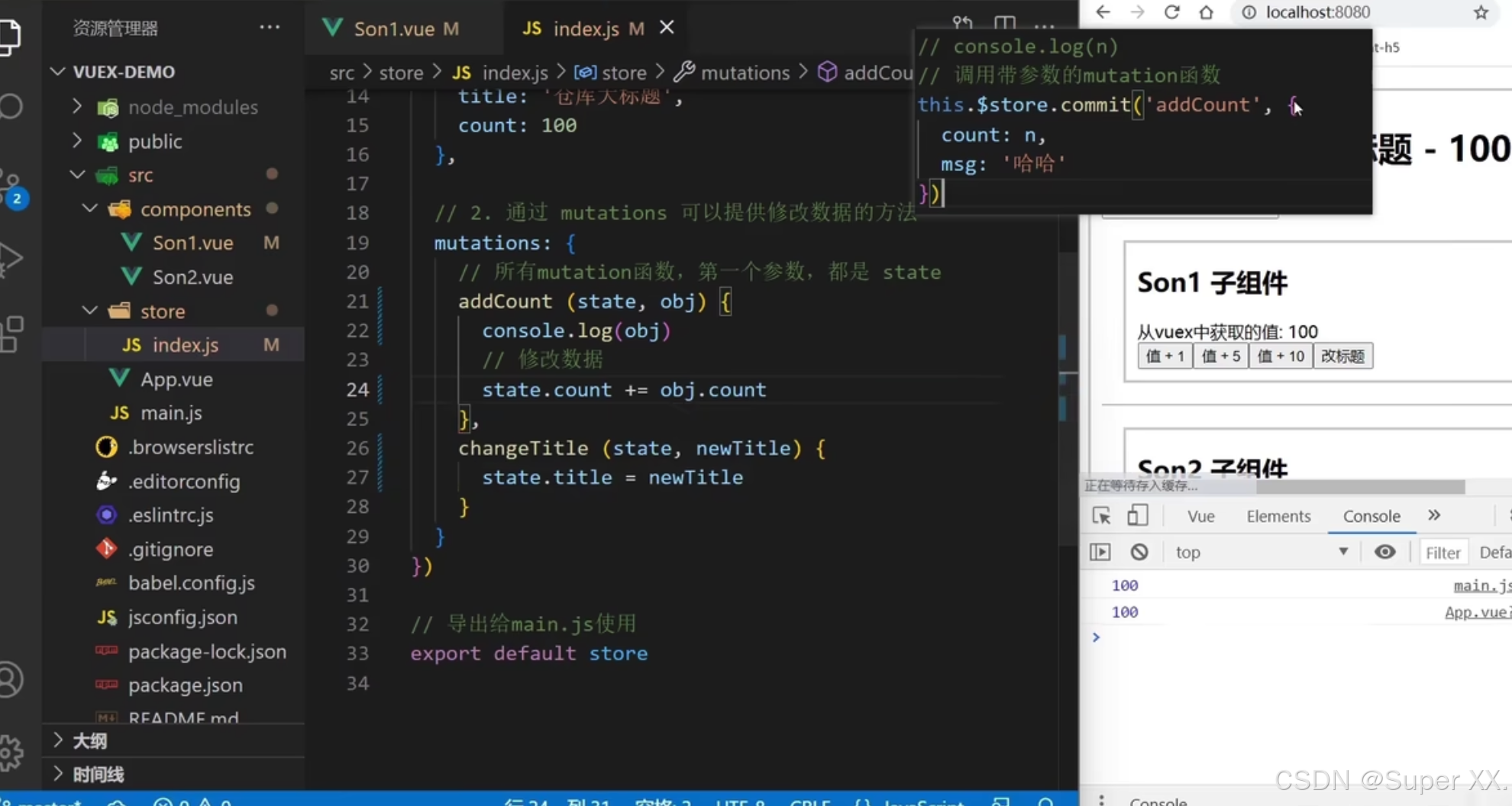
在本篇中,我们通过播客相似性搜索为例,进一步研究基于chroma 的相似性搜索:
参考:
https://www.kaggle.com/code/switkowski/building-a-podcast-recommendation-engine/notebook
数据集来源:
https://www.kaggle.com/code/switkowski/building-a-podcast-recommendation-engine/input
数据的预处理
import pandas as pd
#print(os.listdir("./input"))
from IPython.core.interactiveshell import InteractiveShell
def preprocessor(file):
InteractiveShell.ast_node_interactivity = "all"
podcasts = pd.read_csv('./input/podcasts.csv')
podcasts = podcasts[podcasts.language == 'English']#选择英语的项目
podcasts = podcasts.dropna(subset=['description'])#删除缺失 description 的项目
podcasts = podcasts.drop_duplicates('itunes_id')#删除重复的itunes_id
sum(podcasts.description.isnull())
podcasts['description_length'] = [len(x.description.split()) for _, x in podcasts.iterrows()]
#podcasts['description_length'].describe()#显示description_length的统计摘要
podcasts = podcasts[podcasts.description_length >= 20]#选择长度>20的项目
podcasts = podcasts[0:10].reset_index(drop=True)#选择前10个项目,并且重新index 编号,不连续的index 变成连续
return podcasts
new_list=preprocessor('./input/podcasts.csv')
for index,row in new_list.iterrows():
print("index:",index)
print (row["description"])搜索
#https://www.kaggle.com/code/switkowski/building-a-podcast-recommendation-engine?select=episodes.csv
#https://www.aicrowd.com/challenges/spotify-million-playlist-dataset-challenge#task
import pandas as pd
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
print(os.listdir("./input"))
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
podcasts = pd.read_csv('./input/podcasts.csv')
podcasts = podcasts[podcasts.language == 'English']
podcasts = podcasts.dropna(subset=['description'])
podcasts = podcasts.drop_duplicates('itunes_id')
sum(podcasts.description.isnull())
podcasts['description_length'] = [len(x.description.split()) for _, x in podcasts.iterrows()]
podcasts['description_length'].describe()
podcasts = podcasts[podcasts.description_length >= 20]
favorite_podcasts = ['The MFCEO Project', 'Up and Vanished', 'Lore']
favorites = podcasts[podcasts.title.isin(favorite_podcasts)]
favorites
podcasts = podcasts[~podcasts.isin(favorites)].sample(15000)
data = pd.concat([podcasts, favorites], sort = True).reset_index(drop = True)
tf = TfidfVectorizer(analyzer = 'word', ngram_range = (1, 3), min_df = 0, stop_words = "english")
tf_idf = tf.fit_transform(data['description'])
tf_idf
similarity = linear_kernel(tf_idf, tf_idf)
similarity
x = data[data.title == 'Up and Vanished'].index[0]
similar_idx = similarity[x].argsort(axis = 0)[-4:-1]
for i in similar_idx:
print(similarity[x][i], '-', data.title[i], '-', data.description[i], '\n')
print('Original - ' + data.description[x])
x = data[data.title == 'Lore'].index[0]
similar_idx = similarity[x].argsort(axis = 0)[-4:-1]
for i in similar_idx:
print(similarity[x][i], '-', data.title[i], '-', data.description[i], '\n')
print('Original - ' + data.description[x])使用TfidfVectorizer将选出来的播客的描述矢量化。
使用linear_kernel 找出两两之间播客描述的相似性。
找出与“Up and Vanished” ,“Lore”相似的播客
倒数第4个到倒数第1个。
similar_idx = similarity[x].argsort(axis = 0)[-4:-1]
将结果打印出来
for i in similar_idx:
print(similarity[x][i], '-', data.title[i], '-', data.description[i], '\n')将 “Up and Vanished” ,“Lore”的标题和描述打印出来。
DeepSeek 的解释笔记
TfidfVectorizer
TfidfVectorizer 是 自然语言处理(NLP) 中常用的工具,用于将文本数据转换为数值特征向量。它是 scikit-learn 库中的一个类,结合了 TF(词频,Term Frequency) 和 IDF(逆文档频率,Inverse Document Frequency) 两种统计方法,能够有效地表示文本数据并捕捉其重要特征。
TfidfVectorizer 的主要参数
以下是 TfidfVectorizer 的一些常用参数:
-
input: 输入类型,可以是文件名、文件对象或文本内容(默认是content)。 -
encoding: 文本编码方式(默认是utf-8)。 -
lowercase: 是否将文本转换为小写(默认是True)。 -
stop_words: 是否移除停用词(如“的”、“是”等),可以设置为'english'或自定义列表。 -
max_df: 忽略在超过一定比例的文档中出现的单词(用于去除常见词)。 -
min_df: 忽略在少于一定数量的文档中出现的单词(用于去除罕见词)。 -
ngram_range: 指定 n-gram 的范围,例如(1, 1)表示只使用单词,(1, 2)表示使用单词和二元词组。 -
max_features: 限制特征向量的最大维度(即最多保留多少个单词)。
使用示例
以下是一个简单的示例,展示如何使用 TfidfVectorizer 将文本数据转换为 TF-IDF 特征矩阵:
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文本数据
documents = [
"我喜欢机器学习",
"机器学习很有趣",
"自然语言处理是机器学习的一个分支"
]
# 初始化 TfidfVectorizer
vectorizer = TfidfVectorizer()
# 拟合并转换文本数据
tfidf_matrix = vectorizer.fit_transform(documents)
# 查看结果
print("TF-IDF 特征矩阵:")
print(tfidf_matrix.toarray()) # 转换为稠密矩阵并打印
print("\n词汇表:")
print(vectorizer.get_feature_names_out()) # 打印词汇表输出结果
TF-IDF 特征矩阵:
[[0. 0. 0.70710678 0.70710678 0. 0. ]
[0.57735027 0.57735027 0. 0. 0.57735027 0. ]
[0. 0. 0. 0. 0.40824829 0.81649658]]
词汇表:
['一个' '分支' '喜欢' '很有趣' '是' '机器学习']
-
TF-IDF 特征矩阵:每一行对应一个文档,每一列对应一个单词,值是该单词的 TF-IDF 权重。
-
词汇表:列出了所有被提取的单词。
应用场景
-
文本分类
将文本转换为 TF-IDF 特征后,可以用于训练分类模型(如朴素贝叶斯、支持向量机等)。 -
信息检索
计算查询词与文档的 TF-IDF 相似性,用于搜索引擎排名。 -
文本聚类
使用 TF-IDF 特征对文本进行聚类分析。 -
推荐系统
计算用户评论或商品描述的 TF-IDF 特征,用于推荐相似商品。
优点
-
简单高效:能够快速将文本数据转换为数值特征。
-
捕捉关键词:通过 TF-IDF 权重,能够突出文档中的重要单词。
-
降噪:通过移除停用词和低频词,减少噪声。
局限性
-
无法捕捉语义:TF-IDF 只考虑词频和文档频率,无法理解单词的语义。
-
稀疏性问题:对于大规模语料库,TF-IDF 矩阵可能会非常稀疏,导致计算效率下降。
-
依赖预处理:需要配合分词、去停用词等预处理步骤才能发挥最佳效果。
总结
TfidfVectorizer 是一个强大的工具,能够将文本数据转换为数值特征,适用于文本分类、聚类、信息检索等任务。它是 NLP 中常用的特征提取方法之一,尤其适合处理中小规模的文本数据。如果需要捕捉语义信息,可以结合词嵌入(如 Word2Vec、BERT)等方法使用。
开启新对话
linear_kernel
linear_kernel 的主要用途是计算两个向量或矩阵之间的线性核(Linear Kernel),也就是它们的点积(dot product)。它在机器学习和数据科学中常用于衡量样本之间的相似性,尤其是在使用核方法(Kernel Methods)或支持向量机(SVM)时。
假设我们有以下两个矩阵 XX 和 YY,分别表示两组样本的特征向量:
python
复制
import numpy as np
from sklearn.metrics.pairwise import linear_kernel
# 样本特征矩阵
X = np.array([[1, 2, 3], [4, 5, 6]]) # 2个样本,每个样本有3个特征
Y = np.array([[7, 8, 9], [10, 11, 12]]) # 2个样本,每个样本有3个特征
# 计算线性核
kernel_matrix = linear_kernel(X, Y)
print(kernel_matrix)输出结果:
[[ 50 68]
[122 167]]这里的输出是一个相似性矩阵,其中每个元素 (i,j)(i,j) 表示 XX 中第 ii 个样本与 YY 中第 jj 个样本的点积(即线性核值)。
优点
-
简单高效
线性核的计算非常简单,只需要计算点积,因此计算速度快。 -
适合线性可分数据
如果数据本身是线性可分的,线性核可以直接用于分类或回归任务。 -
可解释性强
线性核的结果易于解释,因为它直接反映了样本在特征空间中的方向相似性。
局限性
-
不适合非线性数据
如果数据是非线性可分的,线性核可能无法捕捉复杂的模式。此时可以使用其他核函数,如 RBF 核(高斯核)或多项式核。 -
表达能力有限
线性核只能捕捉线性关系,无法处理更复杂的特征交互。
总结
linear_kernel 是一个简单但非常有用的工具,主要用于计算样本之间的线性相似性。它在支持向量机、文本分类、推荐系统等任务中都有广泛应用。如果你的数据是线性可分的,或者你需要一个高效的相似性度量方法,linear_kernel 是一个很好的选择。
结论
DeepSeek 对于程序猿学习帮助非常大,从本文开始,我会在博文中添加一些DeepSeek 提示的笔记。
在下面,我们会进一步地讨论急于大模型Embedding 的相似性搜索的编程