目录
- 前言
- 概述
- SD安装
- 1、安装软件
- 2、启动
- 3、配置
- 4、运行
- 5、测试
- 导入SD模型【决定画风】
- 常用模型
- 下载安装模型
- SD卸载
- SD文生图
- 提示词
- 提示词使用技巧
- 提示词的高级使用技巧
- 强调关键词
前言
我向来不喜欢搞一些没有用的概念,所以直接整理可能用到的东西。
sd简单的说就是一个更据描述生成不同风格的图片的东西,与之对应的还有mj,但是我绝对不会使用他,为什么,因为收费,可以不赚钱,但是绝对不能往里搭,无非浪费一些时间而已
软件下载
- 秋葉aaaki 唯一账号:https://space.bilibili.com/12566101
概述
Stable Diffusion模型并不是单一的文生图模型,而是多个模型组成的运作系统,其中的技术可以拆解为3个结构来看:
- ClipText 文本编码器 :用于解析提示词的Clip模型
- 编码器Clip ,它是由OpenAI公司开发的模型,包括文本编码和图像编码2个部分,分别用于提取文本和图像的特征,通过搜集大量网络上的图像和文字信息再对Clip模型进行训练,可以实现文本和图像的对应关系。
- 在SD模型运作过程中,它可以提取提示词文本部分的特征传递给图像生成器,让模型理解我们输入的提示词内容,从而达到文本控制图像生成的目的。
- Diffusion扩散模型 : 用于生成图像的U-Net 和Sche duler
- 就是更据算法什么东西的生成图像
- VAE模型 : 用于压缩和恢复的图像解码器
- 相当于滤镜
SD安装
1、安装软件

2、启动

3、配置



4、运行


5、测试
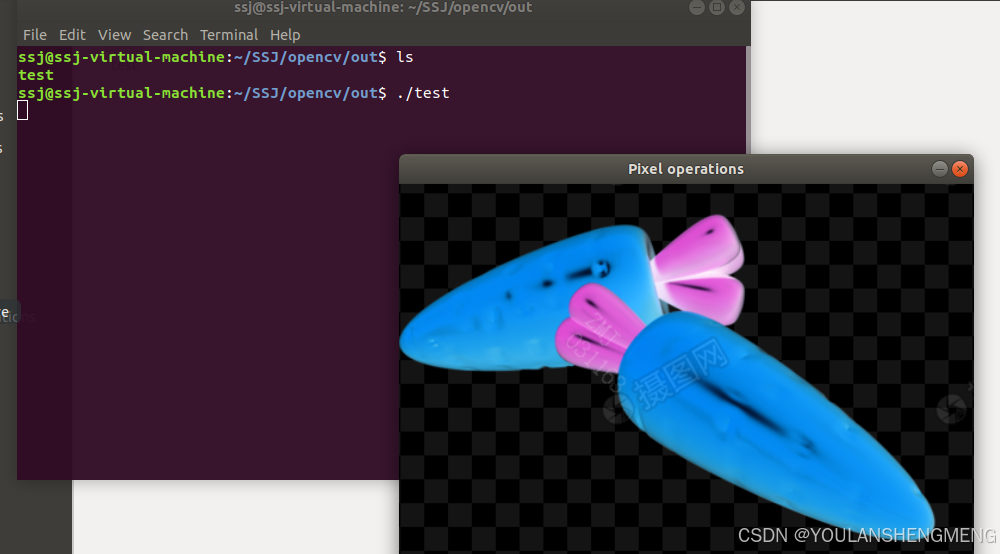
要么直接弹窗,要么就复制控制台中的链接http://127.0.0.1:7860
打开页面后直接点击生成,看看有没有图片生成

导入SD模型【决定画风】
常用模型
- Checkpoint(大模型)【常用】
- 相当于风格滤镜,例如 油画,漫画,写实风等。
- 需要注意的是,一些Checkpoint需要与特定的低码率编码器(Lora)配置使用,以获得更好的效果
- VAE模型
- 对模型的滤镜进行微调,不同的VAE右一些细节上的差异,但是不会影响输出的效果
- 可以理解成对模型进行增强,有些模型文件已经有了VAE效果,所以不要盲目挂载,选择自动模式就行
- embedding
- 相当于组件。举个例子,如果我们想要生成一个开心的皮卡丘,通常需要输入很多描述词,如黄毛、老鼠、长耳朵、红等等。但是,如果引入皮卡丘的embedding,我们只需要输入两个词:皮卡丘和开心。皮卡丘的embedding打包了所有皮卡丘的特征描述,这样我们就不用每次输入很多单词来控制生成的画面了。
- 在日常使用中,embedding技术通常用于控制人物的动作和特征,或者生成特定的画风。相比于其他模型(如LORA),embedding的大小只有几十KB,而不是几百兆或几GB,除了还原度对比lora差一些但在存储和使用上更加方便
- LoRA模型【常用】
- LORA与embedding在本质上类似,因为携带着大量的训练数据,所以LORA对人物和细节特征的复刻更加细腻。
- 每个LORA模型对输出图像的权重设置是非常重要的。权重设置越大,对画面的影响因素就越浅。通常情况下,权重应该控制在0.7-1之间。如果权重过高,会大幅度影响出图的质量。
- 为了获得最佳效果,我们可以根据不同的LORA模型选择适当的提示词和排除词,并在设置权重时进行调整。同时,我们还可以参考其他作者的经验和技巧,以便更好地利用LORA生成图像
下载安装模型
- https://civitai.com/各类模型下载也俗称c站(不稳定,用魔法)
- https://lexica.art/找一些风格提示词不错
- https://www.liblib.art/


SD卸载
直接把整个文件夹删除,删除前记得把模型复制出来,以后还能用
SD文生图
Stable Diffusion基础的操作流程并不复杂
- 选择模型【决定画风】
- 选择功能(文生图)
- 填写提示词【主要决定画面内容】
- 设置参数 【设置图像的预设属性】
- 点击生成。
通过操作流程就能看出,我们最终的出图效果是由 模型、提示词、参数设置 三者共同决定的,缺一不可。

提示词
大家都知道,如今的AI工具大多是通过提示词来控制模型算法,那究竟什么是提示词?
对于人类而言,在经过多年的学习和使用后,我们只需简单的几句话便能轻松的沟通和交流。但如今的人工智能还是基于大模型的数据库进行学习,如果只是通过简单的自然语言描述,没有办法做到准确理解。为了更好的控制AI,人们逐渐摸索出通过反馈来约束模型的方法,原理就是当模型在执行任务的时候,人类提供正面或负面的反馈来指导模型的行为。而这种用于指导模型的信息,就被统称为 Prompt提示词。
Stable Diffusion的咒语上除了prompt(正向关键词)外,还有Negative prompt反向关键词。
- 正向提示词用于描述想要生成的图像内容,
- 反向关键词用于控制不想出现在图像中的内容
比如目前很多模型还无法理解的手部构造,为了避免出现变形,我们可以提前在反向关键词中输入手部相关的提示词,让绘图结果规避出现手的情况。
注意:不是zg人开发的,所以这里的提示词去翻译成英文,只需以词组形式分段输入即可,词组间使用英文逗号进行分隔。大部分情况下字母大小写和断行也不会影响画面内容,我们可以直接将不同部分的提示词进行断行,由此来提升咒语的可读性。
提示词使用技巧
当然如果每次都是想到什么输什么,画面中可能还是会缺失很多信息,这里给大家分享一下我自己平时使用的提示词公式,按顺序分别为: 主体内容、环境背景、构图镜头、图像设定、参考风格。 后续在编写咒语时可以按照一下类目对号入座,会更加规范和易读。
需要注意的是,公式只是参考,并非每次编写咒语我们都要包含所有内容,正常的流程应该是先填写主体内容看看出图效果,再根据自己的需求来做优化调整。

提示词的高级使用技巧
强调关键词
先来看看 强调关键词 ,这应该是使用最为频繁的语法了。强调关键词是依赖括号和数值来控制特定关键词的权重,当权重数值越高,说明模型对该关键词更加重视,在运行过程中模型就会着重绘制该部分的元素,在最终成像时图片中就会体现更多对应信息。反之数值越低,则最终图片中对应内容会展示的更少。
控制关键词的括号共有三种类型: 圆括号()、花括号{}和方括号[] ,分别表示将括号内关键词的权重调整到原有的1.1倍、1.05倍和0.9倍。其中花括号{}平时很少会使用, 一般都是用圆括号()和方括号[] 。
需要注意的是,这里括号是支持多层叠加的,每层括号都表示乘以固定倍数的权重

除了直接加括号外,还有一种更常用的控制权重方法,那就是直接填写数值。

虽然强调关键词语法支持的权重范围在0.1~100之间,但是过高和过低的权重都会影响出图效果,因此建议大家控制在 0.5~1.5 范围即可。
这里还有个快捷操作的小技巧,就是选中对应关键词后,按住 ctrl+⬆️ / ⬇️ ,可以快速增加和减少权重数值,默认每次修改0.1,可以在设置中修改默认数值。