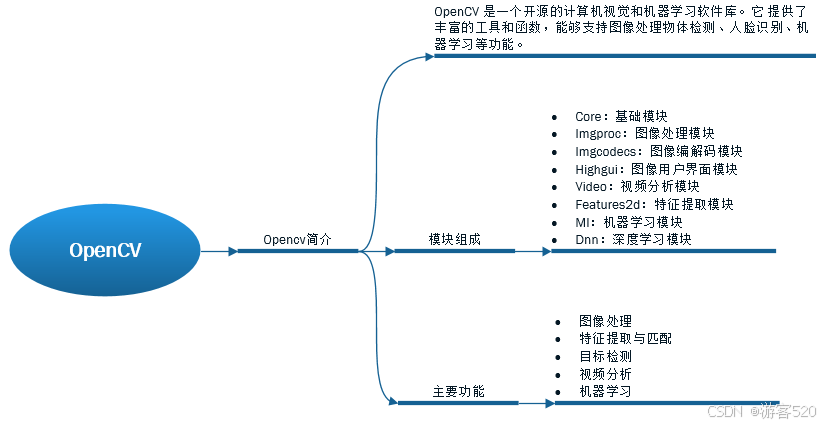
加载数据集
from datasets import load_dataset, load_from_disk
dataset_name="Dahoas/rm-static"
raw_datasets = load_dataset(dataset_name)
第3行报错,ValueError: Invalid pattern: ‘**‘ can only be an entire path component,查看datasets 版本为2.0.0,另一个conda 环境可以正常执行,另一个环境的datasets 版本为3.0.2,升级第一个的环境的datasets 版本,由2.0.0升级为3.0.2 发现不再报错
README.md: 530B [00:00, 729kB/s]
dataset_infos.json: 926B [00:00, 1.58MB/s]
(…)-00000-of-00001-2a1df75c6bce91ab.parquet: 100%|█| 68.4M/68.4M [00:08<00:00, 7.80MB/s]
(…)-00000-of-00001-8c7c51afc6d45980.parquet: 100%|█| 4.61M/4.61M [00:00<00:00, 8.58MB/s]
Generating train split: 100%|██████████| 76256/76256 [00:00<00:00, 490199.33 examples/s]
Generating test split: 100%|█████████████| 5103/5103 [00:00<00:00, 631633.52 examples/s]
参考资料:
1 报错处理 - load_dataset | ValueError: Invalid pattern: ‘**‘ can only be an entire path component_valueerror: invalid pattern: '**' can only be an e-CSDN博客
2 ValueError: Invalid pattern: ‘**‘ can only be an entire path component-CSDN博客