgenius/dify/blob/main/README_CN.md
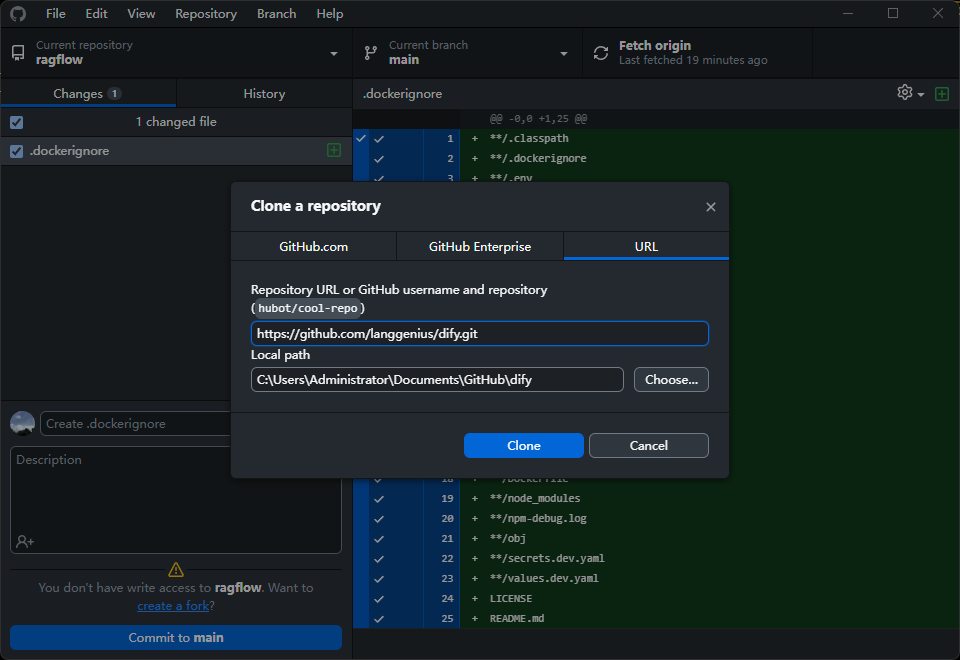
和上面的部署一眼,克隆项目,然后通过 docker 部署
git clone https://github.com/langgenius/dify.git
运行项目中的 docker-compose.yml
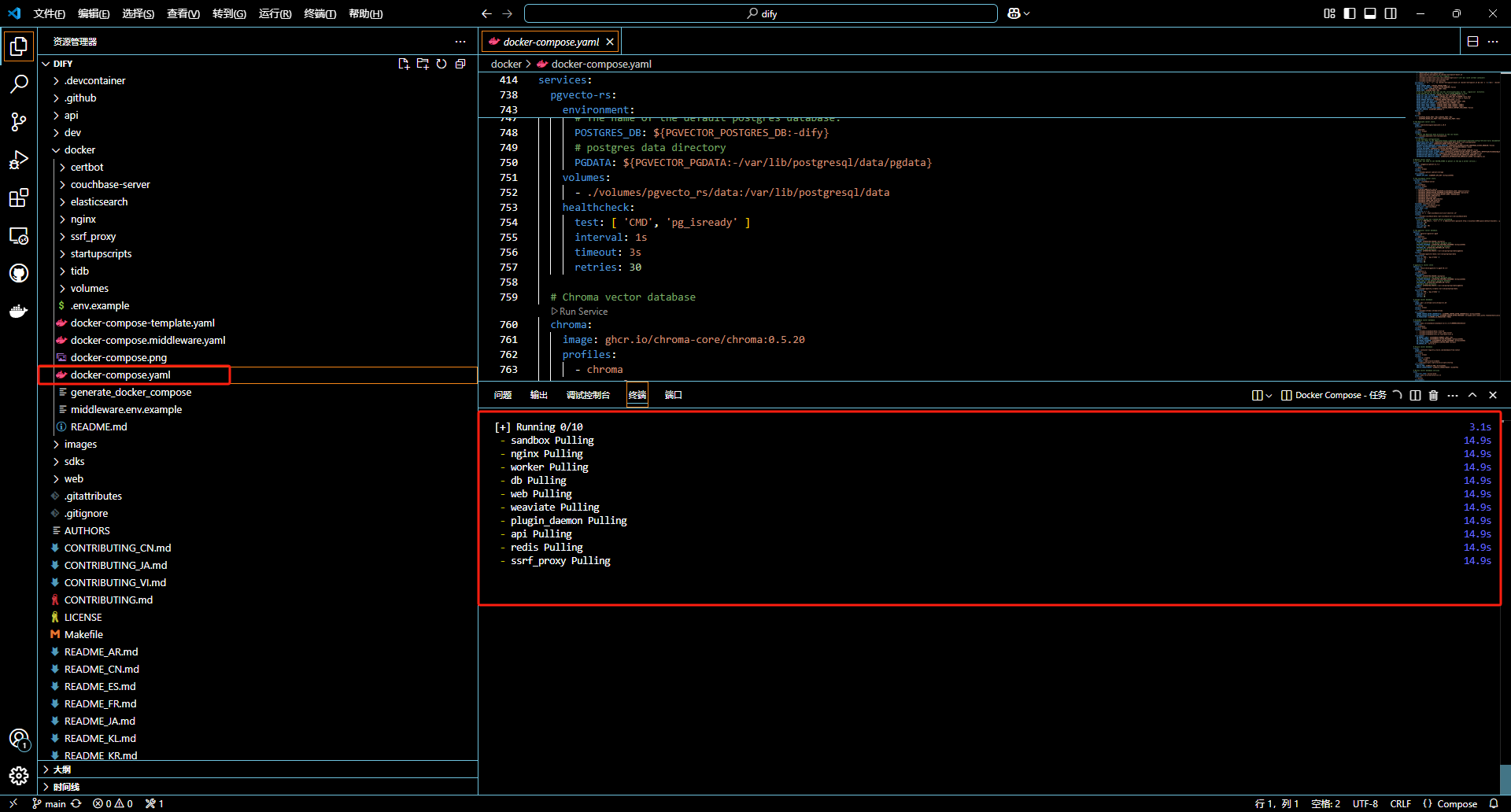
这里直接通过 vs code 运行
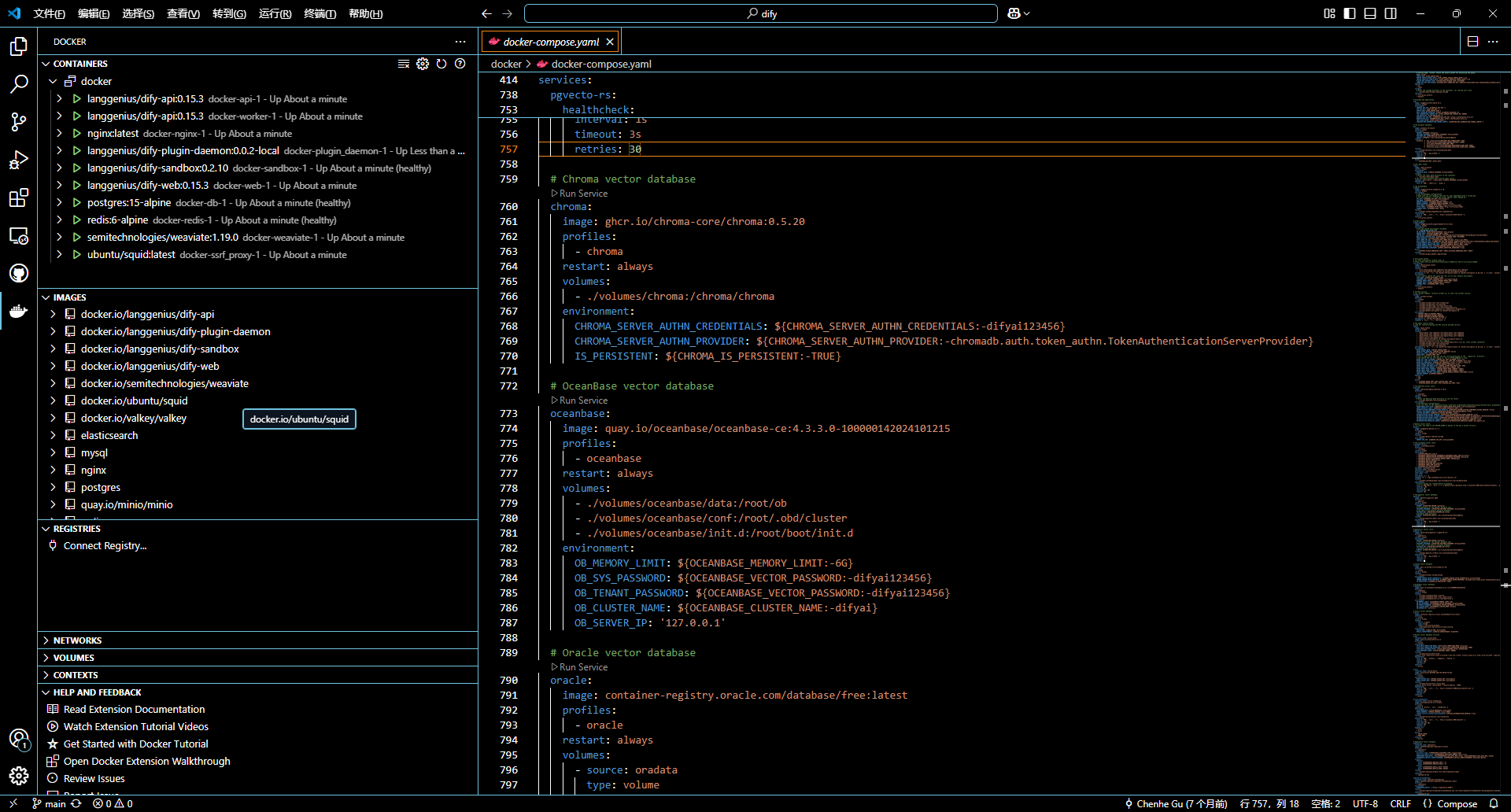
docker 中观察容器运行情况
同样是 80 端口,需要注册一个账号
用注册的账号登陆即可
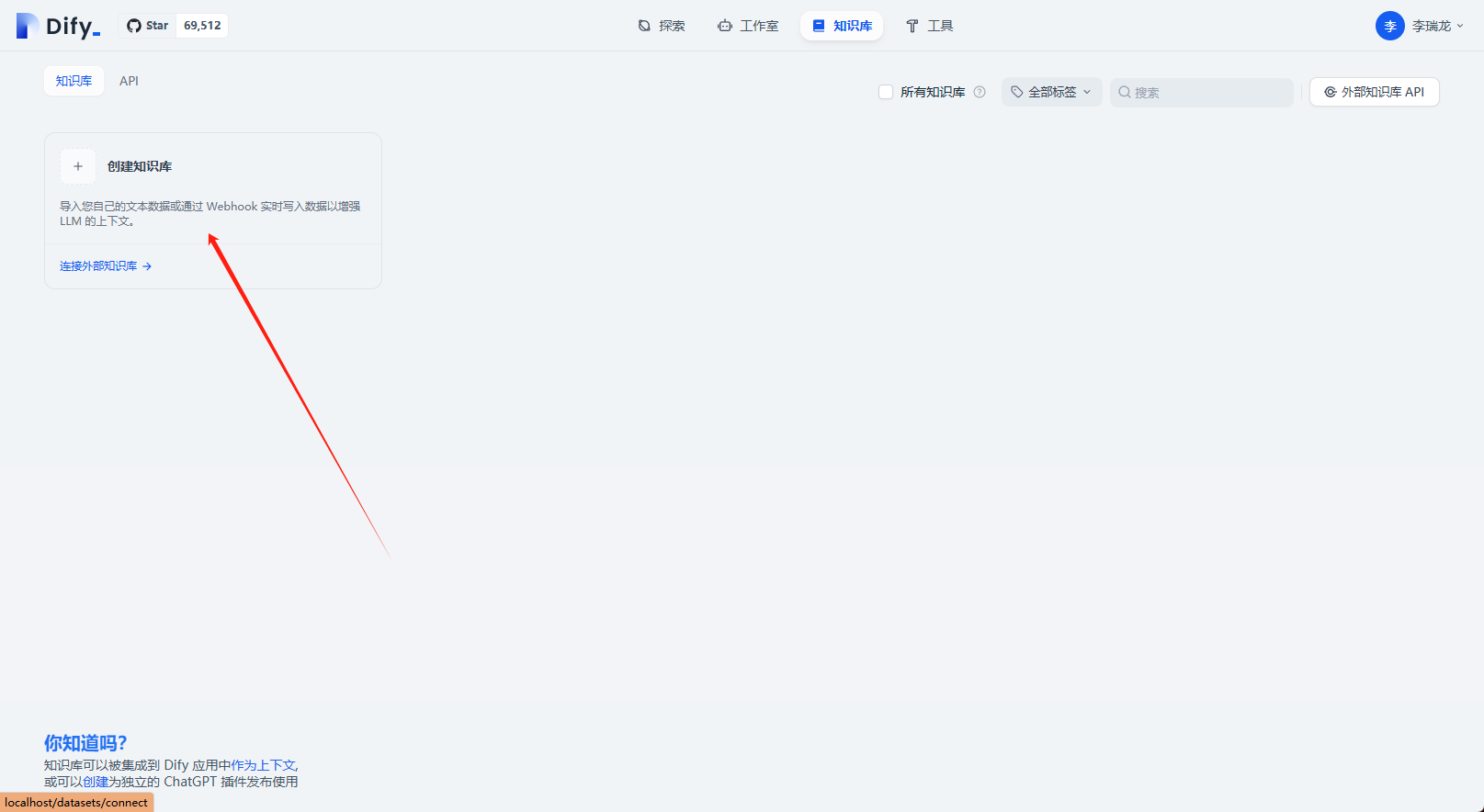
选择知识库
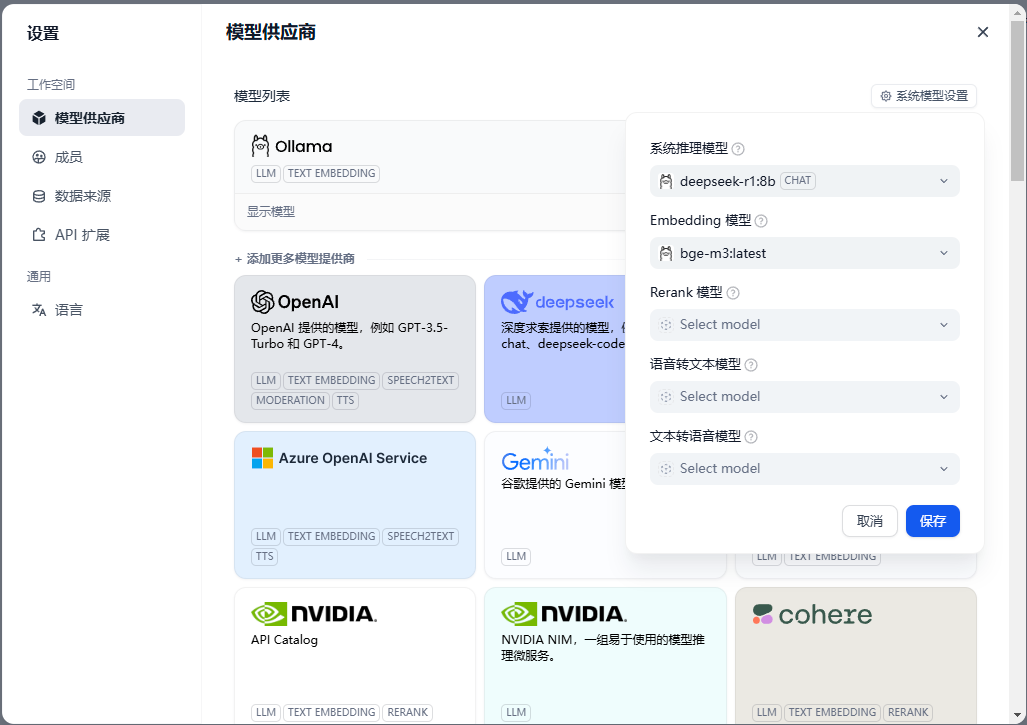
在用户中心设置中配置模型相关配置
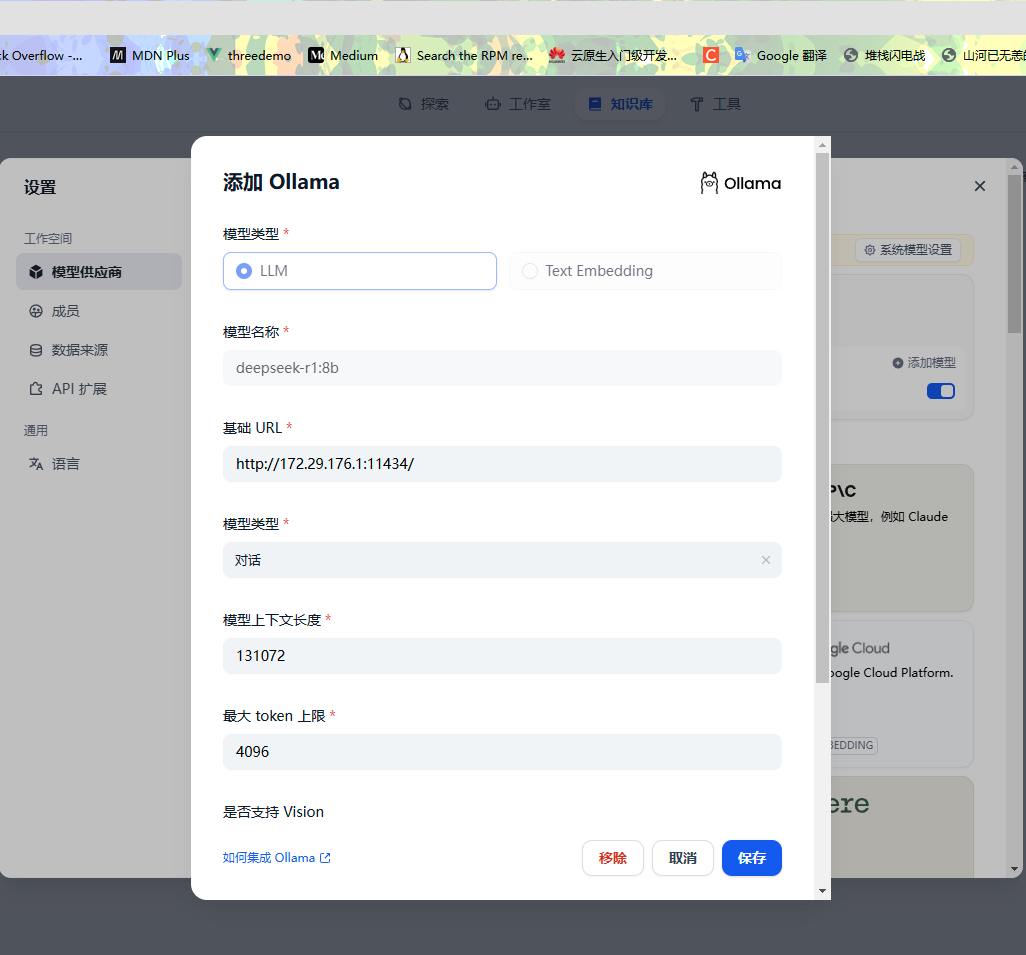
配置本地模型,需要注意这里的地址
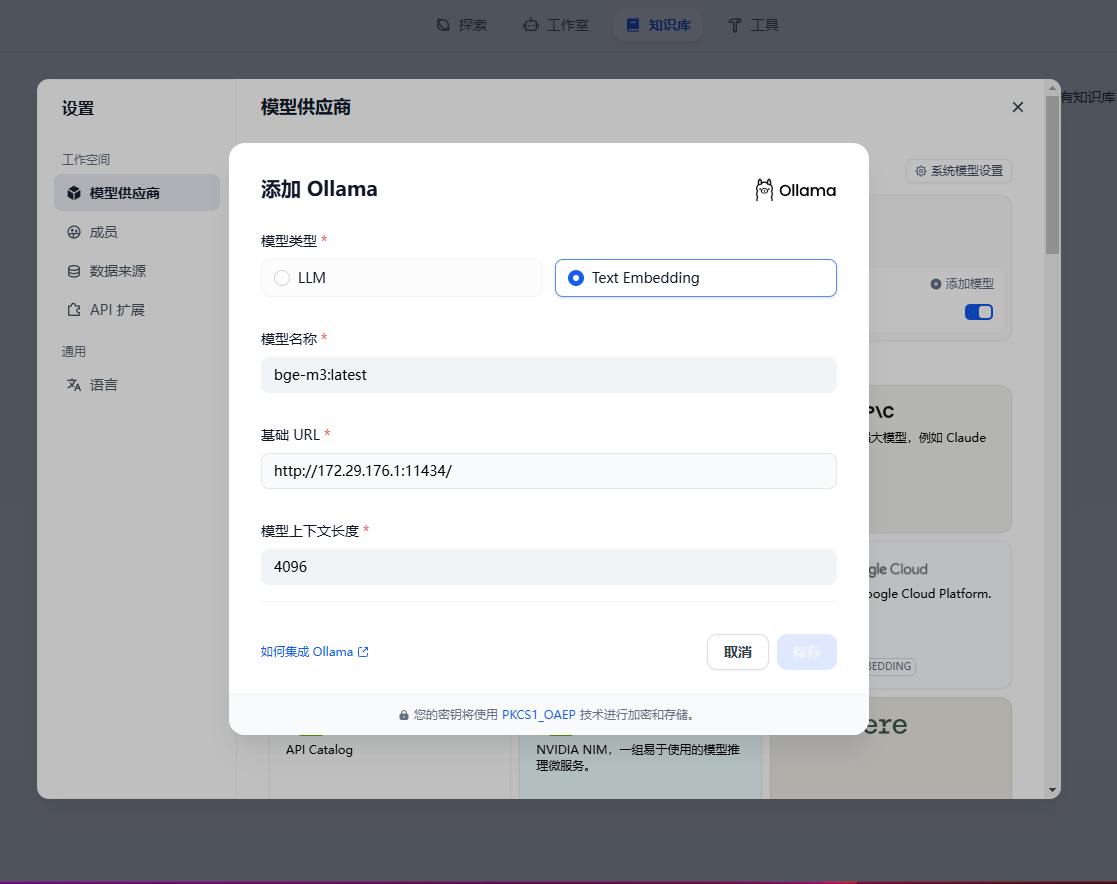
配置嵌入模型
然后中模型配置中添加
选择创建知识库
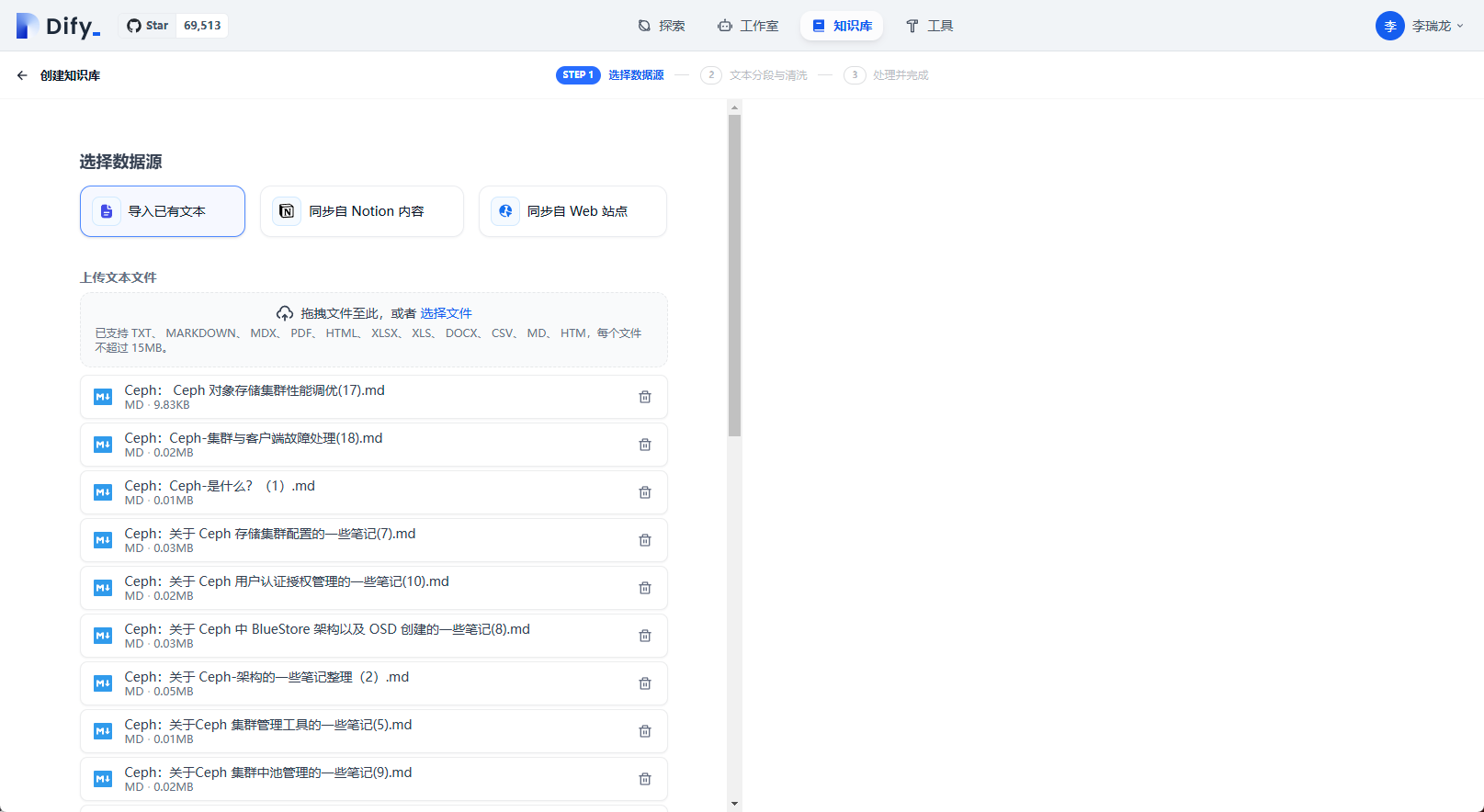
导入本地知识库
分段相关配置
保存设置
等待文档解析完成
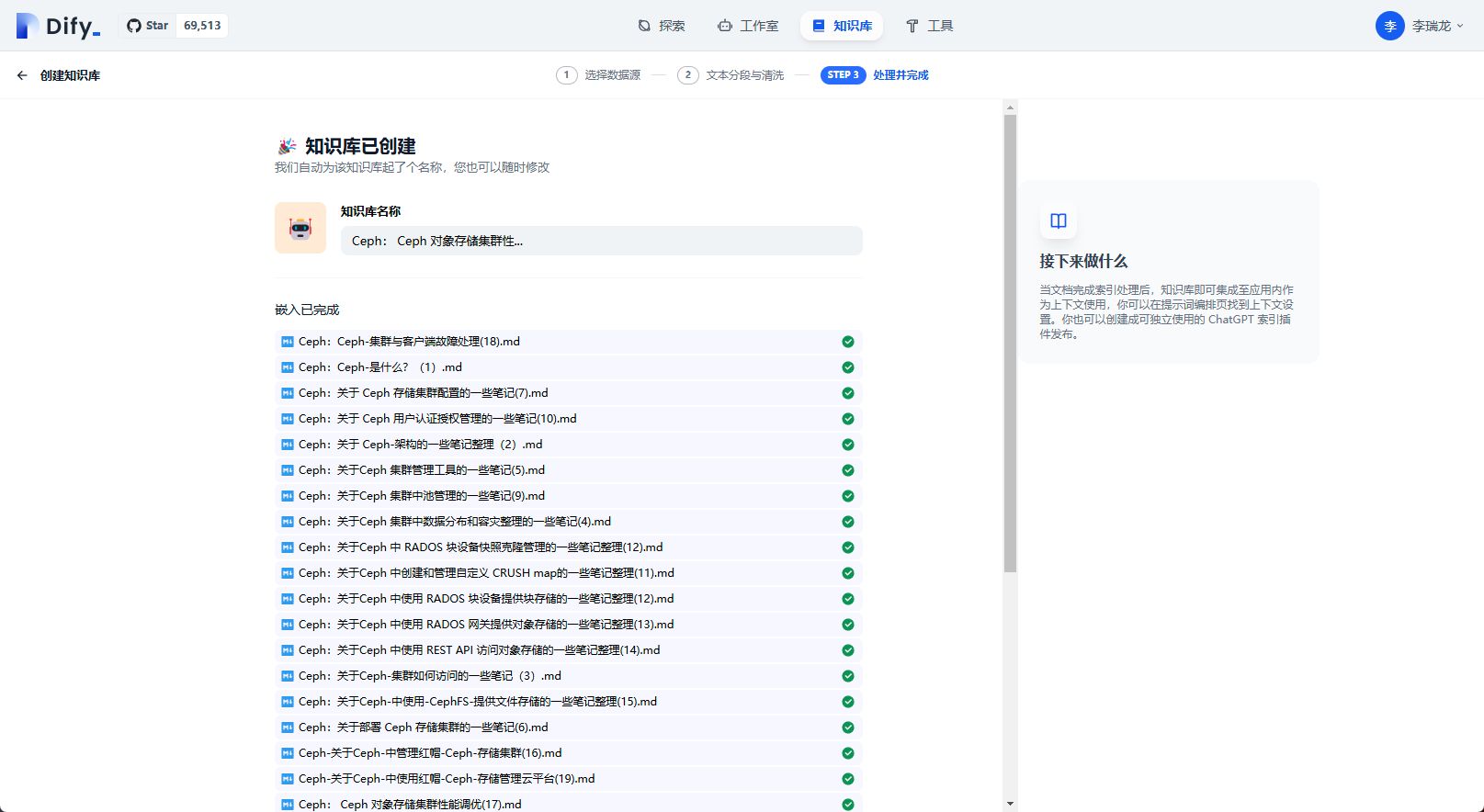
知识库创建完成
创建聊天助手
上下文选择之前创建的知识库
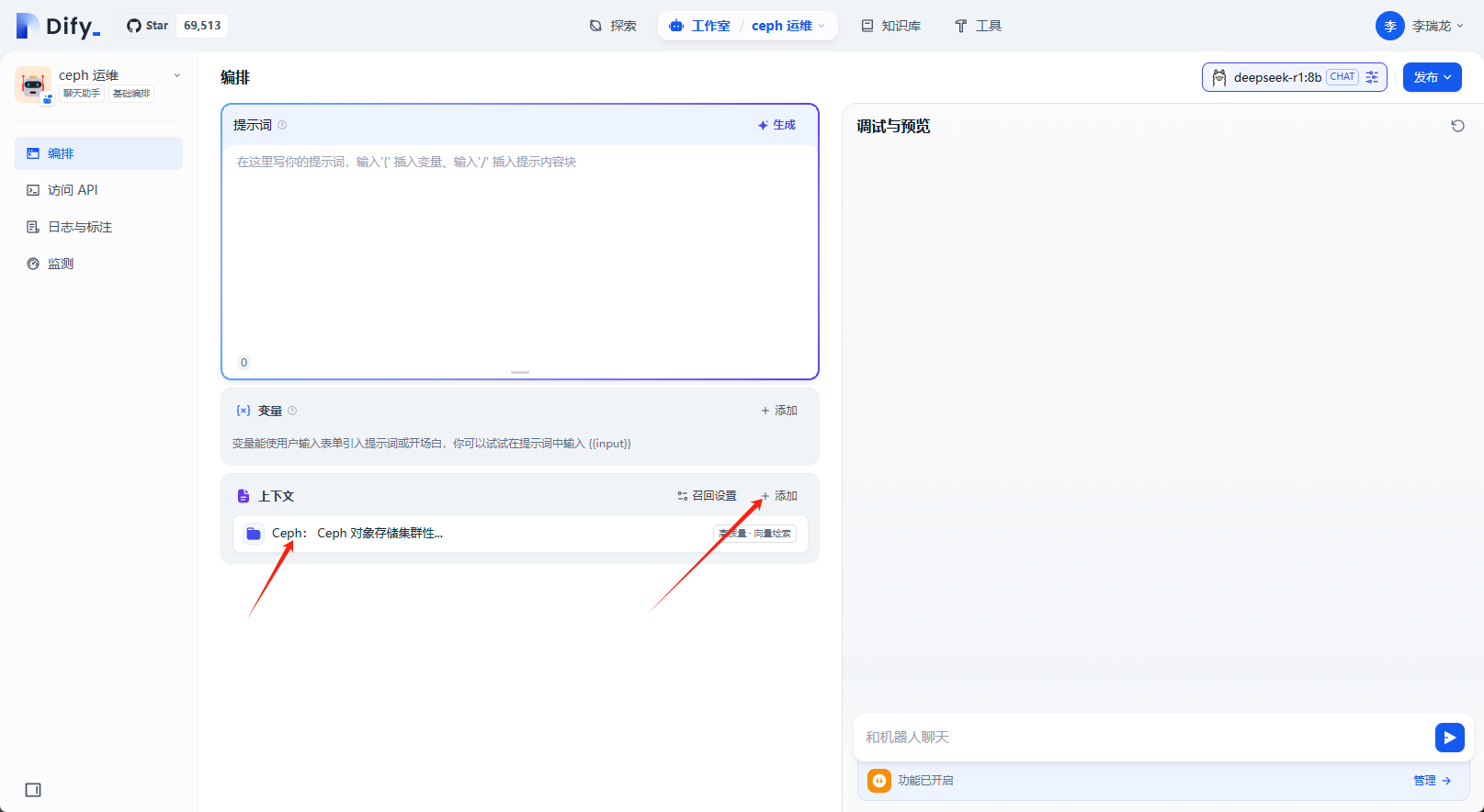
做简单的问答测试,可以看到最下面引用的文档
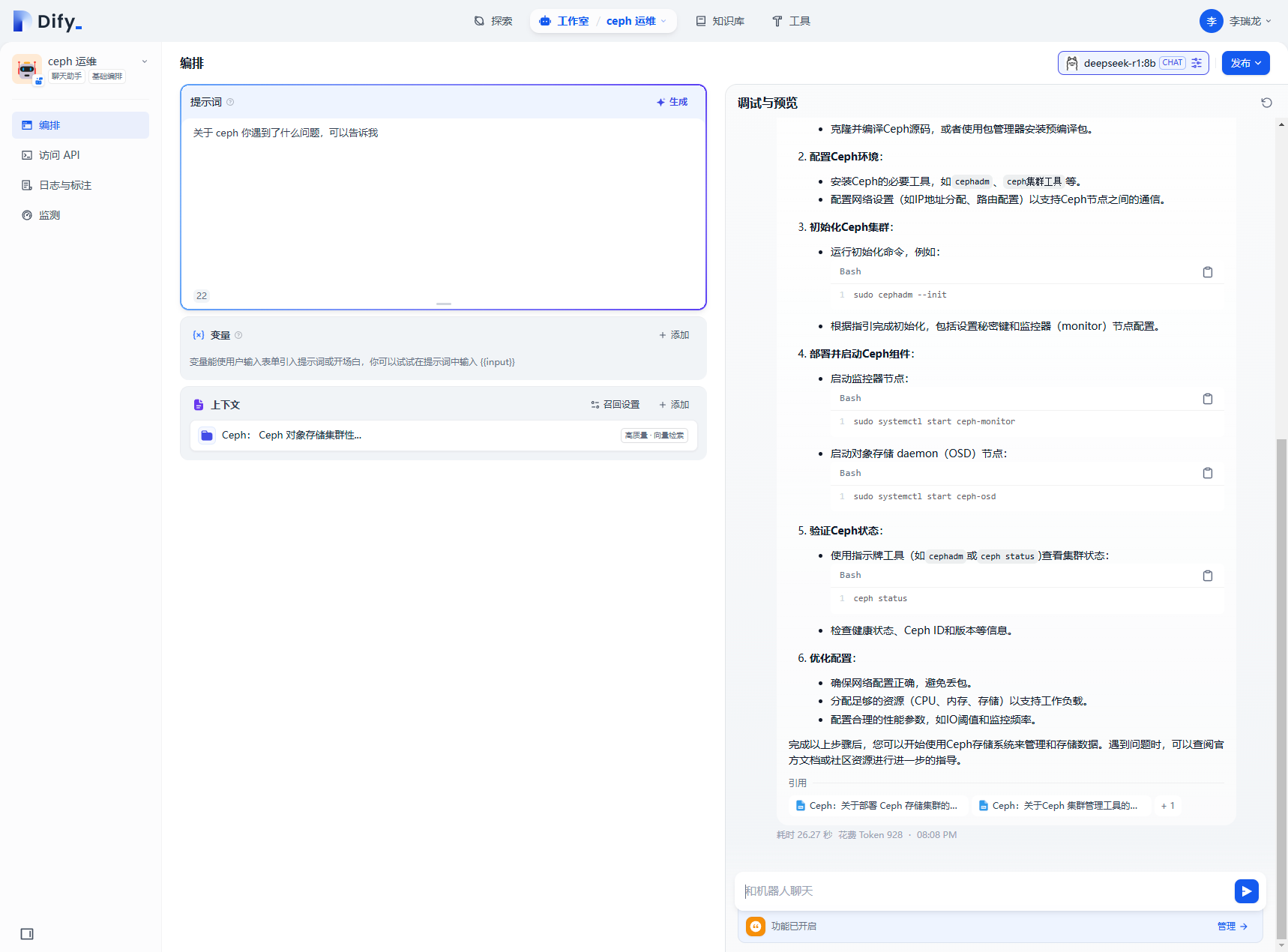
点击发布,知识库机器人创建完成
Cherry Studio + DeepSeek
Cherry Studio 是一款开源、跨平台(支持 Windows/macOS/Linux)的 AI 桌面客户端,专注于聚合多模型服务并提供本地化 AI 应用开发支持。
官网地址: https://cherry-ai.com/
下载地址: https://cherry-ai.com/download
项目地址: https://github.com/CherryHQ/cherry-studio
它的这样介绍自己: Cherry Studio 是一款支持多个大语言模型(LLM)服务商的桌面客户端,兼容 Windows、Mac 和 Linux 系统。

以下是其核心功能与使用要点:
多模型集成:支持 300+ 主流大语言模型,包括 DeepSeek、OpenAI、Gemini、Claude 等,通过 API 密钥接入云端服务,也支持本地部署模型(如 Ollama)知识库管理:可上传 PDF、Word、Excel、网页链接等文件,构建本地结构化数据库,通过 RAG 技术实现智能检索,支持向量化处理和来源标注预置智能体: 内置 300+ 行业助手(如翻译、编程、营销),支持自定义提示词(Prompt)创建专属 AI 应用多模态处理: 支持文本生成、图像生成(集成硅基流动等平台)、代码高亮、Markdown 渲染及文件格式转换
下面我们看看如何搭建
下载安装
设置图标选择模型服务,选择本地的 ollama 服务,
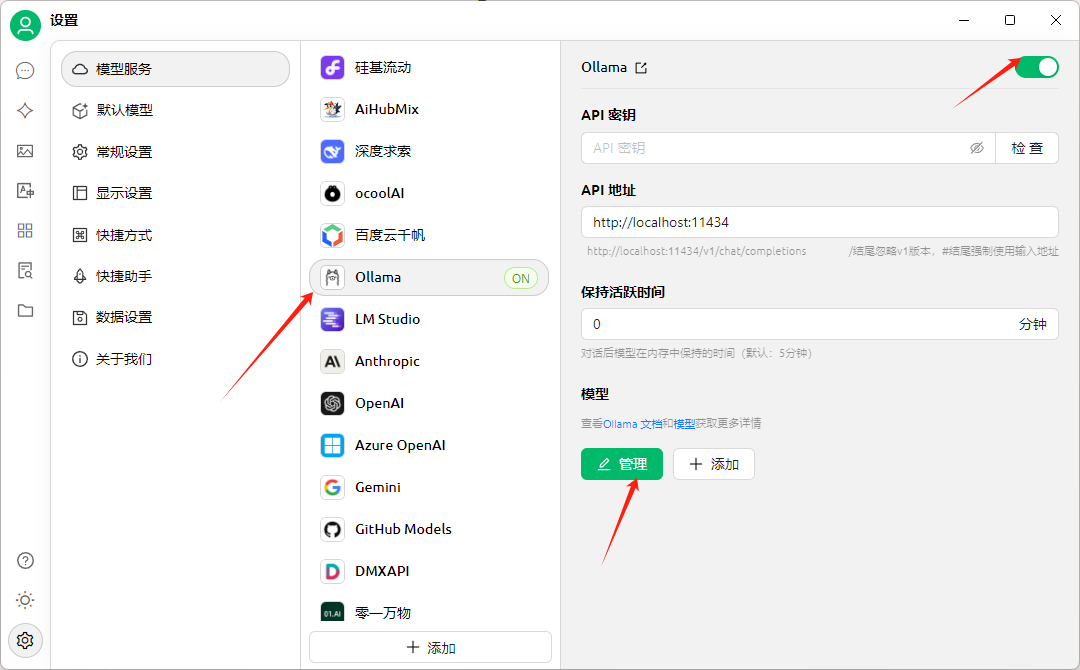
模型配置
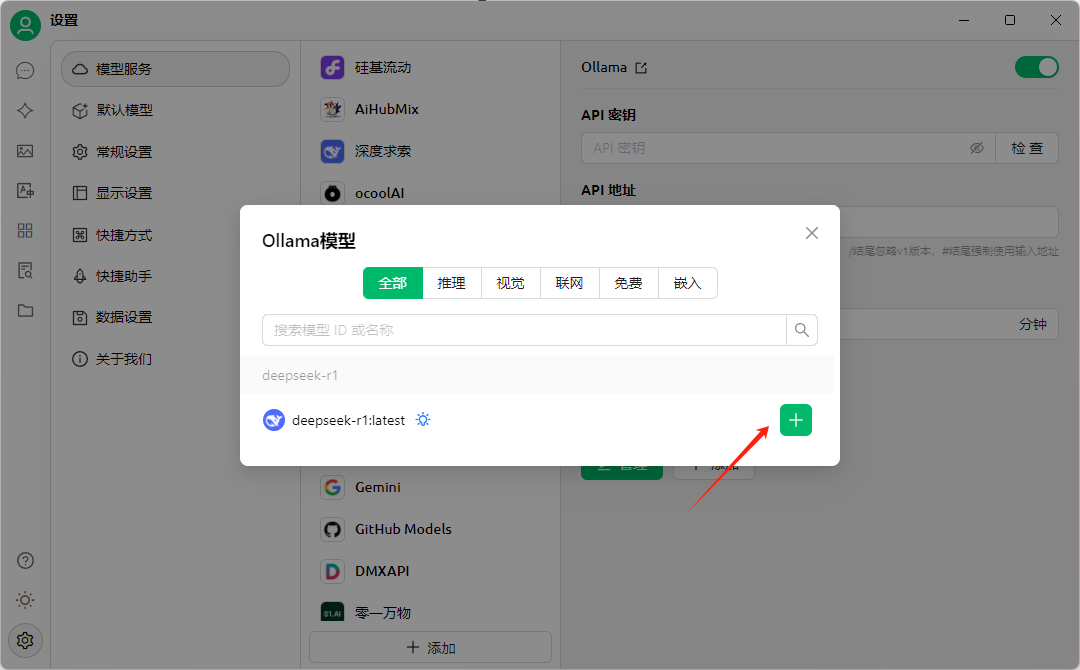
选择我们之前 pull 的模型
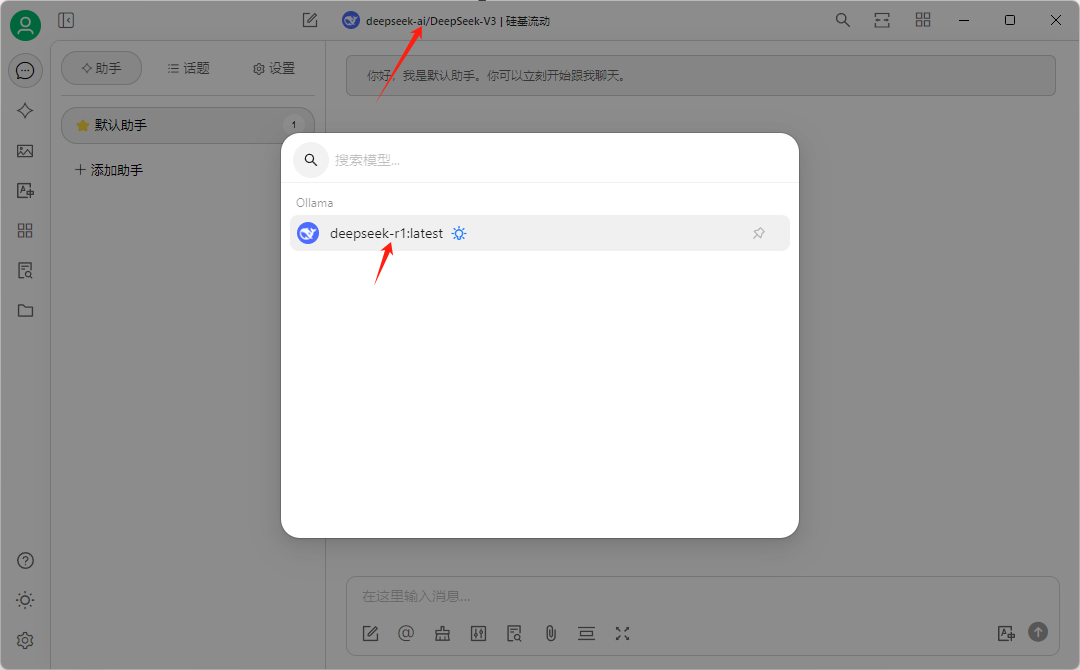
然后在默认助手中作简单测试
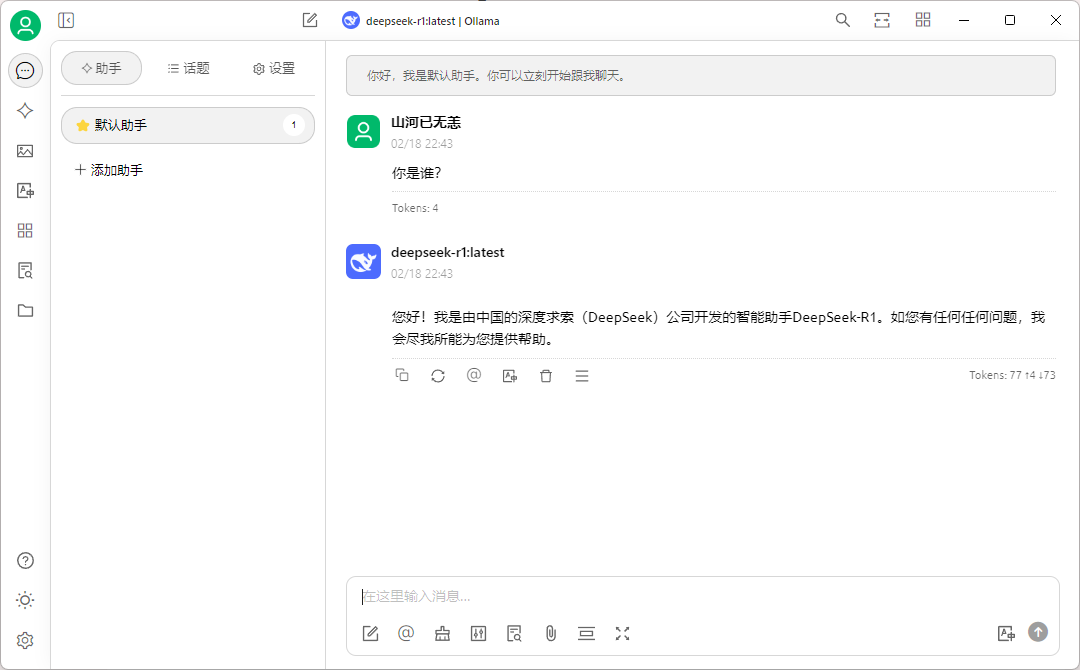
选择知识库图标,创建知识库,添加嵌入模型
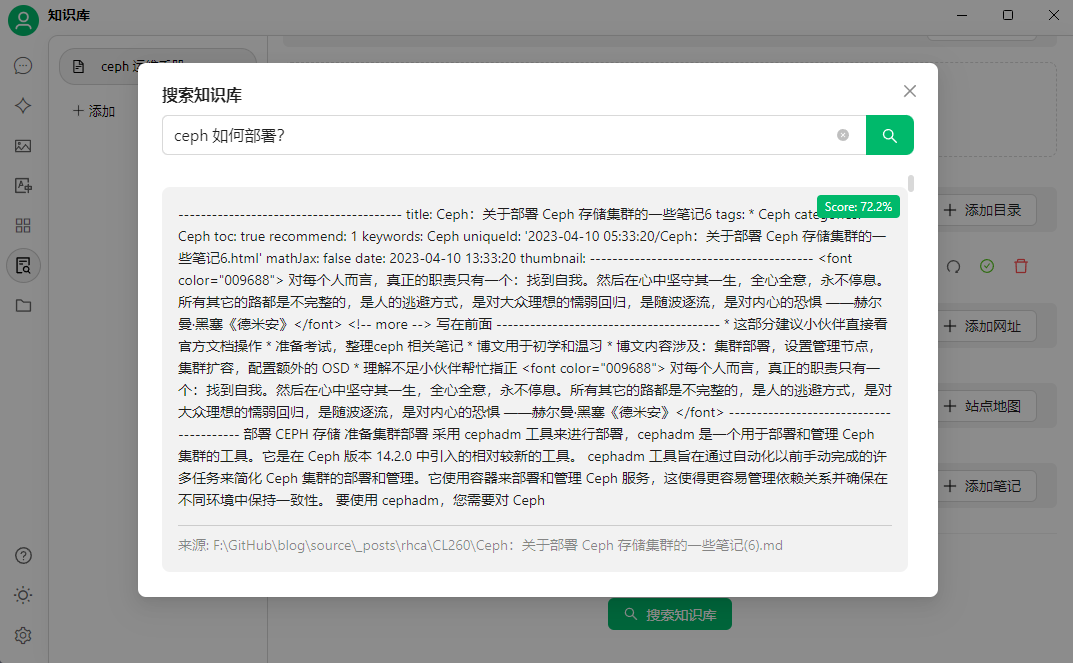
然后上传要创建知识库的文件,可以通过搜索知识库简单测试
然后就可以提问了,选择一开始添加的本地模型,提问的时候选择知识库
文档中的内容做简单问答测试
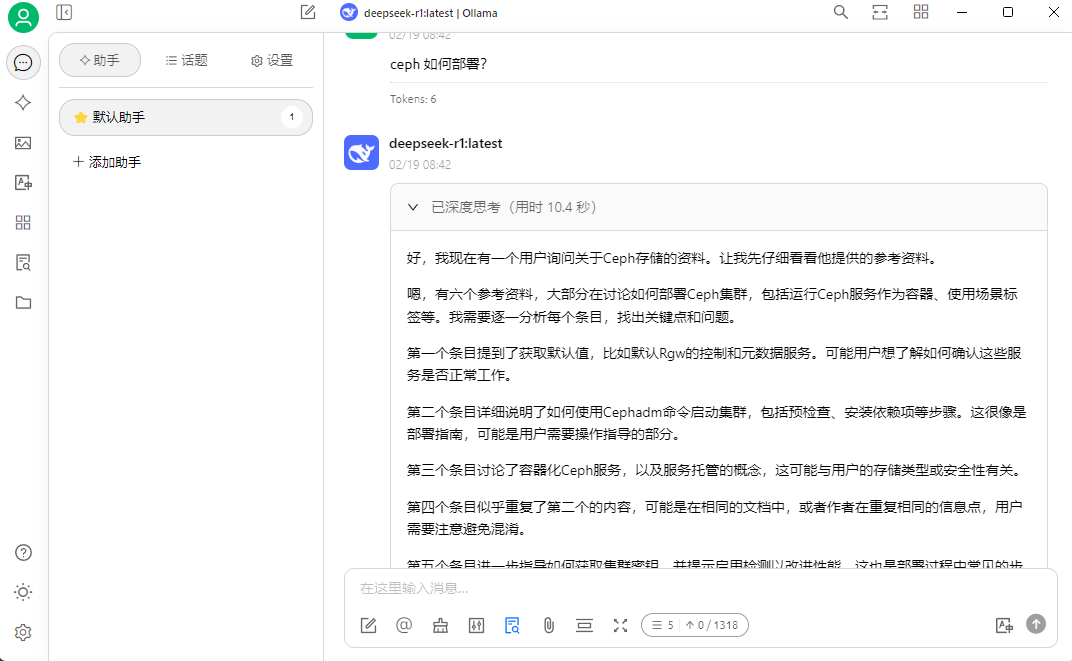
引用知识库中的内容
AnythingLLM + DeepSeek
AnythingLLM 同样是一个全栈应用程序,可以使用现成的商业大语言模型或流行的开源大语言模型,再结合向量数据库解决方案构建一个私有ChatGPT,不再受制于人:您可以本地运行,也可以远程托管,并能够与您提供的任何文档智能聊天。
官网下载地址: https://anythingllm.com/
文档地址: https://docs.anythingllm.com/
项目地址: https://github.com/Mintplex-Labs/anything-llm/blob/master/locales/README.zh-CN.md
下载安装包:
直接安装即可,安装完后会有如下的界面

选择本地的模型
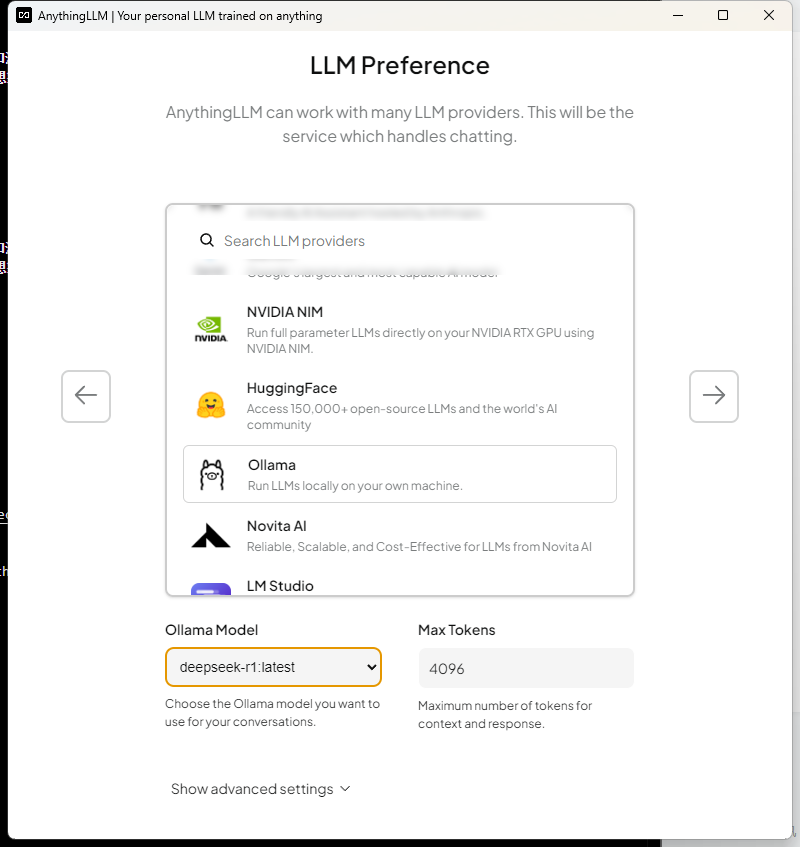
之后一直下一步,创建工作区
然后在新工作区,选择下面的箭头
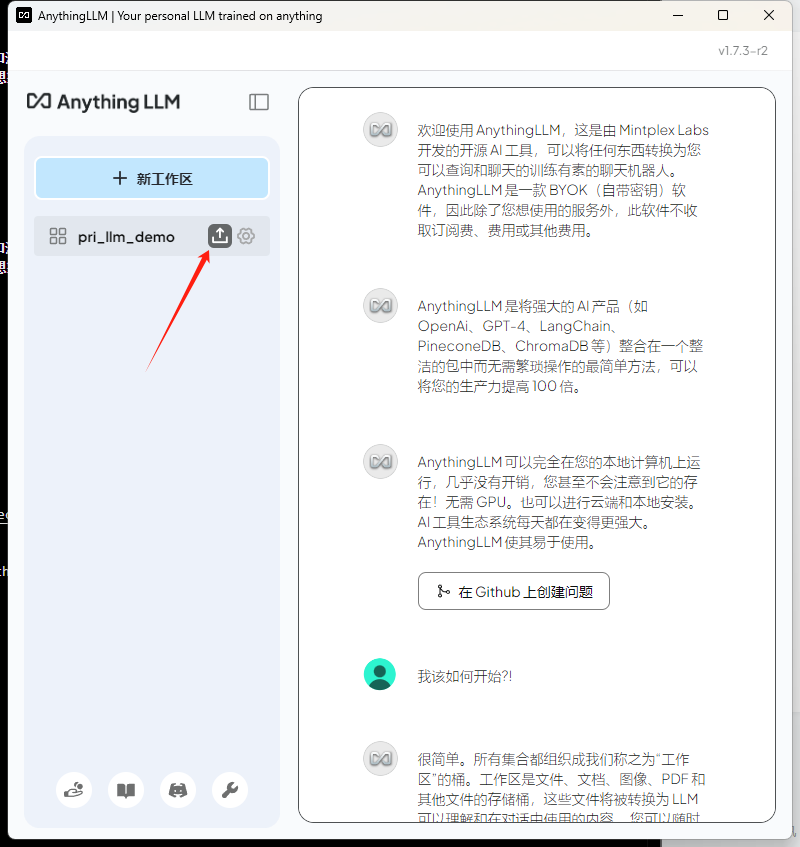
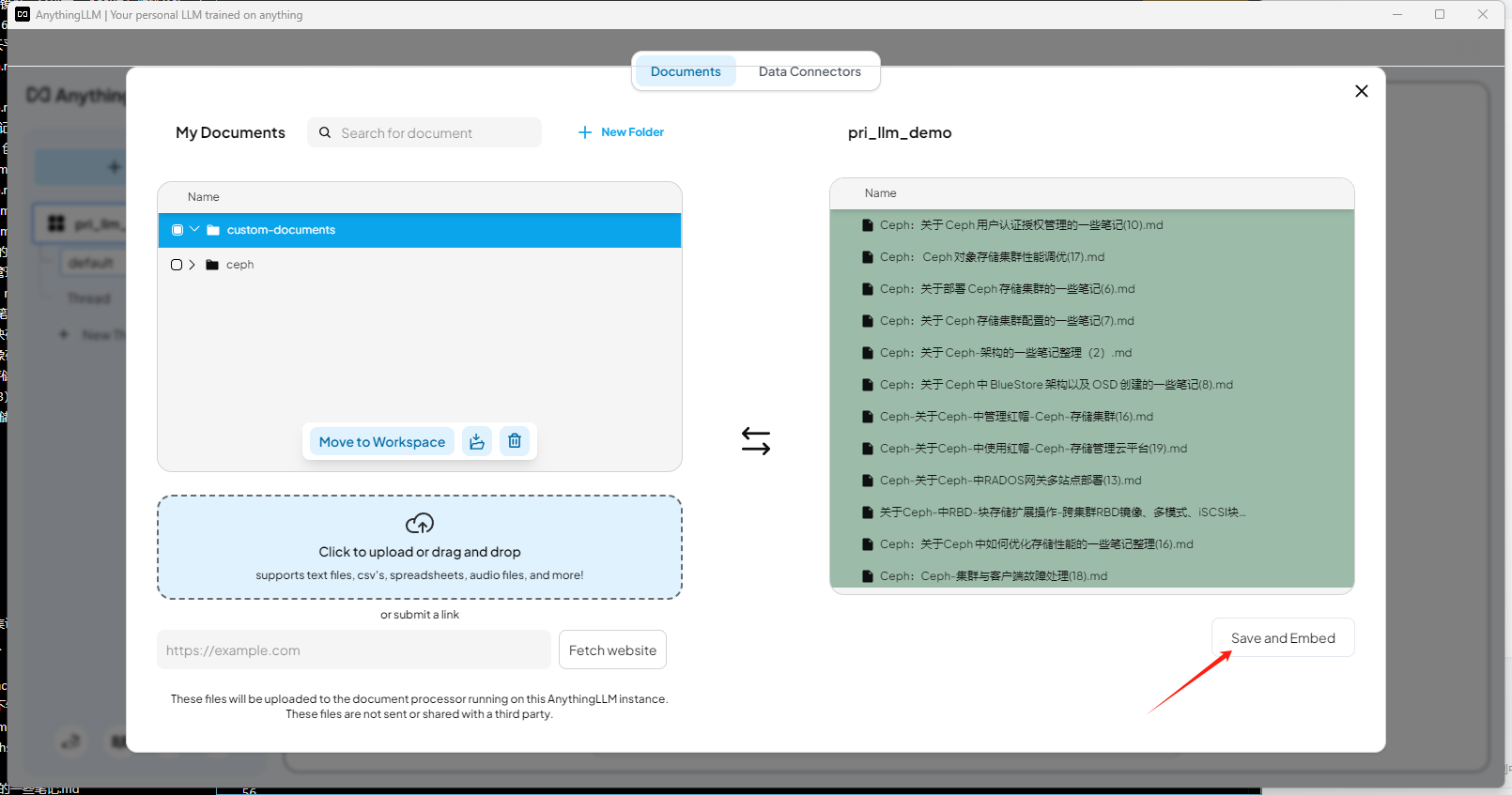
导入知识库文档
添加到工作区
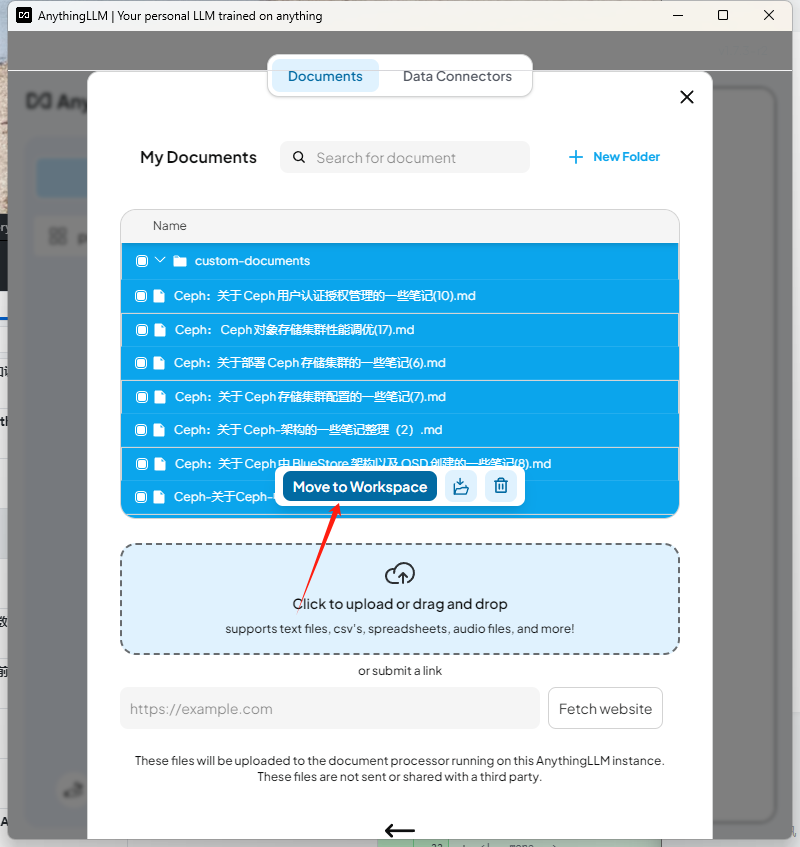
选择启用
问一个知识库相关的问题测试
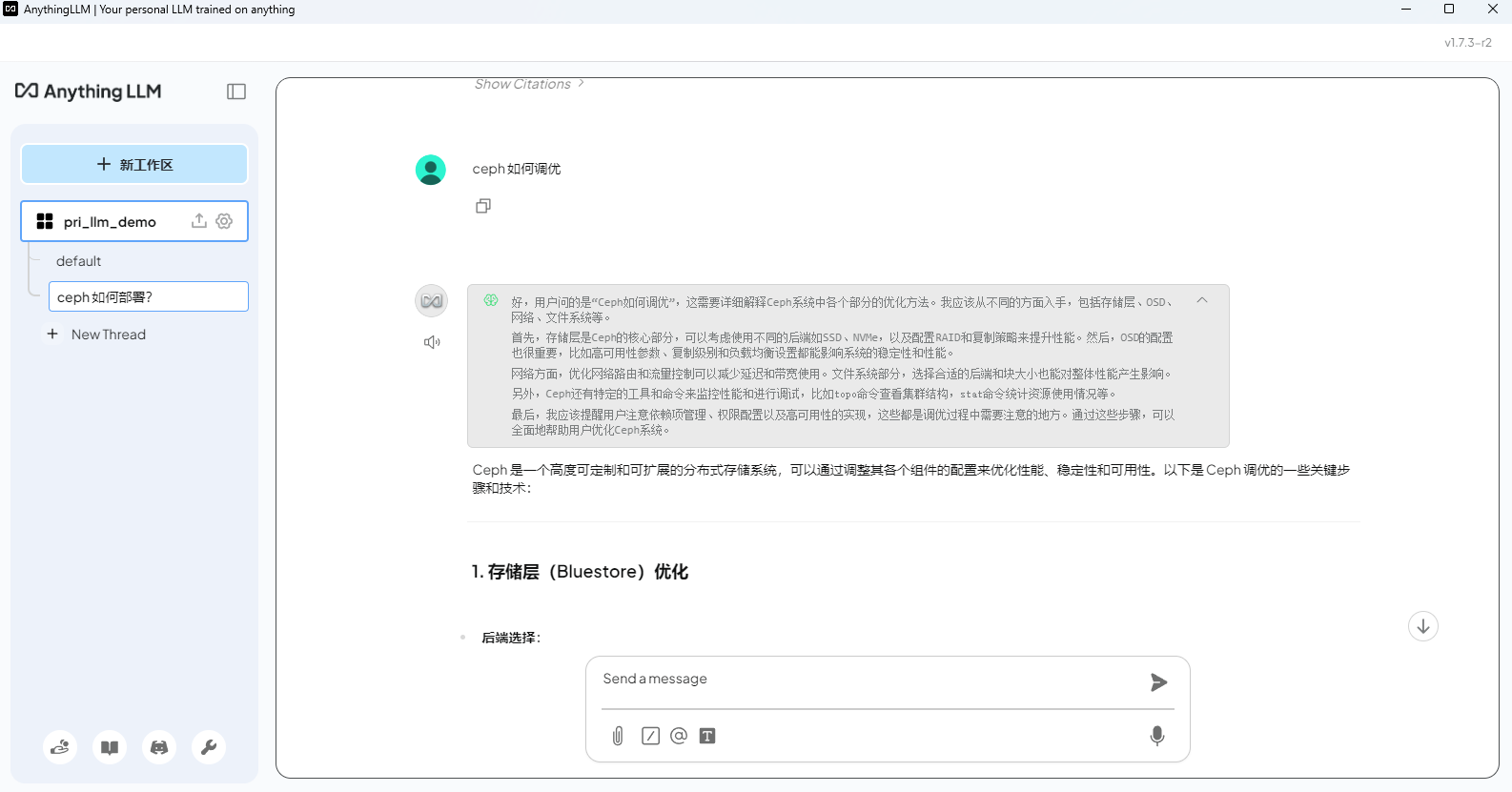
最下面会列出引用的文档
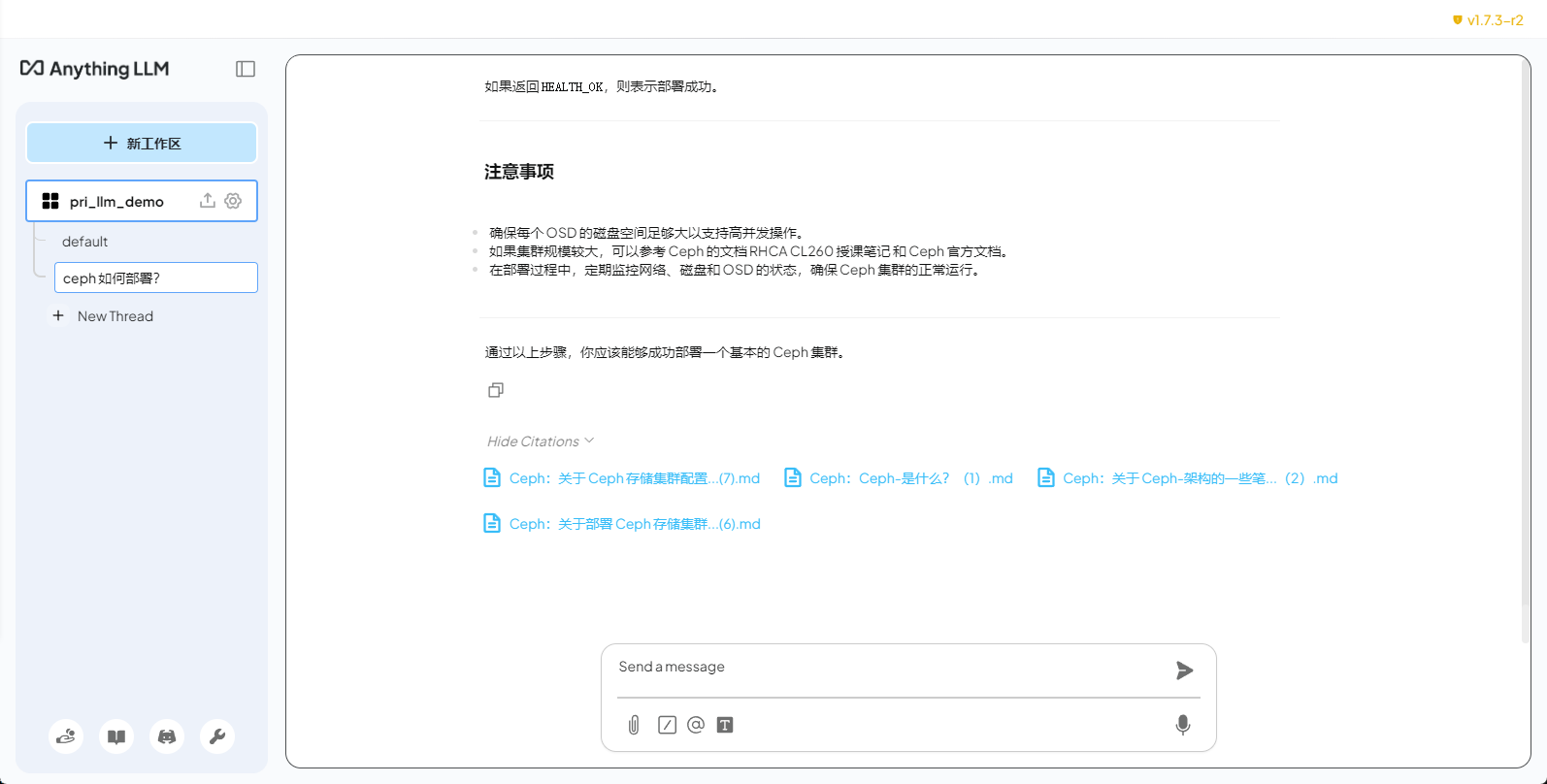
LLM 相关配置可以在设置中设置
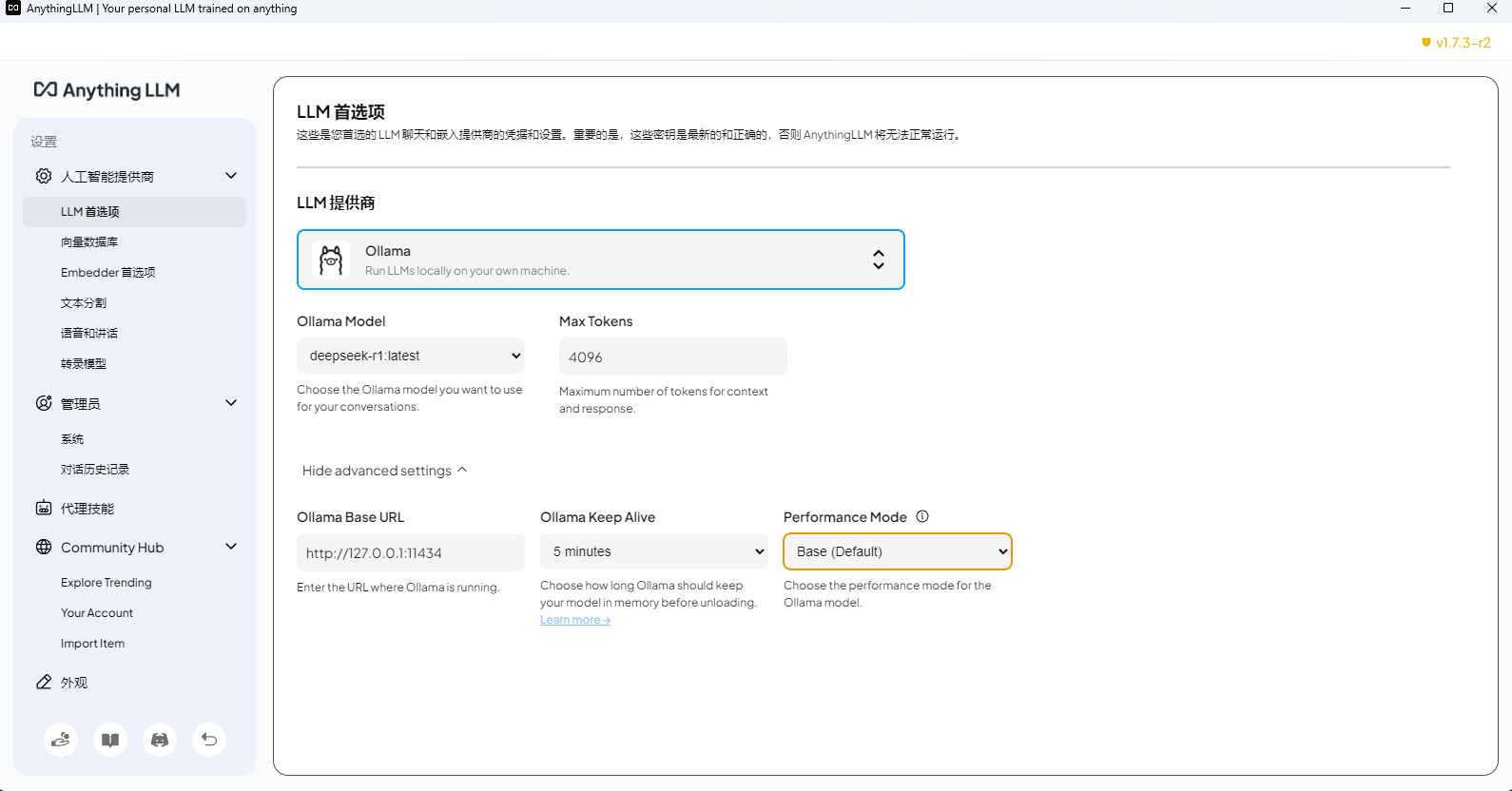
AnythingLLM 和 Cherry Studio 都是客户端,所以 ollama 的推理模型直接设置 本地回环地址就可以
整体来看,Ragflow 相对专业一点,其次是 Dify ,Cherry Studio ,AnythingLLM ,但是前两个相对部署较重,后两个客户端,可以直接客户端部署。
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 😃
https://ragflow.io
https://dify.ai/zh
https://cherry-ai.com/
https://anythingllm.com/
© 2018-至今 liruilonger@gmail.com, 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)