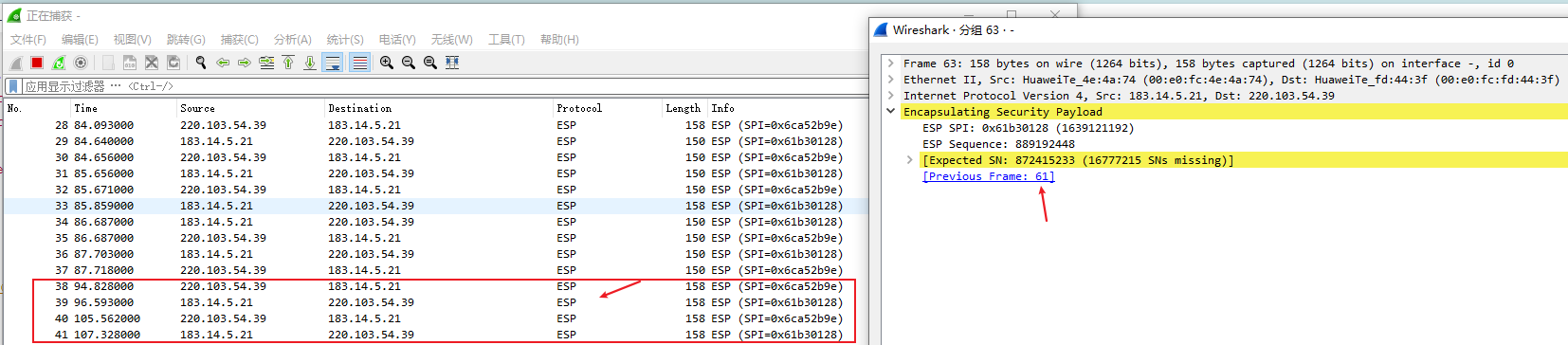
LSTM(长短期记忆网络)和GRU(门控循环单元)是两种流行的循环神经网络变体,它们被设计来解决传统RNN在处理长序列数据时遇到的梯度消失和梯度爆炸问题。这两种网络都通过引入门控机制来控制信息的流动,从而能够更好地捕捉长距离依赖关系。
LSTM(Long Short-Term Memory)
LSTM网络由Hochreiter和Schmidhuber于1997年提出。它通过引入三个门控(输入门、遗忘门、输出门)和一个单元状态来解决梯度消失问题。
- 遗忘门(Forget Gate):决定哪些信息需要从单元状态中丢弃。
- 输入门(Input Gate):决定哪些新信息将被存储在单元状态中。
- 单元状态(Cell State):携带有关输入序列的信息,并在整个序列中传递。
- 输出门(Output Gate):决定输出值,基于单元状态和隐藏状态。
LSTM的数学表达式如下:
[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ]
[ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) ]
[ \tilde{C}t = \tanh(W_C \cdot [h{t-1}, x_t] + b_C) ]
[ C_t = f_t * C_{t-1} + i_t * \tilde{C}t ]
[ o_t = \sigma(W_o \cdot [h{t-1}, x_t] + b_o) ]
[ h_t = o_t * \tanh(C_t) ]
其中,( f_t )、( i_t )、( o_t ) 分别是遗忘门、输入门和输出门的激活值,( C_t ) 是单元状态,( h_t ) 是隐藏状态,( \sigma ) 是sigmoid函数,( * ) 表示逐元素乘法。
GRU(Gated Recurrent Unit)
GRU是Cho等人在2014年提出的一种更简洁的RNN变体,它将LSTM中的遗忘门和输入门合并为一个更新门,并引入重置门。
- 更新门(Update Gate):控制从旧的隐藏状态到新的隐藏状态的转换。
- 重置门(Reset Gate):控制从过去的信息中忘记多少,以帮助模型处理长期依赖。
- 隐藏状态(Hidden State):同时作为单元状态和输出状态。
GRU的数学表达式如下:
[ z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) ]
[ r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) ]
[ \tilde{h}t = \tanh(W \cdot [r_t * h{t-1}, x_t] + b) ]
[ h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t ]
其中,( z_t ) 是更新门的激活值,( r_t ) 是重置门的激活值,( \tilde{h}_t ) 是候选隐藏状态,( h_t ) 是最终的隐藏状态。
LSTM与GRU的比较
- 参数数量:GRU的参数数量通常少于LSTM,因为它没有单独的单元状态和输出门。
- 计算复杂度:GRU的计算复杂度较低,因为它的结构更简单。
- 性能:在某些任务中,LSTM和GRU的性能相当,但在处理非常长的序列时,LSTM通常表现更好。
- 适用性:对于较小的数据集,GRU可能更快地收敛,但在较大的数据集上,LSTM可能更稳定。
在实际应用中,选择LSTM还是GRU取决于具体任务的需求、数据集的大小以及模型的复杂度。有时,通过实验比较两者的性能来决定使用哪种模型是一个好的选择。


![[Linux] 信号保存与处理](https://i-blog.csdnimg.cn/direct/743ffdeed37346ffa12c2235e13c9fba.jpeg)