🌍杭州:全球数贸港核心区建设方案拟出台 争取国家支持杭州在网络游戏管理给予更多权限
🎄Kimi深夜炸场:满血版多模态o1级推理模型!OpenAI外全球首次!Jim Fan:同天两款国产o1绝对不是巧合!
✨切尔诺贝利核电站传出爆炸声 泽连斯基发声
14日1时50分左右,切尔诺贝利核电站的“新安全封隔”设施内传出爆炸声并出现火情,该封隔设施负责保护切尔诺贝利核电站4号反应堆。据了解,一架无人机撞上了“新安全封隔”设施顶部。
1.Seed Research | 视频生成模型最新成果,可仅靠视觉认知世界!现已开源
1. 模型仅靠“视觉”即可学习知识
面向本次研究,研究团队构建了两个实验环境:视频围棋对战和视频机器人模拟操控。
其中,围棋可以很好地评估模型的规则学习、推理和规划能力,且围棋关键信息仅有黑白两色及棋盘,可将外观、纹理等复杂细节与高级知识的评估分离,非常适合对上述问题的探索。同时,团队还选取了机器人任务,以考察模型在理解控制规则和规划任务方面的能力。
在模型训练环节,团队构建了一个包含大量视频演示数据的离线数据集,让模型“观看”学习,以此得到一个可以根据过往观测,预测未来画面的视频生成器。
模型架构上,团队使用朴素的自回归模型实例化视频生成器,它包含一个 VQ-VAE 编码器 - 解码器和一个自回归 Transformer 。编码器负责将视频帧(画面)转换为离散标记,Transformer 在训练期间使用这些标记预测下一标记。
在推理过程中,Transformer 生成下一帧(画面)的离散标记,这些标记随后由解码器转换回像素空间。通过任务相关的映射函数,模型可将生成画面转换为任务执行动作。这让视频生成实验模型可在不依赖任何动作标签情况下,学习和执行具体任务。
基于上述朴素的框架对围棋和机器人视频数据进行建模,团队观测到,模型可以掌握基本的围棋规则、走棋策略以及机器人操纵能力。
但团队同时也发现,视频序列的知识挖掘效率显著落后于文本形式,具体如下图所示。

团队将这归因于——视频中存在大量冗余信息,影响了模型的学习效率。
例如,学习棋子移动过程中,模型只需通过状态序列中少量位置标记编码,但面向视频数据,编码器则会产生过多冗余标记,不利于模型对复杂知识的快速学习。
2. 压缩视觉变化,让视频学习更加高效
根据上述观测结果,团队提出 VideoWorld 。它在保留丰富视觉信息的同时,压缩了关键决策和动作相关的视觉变化,实现了更有效的视频学习。
通常,视频编码需要数百或数千个离散标记来捕捉每帧内的视觉信息,这导致知识被稀疏地嵌入标记中。为此,VideoWorld 引入了一个潜在动态模型(Latent Dynamics Model, LDM),可将帧间视觉变化压缩为紧凑的潜在编码,提高模型的知识挖掘效率。
举例而言,围棋中的多步棋盘变化或机器人连续动作均表现出强时间相关性,通过将这些多步变化压缩成紧凑嵌入,不仅让策略信息更紧凑,还将前向规划指导信息进行编码。
LDM 采用了 MAGVITv2 风格的编码器 - 解码器结构,同时取消时间维度下采样,以保留每帧细节。
对于一个视频片段,LDM 采样每一帧及其后续固定数量帧,编码器先以因果方式提取每帧特征图,且进行量化,以保留详细视觉信息。
接下来,LDM 定义了一组注意力模块和对应可学习向量。每个向量通过注意力机制捕捉第一帧至后续固定帧的动态变化信息,然后通过 FSQ 量化。其中,量化器作为信息筛选器,防止 LDM 简单记忆后续帧原始内容,而非压缩关键动态信息。
最后,解码器使用第一帧的特征图和帧之间的视觉变化编码重建后续帧,最终实现对未来动作的预测和规划,实现对知识的认知学习。
下图为模型架构概览,左侧为整体架构,右侧为潜在动态模型。

通过使用多个向量顺序编码第一帧到后续多帧的动态变化,VideoWorld 实现了紧凑且信息丰富的视觉表示,可以捕捉视觉序列中的短期和长期依赖关系。这对于长期推理和规划任务至关重要。
通过引入 LDM ,VideoWorld 在仅有 300M 参数量下,达到专业 5 段的 9x9 围棋水平,且不依赖任何强化学习中的搜索或奖励函数机制。在机器人任务上,VideoWorld 也展现出了对多任务、多环境的泛化能力。 3. 纯视觉模型可“预测”未来,并能“理解”因果关系觉模型可“预测”未来,并能“理解”因果关系
3.纯视觉模型可“预测”未来,并能“理解”因果关系
针对 LDM 提高视频学习效率的原因,团队进行了更为细致地分析,得出如下 3 点结论:
- LDM 建模了训练集的数据模式。
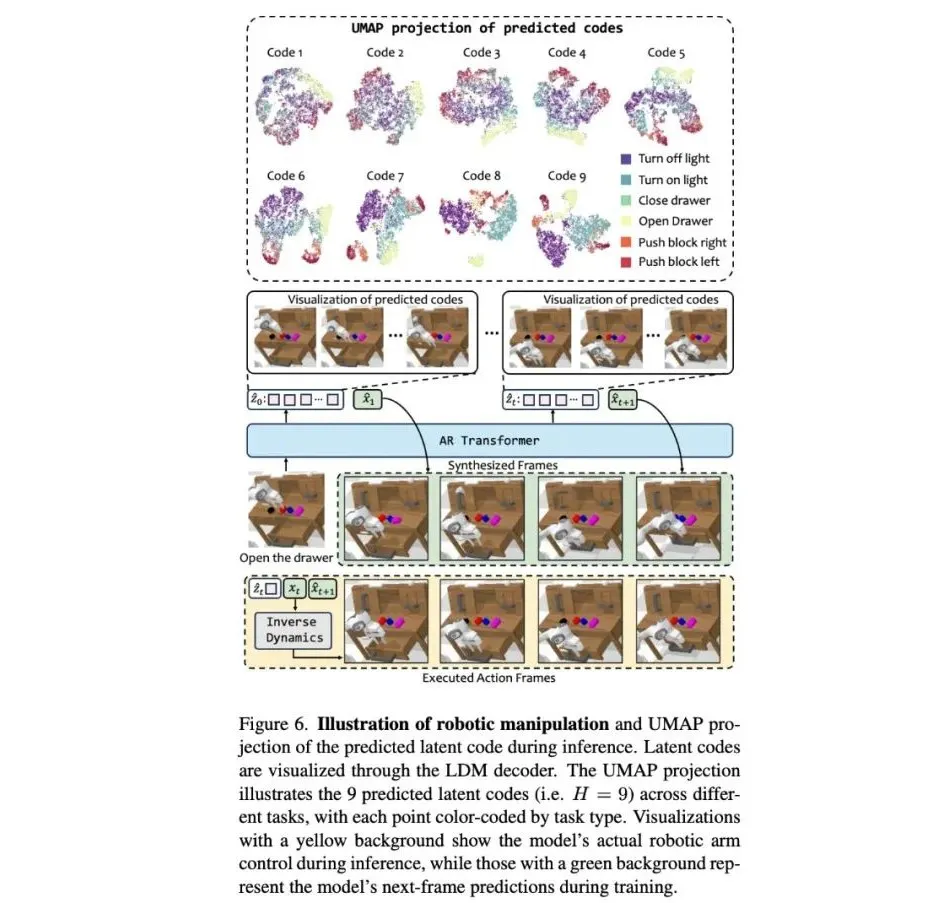
下图为 LDM 潜在编码 UMAP 可视化呈现,面向围棋和机器人训练集,每个点代表一个潜在编码。
其中,UMAP 是一种流行的降维算法,用于将高维数据映射到低维空间,展现模型特征提取情况。
在下图左侧中,奇数步表示白方走棋,偶数步表示黑方,图例展示了新增黑棋的一些常见模式。UMAP 可视化表明:LDM 建模了训练集中常见的走棋模式,并能将短期和长期数据模式压缩至潜在空间中,提取并总结走棋规律。
同理,下图右侧为机械臂沿 X/Y/Z 轴运动方向可视化潜在编码,随着步数(Step)增多,也能看到 LDM 可以建模多步动态依赖关系。

- LDM 帮助模型在测试时进行前向规划。
团队还研究了 LDM 在模型推理中的价值。
如下图 UMAP 可视化所示,在测试阶段,模型生成的潜在编码按照时间步(Time-step)进行分组,使得模型能够从更长远视角进行围棋决策。

在机器人场景实验中,团队也观察到了类似现象。
下图展示了 VideoWorld 在不同机器人操控任务中预测的潜在编码。不同时间步的潜在编码根据任务类型进行分组,突显了模型逐步捕捉特定任务长程变化的能力。
- LDM 可以生成因果相关的编码。
为进一步研究潜在编码的影响,团队进行了一项干预实验:用随机标记替换不同时间步的潜在编码,并观察其对模型性能的影响。
实验结果显示,干预第一个编码的影响最大,这可能由于编码之间存在因果依赖,团队认为:改变第一个编码,即下一时间步的最佳决策,会影响所有未来的决策,侧面说明模型可生成因果相关编码,理解因果关系。
2.苹果据称继续与百度合作 为中国iPhone用户开发AI功能 以分散风险
据媒体援引消息人士报道,尽管与阿里巴巴建立了合作关系,但苹果公司仍继续与百度合作,为中国iPhone用户开发人工智能(AI)功能。
据悉,百度正在开发一种能处理图片和文本的AI搜索功能,并对中文版Siri语音助手进行升级,这些功能属于“Apple Intelligence”(苹果智能)套件的一部分。
苹果在去年的WWDC(全球开发者大会)上首次公布了Apple Intelligence,并宣布与AI公司OpenAI合作。去年12月,Apple Intelligence在美国、英国、澳大利亚和加拿大等英语国家率先上线。
有消息称苹果自 2023 年起开始测试来自中国开发者的不同AI模型,以推出面向中国市场的Apple Intelligence,并且一度选择了百度作为主要合作伙伴。
据媒体周二报道称,苹果近几个月开始考虑其他选项,除了腾讯、阿里和字节跳动等中国互联网巨头外,该公司还测试了近来火爆的AI初创公司深度求索(DeepSeek)的AI模型。
这一消息公布后,苹果和阿里股价均大幅上涨。
在经过权衡之后,苹果最终选择了与阿里合作开发AI功能。阿里董事局主席蔡崇信周四在迪拜的一场峰会上证实了这一合作关系。
苹果同时与百度和阿里合作,显示出其在中国市场采取了多方合作的策略,以降低风险。苹果在中国市场面临着来自华为和Vivo等本土智能手机品牌的激烈竞争。
在国际市场,Apple Intelligence依靠的是苹果自研AI模型和与OpenAI的合作,后者的聊天机器人ChatGPT在处理iPhone的复杂任务上发挥了更多作用。
3.Anthropic秘密「混合模型」 Claude 4首曝细节,硬刚GPT-5!深度推理模型来了
Anthropic终于要开始搞点事情啦!
近期的「推理模型」热潮中,Anthropic除了其CEO打了几个嘴炮外,还没有掏出一个拿得出手的产品。
在这样下去,可能要退出AI一线模型玩家行列了。Anthropic自己显然不想看到这种情况发生。
就在刚刚,有消息称,Anthropic会在未来几周内发布其全新的「混合AI」模型。
Anthropic版「推理模型」,测试时计算完全掌控
在OpenAI去年秋季发布其「推理模型」后,谷歌以及国内众多AI公司纷纷推出了自己的模型。作为一个主要的竞争对手,Anthropic在这场推理竞赛中却明显缺席。
现在,我们知道了原因——Anthropic开发的是一款融合了推理能力的混合AI模型。
具体来说,这种「混合模型」可以使用更多的计算资源来计算复杂问题,但也能像传统LLM一样快速处理更简单的任务,无需额外计算。
此外,模型还可以让客户控制它在查询时使用的算力——换句话说就是,它在解决问题时「推理」的时长。
开发者可以通过一个滑动条来调整模型在尝试找出答案或完成任务时将处理或生成的token数量。
通过将滑动条设置为「0」,开发者可以将Anthropic模型作为一个普通的、非推理AI使用,类似于OpenAI的GPT-4o。
OpenAI也有类似的功能,允许开发者控制其推理模型「思考」的时间。
但开发者仅限于「低」、「中」和「高」三种设置,很难预测模型在这些级别上实际会处理多少token——因此,也很难预测单次查询的成本。
现在,OpenAI可能转而成为追随者。
2月13日,CEO Sam Altman表示,OpenAI计划将其Orion大语言模型作为GPT-4.5发布——这是一个传统的、非推理模型。之后,则会把GPT模型和o系列推理模型合并为一个单一的AI。
在外界看来,这和Anthropic尚未公开的技术路线可谓是如出一辙。(去年11月The Information曾做过相关预测)
从Anthropic和OpenAI设计模型和产品的方式,我们可以清晰地看出它们在竞争激烈的AI市场中的战略定位。
OpenAI显然更希望ChatGPT成为面向消费者或个人专业人士的突破性应用,这可能就是它在推理模型中使用低-中-高命名法的原因,因为这更容易让普通用户理解。
Anthropic则更专注于企业市场,这就是为什么它致力于开发能让开发者通过滑动条方式更好地控制成本、速度和定价的功能。
据知情人士透露,Anthropic即将推出的模型在编程方面也取得了特别显著的进展,这已经成为生成式AI在企业中最强大的应用之一。
当允许Anthropic模型使用最长时间「思考」时,在某些编程基准测试中,它的表现已经超过了客户目前能访问到的最先进的OpenAI推理模型(即o3-mini high)。
这位人士表示,虽然OpenAI的推理模型在更学术性的问题上表现更好,比如竞争性编程问题,但Anthropic的模型更擅长处理企业工程师可能遇到的实际编程任务。
例如,Anthropic的模型更善于理解由数千个文件组成的复杂代码库,并能一次性生成可用的完整代码行。
不过,仍然悬而未决的重要问题是,Anthropic的新模型将收取多少费用,以及它是否会比OpenAI最近发布的o3-mini推理模型更便宜。后者因比OpenAI最受欢迎的非推理模型GPT-4o更便宜而给开发者留下了深刻印象。
目前还不清楚像DeepSeek和谷歌最新的Gemini模型这样的超低价AI是否会推动所有模型的价格趋近于零。
就目前来看,市场上似乎在进行着两场不同的竞争:
- 在AI开发的前沿,那些在推理或编程方面能够逐步改进的模型将继续保持定价优势;
- 在另一个更大的市场中,那些「够用就好」(good-enough)的模型则可能会继续展开价格战。
对于这个全新的「混合模型」,有网友认为,Anthropic新模型的成败将取决于它的成本,毕竟性能也很强的o3-mini是一个小模型,成本很低。
2027年收入飙至345亿美元
根据The Information的报道,Anthropic在2023年烧了56亿美元现金后,计划在2025年将支出减少近半,并在2027年实现高达345亿美元的收入。
要实现这样的增长,Anthropic需要大幅缩小与市场领导者OpenAI之间的差距。目前OpenAI的收入可能是Anthropic的5倍以上——在2027年实现4,400亿美元的收入。
Anthropic和OpenAI一直是企业在生成式AI投资方面的风向标,因此科技投资者正密切关注两家公司的表现。
在最可能的基本情况下,Anthropic表示其收入将从2025年的22亿美元增长至2027年的120亿美元。
目前外界并不知道Anthropic在2024年的具体收入,不过其月收入从年初的约800万美元上升到年底的约8,000万美元,这表明其全年收入在4亿至6亿美元之间。Anthropic即将推出的新一代旗舰模型Claude有望支持其宏伟的增长目标。据知情人士透露,新模
型预计在未来几周内发布。
然而,最近像DeepSeek这样的超低成本模型的发布,引发了人们对AI公司是否需要降价以保持竞争力的质疑。
在DeepSeek发布后,Anthropic也是少数几个没有大幅降低模型价格的AI实验室之一。
从Anthropic的融资材料来看,公司认为通过API向企业提供技术服务的机会,要大于与ChatGPT等聊天机器人竞争。
OpenAI的ChatGPT在普通用户以及程序员、营销人员和律师等专业人士群体中取得了突破性成功,截至去年底,其订阅收入每月超过3.33亿美元。



















