{
"cells": [
{
"cell_type": "markdown",
"metadata": {
},
"source": [
"# 基于用户的协同过滤算法"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
},
"outputs": [],
"source": [
"# 导入包\n",
"import random\n",
"import math\n",
"import time\n",
"from tqdm import tqdm"
]
},
{
"cell_type": "markdown",
"metadata": {
},
"source": [
"## 一. 通用函数定义"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
},
"outputs": [],
"source": [
"# 定义装饰器,监控运行时间\n",
"def timmer(func):\n",
" def wrapper(*args, **kwargs):\n",
" start_time = time.time()\n",
" res = func(*args, **kwargs)\n",
" stop_time = time.time()\n",
" print('Func %s, run time: %s' % (func.__name__, stop_time - start_time))\n",
" return res\n",
" return wrapper"
]
},
{
"cell_type": "markdown",
"metadata": {
},
"source": [
"### 1. 数据处理相关\n",
"1. load data\n",
"2. split data"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
},
"outputs": [],
"source": [
"class Dataset():\n",
" \n",
" def __init__(self, fp):\n",
" # fp: data file path\n",
" self.data = self.loadData(fp)\n",
" \n",
" @timmer\n",
" def loadData(self, fp):\n",
" data = []\n",
" for l in open(fp):\n",
" data.append(tuple(map(int, l.strip().split('::')[:2])))\n",
" return data\n",
" \n",
" @timmer\n",
" def splitData(self, M, k, seed=1):\n",
" '''\n",
" :params: data, 加载的所有(user, item)数据条目\n",
" :params: M, 划分的数目,最后需要取M折的平均\n",
" :params: k, 本次是第几次划分,k~[0, M)\n",
" :params: seed, random的种子数,对于不同的k应设置成一样的\n",
" :return: train, test\n",
" '''\n",
" train, test = [], []\n",
" random.seed(seed)\n",
" for user, item in self.data:\n",
" # 这里与书中的不一致,本人认为取M-1较为合理,因randint是左右都覆盖的\n",
" if random.randint(0, M-1) == k: \n",
" test.append((user, item))\n",
" else:\n",
" train.append((user, item))\n",
"\n",
" # 处理成字典的形式,user->set(items)\n",
" def convert_dict(data):\n",
" data_dict = {}\n",
" for user, item in data:\n",
" if user not in data_dict:\n",
" data_dict[user] = set()\n",
" data_dict[user].add(item)\n",
" data_dict = {k: list(data_dict[k]) for k in data_dict}\n",
" return data_dict\n",
"\n",
" return convert_dict(train), convert_dict(test)"
]
},
{
"cell_type": "markdown",
"metadata": {
},
"source": [
"### 2. 评价指标\n",
"1. Precision\n",
"2. Recall\n",
"3. Coverage\n",
"4. Popularity(Novelty)"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
},
"outputs": [],
"source": [
"class Metric():\n",
" \n",
" def __init__(self, train, test, GetRecommendation):\n",
" '''\n",
" :params: train, 训练数据\n",
" :params: test, 测试数据\n",
" :params: GetRecommendation, 为某个用户获取推荐物品的接口函数\n",
" '''\n",
" self.train = train\n",
" self.test = test\n",
" self.GetRecommendation = GetRecommendation\n",
" self.recs = self.getRec()\n",
" \n",
" # 为test中的每个用户进行推荐\n",
" def getRec(self):\n",
" recs = {}\n",
" for user in self.test:\n",
" rank = self.GetRecommendation(user)\n",
" recs[user] = rank\n",
" return recs\n",
" \n",
" # 定义精确率指标计算方式\n",
" def precision(self):\n",
" all, hit = 0, 0\n",
" for user in self.test:\n",
" test_items = set(self.test[user])\n",
" rank = self.recs[user]\n",
" for item, score in rank:\n",
" if item in test_items:\n",
" hit += 1\n",
" all += len(rank)\n",
" return round(hit / all * 100, 2)\n",
" \n",
" # 定义召回率指标计算方式\n",
" def recall(self):\n",
" all, hit = 0, 0\n",
" for user in self.test:\n",
" test_items = set(self.test[user])\n",
" rank = self.recs[user]\n",
" for item, score in rank:\n",
" if item in test_items:\n",
" hit += 1\n",
" all += len(test_items)\n",
" return round(hit / all * 100, 2)\n",
" \n",
" # 定义覆盖率指标计算方式\n",
" def coverage(self):\n",
" all_item, recom_item = set(), set()\n",
" for user in self.test:\n",
" for item in self.train[user]:\n",
" all_item.add(item)\n",
" rank = self.recs[user]\n",
" for item, score in rank:\n",
" recom_item.add(item)\n",
" return round(len(recom_item) / len(all_item) * 100, 2)\n",
" \n",
" # 定义新颖度指标计算方式\n",
" def popularity(self):\n",
" # 计算物品的流行度\n",
" item_pop = {}\n",
" for user in self.train:\n",
" for item in self.train[user]:\n",
" if item not in item_pop:\n",
" item_pop[item] = 0\n",
" item_pop[item] += 1\n",
"\n",
" num, pop = 0, 0\n",
" for user in self.test:\n",
" rank = self.recs[user]\n",
" for item, score in rank:\n",
" # 取对数,防止因长尾问题带来的被流行物品所主导\n",
" pop += math.log(1 + item_pop[item])\n",
" num += 1\n",
" return round(pop / num, 6)\n",
" \n",
" def eval(self):\n",
" metric = {'Precision': self.precision(),\n",
" 'Recall': self.recall(),\n",
" 'Coverage': self.coverage(),\n",
" 'Popularity': self.popularity()}\n",
" print('Metric:', metric)\n",
" return metric"
]
},
{
"cell_type": "markdown",
"metadata": {
},
"source": [
"## 二. 算法实现\n",
"1. Random\n",
"2. MostPopular\n",
"3. UserCF\n",
"4. UserIIF"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
},
"outputs": [],
"source": [
"# 1. 随机推荐\n",
"def Random(train, K, N):\n",
" '''\n",
" :params: train, 训练数据集\n",
" :params: K, 可忽略\n",
" :params: N, 超参数,设置取TopN推荐物品数目\n",
" :return: GetRecommendation,推荐接口函数\n",
" '''\n",
" items = {}\n",
" for user in train:\n",
" for item in train[user]:\n",
" items[item] = 1\n",
" \n",
" def GetRecommendation(user):\n",
" # 随机推荐N个未见过的\n",
" user_items = set(train[user])\n",
" rec_items = {k: items[k] for k in items if k not in user_items}\n",
" rec_items = list(rec_items.items())\n",
" random.shuffle(rec_items)\n",
" return rec_items[:N]\n",
" \n",
" return GetRecommendation"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
},
"outputs": [],
"source": [
"# 2. 热门推荐\n",
"def MostPopular(train, K, N):\n",
" '''\n",
" :params: train, 训练数据集\n",
" :params: K, 可忽略\n",
" :params: N, 超参数,设置取TopN推荐物品数目\n",
" :return: GetRecommendation, 推荐接口函数\n",
" '''\n",
" items = {}\n",
" for user in train:\n",
" for item in train[user]:\n",
" if item not in items:\n",
" items[item] = 0\n",
" items[item] += 1\n",
" \n",
" def GetRecommendation(user):\n",
" # 随机推荐N个没见过的最热门的\n",
" user_items = set(train[user])\n",
" rec_items = {k: items[k] for k in items if k not in user_items}\n",
" rec_items = list(sorted(rec_items.items(), key=lambda x: x[1], reverse=True))\n",
" return rec_items[:N]\n",
" \n",
" return GetRecommendation"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
},
"outputs": [],
"source": [
"# 3. 基于用户余弦相似度的推荐\n",
"def UserCF(train, K, N):\n",
" '''\n",
" :params: train, 训练数据集\n",
" :params: K, 超参数,设置取TopK相似用户数目\n",
" :params: N, 超参数,设置取TopN推荐物品数目\n",
" :return: GetRecommendation, 推荐接口函数\n",
" '''\n",
" # 计算item->user的倒排索引\n",
" item_users = {}\n",
" for user in train:\n",
" for item in train[user]:\n",
" if item not in item_users:\n",
" item_users[item] = []\n",
" item_users[item].append(user)\n",
" \n",
" # 计算用户相似度矩阵\n",
" sim = {}\n",
" num = {}\n",
" for item in item_users:\n",
" users = item_users[item]\n",
" for i in range(len(users)):\n",
" u = users[i]\n",
" if u not in num:\n",
" num[u] = 0\n",
" num[u] += 1\n",
" if u not in sim:\n",
" sim[u] = {}\n",
" for j in range(len(users)):\n",
" if j == i: continue\n",
" v = users[j]\n",
" if v not in sim[u]:\n",
" sim[u][v] = 0\n",
" sim[u][v] += 1\n",
" for u in sim:\n",
" for v in sim[u]:\n",
" sim[u][v] /= math.sqrt(num[u] * num[v])\n",
" \n",
" # 按照相似度排序\n",
" sorted_user_sim = {k: list(sorted(v.items(), \\\n",
" key=lambda x: x[1], reverse=True)) \\\n",
" for k, v in sim.items()}\n",
" \n",
" # 获取接口函数\n",
" def GetRecommendation(user):\n",
" items = {}\n",
" seen_items = set(train[user])\n",
" for u, _ in sorted_user_sim[user][:K]:\n",
" for item in train[u]:\n",
" # 要去掉用户见过的\n",
" if item not in seen_items:\n",
" if item not in items:\n",
" items[item] = 0\n",
" items[item] += sim[user][u]\n",
" recs = list(sorted(items.items(), key=lambda x: x[1], reverse=True))[:N]\n",
" return recs\n",
" \n",
" return GetRecommendation"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
},
"outputs": [],
"source": [
"# 4. 基于改进的用户余弦相似度的推荐\n",
"def UserIIF(train, K, N):\n",
" '''\n",
" :params: train, 训练数据集\n",
" :params: K, 超参数,设置取TopK相似用户数目\n",
" :params: N, 超参数,设置取TopN推荐物品数目\n",
" :return: GetRecommendation, 推荐接口函数\n",
" '''\n",
" # 计算item->user的倒排索引\n",
" item_users = {}\n",
" for user in train:\n",
" for item in train[user]:\n",
" if item not in item_users:\n",
" item_users[item] = []\n",
" item_users[item].append(user)\n",
" \n",
" # 计算用户相似度矩阵\n",
" sim = {}\n",
" num = {}\n",
" for item in item_users:\n",
" users = item_users[item]\n",
" for i in range(len(users)):\n",
" u = users[i]\n",
" if u not in num:\n",
" num[u] = 0\n",
" num[u] += 1\n",
" if u not in sim:\n",
" sim[u] = {}\n",
" for j in range(len(users)):\n",
" if j == i: continue\n",
" v = users[j]\n",
" if v not in sim[u]:\n",
" sim[u][v] = 0\n",
" # 相比UserCF,主要是改进了这里\n",
" sim[u][v] += 1 / math.log(1 + len(users))\n",
" for u in sim:\n",
" for v in sim[u]:\n",
" sim[u][v] /&#完整地实现了推荐系统的构建、实验和评估过程,为不同推荐算法在同一数据集上的性能比较提供了可重复实验的框架
news2026/2/13 17:57:43
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2277589.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

JAVA:利用 RabbitMQ 死信队列实现支付超时场景的技术指南
1、简述
在支付系统中,订单支付的超时自动撤销是一个非常常见的业务场景。通常用户未在规定时间内完成支付,系统会自动取消订单,释放相应的资源。本文将通过利用 RabbitMQ 的 死信队列(Dead Letter Queue, DLQ)来实现…

![[青基解读一] 2025年国家自然科学基金---指南解读](https://i-blog.csdnimg.cn/direct/00d82bfffcf945af886aae6bbb8e1729.png)
[青基解读一] 2025年国家自然科学基金---指南解读
指南解读
1 需要2个高级专业技术职称推荐(2个正教授) 2 国自然、国社科只能申请一个 3 资助类别 亚类说明 附注说明 自由探索or目标导向 4 申请代码到二级 申请代码、研究方向、关键词 主要参与者不写学生仅写人数 主要参与者 在线采集、填写简历、生成…

Open FPV VTX开源之ardupilot配置
Open FPV VTX开源之ardupilot配置 1. 源由2. 配置3. 总结4. 参考资料5. 补充5.1 飞控固件版本5.2 配置Ardupilot的BF OSD5.3 OSD偏左问题 1. 源由
飞控嵌入式OSD - ardupilot配置使用ardupliot配套OSD图片。
Choose correct font depending on Flight Controller SW. ──>…

HarmonyOS应用开发者初级认证最新版– 2025/1/13号题库新版
1.欢迎各位读者,本文档来自鸿蒙开发学员亲测,最新版。(考试时直接Ctrlf进行搜索,一定要认真比对答案,有的答案相似度很高)!!!!!! 欢迎…

视觉多模态大模型---MiniMax-vl-01---以闪电般的注意力缩放基础模型
简介
MiniMax-VL-01 是与今年1月15日由上海稀宇科技有限公司(MiniMax)发布并开源的一款视觉多模态大模型,它与基础语言大模型 MiniMax-Text-01 一同构成了 MiniMax-01 系列。这款模型的设计初衷是为了应对日益增长的长上下文处理需求&#x…

CF 230A.Dragons(Java实现)
题目分析 (桐老爷,泪目)题目讲很多字,其实就是打怪升级,初始战斗力>龙的战斗力就能击败龙并炼化经验增加战斗力,然后打下一条龙,如果打不过了就寄
思路分析 首先我还是想到键值对࿰…

【落羽的落羽 C语言篇】文件操作
文章目录 一、文件的概念和分类1. 概念和分类2. 文件名3. 数据文件 三、文件操作1. 文件的打开和关闭1.1 流1.2 文件指针1.3 文件的打开和关闭 2. 文件的顺序读写3. 文件的随机读写4. 文件读取的判定5. 文件缓冲区 一、文件的概念和分类
1. 概念和分类
文件是用来保存数据的。…

速通Docker === 介绍与安装
目录 Docker介绍
Docker优势
Docker组件
Docker CLI (命令行接口)
Docker Host (Docker 守护进程)
容器 (Container)
镜像 (Image)
仓库 (Registry)
关系总结
应用程序部署方式
传统部署 (Traditional Deployment)
虚拟化部署 (Virtualization Deployment)
容器部署…

数据分析:非度量多维排列 NMDS (Non-metric multidimensional scaling)ANOSIM检验分析
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍原理步骤加载R包数据下载导入数据数据预处理计算距离矩阵ANOSIM检验非度量多维排列NMDS应力值(stress value)画图输出系统信息介绍
非度量多维排列(Non-metric Multidimensiona…

Flink (七): DataStream API (四) Watermarks
1. Event Time and Processing Time
1. 1 处理时间(Processing time)
处理时间是指执行相应操作的机器的系统时间。当流处理程序基于处理时间运行时,所有基于时间的操作(如时间窗口)将使用执行相应算子的机器的系统时…

OpenStack 网络服务的插件架构
OpenStack 的网络服务具有灵活的插件架构,可支持多种不同类型的插件以满足不同的网络需求。以下是对 OpenStack 网络服务插件架构中一些常见插件类型的介绍: 一、SDN 插件
Neutron 与 SDN 的集成:在 OpenStack 网络服务里,SDN 插…

光伏储能交直流微电网Matlab/Simulink仿真模型
博士毕业后项目和课题的交接工作也都基本上结束了,之前从20年我博一开始创作的博客,我也将从25年伊始重新进行更新,在保留原有内容的基础上,在对现如今的研究热点进行补充,希望能为各位校友提供一定的研究思路。首先是…

【js进阶】设计模式之单例模式的几种声明方式
单例模式,简言之就是一个类无论实例化多少次,最终都是同一个对象
原生js的几个辅助方式的实现
手写forEch,map,filter
Array.prototype.MyForEach function (callback) {for (let i 0; i < this.length; i) {callback(this[i], i, this);}
};con…

Broker收到消息之后如何存储
1.前言
此文章是在儒猿课程中的学习笔记,感兴趣的想看原来的课程可以去咨询儒猿课堂《从0开始带你成为RocketMQ高手》,我本人觉得这个作者还是不错,都是从场景来进行分析,感觉还是挺适合我这种小白的。这块主要都是我自己的学习笔…


计算机网络 网络层 2
IP协议:
Ip数据报的格式: 首部:分为固定部分 和 可变部分
固定部分是20B 版本:表明了是IPV4还是IPV6
首部长度:单位是 4B,表示的范围是(5~15)*4B
填充:全0,,让首部变…
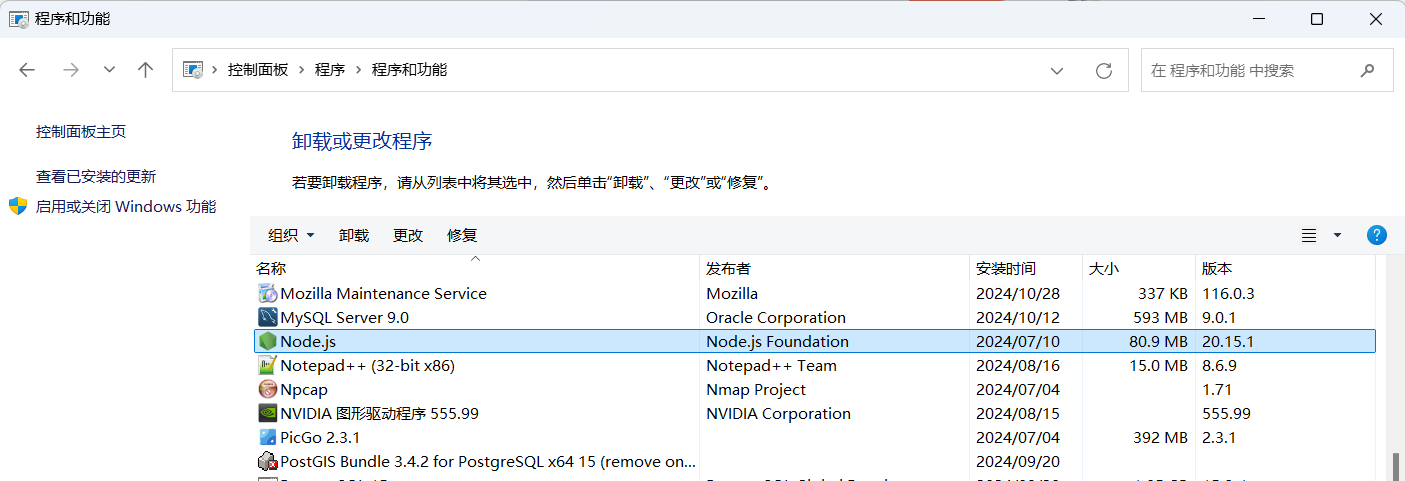
干净卸载Windows的Node.js环境的方法
本文介绍在Windows电脑中,彻底删除Node.js环境的方法。 在之前的文章Windows系统下载、部署Node.js与npm环境的方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/144810076)中,我们介绍过在Windows电脑中࿰…

《汽车维护与修理》是什么级别的期刊?是正规期刊吗?能评职称吗?
问题解答:
问:《汽车维护与修理》是不是核心期刊?
答:不是,是知网收录的正规学术期刊。
问:《汽车维护与修理》级别?
答:国家级。主管单位:中国汽车维修行业协会 …
