- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,Java领域新星创作者
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人

文章目录
- 一、引言
- 二、缓存池机制(BufferPool)
- 1. BufferPooll
- 2. allocate()
- 3. deallocate()
- 三、缓冲池流程图
- 四、总结
Kafka从成神到成仙系列
- 【Kafka从成神到升仙系列 一】Kafka源码环境搭建
- 【Kafka从成神到升仙系列 二】生产者如何将消息放入到内存缓冲区
- 【Kafka从成神到升仙系列 三】你真的了解 Kafka 的元数据嘛
初学一个技术,怎么了解该技术的源码至关重要。
对我而言,最佳的阅读源码的方式,那就是:不求甚解,观其大略
你如果进到庐山里头,二话不说,蹲下头来,弯下腰,就对着某棵树某棵小草猛研究而不是说先把庐山的整体脉络研究清楚了,那么你的学习方法肯定效率巨低而且特别痛苦。
最重要的还是慢慢地打击你的积极性,说我的学习怎么那么不 happy 啊,怎么那么没劲那,因为你的学习方法错了,大体读明白,先拿来用,用着用着,很多道理你就明白了。
先从整体上把关源码,再去扣一些细节问题。
举个简单的例子:
如果你刚接触 HashMap,你刚有兴趣去看其源码,在看 HashMap 的时候,有一个知识:当链表长度达到 8 之后,就变为了红黑树,小于 6 就变成了链表,当然,还和当前的长度有关。
这个时候,如果你去深究红黑树、为什么是 8 不是别的,又去查 泊松分布,最终会慢慢的耗死自己。
所以,正确的做法,我们先把这一部分给略过去,知道这个概念即可,等后面我们把整个庐山看完之后,再回过头抠细节。
当然,本章我们讲述 Kafka 生产者的缓存池机制
一、引言
kafka生产端的组成主要由以下几方面构成:
- 生产端的初始化
- 元数据的更新
- 缓存池(BufferPool)机制
- 网络
I/O模型 Sender的消息发送
其中,我们 生产端的初始化、元数据的更新已经介绍完毕,今天我们来看看 缓存池(BufferPool)机制
废话不多说,老司机开始发车
二、缓存池机制(BufferPool)
Kafka 为什么需要缓存池的机制呢?
我们先来看一下目前 Kafka 生产者这边的整体架构:
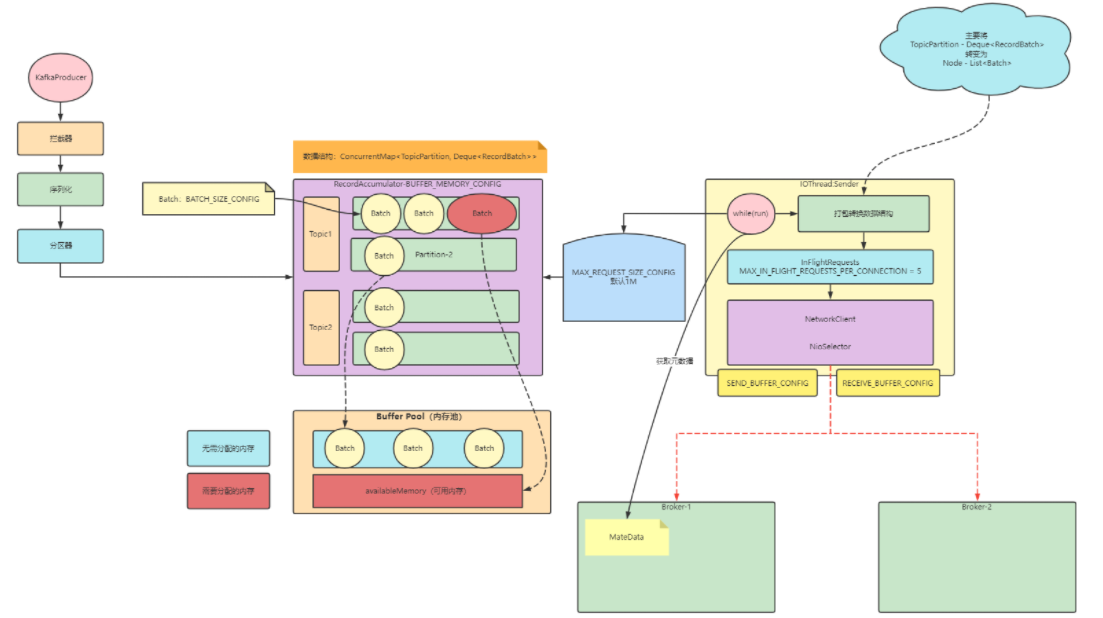
Kafka 拥有极大的吞吐量,并且生产者发送消息时,是按照 ProducerBatch 进行的发送。这个时候,如果我们不能合理的创建和释放 ProducerBatch,会造成严重的 GC 问题。
为了解决该问题,Kafka 设计了一套缓存池的架构机制
1. BufferPooll
竟然提到了缓存池,那么就不得不分析一下 BufferPool 的源码
public class BufferPool {
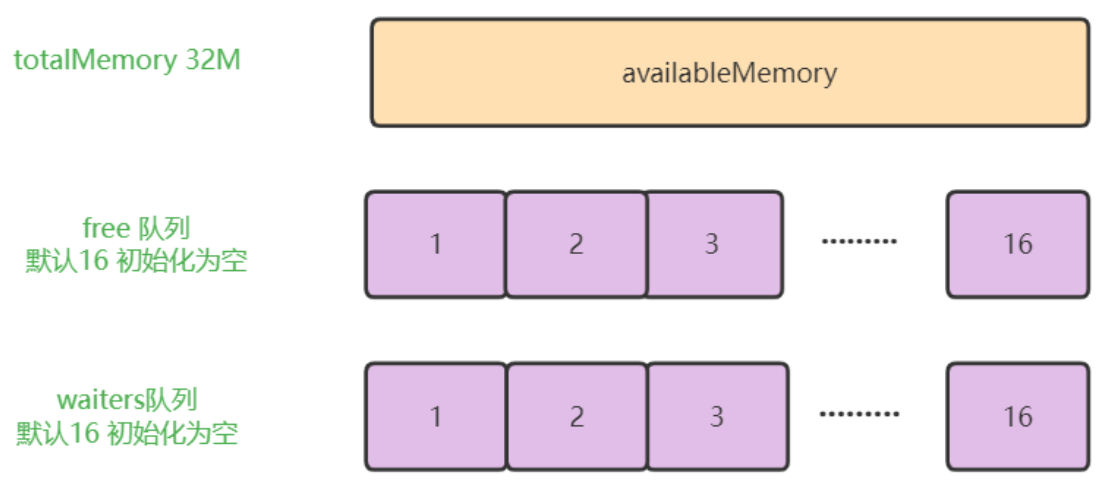
// 整个BufferPool总内存大小 默认32M
private final long totalMemory;
// 当前BufferPool管理的单个ByteBuffer大小,16k
private final int poolableSize;
// 因为有多线程并发分配和回收ByteBuffer,用锁控制并发,保证线程安全。
private final ReentrantLock lock;
// 对应一个ArrayDeque<ByteBuffer> 队列,其中缓存了固定大小的 ByteBuffer 对象
private final Deque<ByteBuffer> free;
// 此队列记录因申请不到足够空间而阻塞的线程对应的 Condition 对象
private final Deque<Condition> waiters;
// 非池化可用的内存即 totalMemory 减去 free 列表中的全部 ByteBuffer 的大小
private long availableMemory;
// 构造函数
public BufferPool(long memory, int poolableSize, Metrics metrics, Time time, String metricGrpName) {
...
// 总的内存
this.totalMemory = memory;
// 默认的池外内存,就是总的内存
this.availableMemory = memory;
}
}
所以,我们一开始的 BufferPool 的结构如下:
2. allocate()
这里我们先介绍一下缓存池分配的流程:如果你看不懂,没有关系,后面每种情况的解析及流程图,喜欢的可以点下关注吆~
/**
* 主要为当前的batch分配内存
*
*/
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
// 1. 如果当前申请的内存大于总内存,则直接报错
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
// 2. 加锁
this.lock.lock();
try {
// 3.申请内存大小恰好为16k 且free缓存池不为空
if (size == poolableSize && !this.free.isEmpty()) {
// 从free队列取出一个ByteBuffer
return this.free.pollFirst();
}
// 4. 计算下free队列当前拥有的内存大小
int freeListSize = this.free.size() * this.poolableSize;
// 如果 free + availableMemory 大于 当前的 size
if (this.availableMemory + freeListSize >= size) {
// 循环的将 free 队列中的 ByteBuffer 给排掉,分配给 availableMemory
freeUp(size);
this.availableMemory -= size;
lock.unlock();
return ByteBuffer.allocate(size);
} else {
// 5. 如果当前BufferPool不够提供申请内存大小,则需要阻塞当前线程
int accumulated = 0;
ByteBuffer buffer = null;
Condition moreMemory = this.lock.newCondition();
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
// 把自己添加到等待队列中末尾,保持公平性,先来的先获取内存,防止饥饿
this.waiters.addLast(moreMemory);
// 循环等待直到分配成功或超时
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
// 当前线程阻塞等待,返回结果为false则表示阻塞超时
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs,TimeUnit.NANOSECONDS);
// 6. 申请内存大小是16k,且free缓存池有了空闲的ByteBuffer
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// 从free队列取出一个ByteBuffer
buffer = this.free.pollFirst();
// 计算累加器
accumulated = size;
} else {
// 释放空间给非池化可用内存,并继续等待空闲空间,如果分配多了只取够size的空间
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.availableMemory);
// 释放非池化可用内存大小
this.availableMemory -= got;
// 累计分配了多少空间
accumulated += got;
}
}
// 7. 当非池化可用内存有内存或free缓存池有空闲ByteBufer且等待队列里有线程正在等待
if (this.availableMemory > 0 || !this.free.isEmpty()) {
if (!this.waiters.isEmpty())
// 唤醒队列里正在等待的线程
this.waiters.peekFirst().signal();
}
// 解锁
lock.unlock();
// 8. 说明空间足够,并且有足够空闲的了。可以执行真正的分配空间了。
if (buffer == null)
// 没有正好的buffer,从缓冲区外(JVM Heap)中直接分配内存
return ByteBuffer.allocate(size);
else
// 直接复用free缓存池的ByteBuffer
return buffer;
}
} finally {
if (lock.isHeldByCurrentThread())
lock.unlock();
}
}
我们概况一下分配的 4 种情况:
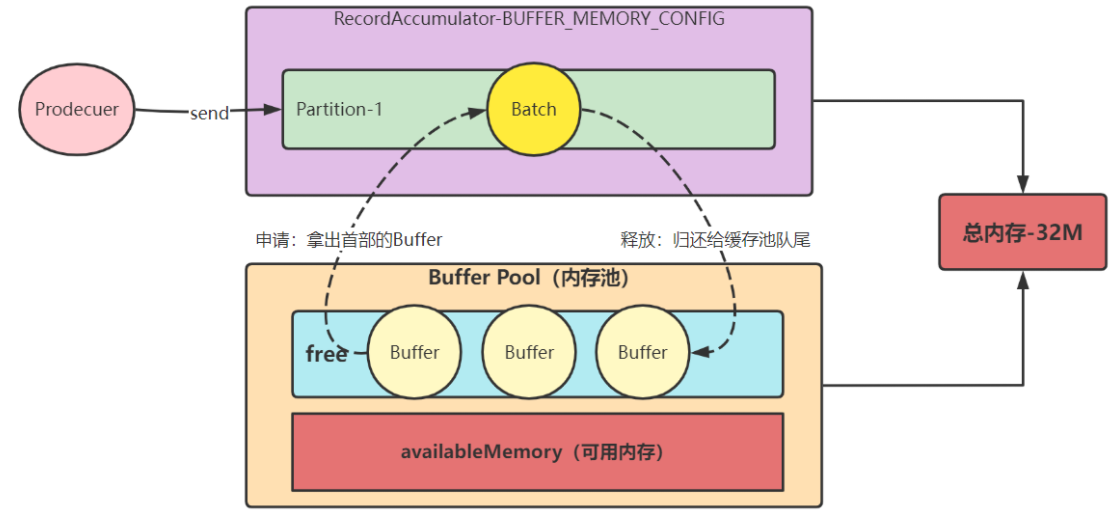
第一种:申请的内存为16KB且free缓存池有缓存可用
此时会直接从 free 缓存池的队首拿出一个 16KB 的 ByteBuffer 来直接使用,等到 ByteBuffer 用完之后,将其 clear() 然后放入 free 缓存池的尾部,随后唤醒下一个等待内存分配的线程。
第二种:申请16k且free缓存池无可用内存
此时 free 缓存池无可用内存,只能从可用内存中获取16k内存来分配,用完后直接将 ByteBuffer 放到 free 缓存池的队尾中,并调用 clear() 清空数据,以便下次重复使用。
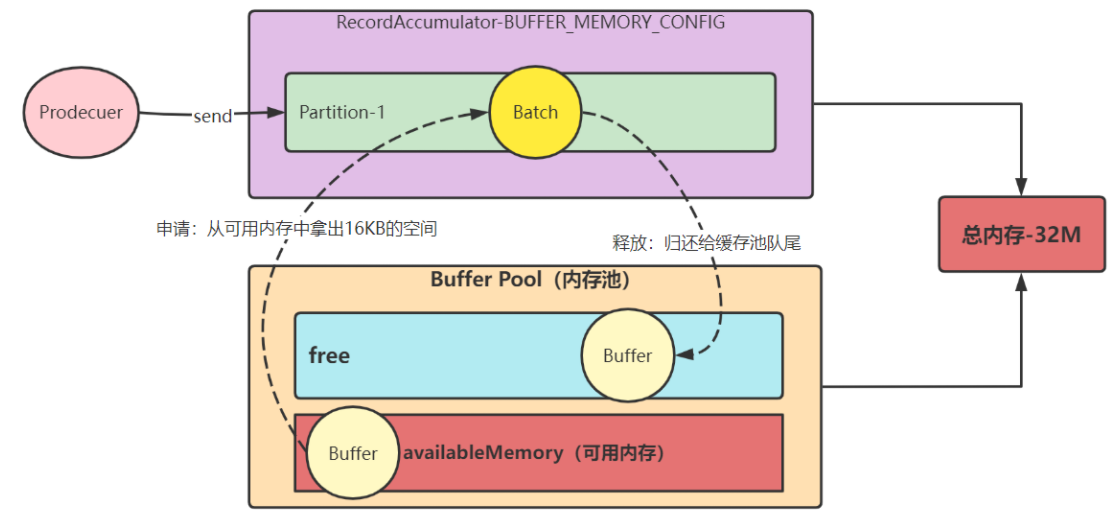
情况3:申请非16k且free缓存池无可用内存
此时 free 缓存池无可用内存,且 申请的是非16k,只能从 非池化可用内存(空间够分配)中获取一部分内存来分配,用完后直接将申请到的内存空间释放到非池化可用内存中,后续会 被 GC 掉。
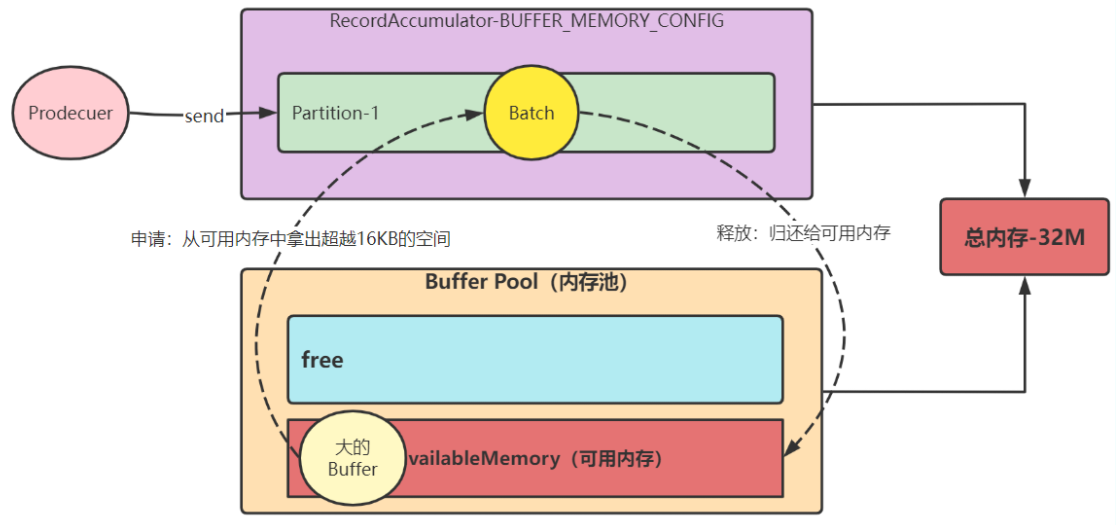
情况4:申请非16k且free缓存池有可用内存,但非池化可用内存不够
此时 free 缓存池有可用内存,但 申请的是非16k,先尝试从 free 缓存池中将 ByteBuffer 释放到非池化可用内存中,直到满足申请内存大小(size),然后从可用内存获取对应内存大小来分配,用完后直接将申请到的内存空间释放到到非池化可用内存中,后续会被 GC 掉。
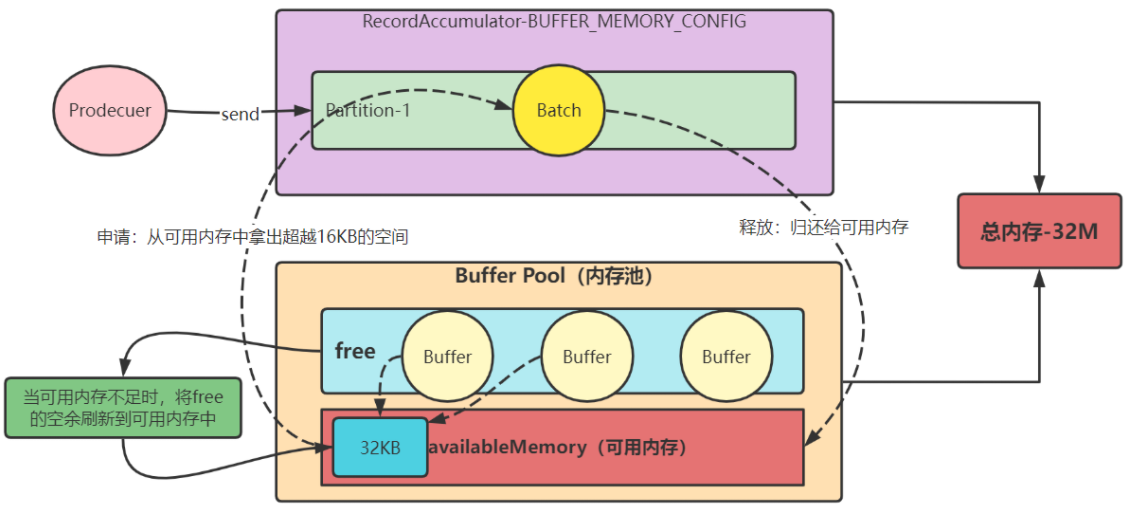
3. deallocate()
当使用完缓存之后,将缓存清空重新放入缓存池的操作源码如下:
// 返回缓存的操作
// 若当前的 ByteBuffer 是 16KB 的,直接放入 free 缓存池
// 若不是,则直接返还给 availableMemory
// 最后唤醒下一个等待内存分配的线程
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
// 清空
buffer.clear();
this.free.add(buffer);
} else {
this.availableMemory += size;
}
// 唤醒下一个等待内存分配的线程
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
三、缓冲池流程图

四、总结
本章我们讲述了 Kafka 生产端为了避免频繁的 GC,创建了 缓存池的机制
当生产端申请的内存为 16KB 时,从缓存池中取缓存使用,非 16KB 则取 不可复用的ByteBuffer 使用
我们在生产中要尽量避免 不可复用的ByteBuffer 的产生,根据当前的业务去调整 batch.size 的大小,否则容易造成频繁的 GC,影响我们的线上业务。
下一章我们将会更新 Kafka 生产端的网络 I/O 模型
喜欢 kafka 的可以点个关注吆,后续会继续更新其源码文章。
我是爱敲代码的小黄,我们下次再见。







![[附源码]java毕业设计闲置物品线上交易系统](https://img-blog.csdnimg.cn/29bcde739fea4e19844bcaccae006e7e.png)