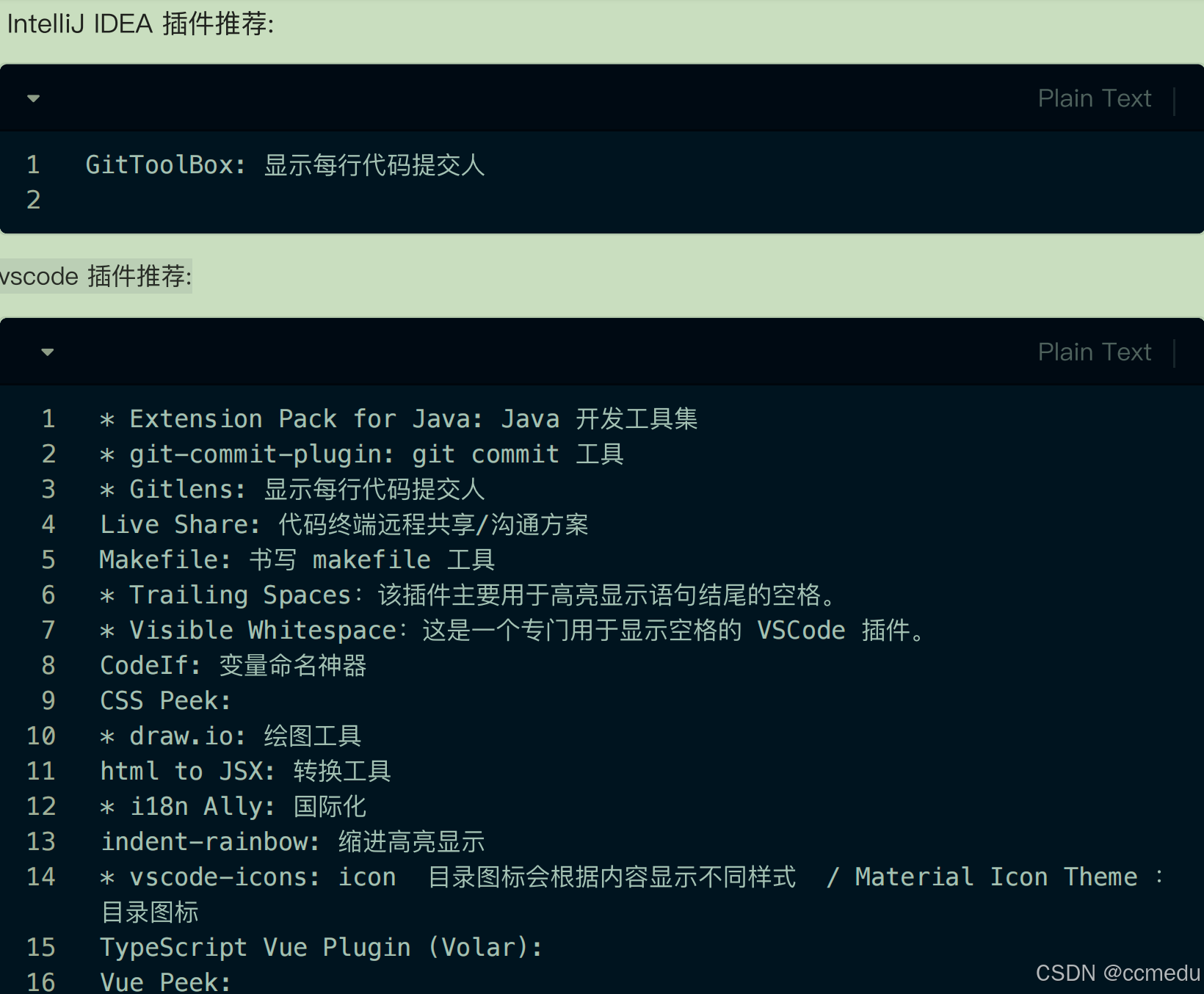
目录
ELMO
一、ELMo的核心设计理念
1. 静态词向量的局限性
2. 动态上下文嵌入的核心思想
3. 层次化特征提取
1. 双向语言模型(BiLM)
2. 多层LSTM的层次化表示
三、ELMo的运行过程
1. 预训练阶段
2. 下游任务微调
四、ELMo的突破与局限性
1. 技术突破
2. 局限性
五、ELMo的历史影响
六、典型应用场景
Bert
1. 对上下文建模的彻底革新
2. 预训练-微调范式(Pre-training + Fine-tuning)
3. 任务驱动的预训练目标
二、BERT的模型架构与技术逻辑
1. 基于Transformer的编码器堆叠
2. 输入表示设计
3. 预训练任务详解
三、BERT的运行过程
1. 预训练阶段
2. 微调阶段
四、BERT的技术突破与局限性
1. 革命性贡献
2. 局限性
五、BERT的历史地位与后续发展
1. NLP范式转变
2. 关键衍生模型
六、BERT的典型应用场景
七、与ELMo的关键对比
ELMO
一、ELMo的核心设计理念
1. 静态词向量的局限性
- 问题根源:传统词向量(如Word2Vec、GloVe)为每个词赋予固定表示,无法处理一词多义(Polysemy)。
- 例证:单词"bank"在"river bank"和"bank account"中含义不同,但静态词向量无法区分。
2. 动态上下文嵌入的核心思想
- 核心理念:词义应由其所在上下文动态生成,而非静态编码。
- 技术路径:通过双向语言模型(BiLM)捕捉上下文信息,生成层次化的词表示。
3. 层次化特征提取
- 语言学假设:不同神经网络层可捕捉不同粒度的语言特征(如词性、句法、语义)。
- 创新点:将LSTM不同层的输出线性组合,构建最终的词表示。
二、ELMo的模型结构与技术逻辑

1. 双向语言模型(BiLM)
- 前向LSTM:建模从左到右的序列概率
![]()
- 后向LSTM:建模从右到左的序列概率
![]()
- 联合优化目标:最大化双向对数似然:

2. 多层LSTM的层次化表示
- 底层特征:LSTM底层输出捕捉局部语法特征(如词性、形态)。
- 高层特征:LSTM顶层输出捕捉全局语义特征(如句间关系、指代消解)。
- 特征融合:通过可学习的权重 组合各层表示:

三、ELMo的运行过程
1. 预训练阶段
- 输入:大规模语料(如1B Word Benchmark)
- 任务目标:通过双向语言模型预测下一个词(前向)和上一个词(后向)
- 参数保存:保留LSTM各层的权重及字符卷积网络的参数。
2. 下游任务微调
- 特征注入方式:
- 静态模式:固定ELMo权重,将词向量拼接至任务模型的输入层。
- 动态模式:允许ELMo参数在任务训练中微调(需权衡计算成本)。
- 多任务适配:适用于分类、问答、NER等多种任务,通过调整权重 优化特征组合。
四、ELMo的突破与局限性
1. 技术突破
- 动态词向量:首次实现基于上下文的动态词表示。
- 双向建模:通过独立训练的双向LSTM间接捕捉全局上下文。
- 层次化特征:验证了不同网络层的语言学意义。
2. 局限性
- 浅层双向性:前向/后向LSTM独立训练,未实现真正的交互式双向建模。
- LSTM效率瓶颈:长序列建模能力受限,训练速度慢于Transformer。
- 上下文长度限制:受LSTM记忆容量影响,长距离依赖捕捉不足。
五、ELMo的历史影响
1. 预训练范式的先驱:证明了语言模型预训练+任务微调的可行性。
2. BERT与GPT的基石:启发了基于Transformer的双向预训练模型(BERT)和自回归模型(GPT)。
3. 特征可解释性研究:推动了对神经网络层次化语言特征的探索(如探针任务分析)。
六、典型应用场景
1. 命名实体识别(NER):动态词向量显著提升实体边界识别精度。
2. 文本分类:通过组合不同层次特征捕捉局部与全局语义。
3. 语义相似度计算:上下文敏感的词表示改善句子匹配效果。


tips:ELMO过程属于无监督学习,RNN base模型预测下一个词的位置,而不是下一个词是否为正确的词


ELMO和transformer没有关系,和BiLSTM有关系,每次input的词汇作词嵌入(转换为词向量)
Bert
一、BERT的核心设计理念

1. 对上下文建模的彻底革新
- 问题驱动:传统模型(如ELMo、GPT)的单向或浅层双向性限制了对上下文的全局理解。
- 核心思想:通过深度双向Transformer实现全上下文交互建模,消除方向性偏差。
2. 预训练-微调范式(Pre-training + Fine-tuning)
- 统一架构:同一模型结构适配多种下游任务,无需任务特定结构调整。
- 参数复用:预训练阶段学习通用语言知识,微调阶段注入领域/任务知识。
3. 任务驱动的预训练目标
- Masked Language Model (MLM):随机遮蔽15%的输入词,迫使模型基于全上下文预测被遮蔽词。
- Next Sentence Prediction (NSP):学习句子间关系,增强对篇章级语义的理解。
二、BERT的模型架构与技术逻辑
1. 基于Transformer的编码器堆叠
- 基础配置:
- BERT-base: 12层Transformer, 768隐藏维度, 12注意力头(110M参数)
- BERT-large: 24层Transformer, 1024隐藏维度, 16注意力头(340M参数)
- 双向注意力机制:每个词可同时关注序列中所有其他词(包括前后位置)。
2. 输入表示设计
- Token Embeddings:WordPiece分词(30k词表),处理未登录词(如"playing"→"play"+"##ing")。
- Segment Embeddings:区分句子A/B(用于NSP任务)。
- Position Embeddings:学习绝对位置编码(最大512长度)。
- 特殊标记:`[CLS]`(分类标记)、`[SEP]`(句子分隔符)、`[MASK]`(遮蔽符)。
3. 预训练任务详解

三、BERT的运行过程
1. 预训练阶段
- 数据源:BooksCorpus(8亿词) + 英文维基百科(25亿词)。
- 训练策略:
- 动态遮蔽:每个epoch重新随机遮蔽词,提升鲁棒性。
- 80-10-10规则:被遮蔽词中80%替换为`[MASK]`,10%替换为随机词,10%保留原词。
- 优化参数:Adam(β₁=0.9, β₂=0.999),学习率1e-4,batch size=256/512。
2. 微调阶段
- 任务适配方式:
- 句子对任务(如STS):使用`[CLS]`标记的嵌入进行相似度计算。
- 序列标注任务(如NER):使用每个token的最后一层输出。
- 问答任务(如SQuAD):输出段落中答案的起始/结束位置概率。
- 轻量级调整:通常仅需在预训练模型顶层添加1-2个全连接层。
四、BERT的技术突破与局限性
1. 革命性贡献
- 深度双向性:突破LSTM/单向Transformer的上下文建模限制。
- 通用表征能力:在11项NLP任务中刷新SOTA(GLUE基准提升7.7%绝对准确率)。
- 长距离依赖建模:自注意力机制有效捕捉跨句子依赖关系。
2. 局限性
- 预训练-微调数据分布差异:MLM的`[MASK]`标记在微调时不存在,导致训练-应用偏差。
- 计算资源消耗:BERT-large预训练需16个TPU训练4天(成本约7,000美元)。
- 生成能力缺失:仅支持编码任务,无法直接生成文本(后由UniLM、BART等改进)。
五、BERT的历史地位与后续发展
1. NLP范式转变
- 预训练成为标配:推动"预训练大模型+下游任务轻量化"成为NLP主流范式。
- 多模态扩展:催生跨领域模型如VideoBERT(视频)、BioBERT(生物医学)。
2. 关键衍生模型
- RoBERTa:移除NSP任务,扩大batch size和训练数据,性能进一步提升。
- ALBERT:通过参数共享(跨层参数)和嵌入分解降低内存消耗。
- DistilBERT:知识蒸馏技术压缩模型体积(保留95%性能,体积减少40%)。
六、BERT的典型应用场景
1. 语义搜索:计算query-document语义相关性(Google Search 2019年应用)。
2. 智能问答:基于段落理解的答案抽取(如Google Assistant)。
3. 文本分类:情感分析、垃圾邮件检测等。
4.实体链接:将文本中的实体链接到知识库(如Wikipedia)。
bert的应用

词性标注、情感分类等
七、与ELMo的关键对比


训练bert的方法

linear multi-class classifier -- softmax
MASK -- 掩饰 遮挡一部分词汇














![P1030 [NOIP2001 普及组] 求先序排列(c++)详解](https://i-blog.csdnimg.cn/direct/6b024bdfbea743efa91e54207aaad90a.png)