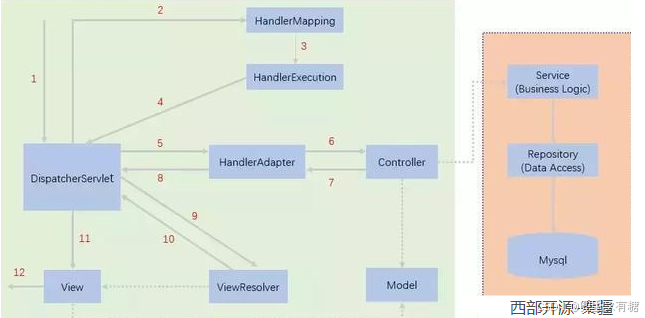
公式样例
渲染前
\[
\sqrt{1904.615384} \approx 43.64
\]渲染后

安装依赖
pip install matplotlib -i https://mirrors.aliyun.com/pypi/simple/ requests
pip install sympy -i https://mirrors.aliyun.com/pypi/simple/ requests
pip install python-docx -i https://mirrors.aliyun.com/pypi/simple/ requests代码
# -*- coding: utf-8 -*-
# ====> 数学公式导出处理 <==== #
import os
import traceback
import matplotlib
from docx import Document
from common.conf import doc_handle_path
from common.util import generate_time_random_code
start_marker = "\["
end_marker = "\]"
output_tmp_folder = f'{doc_handle_path}math_2_img{os.sep}'
if not os.path.exists(output_tmp_folder):
os.mkdir(output_tmp_folder)
def is_have_math(text):
s_count = text.count('\[')
e_count = text.count('\]')
if s_count >= e_count or e_count >= s_count:
return True
return False
def find_and_replace(text, start_marker="\[", end_marker="\]"):
"""
查找并替换由_start和_end包围的文本。
:param text: 需要处理的原始文本
:param start_marker: 标记开始的字符串,默认为"_start"
:param end_marker: 标记结束的字符串,默认为"_end"
:return: 替换后的文本
"""
result_parts = [] # 存储结果片段
current_position = 0 # 当前处理到的位置
while True:
start_pos = text.find(start_marker, current_position)
if start_pos == -1:
# 没有找到更多的_start标记,将剩余部分添加到结果中并退出循环
result_parts.append(text[current_position:])
break
# 添加_start之前的部分到结果中
result_parts.append(text[current_position:start_pos])
# 查找对应的_end标记
end_pos = text.find(end_marker, start_pos + len(start_marker))
if end_pos == -1:
# 如果没有找到_end标记,则将剩余部分全部添加到结果中并退出
result_parts.append(text[start_pos:])
break
# 提取并处理_start和_end之间的文本
content = text[start_pos + len(start_marker):end_pos]
processed_content = '111' # 定义你自己的处理逻辑
print(content)
# 将处理后的内容添加到结果中
result_parts.append(processed_content)
# 更新当前处理位置为_end之后
current_position = end_pos + len(end_marker)
# 返回拼接后的最终结果
return ''.join(result_parts)
def replace_first_closing_brace(text, split_marker=r'\(\boxed{', start_tag='[', end_tag=']'):
"""
根据split_marker切割文本,并将每个元素的第一个"}"替换为replacement字符。
:param text: 需要处理的原始文本
:param split_marker: 用于切割文本的标记,默认为'\(\boxed{'
:param replacement: 用来替换第一个'}'的字符,默认为'_'
:return: 处理后的文本
"""
# 如果没有split_marker,则直接返回原text
if split_marker not in text:
return text
# 根据split_marker切割文本
parts = text.split(split_marker)
# 第一个元素是split_marker之前的内容,不需要处理
processed_parts = [parts[0]]
for part in parts[1:]:
# 找到第一个"}"的位置并替换为replacement
closing_brace_index = part.find('}')
if closing_brace_index != -1:
new_part = part[:closing_brace_index] + end_tag + part[closing_brace_index + 3:]
else:
new_part = part # 如果没有找到"}",则保持原样
processed_parts.append(new_part)
# 将处理后的部分重新组合成新的字符串
result = split_marker.join(processed_parts)
if split_marker in result:
result = result.replace(split_marker, start_tag)
return result
def math_generate_docx(text, path):
# 创建新的Document对象
document = Document()
# 添加标题
# document.add_heading('Document Title', 0)
current_position = 0 # 当前处理到的位置
imgs = []
while True:
start_pos = text.find(start_marker, current_position)
if start_pos == -1:
# 没有找到更多的_start标记,将剩余部分添加到结果中并退出循环
other_text = replace_first_closing_brace(text[current_position:])
document.add_paragraph(other_text)
break
# 添加_start之前的部分到结果中
document.add_paragraph(text[current_position:start_pos])
# 查找对应的_end标记
end_pos = text.find(end_marker, start_pos + len(start_marker))
if end_pos == -1:
# 如果没有找到_end标记,则将剩余部分全部添加到结果中并退出
document.add_paragraph(text[start_pos:])
break
# 提取并处理_start和_end之间的文本
content = text[start_pos + len(start_marker):end_pos]
math_img_path = math_2_img(content)
if math_img_path:
imgs.append(math_img_path)
document.add_picture(math_img_path)
else:
document.add_paragraph(content)
# 更新当前处理位置为_end之后
current_position = end_pos + len(end_marker)
# 保存文档到本地
document.save(path)
for img in imgs:
if os.path.exists(img):
os.remove(img)
def math_2_img(text):
text = text.replace('\n', '')
formula = r"$" + text + "$"
matplotlib.use('Agg')
import matplotlib.pyplot as plt
try:
# 创建一个只包含公式的图像
plt.figure(figsize=(6, 1)) # 调整大小以适应公式
plt.text(0.5, 0.5, formula, fontsize=20, ha='center', va='center')
plt.axis('off') # 关闭坐标轴
# 保存图像到本地
output_tmp_path = f'{output_tmp_folder}{generate_time_random_code(5)}.png'
plt.savefig(output_tmp_path, bbox_inches='tight', pad_inches=0.1, dpi=300)
except:
traceback.print_exc()
return None
plt.close()
return output_tmp_path
if __name__ == '__main__':
s = r"""
为了解决这个问题,我们将按照以下步骤进行:
1. 计算58和64的乘积。
2. 将结果除以3.12。
3. 将结果乘以1.6。
4. 对结果取平方根。
让我们从第一步开始:
1. 计算58和64的乘积:
\[
58 \times 64 = 3712
\]
2. 将3712除以3.12:
\[
\frac{3712}{3.12} \approx 1190.384615
\]
3. 将1190.384615乘以1.6:
\[
1190.384615 \times 1.6 \approx 1904.615384
\]
4. 对1904.615384取平方根:
\[
\sqrt{1904.615384} \approx 43.64
\]
因此,最后的得数是 \(\boxed{43.64}\)。
"""
math_generate_docx(s, 'example.docx')











![[JavaScript] 运算符详解](https://i-blog.csdnimg.cn/img_convert/c77549fcdd71ddee706904782faa6a93.gif)