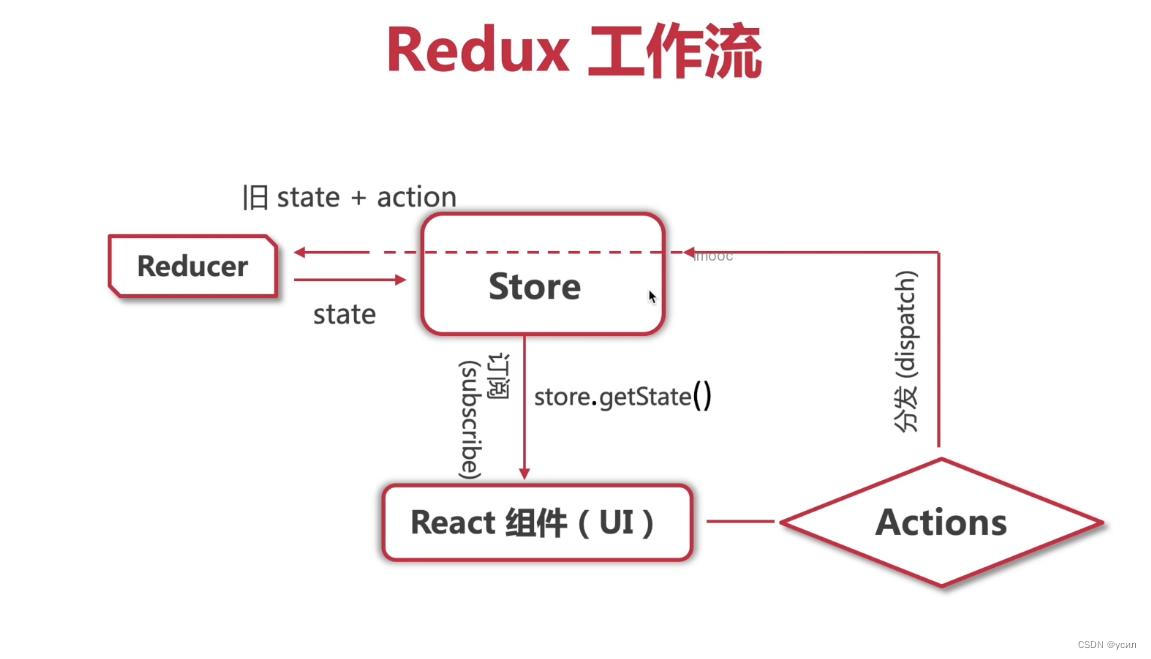
- 1. 传统卷积
- 2. Mobilenet V1
- 2.1 Separable卷积
- 2.2 整体结构
- 3. Mobilenet V2
- 3.1 Relu
- 3.2 逆残差
- 3.3 整体结构
- 4. Mobilenet V3
- 4.1 SE attention
- 4.2 Switch激活函数
- 5. Mobilenet V3 代码
2016年直至现在,业内提出了SqueezeNet、ShuffleNet、NasNet、MnasNet以及MobileNet等轻量级网络模型。这些模型使移动终端、嵌入式设备运行神经网络模型成为可能。
V1(Separable卷积)->V2(逆残差)->V3(SE)
1. 传统卷积
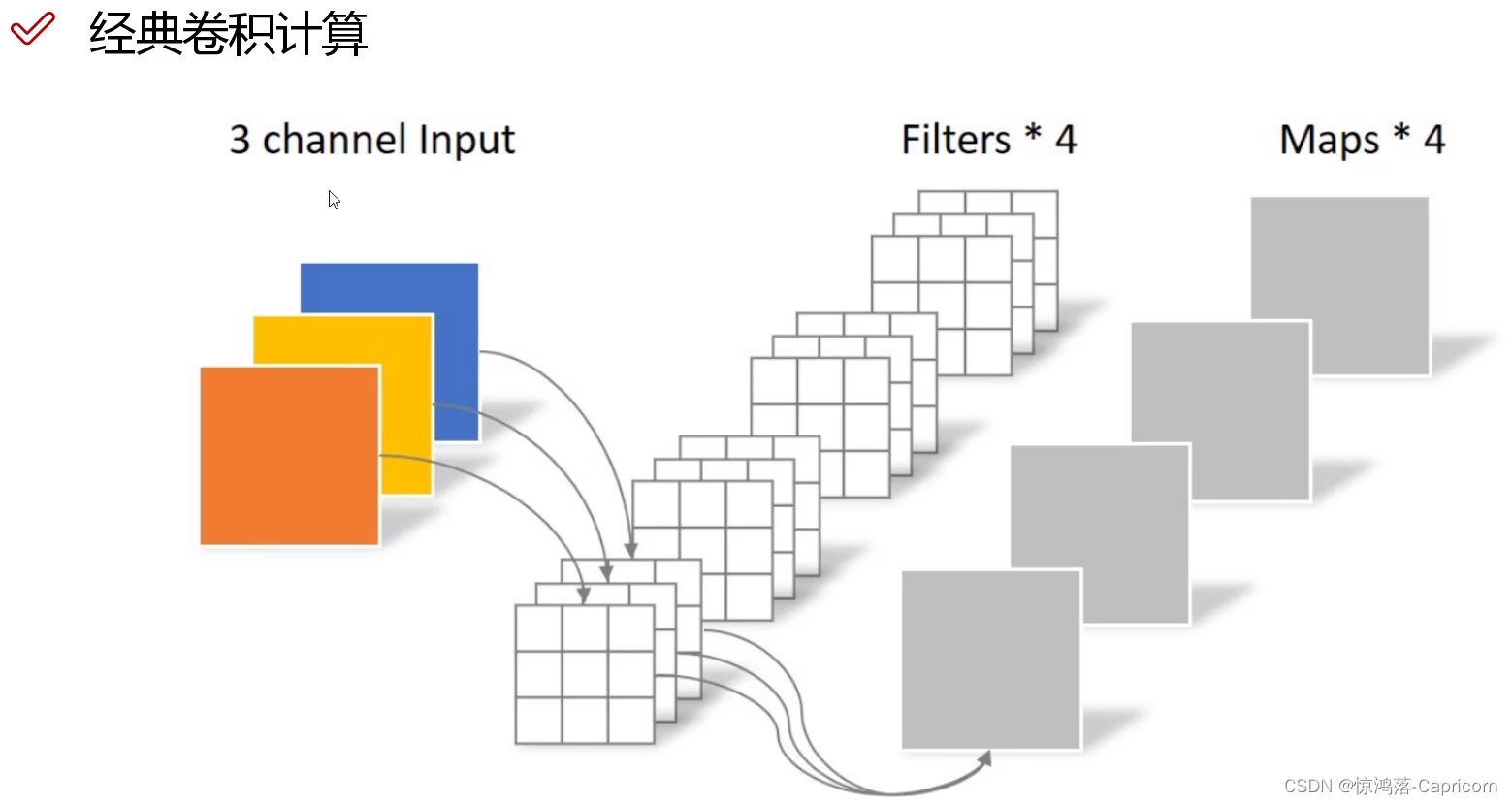
输入图像的channel=卷积核的channel
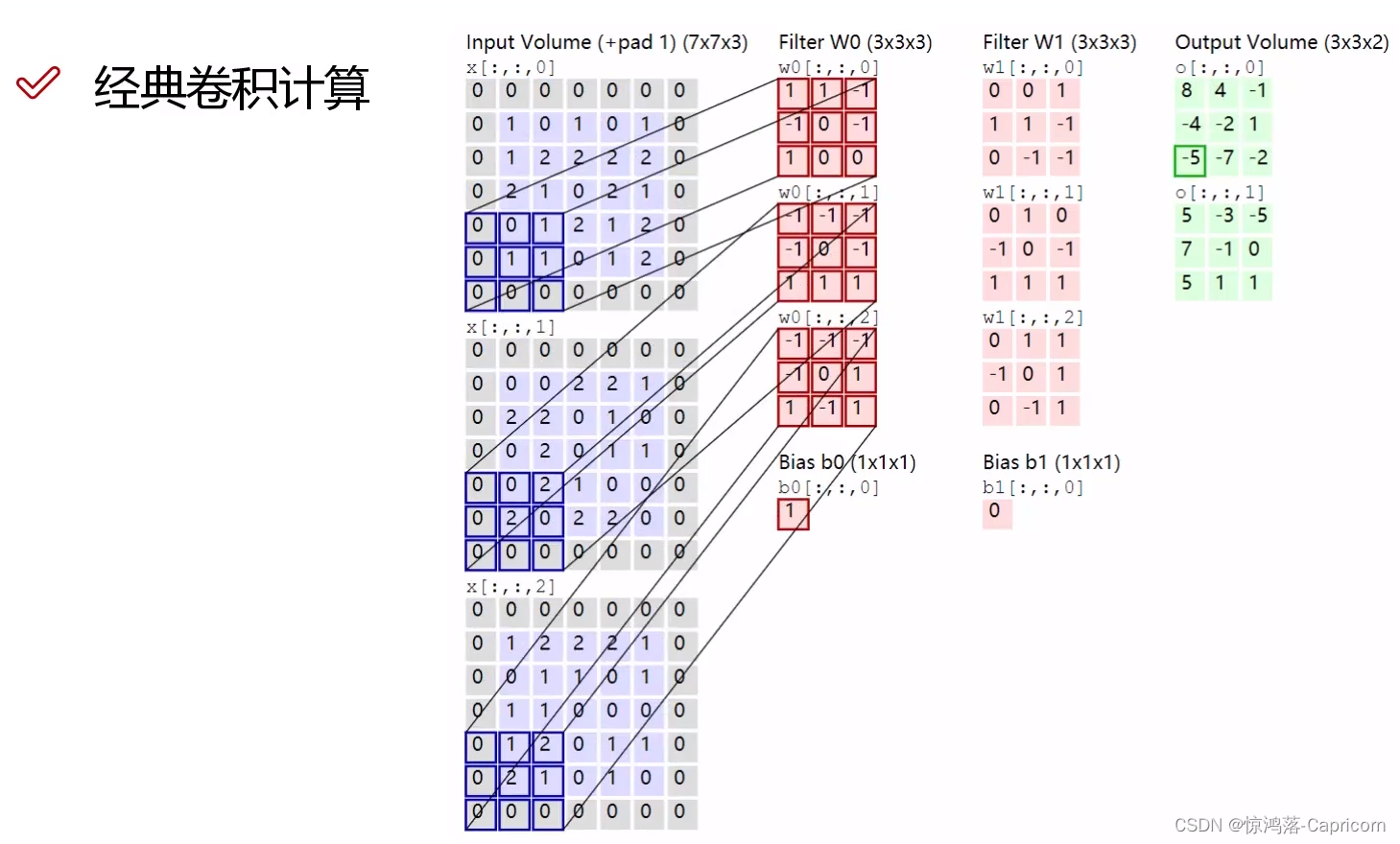
计算量 与 H W 卷积核大小有关
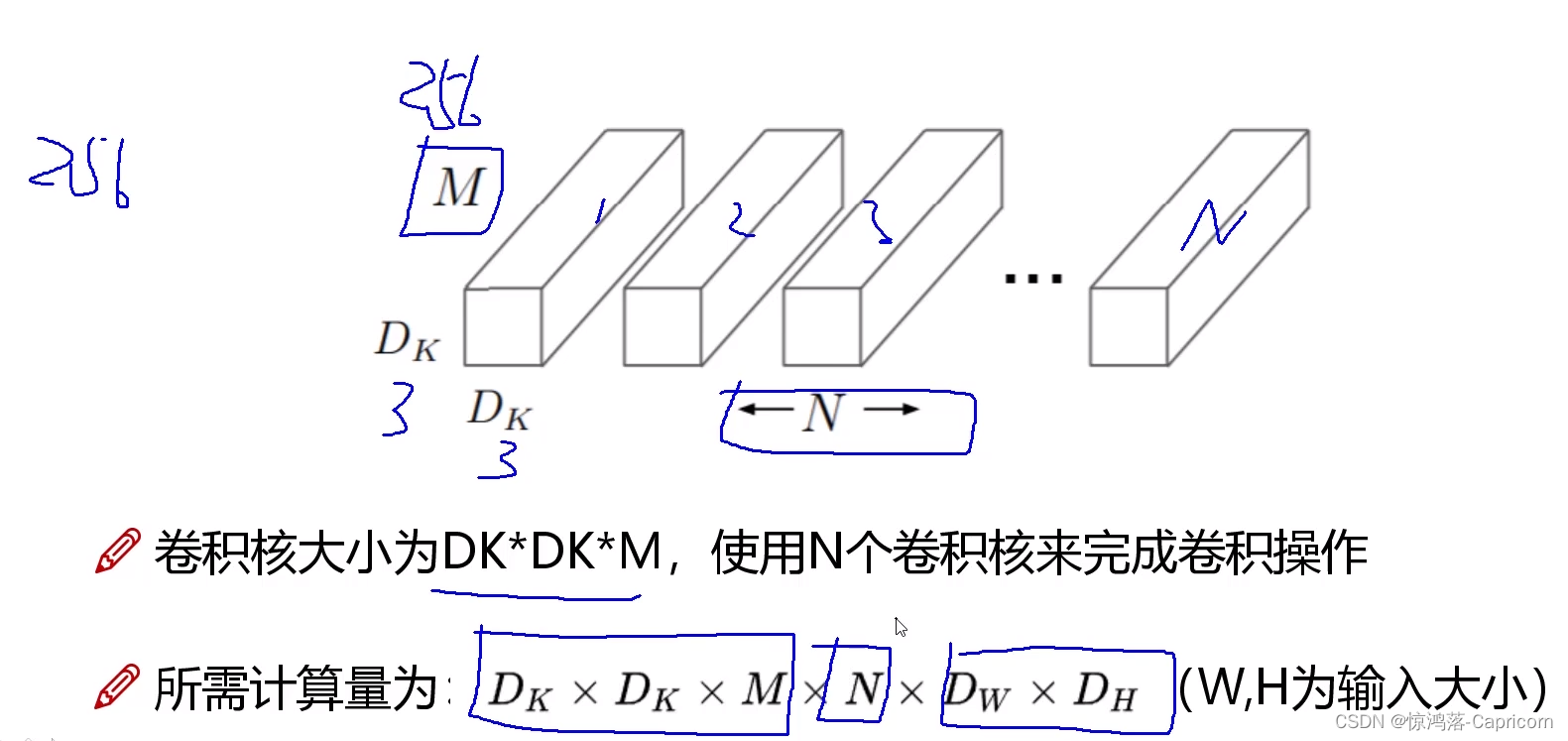
2. Mobilenet V1
2.1 Separable卷积
Step1:逐通道独立卷积(Depthwise卷积):一个卷积核负责一个通道
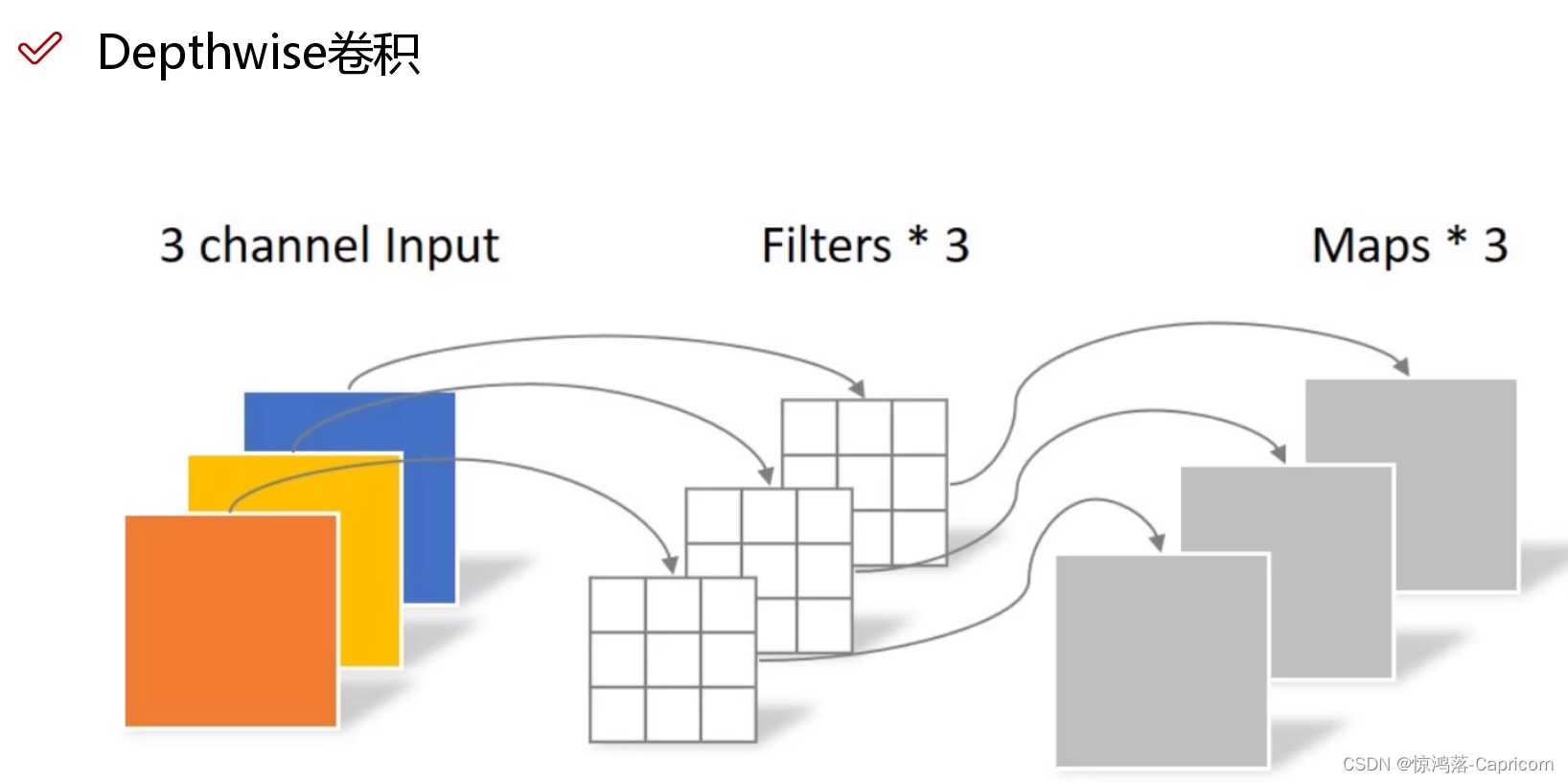
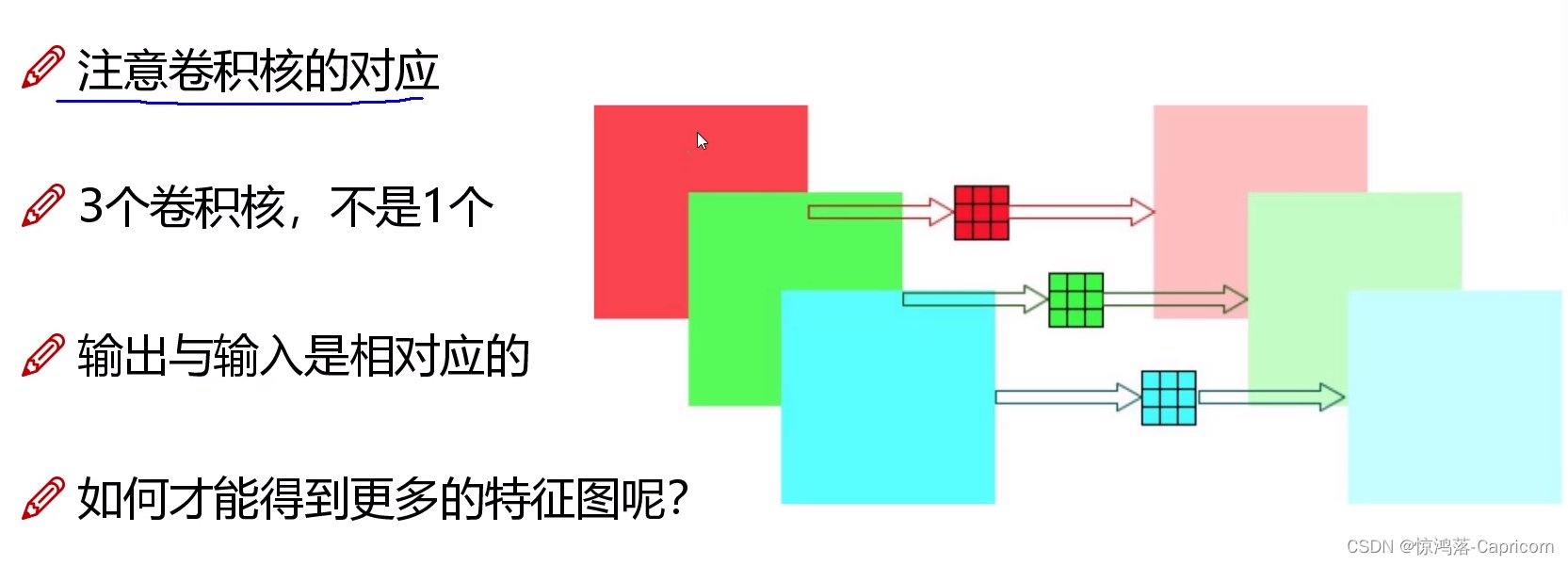
Step2:逐点卷积(Pointwise卷积):卷积核1x1的普通卷积,省参数,N个卷积核得到N个特征图
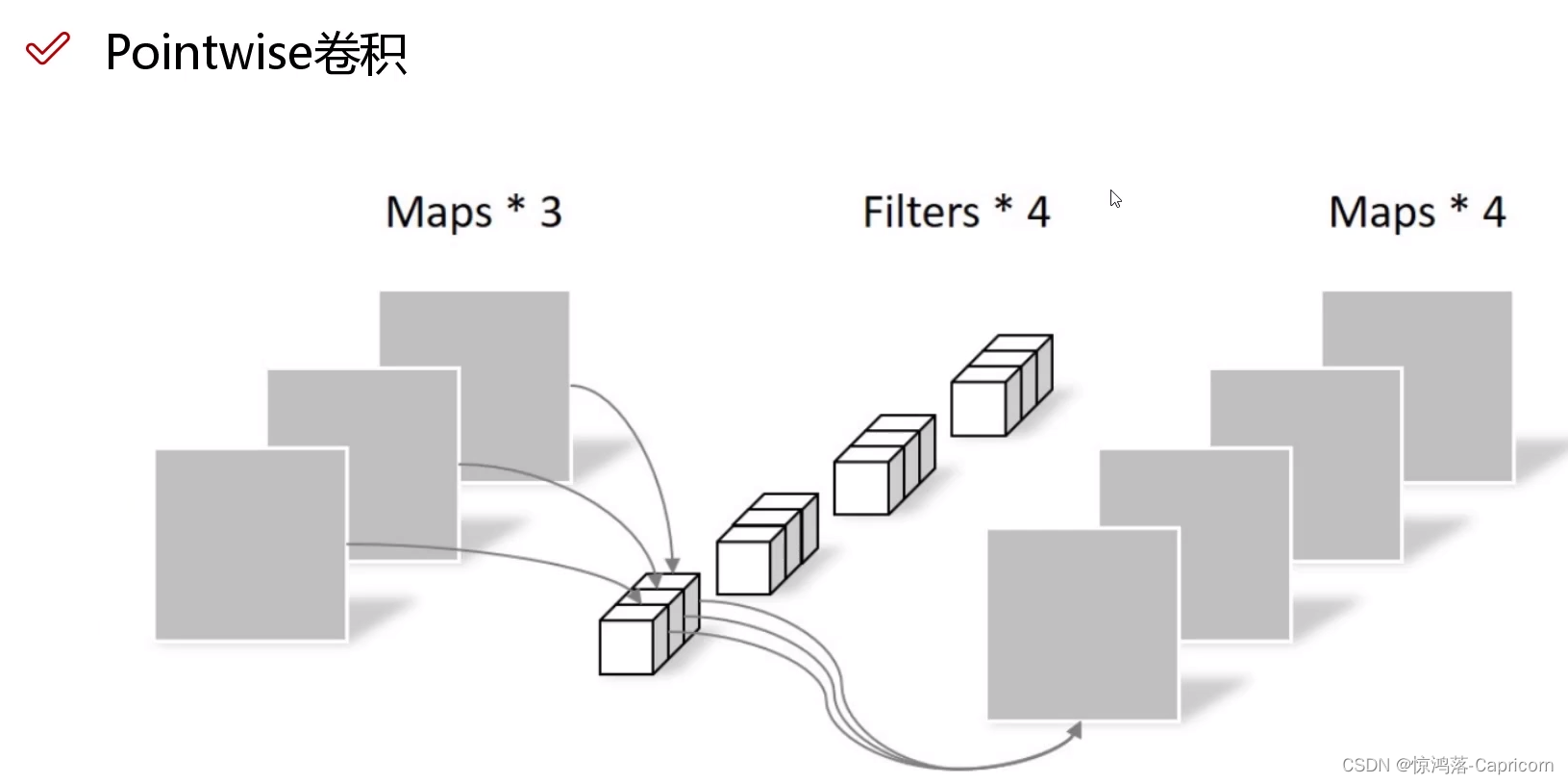
两步走的Separable卷积效果与普通卷积相似,但计算量大大减小
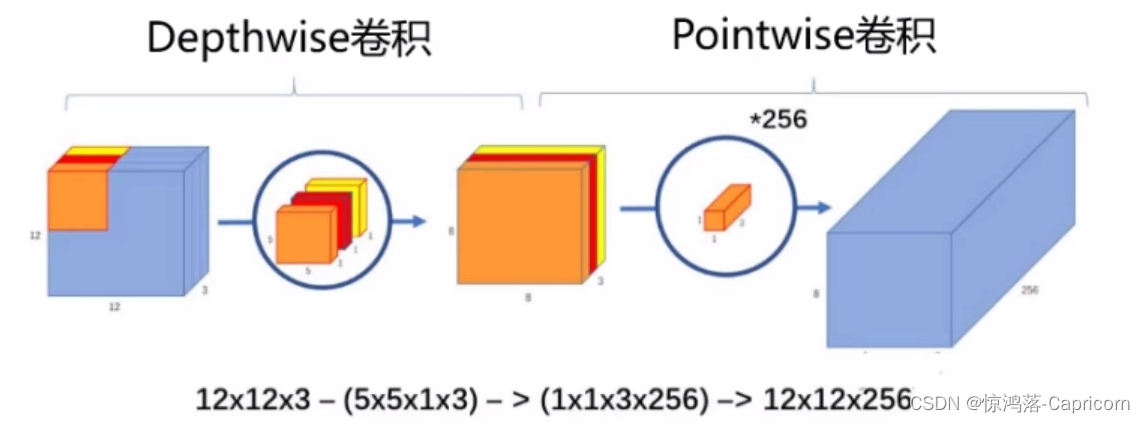


2.2 整体结构
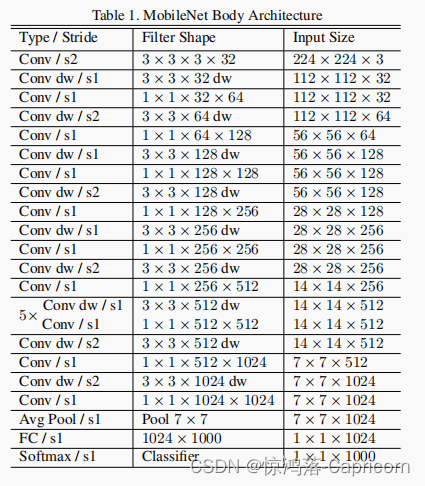
v1一路卷积到底
使用relu6
3. Mobilenet V2

3.1 Relu
relu使低维数据损失信息
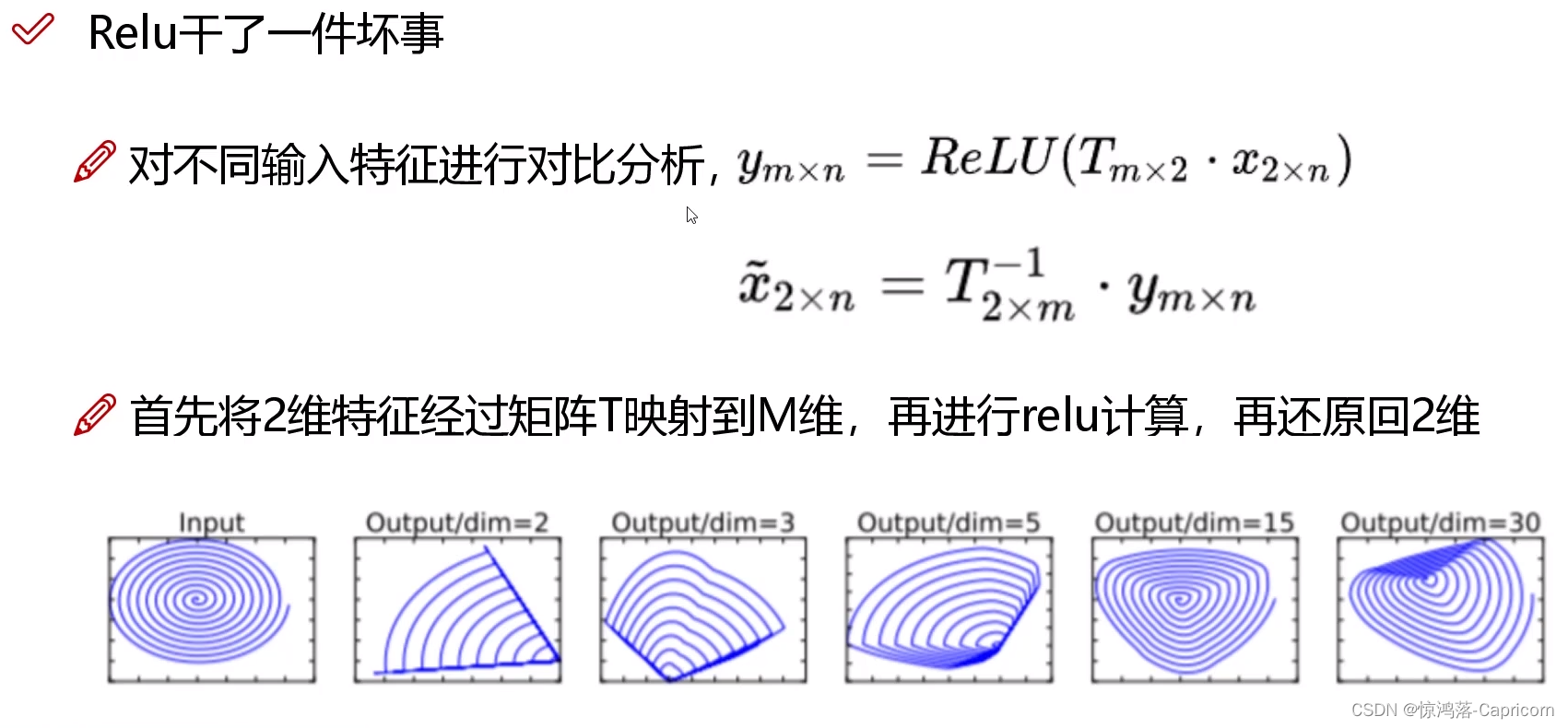
3.2 逆残差
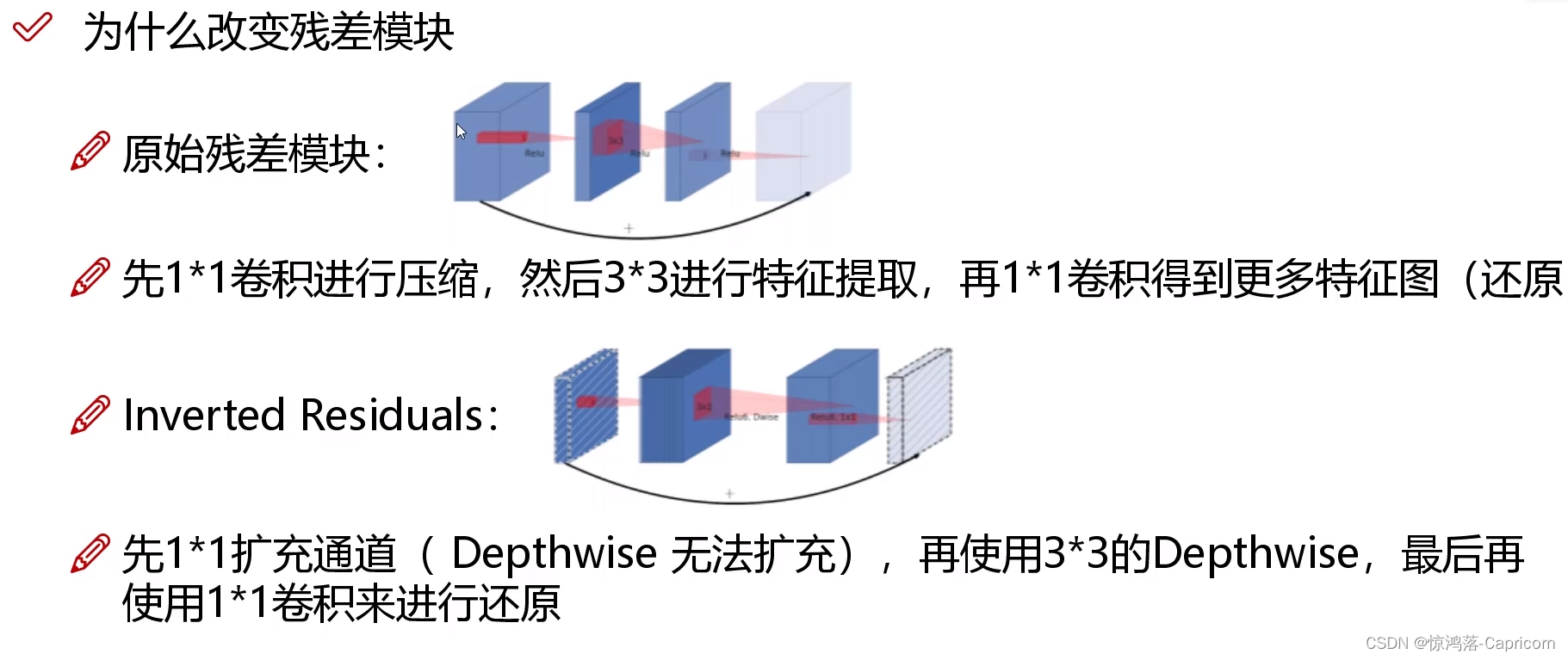
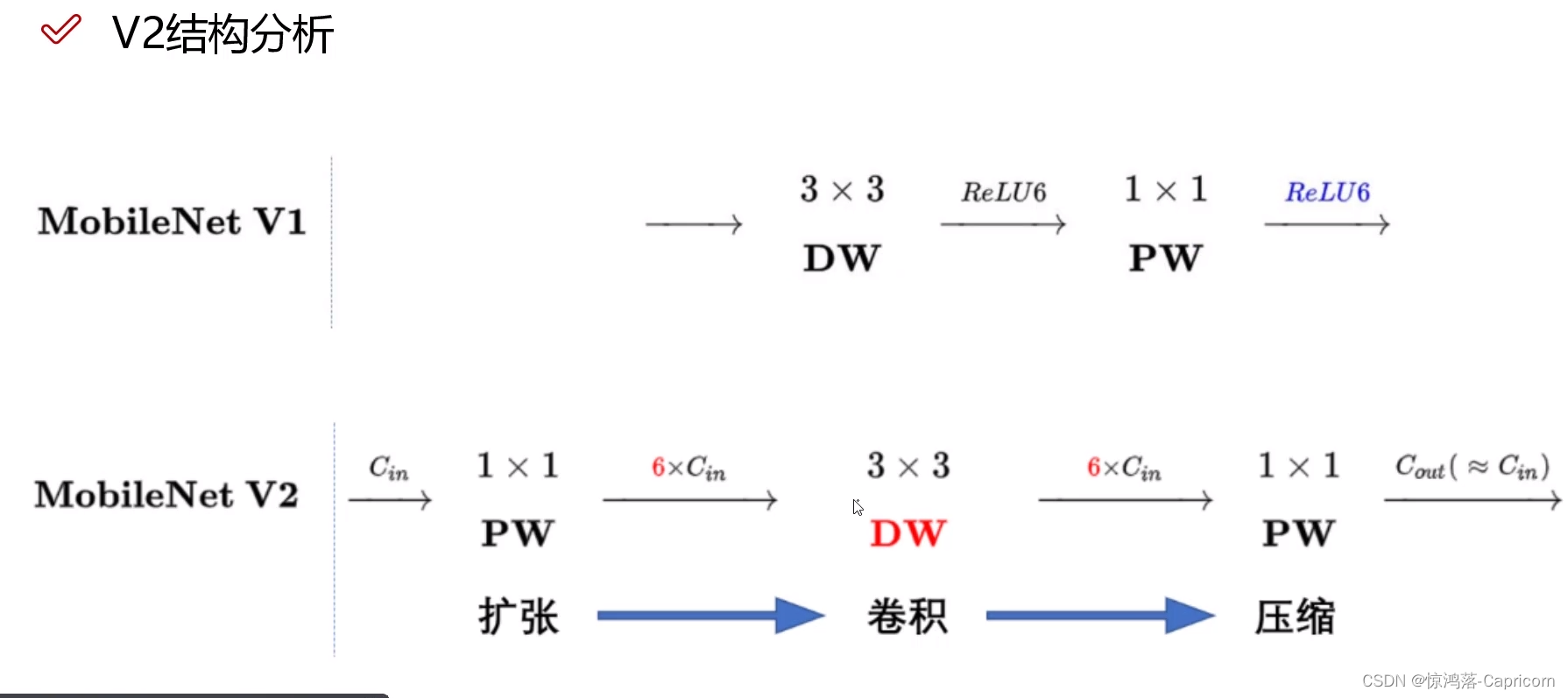
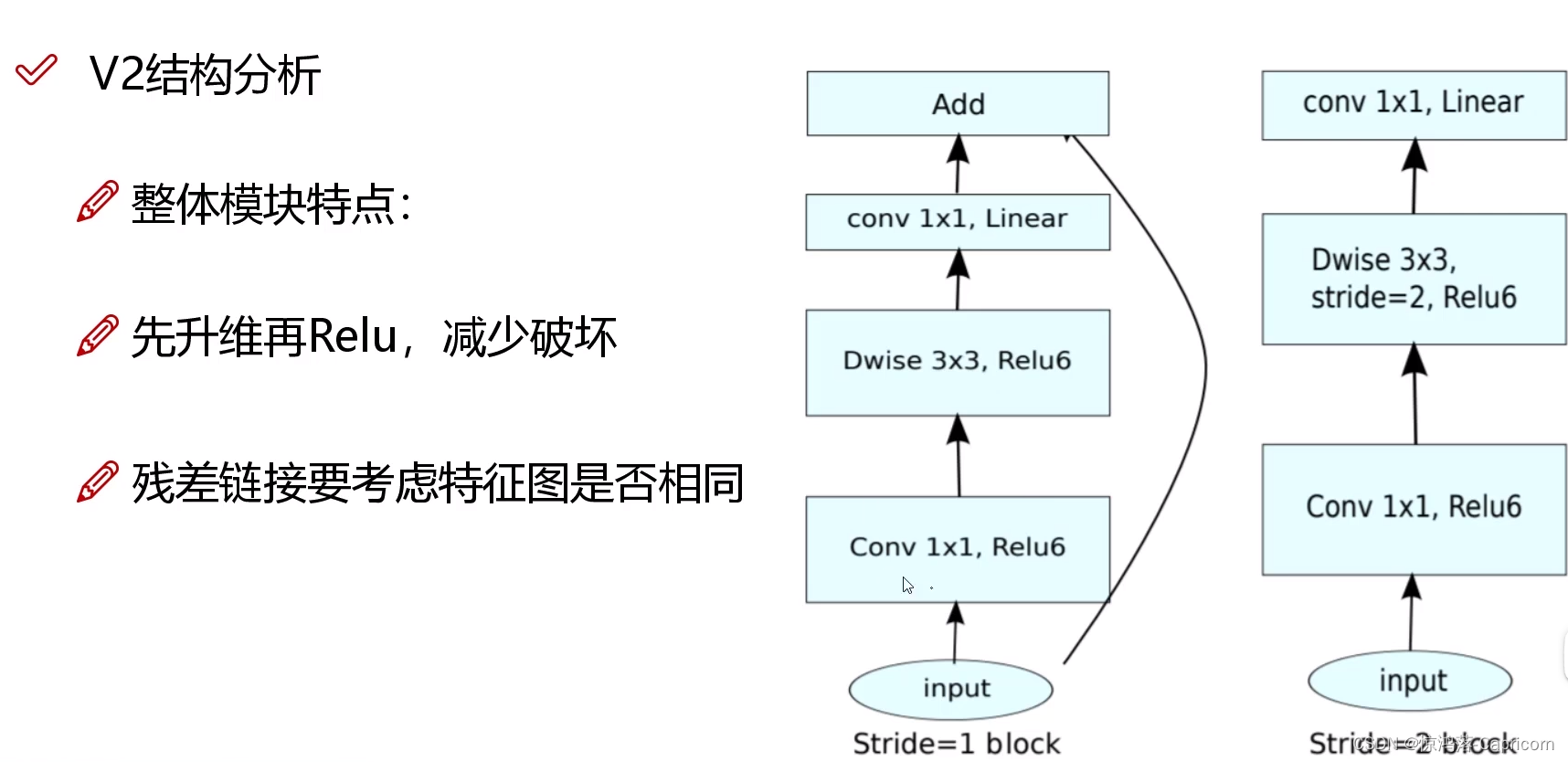
3.3 整体结构

4. Mobilenet V3

4.1 SE attention
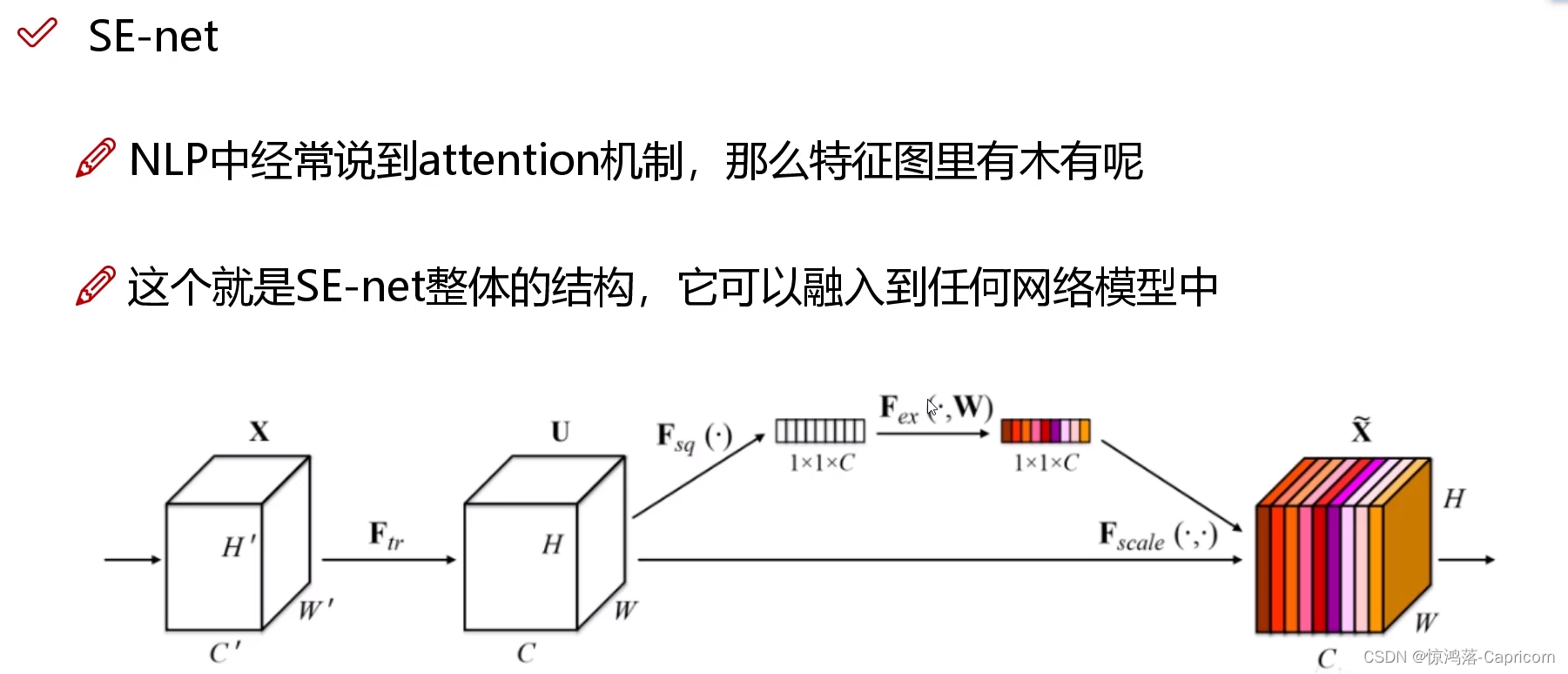
Step1:求每个通道的权重值(1x1xc)(全局平均池化)

Step2:使用两个全连接层计算权重值的回归值sc(1x1xc),然后完成加权操作(每个通道权重回归值sc x 每个通道原始特征图uc)

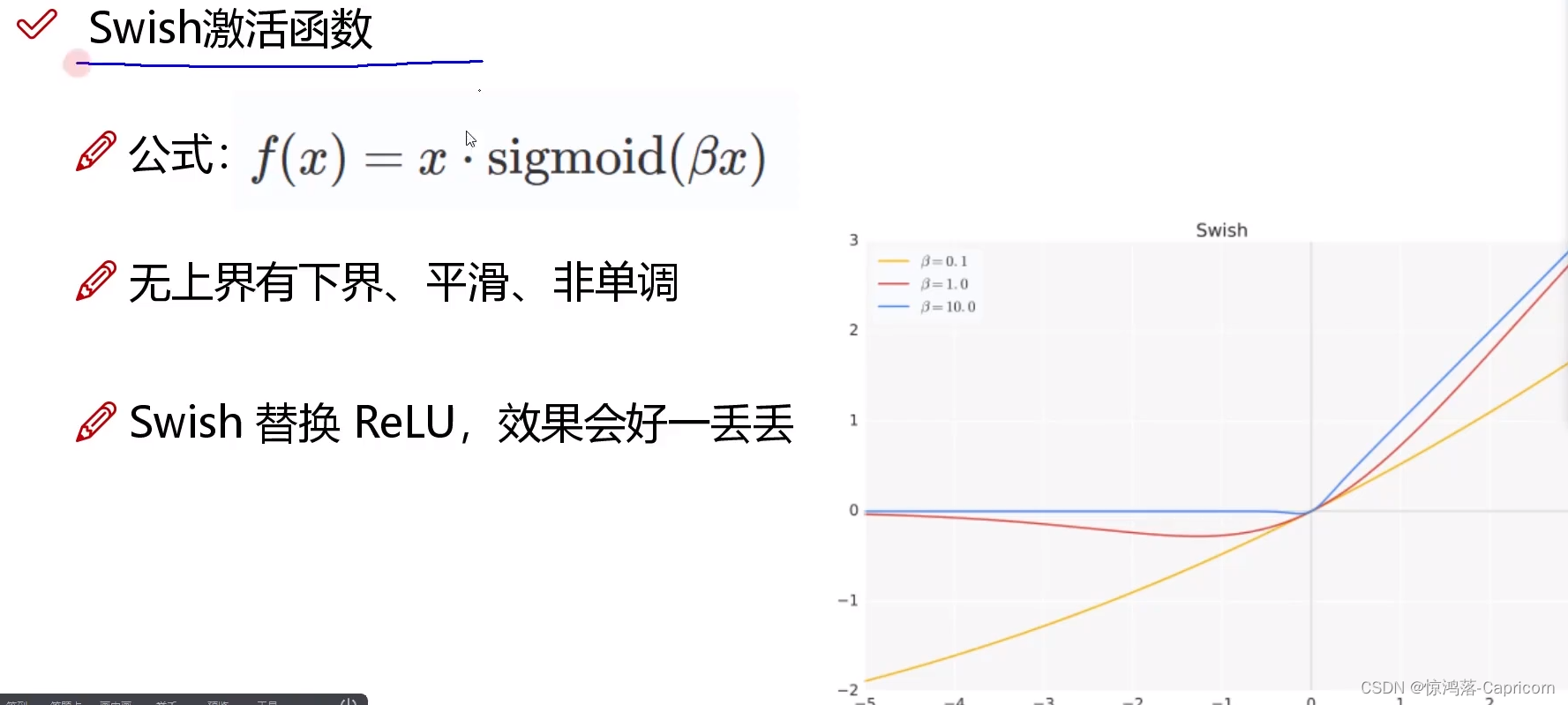
4.2 Switch激活函数
5. Mobilenet V3 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
class hsigmoid(nn.Module):
def forward(self, x):
out = F.relu6(x + 3, inplace=True) / 6
return out
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size // reduction),
nn.ReLU(inplace=True),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size),
hsigmoid()
)
def forward(self, x):
return x * self.se(x)
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_size)
self.shortcut = nn.Sequential()
if stride == 1 and in_size != out_size:
self.shortcut = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_size),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se != None:
out = self.se(out)
out = out + self.shortcut(x) if self.stride==1 else out
return out
class MobileNetV3_Large(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Large, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), None, 1),
Block(3, 16, 64, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 72, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 72, 40, nn.ReLU(inplace=True), SeModule(40), 2),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(3, 40, 240, 80, hswish(), None, 2),
Block(3, 80, 200, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 480, 112, hswish(), SeModule(112), 1),
Block(3, 112, 672, 112, hswish(), SeModule(112), 1),
Block(5, 112, 672, 160, hswish(), SeModule(160), 1),
Block(5, 160, 672, 160, hswish(), SeModule(160), 2),
Block(5, 160, 960, 160, hswish(), SeModule(160), 1),
)
self.conv2 = nn.Conv2d(160, 960, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(960)
self.hs2 = hswish()
self.linear3 = nn.Linear(960, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
class MobileNetV3_Small(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Small, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), SeModule(16), 2),
Block(3, 16, 72, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 88, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 96, 40, hswish(), SeModule(40), 2),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 120, 48, hswish(), SeModule(48), 1),
Block(5, 48, 144, 48, hswish(), SeModule(48), 1),
Block(5, 48, 288, 96, hswish(), SeModule(96), 2),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
)
self.conv2 = nn.Conv2d(96, 576, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(576)
self.hs2 = hswish()
self.linear3 = nn.Linear(576, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
def test():
net = MobileNetV3_Small()
x = torch.randn(2,3,224,224)
y = net(x)
print(y.size())
test()