欢迎来到我的主页:【Echo-Nie】
本篇文章收录于专栏【机器学习】

1 sklearn相关介绍
Scikit-learn 是一个广泛使用的开源机器学习库,提供了简单而高效的数据挖掘和数据分析工具。它建立在 NumPy、SciPy 和 matplotlib 等科学计算库之上,支持多种机器学习任务,包括分类、回归、聚类、降维、模型选择和预处理等。
SKLearn官网(需要魔法): scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation

上面这张图是官网提供的,分别从回归、分类、聚类、数据降维共4个方面总结了scikit-learn的使用。
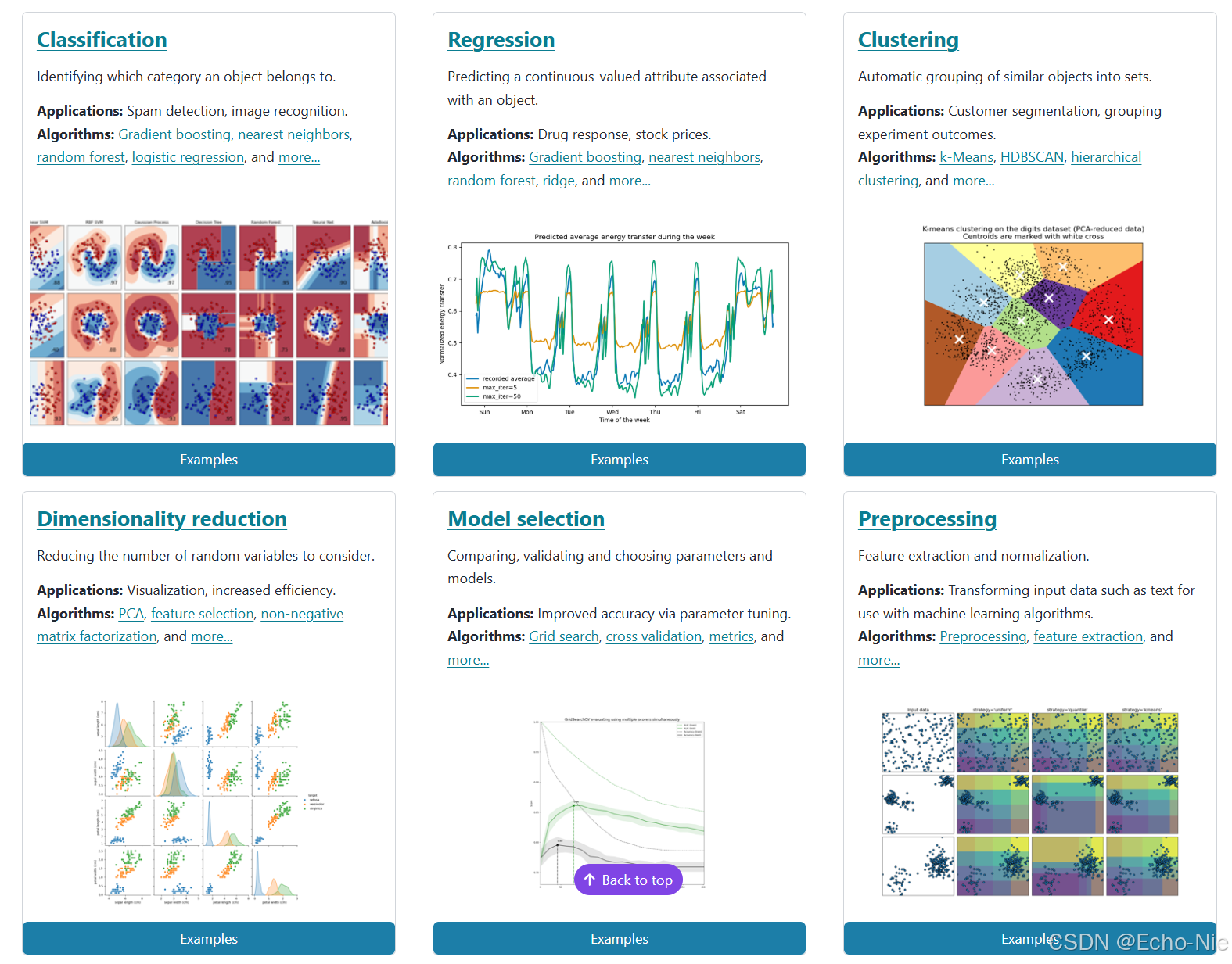
这张图的是官网主页,主要概述了机器学习的几个主要任务及其应用和常用算法:
-
分类(Classification):
定义:识别对象所属的类别。
应用:垃圾邮件检测、图像识别。
算法:梯度提升、最近邻、随机森林、逻辑回归等。
-
降维(Dimensionality Reduction):
定义:减少需要考虑的随机变量的数量。
应用:可视化、提高效率。
算法:主成分分析(PCA)、特征选择、非负矩阵分解等。
-
回归(Regression):
定义:预测与对象相关的连续值属性。
应用:药物反应、股票价格。
算法:梯度提升、最近邻、随机森林、岭回归等。
-
模型选择(Model Selection):
定义:比较、验证和选择参数和模型。
应用:通过参数调优提高准确性。
算法:网格搜索、交叉验证、评估指标等。
-
聚类(Clustering):
定义:将相似对象自动分组。
应用:客户细分、实验结果的分类。
算法:k均值、HDBSCAN、层次聚类等。
-
预处理(Preprocessing):
定义:特征提取和归一化。
应用:转换输入数据(如文本)以供机器学习算法使用。
算法:预处理、特征提取等。
2 MINIST实验准备工作
MNIST 数据集是一个经典的机器学习基准数据集,包含手写数字的灰度图像,每张图像的大小为 28×28 像素。以下是对 MNIST 数据集的加载和预处理步骤。
首先导入相关库,读取数据集。Mnist数据是图像数据:(28,28,1) 的灰度图,使用fetch_openml下载数据集。

# 导入numpy库,用于数值计算,特别是对数组和矩阵的操作
import numpy as np
# 导入os库,用于与操作系统进行交互,比如文件目录操作
import os
# 在Jupyter Notebook中使用,使得matplotlib生成的图表直接嵌入显示
%matplotlib inline
# 导入matplotlib库,用于数据可视化;matplotlib是Python中最基础的绘图库
import matplotlib
# 从matplotlib导入pyplot模块,通常使用plt作为别名,提供类似MATLAB的绘图接口
import matplotlib.pyplot as plt
# 设置matplotlib中轴标签(x轴和y轴)的默认字体大小为14
plt.rcParams['axes.labelsize'] = 14
# 设置matplotlib中y轴刻度标签的默认字体大小为12
plt.rcParams['ytick.labelsize'] = 12
# 导入warnings库,用于控制Python程序中的警告信息
import warnings
# 忽略所有警告信息,这样在运行代码时可以避免显示不重要的警告
warnings.filterwarnings('ignore')
# 设置随机数种子为42,确保np.random下的随机函数生成的随机数序列是可复现的
np.random.seed(42)
from sklearn.datasets import fetch_openml
# 确认数据存储目录
data_dir = os.path.join(os.getcwd(), 'data')
# 下载 MNIST 数据集并保存到 data
# mnist = fetch_openml("mnist_784", parser='auto', data_home=data_dir)
# 使用fetch_openml尝试从本地加载MNIST数据集
# parser='auto' 参数根据数据自动选择合适的解析器,data_home指定了数据存放路径
mnist = fetch_openml("mnist_784", parser='auto', data_home=data_dir)
# 如果想要确认数据是否确实是从本地加载的,可以检查mnist对象的内容
print(mnist.DESCR) # 打印数据集描述
# 直接使用数据
X, y = mnist.data, mnist.target
print(f"数据形状: {X.shape}")
print(f"标签形状: {y.shape}")
X, y = mnist["data"], mnist["target"]
X.shape # (70000, 784)
y.shape # (70000,)
MNIST 数据集中的每个样本是一个 784 维的向量,表示 28×28 的灰度图像。
# 可视化第 0 个样本
plt.imshow(X[0].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()

整体的数据集长下面这个样子

3 划分数据集
# 将数据集 X 和对应的标签 y 划分为训练集和测试集
# X[:60000] 表示取数据集 X 的前 60000 个样本作为训练集的特征
# X[60000:] 表示取数据集 X 中从第 60001 个样本开始到最后一个样本作为测试集的特征
# y[:60000] 表示取标签 y 的前 60000 个样本作为训练集的标签
# y[60000:] 表示取标签 y 中从第 60001 个样本开始到最后一个样本作为测试集的标签
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
# 洗牌操作:打乱训练集的顺序,确保数据的随机性
import numpy as np
# 生成一个长度为 60000 的随机排列数组,表示打乱后的索引
# np.random.permutation(60000) 会生成 0 到 59999 的随机排列
shuffle_index = np.random.permutation(60000)
# 使用打乱后的索引重新排列训练集的特征和标签
# X_train.iloc[shuffle_index] 表示按照 shuffle_index 的顺序重新排列训练集的特征
# y_train.iloc[shuffle_index] 表示按照 shuffle_index 的顺序重新排列训练集的标签
X_train, y_train = X_train.iloc[shuffle_index], y_train.iloc[shuffle_index]
shuffle_index
| 样本数/类别 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| nums | 12628 | 37730 | 39991 | 8525 | 8279 | 51012 | 14871 | 15127 | 9366 | 33322 |
4 交叉验证
这里先简单介绍一下什么是交叉验证。
交叉验证是机器学习中用来评估模型性能的一种方法。简单来说,它通过反复划分数据来确保模型在不同数据上的表现稳定
交叉验证的核心是多次训练和测试。它将数据集分成多个部分,轮流用其中一部分作为测试集,其余部分作为训练集,最终综合多次的结果来评估模型。
最常用的方法是k折交叉验证,步骤如下:
- 分折:将数据分成k份(比如5份、10份)。
- 轮流测试:每次用1份作为测试集,剩下的k-1份作为训练集。
- 训练和评估:在训练集上训练模型,在测试集上评估性能。
- 综合结果:重复k次后,取平均性能作为模型的最终评估。
特点如下:
-
稳定性:通过多次评估,减少因数据划分不同带来的波动。
-
数据利用充分:所有数据都用于训练和测试,避免浪费。
-
计算成本高:需要多次训练,尤其是数据量大时。
-
时间消耗:比简单的训练-测试划分更耗时。
类似于你考试复习,假设书有10章内容。为了确保你每章都掌握:
- 第一次:复习第2-10章,用第1章测试自己。
- 第二次:复习第1章和第3-10章,用第2章测试自己。
- 一直重复:重复这个过程,直到每一章都当过测试内容。
- 最终评估:把每次测试的成绩平均一下,看看自己整体掌握得如何。
4.1 打标签以及分类器
# 将训练集标签中所有值为'1'的标记为True(即正类),其余为False(即负类)
# 这里将进行二分类问题,目标是识别数字'1'
y_train_1 = (y_train == '1')
# 对测试集标签做同样的处理
y_test_1 = (y_test == '1')
# 打印训练集标签转换结果的前50个元素,确认是否正确地进行了二值化
print(y_train_1[:50])
from sklearn.linear_model import SGDClassifier
# 创建一个SGDClassifier实例,设置最大迭代次数为5,随机状态为42以确保结果可复现
sgd_clf = SGDClassifier(max_iter=5, random_state=42)
# 使用训练数据X_train及其对应的二值化标签y_train_1来训练模型
# 目标是让模型学会区分数字'1'和其他数字
sgd_clf.fit(X_train, y_train_1)
# 使用训练好的 SGD 分类器 (sgd_clf) 对单个样本进行预测
# X.iloc[35000] 表示从数据集 X 中提取索引为 35000 的样本(特征数据)
# [X.iloc[35000]] 将单个样本包装成一个列表,因为 predict 方法通常接受批量数据输入
# sgd_clf.predict() 是模型预测方法,返回输入样本的预测结果
sgd_clf.predict([X.iloc[35000]])
y[35000]
# 上面是true,这里就看看实际标签是不是“1”,打印出来是1,所以没问题
4.2 工具包进行交叉验证
# 导入交叉验证评估工具 cross_val_score
from sklearn.model_selection import cross_val_score
# 使用交叉验证评估 SGD 分类器 (sgd_clf) 的性能
# cross_val_score 是用于计算模型在交叉验证中得分的函数
# 参数说明:
# - sgd_clf: 训练好的 SGD 分类器模型
# - X_train: 训练集的特征数据
# - y_train_1: 训练集的标签数据(假设是二分类问题,标签为 5 或非 5)
# - cv=3: 使用 3 折交叉验证(将数据分成 3 份,轮流用其中 1 份作为验证集,其余作为训练集)
# - scoring='accuracy': 使用准确率(accuracy)作为评估指标
cross_val_score(sgd_clf, X_train, y_train_1, cv=3, scoring='accuracy')
# 导入交叉验证评估工具 cross_val_score
from sklearn.model_selection import cross_val_score
# 使用交叉验证评估 SGD 分类器 (sgd_clf) 的性能
# cross_val_score 是用于计算模型在交叉验证中得分的函数
# 参数说明:
# - sgd_clf: 训练好的 SGD 分类器模型
# - X_train: 训练集的特征数据
# - y_train_1: 训练集的标签数据(假设是二分类问题,标签为 1 或非 1)
# - cv=3: 使用 10 折交叉验证(将数据分成 10 份,轮流用其中 1 份作为验证集,其余作为训练集)
# - scoring='accuracy': 使用准确率(accuracy)作为评估指标
cross_val_score(sgd_clf, X_train, y_train_1, cv=10, scoring='accuracy')
X_train.shape
y_train_1.shape
4.3 手动进行交叉验证
# 导入 StratifiedKFold 和 clone 工具
# StratifiedKFold 用于分层 K 折交叉验证,确保每一折的类别分布与整体一致
# clone 用于创建一个模型的副本,避免修改原始模型
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
# 初始化 StratifiedKFold 对象
# n_splits=3 表示将数据分成 3 折
# shuffle=True 表示在划分数据前先打乱数据顺序
# random_state=42 设置随机种子,确保结果可复现
skflods = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
# 使用 StratifiedKFold 对训练集进行分层 K 折交叉验证
# train_index 和 test_index 分别是每一折的训练集和测试集的索引
for train_index, test_index in skflods.split(X_train, y_train_1):
# 克隆 SGD 分类器模型,创建一个独立的副本
clone_clf = clone(sgd_clf)
# 根据当前折的训练集索引,提取训练集的特征和标签
X_train_folds = X_train.iloc[train_index]
y_train_folds = y_train_1[train_index]
# 根据当前折的测试集索引,提取测试集的特征和标签
X_test_folds = X_train.iloc[test_index]
y_test_folds = y_train_1[test_index]
# 使用当前折的训练集训练克隆的模型
clone_clf.fit(X_train_folds, y_train_folds)
# 使用训练好的模型对当前折的测试集进行预测
y_pred = clone_clf.predict(X_test_folds)
# 计算预测正确的样本数量
n_correct = sum(y_pred == y_test_folds)
# 计算并打印当前折的准确率(预测正确的比例)
print(n_correct / len(y_pred))
# 效果要比工具包的更差一些
5 混淆矩阵
在分类任务中,特别是二分类问题中,TP(True Positives)、FP(False Positives)、FN(False Negatives)和TN(True Negatives)是评估模型性能的关键指标,定义如下:
- TP (True Positives): 真阳性。指的是实际为正类且被模型正确预测为正类的样本数量。
- FP (False Positives): 假阳性。指的是实际为负类但被模型错误地预测为正类的样本数量。
- FN (False Negatives): 假阴性。指的是实际为正类但被模型错误地预测为负类的样本数量。
- TN (True Negatives): 真阴性。指的是实际为负类且被模型正确预测为负类的样本数量。
SKlearn中都已经有相关的工具了,所以这里只是进行一个demo的演示。

# 导入交叉验证预测函数cross_val_predict
from sklearn.model_selection import cross_val_predict
# 使用3折交叉验证生成训练集的预测结果
# 参数说明:
# - sgd_clf: 预定义的随机梯度下降分类器(SGDClassifier)
# - X_train: 训练集的特征数据
# - y_train_1: 目标标签,此处为二元分类问题(例如判断是否为数字1)
# - cv=3: 指定3折交叉验证,将数据分为3份,依次用其中2份训练,1份预测
# 返回值y_train_pred: 包含每个样本预测结果的数组,通过交叉验证避免模型过拟合训练数据
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_1, cv=3)
# 查看y_train_pred的形状
# y_train_pred是通过交叉验证生成的预测结果数组
# 它的形状表示预测结果的数量,通常与训练集的样本数量一致
# 返回值是一个元组,表示数组的维度
y_train_pred.shape
# 获取训练数据集X_train的形状(维度信息)
# shape属性返回一个包含数组各维度大小的元组
# 例如对于二维数组,shape[0]是行数,shape[1]是列数
print(X_train.shape) # 打印X_train的形状
# 导入confusion_matrix函数
from sklearn.metrics import confusion_matrix
# 使用confusion_matrix函数计算并生成训练集上的混淆矩阵
# 参数y_train_1是训练数据集的真实标签
# 参数y_train_pred是对应训练数据集上模型的预测标签
# 返回结果是一个二维数组,其中:
# 第i行第j列的元素表示实际属于第i类但被预测为第j类的样本数量
cm = confusion_matrix(y_train_1, y_train_pred)
# 打印混淆矩阵
print(cm)
[[52985 273]
[ 300 6442]]
可能不太直观,可以画个图看看。
# 使用 Seaborn 的 heatmap 函数绘制混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Reds',
xticklabels=['Not 1', '1'], yticklabels=['Not 1', '1'])
plt.title('matrix', fontsize=16)
plt.xlabel('pre', fontsize=14)
plt.ylabel('true', fontsize=14)
plt.show()

negative class [[ true negatives , false positives ],
positive class [ false negatives , true positives ]]
-
true negatives: 53,985个数据被正确的分为非1类别
-
false positives:273张被错误的分为1类别
-
false negatives:300张错误的分为非1类别
-
true positives: 6442张被正确的分为1类别
6 Precision, Recall and F1
在机器学习和数据分析中,精确率(Precision)和召回率(Recall)是评估分类模型性能的两个关键指标,尤其在处理不平衡数据集时显得尤为重要。
精确率衡量的是模型预测为正类的样本中,实际为正类的比例。它反映了模型预测正类的准确性。公式为:
P r e c i s i o n = T P T P + F P Precision = \frac {TP} {TP + FP} Precision=TP+FPTP
- TP(True Positives):真正例,即模型正确预测为正类的样本数量。
- FP(False Positives):假正例,即模型错误预测为正类的样本数量。
召回率衡量的是所有实际为正类的样本中,模型正确预测为正类的比例。它反映了模型对正类的覆盖能力。公式为:
R e c a l l = T P T P + F N Recall = \frac {TP} {TP + FN} Recall=TP+FNTP
- TP(True Positives):真正例,即模型正确预测为正类的样本数量。
- FN(False Negatives):假负例,即模型错误预测为负类的样本数量。
精确率和召回率之间通常存在权衡关系。提高精确率可能会降低召回率,反之亦然。
高精确率:模型更倾向于保守地预测正类,减少误报(FP),但可能会漏掉一些真正的正类(FN)。
高召回率:模型更倾向于积极地预测正类,减少漏报(FN),但可能会增加误报(FP)。
在实际应用中,需要根据具体问题的需求来平衡精确率和召回率。例如:
- 垃圾邮件检测:更注重高召回率,因为漏掉一封垃圾邮件可能比误判一封正常邮件为垃圾邮件更好一些。
- 疾病诊断:更注重高召回率,因为漏掉一个患病的患者可能比误诊一个健康的人为患病更危险。
from sklearn.metrics import precision_score,recall_score
precision_score(y_train_1,y_train_pred)
# 召回率
recall_score(y_train_1,y_train_pred)
将Precision 和 Recall结合到一个称为F1 score 的指标,调和平均值给予低值更多权重。 因此,如果召回和精确度都很高,分类器将获得高 F 1 F_1 F1分数。分值低的权重更大。
F 1 = 2 1 precision + 1 recall = 2 × precision × recall precision + recall = T P T P + F N + F P 2 F_1 = \frac{2}{\frac{1}{\text{precision}} + \frac{1}{\text{recall}}} = 2 \times \frac{\text{precision} \times \text{recall}}{\text{precision} + \text{recall}} = \frac{TP}{TP + \frac{FN + FP}{2}} F1=precision1+recall12=2×precision+recallprecision×recall=TP+2FN+FPTP
from sklearn.metrics import f1_score
f1_score(y_train_1,y_train_pred)
7 阈值
7.1 阈值介绍
在机器学习中,特别是在分类问题中,阈值(Threshold)是一个用于将连续的决策分数或概率转换为离散的类别标签的临界点。阈值是模型输出和最终预测之间的转换标准。
通常,提高阈值会提高precision但降低recall。
阈值的作用:
在二分类问题中,模型通常会输出一个表示属于正类的概率或一个决策分数。
阈值用于决定何时将这些分数解释为正类(通常阈值设为0.5,但可以根据需要调整)。
在多分类问题中,阈值的概念可能不那么直接,因为每个类别可能有自己的分数或概率。
但是,阈值仍然可以用来决定在概率分布中选择哪个类别作为最终预测。
阈值的选择:
-
默认阈值:在许多情况下,默认阈值可能为0.5,这意味着如果模型预测的概率大于或等于0.5,则预测为正类;否则,预测为负类。
-
调整阈值:根据具体应用的需求,阈值可以调整。例如,如果希望减少假正例(False Positives),可能会选择一个更高的阈值;如果希望减少假负例(False Negatives),可能会选择一个更低的阈值。
阈值的影响:
-
精确率和召回率:改变阈值会影响精确率和召回率。通常,提高阈值会提高precision但降低recall。
-
模型性能:不同的阈值可能导致模型性能的显著变化,因此在实际应用中,选择合适的阈值是非常重要的。
简单来说,阈值就是一个帮助我们做出决策的“分界线”。不同的阈值可能会影响我们的决策结果,有时候我们需要根据实际情况来调整这个“分界线”,以便做出更好的决策。
7.2 skl中的阈值
Scikit-Learn不允许直接设置阈值,但它可以得到决策分数,调用其decision_function()方法,而不是调用分类器的predict()方法,该方法返回每个实例的分数,然后使用想要的阈值根据这些分数进行预测:
# 使用训练好的 SGD 分类器 (sgd_clf) 对单个样本进行决策函数值计算
# decision_function 方法返回每个样本属于正类(这里是数字 '1')的置信度分数
y_scores = sgd_clf.decision_function([X.iloc[35000]])
print("Decision function score for sample 35000:", y_scores)
# 设定一个阈值 t 来手动决定分类结果
# 如果决策函数值大于这个阈值,则认为该样本属于正类
t = 50000
y_pred = (y_scores > t)
print("Prediction with threshold of 50000:", y_pred)
# 使用 cross_val_predict 函数进行交叉验证预测,并获取决策函数值
# cv=3 表示使用 3 折交叉验证;method="decision_function" 指定返回决策函数值而不是默认的概率估计
y_scores = cross_val_predict(sgd_clf, X_train, y_train_1, cv=3,
method="decision_function")
# 打印前10个样本的决策函数值
print("First 10 decision function scores from cross-validation:\n", y_scores[:10])
# 计算精确率、召回率和对应的阈值
# precision_recall_curve 函数基于真实的标签 (y_train_1) 和预测的得分 (y_scores) 来计算这些指标
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_1, y_scores)
# 查看训练集标签的真实形状
y_train_1.shape
# 查看阈值数组的形状
thresholds.shape # (60000,0)
precisions[:10]
# 查看精确率数组的形状
precisions.shape # (60001,0)
# 查看召回率数组的形状
recalls.shape # (60001,0)
# 这两块是官方需要召回率从0开始多设置了一个,所以比阈值多1个。
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
"""
绘制精确率和召回率相对于阈值的变化图。
参数:
precisions (list): 精确率列表。
recalls (list): 召回率列表。
thresholds (list): 阈值列表。
"""
plt.figure(figsize=(10, 6))
plt.plot(thresholds, precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g-", label="Recall")
plt.xlabel("Threshold", fontsize=14)
plt.ylabel("Precision/Recall", fontsize=14)
plt.title("Precision and Recall vs. Threshold", fontsize=16)
plt.legend(loc="upper left", fontsize=12)
plt.grid(True)
plt.ylim([0, 1])
plt.xlim([min(thresholds), max(thresholds)])
plt.figure(figsize=(8, 4))
plot_precision_recall_vs_threshold(precisions,recalls,thresholds)
plt.xlim([-700000, 700000])
plt.show()

def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls,
precisions,
"b-",
linewidth=2)
plt.xlabel("Recall", fontsize=16)
plt.ylabel("Precision", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.figure(figsize=(8, 6))
plot_precision_vs_recall(precisions, recalls)
plt.show()

8 ROC曲线(简单介绍)
ROC曲线,全称为接收者操作特征曲线(Receiver Operating Characteristic Curve),是一种在二分类问题中评估分类模型性能的工具。它通过展示在不同阈值下模型的真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR)之间的关系,来帮助我们理解模型的判别能力。
在二分类问题中,真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR)是评估分类模型性能的两个关键指标,其计算公式如下:
-
真正例率TPR,也称为Recall:
TPR = TP TP + FN \text{TPR} = \frac{\text{TP}}{\text{TP} + \text{FN}} TPR=TP+FNTP -
假正例率FPR:
FPR = FP FP + TN \text{FPR} = \frac{\text{FP}}{\text{FP} + \text{TN}} FPR=FP+TNFP
ROC曲线下的面积(Area Under the Curve, AUC)是一个常用的评估指标,其值范围从0到1,值越大表示模型性能越好:
- AUC = 0.5:表示模型的性能等同于随机猜测,相当于你一个人去猜正反面,也是50%。
- AUC = 1:表示模型具有完美的区分能力。
- 0 < AUC < 1:表示模型具有一定的区分能力,值越接近1,性能越好。
直接说结论,下图的ROC曲线越往左上角,表示模型性能越好。
因为y轴是TPR,x轴是FPR,你肯定是需要TPR越高越好,同时要保证FPR尽可能的小。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_1, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.figure(figsize=(8, 6))
plot_roc_curve(fpr, tpr)
plt.show()

计算一下面积
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_1, y_scores)
0.9972526261202149
说明分类效果是非常好的。
你也可以这样画图,把auc面积加入。
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
def plot_roc_curve(fpr, tpr, roc_auc, label=None):
"""
绘制ROC曲线并显示AUC面积。
参数:
fpr (list): 假正例率列表。
tpr (list): 真正例率列表。
roc_auc (float): ROC曲线下的面积(AUC值)。
label (str): 图例标签。
"""
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.grid(True)
# 计算ROC曲线上的点
fpr, tpr, thresholds = roc_curve(y_train_1, y_scores)
# 计算AUC值
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线并显示AUC面积
plot_roc_curve(fpr, tpr, roc_auc)
plt.show()





![[LVGL] 在VC_MFC中移植LVGL](https://i-blog.csdnimg.cn/direct/53c7f1b2a72442f694d54ebab1e3bf1d.png)