背景
在分类模型中,预测概率不仅是结果,更是模型决策的关键依据。为了更直观地理解这些概率分布,3D可视化提供了一种生动的展示方式,本文通过3D概率分布图,直观展示分类模型的预测概率
代码实现
基于时间序列的3D分布可视化
import datetime
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
import pandas as pd
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
# 示例数据,用于演示
num_samples = 100 # 时间间隔的数量(样本数量)
categories = ['Class A', 'Class B', 'Class C'] # 示例类别名称
probability_df = pd.DataFrame(
np.random.rand(num_samples, len(categories)),
columns=categories
)
# 每个类别的颜色
colors = ['#FF9999', '#99CCFF', '#99FF99'] # 柔和的红色、蓝色和绿色
# 生成时间戳,用作x轴(模拟时间间隔)
start_time = datetime.datetime.now() # 当前时间作为起点
time_stamps = [start_time + datetime.timedelta(minutes=5 * i) for i in range(num_samples)] # 每隔5分钟生成一个时间点
time_labels = [ts.strftime('%H:%M') for ts in time_stamps] # 格式化时间戳为“小时:分钟”形式
# 创建图形和3D坐标轴
fig = plt.figure(figsize=(20, 20)) # 设置图形大小
ax = fig.add_subplot(111, projection='3d') # 添加3D子图
# 将x值设置为时间索引
x = np.arange(probability_df.shape[0]) # x表示时间序列的索引
# 为每个类别绘制概率分布的曲面图
for i, col in enumerate(probability_df.columns):
y = np.full_like(x, i) # y值固定为类别的索引
z = probability_df[col].values
# 定义多边形的顶点
verts = [[(x[0], y[0], 0)] + [(x[j], y[j], z[j]) for j in range(len(x))] + [(x[-1], y[-1], 0)]]
poly = Poly3DCollection(
verts, # 多边形顶点列表
facecolors=colors[i % len(colors)], # 多边形的填充颜色
edgecolors=colors[i % len(colors)], # 多边形的边界颜色
alpha=0.7, # 透明度
lw=1.5 # 边框宽度
)
ax.add_collection3d(poly) # 将多边形添加到3D坐标轴
# 设置坐标轴的范围和标签
ax.set_xlim([0, len(x)]) # 设置x轴范围
ax.set_ylim([-0.5, len(probability_df.columns) - 0.5]) # 设置y轴范围
ax.set_zlim([0, 1]) # 设置z轴范围
ax.set_xticks(np.linspace(0, len(x) - 1, 5)) # x轴设置5个等间距刻度
ax.set_xticklabels([time_labels[int(t)] for t in np.linspace(0, len(x) - 1, 5).astype(int)], fontsize=12) # 设置x轴标签
ax.set_yticks(range(len(probability_df.columns))) # y轴刻度为类别索引
ax.set_zticks(np.linspace(0, 1, 5)) # z轴设置为0到1之间的5段
ax.set_yticklabels(probability_df.columns, fontsize=12) # y轴标签为类别名称
# 设置坐标轴标签,并通过 labelpad 参数调整标签与坐标轴的距离
ax.set_xlabel('Time (HH:MM)', fontsize=18, labelpad=20) # 调整 x轴标签的距离
ax.set_ylabel('Classes', fontsize=18, labelpad=30) # 调整 y轴标签的距离
ax.set_zlabel('Probability', fontsize=18, labelpad=3) # 调整 z轴标签的距离
ax.view_init(elev=30, azim=-45) # 设置3D图的视角(俯仰角30度,方位角-45度)
plt.savefig("probability_visualization_with_time.pdf", format="pdf", dpi=1200)
plt.show()
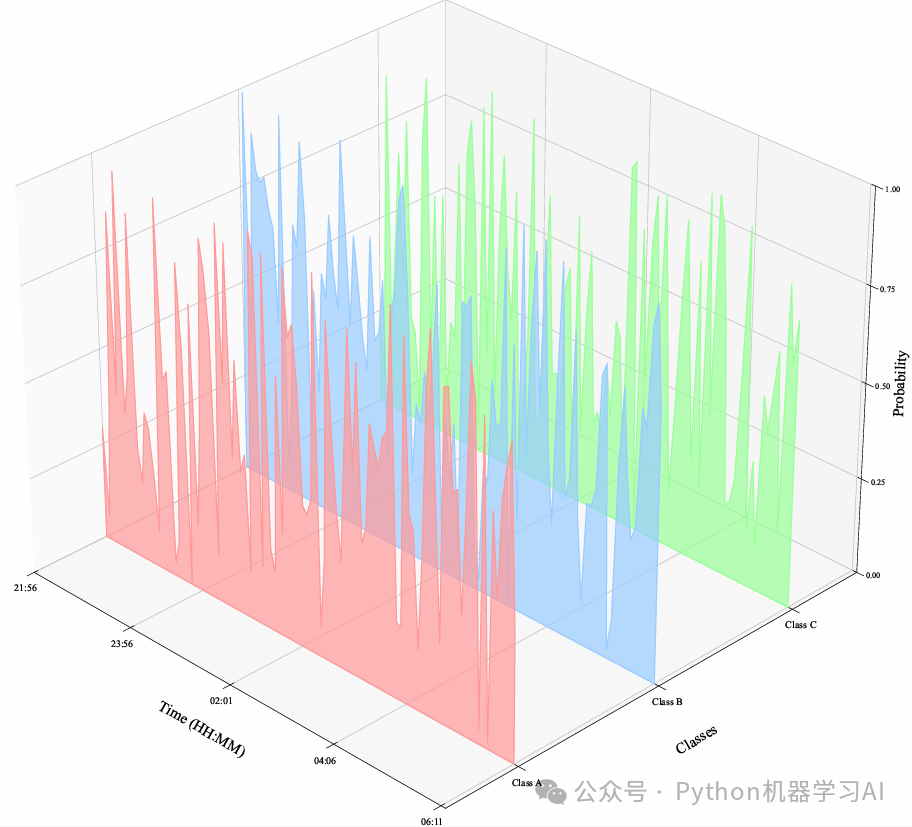
通过生成时间序列数据,将数值分布映射到三维空间,直观展示不同类别的数值随时间变化的趋势,基于这个代码的可视化方式,接下来进一步探索如何将分类模型的概率分布用同样的可视化进行映射
模型概率获取
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_excel('2024-12-16-0公众号Python机器学习AI—class (1).xlsx')
# 划分特征和目标变量
X = df.drop(['y'], axis=1)
y = df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42, stratify=df['y'])
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rf_model = RandomForestClassifier(random_state=42, n_estimators=100)
# 训练模型
rf_model.fit(X_train, y_train)
# 预测类别的概率
probabilities = rf_model.predict_proba(X_test)
# 创建一个 DataFrame,列名为类别
probability_df = pd.DataFrame(probabilities, columns=[f'Prob_Class_{i}' for i in range(probabilities.shape[1])])
# 如果需要,可以添加 X_test 的索引或其他标识列
probability_df.index = X_test.index
# 重置索引,并选择是否保留原索引作为一列
probability_df.reset_index(drop=True, inplace=True)
probability_df.head()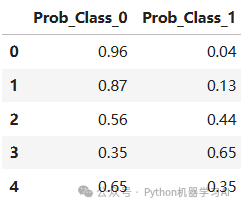
通过构建一个随机森林分类模型,对测试数据进行预测,并生成每个样本属于各个类别的概率分布,以便进一步分析模型的分类行为
3D概率分布可视化-1
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
# 为每个类别定义颜色
colors = [
"darkviolet", # 类别1的颜色
"teal", # 类别2的颜色
]
# 创建图形对象和3D坐标轴
fig = plt.figure(figsize=(20, 20)) # 设置图形大小
ax = fig.add_subplot(111, projection='3d') # 添加3D子图
# 将x值设置为样本索引
x = np.arange(probability_df.shape[0]) # x表示样本的索引
# 为每个类别绘制概率分布
for i, col in enumerate(probability_df.columns): # 遍历每个类别
y = np.full_like(x, i) # y值固定为类别的索引
z = probability_df[col].values # z表示类别对应的概率值
# 创建多边形的顶点
verts = [[(x[0], y[0], 0)] + [(x[j], y[j], z[j]) for j in range(len(x))] + [(x[-1], y[-1], 0)]] # 定义多边形的顶点
poly = Poly3DCollection(
verts, # 多边形的顶点列表
facecolors=colors[i % len(colors)], # 多边形的填充颜色(按类别循环选择颜色)
edgecolors=colors[i % len(colors)], # 多边形的边界颜色
alpha=0.5, # 设置透明度
lw=2 # 边框宽度
)
ax.add_collection3d(poly) # 将多边形添加到3D坐标轴
# 设置坐标轴的范围和标签
ax.set_xlim([0, len(x)]) # 设置x轴范围
ax.set_ylim([-0.5, len(probability_df.columns) - 0.5]) # 设置y轴范围
ax.set_zlim([0, 1]) # 设置z轴范围
ax.set_xticks(np.linspace(0, len(x), 5)) # 设置x轴刻度(等间隔5个点)
ax.set_yticks(range(len(probability_df.columns))) # 设置y轴刻度为类别索引
ax.set_zticks(np.linspace(0, 1, 5)) # 设置z轴刻度(概率值分为5段)
ax.set_yticklabels(probability_df.columns, fontsize=12) # 设置y轴刻度标签为类别名称
ax.set_xlabel('Sample Index', fontsize=18) # 设置x轴标签为“样本索引”
ax.set_ylabel('Classes', fontsize=18) # 设置y轴标签为“类别”
ax.set_zlabel('Probability', fontsize=18) # 设置z轴标签为“概率”
ax.view_init(elev=20, azim=-60) # 设置3D图的视角(俯仰角为20度,方位角为-60度)
plt.savefig("1.pdf", format="pdf", dpi=1200)
plt.show()
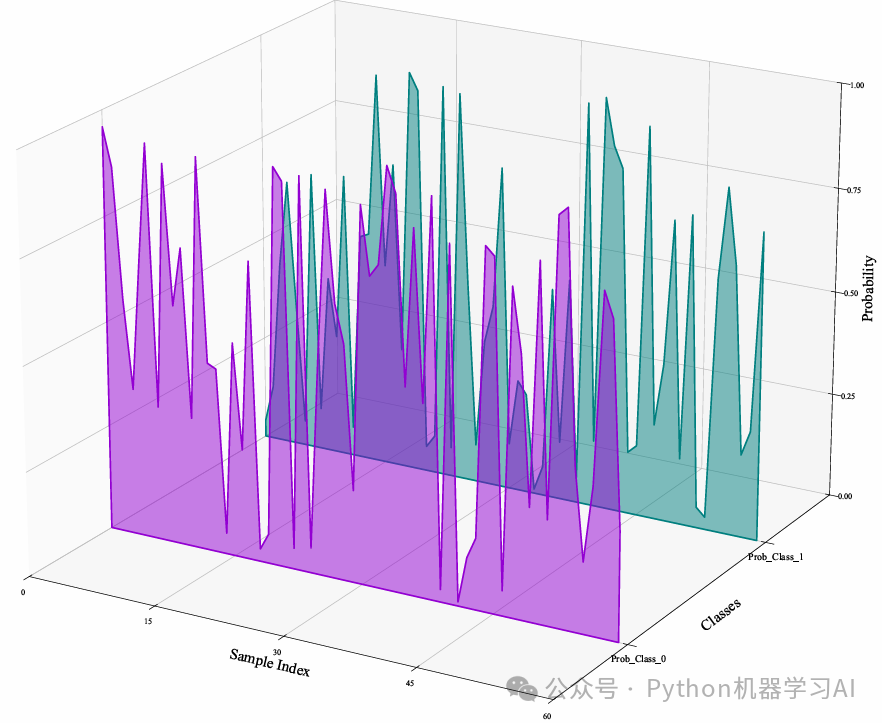
通过3D可视化展示了分类模型的预测概率分布,以样本索引为X轴、类别为Y轴、概率值为Z轴,并使用不同颜色区分类别,使模型的分类结果更加直观
3D概率分布可视化-2
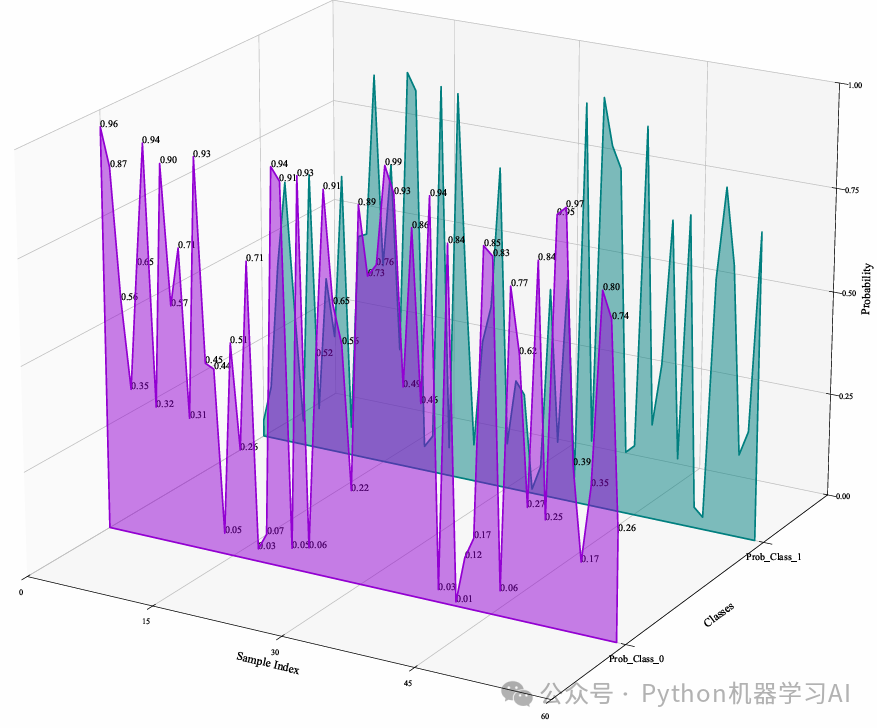
在前面的基础上通过为第一个类别添加概率值的文本标注,使可视化更具解释性和直观性
3D概率分布可视化-3
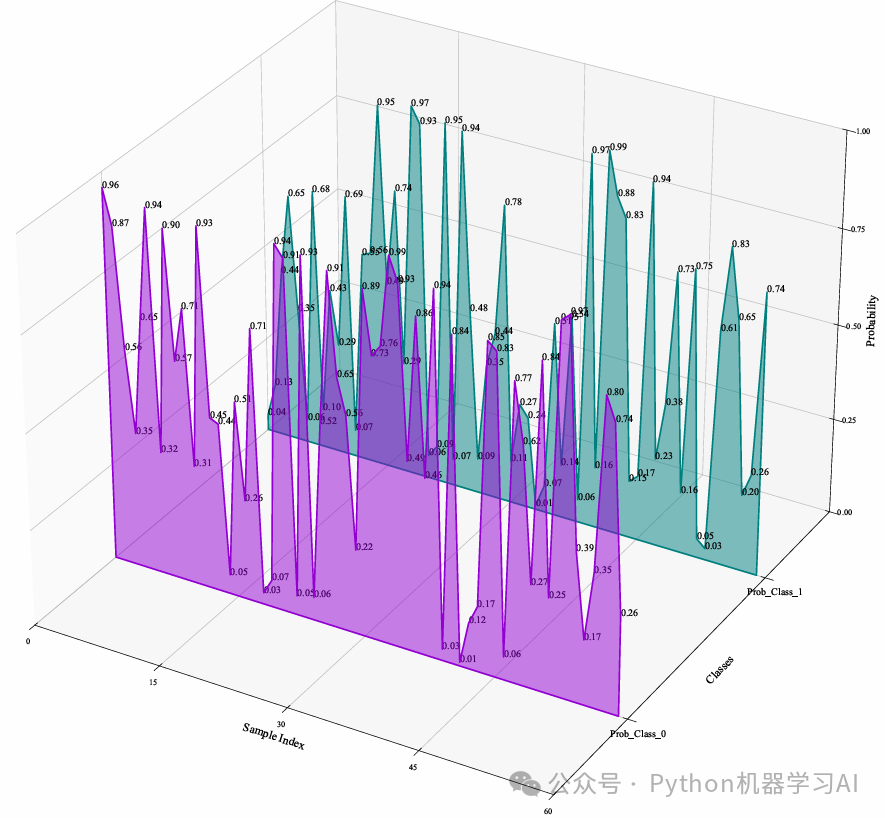
在所有类别上添加了概率值的文本标注,使得每个样本在每个类别的具体预测概率都可以直接观察到,进一步增强了3D可视化的细节和解释性,适合更精确的模型分析和展示,关注微信公众号:Python机器学习AI
往期推荐
从模型构建到在线部署:基于Stacking集成模型的全流程实现与SHAP可视化
探究SHAP交互效应:基于shap.dependence_plot与自定义可视化方法的对比分析
利用Optuna TPE算法优化RF模型及3D曲面图展示调参过程
nature medicine二分类结局随机森林模型构建与评估复现
期刊配图:分类变量SHAP值的箱线图及可视化优化展示
如何用SHAP解读集成学习Stacking中的基学习器和元学习器以及整体模型贡献
从入门到实践:如何利用Stacking集成多种机器学习算法提高模型性能
整合数据分布+拟合线+置信区间+相关系数的皮尔逊相关可视化
期刊配图:通过变量热图展示样本与模型预测的关联信息
期刊配图:如何有效呈现回归、分类模型的评价指标