拼写纠正系列
NLP 中文拼写检测实现思路
NLP 中文拼写检测纠正算法整理
NLP 英文拼写算法,如果提升 100W 倍的性能?
NLP 中文拼写检测纠正 Paper
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
一个提升英文单词拼写检测性能 1000 倍的算法?
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
nlp-hanzi-similar 汉字相似度
word-checker 中英文拼写检测
pinyin 汉字转拼音
opencc4j 繁简体转换
sensitive-word 敏感词
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
感受
这一篇和我的理念很类似,其实就是汉字的三个部分:音 形 义
字典是学习一个字符如何发音、书写和使用的参考书籍
其实本质上还是类似的。
TODO: 不过目前义(使用)这个部分我做的还比较弱,考虑添加一个关于单个字/词的解释词库。
论文+实现
论文地址: https://arxiv.org/pdf/2210.10320v1
源码地址:https://github.com/geekjuruo/lead
摘要
中文拼写检查(CSC)旨在检测和纠正中文拼写错误。
近年来的研究从预训练语言模型的知识出发,并将多模态信息引入CSC模型,以提高性能。
然而,它们忽视了字典中丰富的知识,字典是学习一个字符如何发音、书写和使用的参考书籍。
本文提出了LEAD框架,使CSC模型能够从字典中学习异质知识,涵盖语音、视觉和语义方面的内容。
LEAD首先根据字典中的字符语音、字形和定义的知识构建正负样本。
然后,采用统一的对比学习训练方案来细化CSC模型的表示。大量实验和对SIGHAN基准数据集的详细分析验证了我们提出方法的有效性。
1 引言
作为一项重要的中文处理任务,中文拼写检查(CSC)旨在检测和纠正中文拼写错误(Wu等,2013a),这些错误主要由发音或字形相似的字符引起(Liu等,2010)。
最近的研究提出引入语音和视觉信息,以帮助预训练语言模型(PLM)处理混淆字符(Liu等,2021;Xu等,2021;Huang等,2021)。
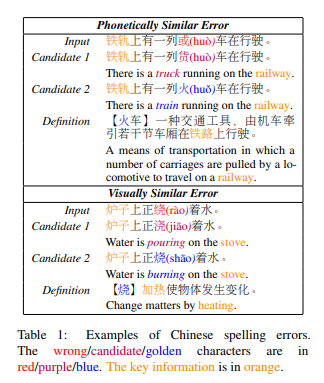
然而,CSC任务具有挑战性,因为它不仅需要语音/视觉信息,还需要复杂的定义知识来帮助找到真正正确的字符。如表1所示,“货(huò)”和“火(huo)”在发音上相似,并且两者都可以与“车”搭配。但如果模型关注关键词“铁轨(railway)”并理解“火车(train)”的意思,那么它就不会被“货”干扰,能够做出正确的判断。
相同的情况也出现在视觉上。对于这些难度较大的样本,PLM表现不佳,因为掩蔽语言建模目标决定了它们预训练的语义知识更多地是关于字符的搭配,而不是它们的定义。
因此,如果模型能够理解单词的意义,它就可以进一步增强以处理更多困难样本,并提高性能。
为了帮助人们学习中文,汉字和词汇的含义已被组织成字典中的定义句子。
字典包含了大量有用的中文拼写检查(CSC)知识,包括字符的语音、字形和定义。
它也是学习如何发音、书写和使用一个字符的中文初学者最重要的资源。受到此启发,我们着眼于利用字典中的丰富知识来提高CSC的性能。
本文提出了LEAD框架,这是一个统一的微调框架,旨在指导CSC模型从字典中学习异质知识。总体来说,LEAD具有一个训练范式,但除了传统的CSC目标外,还有三个不同的训练目标。这使得模型能够学习三种不同类型的知识,即语音、视觉和定义知识。具体而言,我们根据不同知识的各自特点构建了各种正负样本,然后利用这些生成的样本对模型进行训练,采用我们设计的统一对比学习范式。
通过优化LEAD,微调后的模型能够处理各种发音/字形相似的字符错误,并且与之前的多模态模型一样,进一步借助字典中包含的定义知识来处理更多的混淆错误。此外,LEAD是一个模型无关的微调框架,它对微调模型没有限制。在实践中,我们使用LEAD对BERT和一个更复杂的多模态CSC模型(Xu等,2021)进行了微调,实验结果显示,LEAD在SIGHAN数据集上的表现一致优于其他方法。
总结来说,我们工作的贡献有三方面:
我们关注字典知识对于CSC任务的重要性,这对未来的CSC研究具有指导意义。
我们提出了LEAD框架,该框架以统一的方式微调模型,使其学习对CSC任务有益的异质知识。
我们在广泛使用的SIGHAN数据集上进行了广泛的实验和详细分析,LEAD超越了之前的最先进方法。
- T1
2 相关工作
2.1 中文拼写检查(CSC)
近年来,基于深度学习的模型逐渐成为中文拼写检查(CSC)方法的主流(Wang等,2018;Hong等,2019;Zhang等,2020;Li等,2022b)。
SpellGCN(Cheng等,2020)使用图卷积网络(GCN)(Kipf和Welling,2017)将具有相似发音和字形的字符嵌入融合在一起,明确建模字符之间的关系。
GAD(Guo等,2021)提出了一种全局注意力解码器方法,并通过混淆集引导替换策略对BERT(Devlin等,2019)进行了预训练。
Li等(2021)提出了一种方法,通过持续识别模型的薄弱环节生成更多有价值的训练样本,并应用任务特定的预训练策略来增强模型。此外,许多CSC相关工作关注了多模态知识对于CSC的重要性。
DCN(Wang等,2021)、MLM-phonetics(Zhang等,2021)和SpellBERT(Ji等,2021)都利用了语音特征来提高CSC性能。PLOME(Liu等,2021)设计了一种基于混淆集的掩蔽策略,并引入了语音和笔画信息。REALISE(Xu等,2021)和PHMOSpell(Huang等,2021)都使用编码器来学习多模态知识。
与之前的工作不同,我们的工作首次引入了来自字典的定义知识,以增强CSC模型。
2.2 对比学习
对比学习是一种广泛应用于自然语言处理(NLP)和计算机视觉(CV)的表示学习方法(Chen等,2020;He等,2020a;Gao等,2021)。对比学习的主要动机是在某个空间中将正样本拉近、负样本推远(Hadsell等,2006;Chen等,2020;Khosla等,2020)。
在NLP领域,已研究了各种对比学习方法,用于学习更好的表示,例如实体(Li等,2022a)、句子(Kim等,2021)和关系(Qin等,2021)。
据我们所知,我们是首个利用对比学习思想来学习更好的语音、视觉和定义知识以增强CSC的工作。
3 方法论
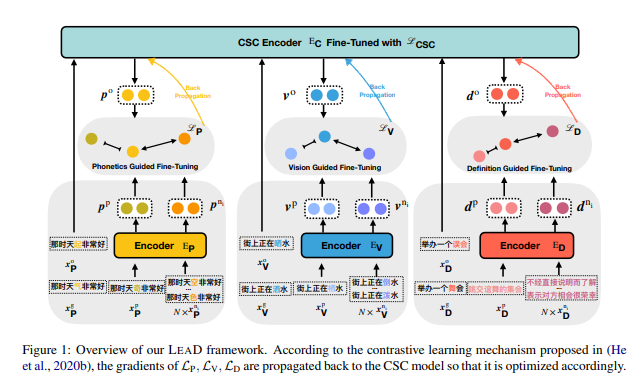
在本节中,我们首先介绍LEAD框架的概述,如图1所示,并描述我们为异质字典知识设计的统一对比学习机制。
然后,对于每个知识引导的微调,我们解释其动机、正/负样本构建以及用于对比学习机制的表示度量。
- f1
3.1 LEAD框架概述
在LEAD中,除了使用CSC样本训练传统的CSC目标外,还生成了用于对比学习的各种正负样本对,涵盖三种知识(即语音、视觉和定义)。
值得强调的是,这三个知识编码器(即 ( E_P ), ( E_V ), 和 ( E_D ))是冻结的,而 ( E_C ) 在训练过程中接收来自多个维度的梯度并进行优化。
此外,我们提出的LEAD是模型无关的,因此我们可以任意配置 ( E_P ), ( E_V ), ( E_D ),并轻松地使用先前的CSC模型作为 ( E_C )。我们在实验中使用的各种编码器的实现细节见附录A.2。
简而言之,我们提出的LEAD通过特定的对比微调引导异质知识,从而将各种有益的信息引入CSC模型,提升其性能。
在3.2至3.4节中,我们将详细介绍为每种知识设计的正负样本对构建和表示度量。
3.2 语音引导微调
根据语音知识,汉字通常通过拼音表示。因此,为了使模型更好地处理语音错误,我们旨在引导模型更多地关注拼音相似的字符。
为此,我们提出了语音引导微调(Phonetics Guided Fine-tuning),其目标是精细调整模型学习的表示空间,使得拼音相似的字符的表示更加接近,而拼音不同的字符的表示则被推远。
这样,在处理拼音拼写错误时,模型将优先与拼音相似的字符关联。
正负样本构建
对于语音知识,我们将拼音相似的字符视为正样本,将拼音不同的字符视为负样本。如图1所示,给定一个训练样本 ( x_o^P ) “那时天起(qǐ, rise)非常好”,其中包含一个语音拼写错误,我们通过将“起(qǐ, rise)”替换为其拼音相似的字符“奇(qí, strange)”来生成正样本 ( x_p^P )。为了生成负样本集 ({x_{ni}^P}),我们随机选择N个拼音不同的字符,如“色(sè, color)”,替换掉“起(qǐ, rise)”。
最终,我们得到一个正样本对 ((x_o^P, x_p^P)) 和N个负样本对 ({(x_o^P, x_{ni}^P)}_{i=0}^{N-1}),用以构建小批量进行语音知识的微调。
3.3 视觉引导微调
类似于语音引导微调,我们提出了视觉引导微调(Vision Guided Fine-tuning),旨在获得更好的视觉表示,并提升模型的视觉错误修正能力。
具体来说,基于汉字由笔画组成的事实,视觉知识的目的是训练模型在视觉表示空间中将笔画相似的字符表示得更近,将笔画不同的字符表示得更远。
正负样本构建
基于字符之间的视觉相似性,对于特定的汉字,我们直接从之前的工作中广泛使用的预定义混淆集(Wang et al., 2019; Cheng et al., 2020; Zhang et al., 2020)中获取与之笔画相似的字符。
例如,如图1所示,对于训练样本 ( x_o^V ) “街上正在晒(shài, bask)水”,我们通过将“晒(shài, bask)”替换为“栖(qī, habitat)”来生成正样本 ( x_p^V )。类似于语音引导微调,我们随机选择笔画不同的字符生成负样本集 ({x_{ni}^V})。
3.4 定义引导微调
如第1节所述,结构化词典中的词语意义在拼写错误无法仅通过语音和视觉信息纠正时,对于人工拼写检查非常有用。为了更好地利用定义知识,我们专门设计了定义引导微调(Definition Guided Fine-tuning),使模型更好地理解词语的含义。得益于定义知识的增强,我们的模型将像人类一样,看到拼写错误并将其与定义联系起来,然后基于原始词义做出合理的修正。
正负样本构建
如图1所示,给定一个随机训练样本 ( x_o^D ) “举办一个误会”及其真实标签句子 ( x_g^D ) “举办一个舞会”。为了获取词语意义,我们必须首先获取包含错误位置 ( s ) 的原始单词。因此,我们将 ( x_g^D ) 分词为“举办/一个/舞会”,并在词典中查找原始单词(即“舞会”)以获取其对应的定义句子作为正样本 ( x_p^D )。至于负样本集 ({x_{ni}^D}),我们将随机选择N个其他单词的定义句子。
考虑到一些单词有多个定义,我们设计了以下几种词语定义选择策略:
- 随机选择定义:最简单的方法是从多个定义句子中随机选择一个句子。
- 选择第一个定义:通过对词典的初步分析,我们发现当一个单词有多个定义时,位于前面的定义通常是该单词最常用的含义。基于这一观察,我们提出选择第一个定义作为词语的意义。
- 选择最相似的定义:直观地说,词语的意义可以通过其上下文来揭示。因此,我们可以通过计算句子 ( x_g^D ) 与定义句子之间的相似度来判断选择哪个定义句子。更实际的方法是通过像BERT这样的编码器获取句子表示,然后使用余弦相似度等距离度量来计算句子表示之间的相似性。
不同词语定义选择策略的效果将在第4.6.2节中进行分析。
3.5 方法概述**
在上述的3.2-3.4节中,我们详细描述了为三种知识类型设计的对比学习目标。
这三种对比学习目标的目的是让CSC模型学习语音学、视觉和定义的外部知识,并最终提高模型的CSC性能。
此外,由于该模型将用于CSC任务,因此仍然需要使用CSC训练数据训练CSC训练目标LCSC。
结论
本文提出通过利用字典中包含的各种知识来促进CSC任务的研究。
我们介绍了LEAD,一个统一的微调框架,旨在进行三种异构知识的对比学习。
大量实验和实证分析验证了我们研究的动机以及我们提出的方法的有效性。我们关注的字典知识不仅对CSC有益,对于其他中文文本处理任务也至关重要。
因此,未来我们将继续挖掘字典中包含的知识,以改进其他中文文本处理任务。
限制性
在本节中,我们详细讨论了我们工作的限制,并提出了我们认为可行的相应解决方案。
语言限制
我们的工作和提出的方法主要聚焦于中文拼写检查(CSC)任务。中文的语言特点与其他语言(如英语)有很大不同。
例如,中文中的语音或视觉相似的字符是CSC的一个巨大挑战,而在英语中并不存在这种现象。
因此,语言特点的限制使得我们的方法无法直接转移到英语场景中。
然而,我们仍然认为我们关注的字典中的定义知识对英语文本纠错仍然具有重要的意义。
编码器选择
我们提出的LEAD框架是一个统一的微调框架,旨在引导CSC模型学习异构知识。
统一的框架使得LEAD对所使用的各种编码器没有严格的限制。
为了验证LEAD的有效性,在我们的实验中,我们只选择了简单的配置,如EP、EV、ED(见附录A.2)。
未来,我们建议可以使用更复杂的模型和配置,以实现更多的性能提升。
运行效率
作为学术验证实验,我们并未在具体代码实现中考虑我们提出的方法的运行效率。
具体来说,在1个V100 GPU上完成训练过程大约需要10小时,且占用最多24G的GPU内存。
我们认为至少有两种解决方案可以提高效率:
(1)将模型训练过程部署到多个GPU上,使用数据并行操作可以增加训练批量大小并缩短训练时间。
(2)将在线正负样本构建改为离线构建,即提前构建并存储用于训练的各种正负样本对,这也可以大大节省训练过程中的时间成本。